天津大学脑机接口MetaBCI项目平台安装教程
天津大学神经工程团队介绍了中国首个脑机接口开源软件平台——MetaBCI的技术架构和实现方法。MetaBCI针对BCI领域中数据分布零散、算法难以复现以及在线系统效率低下的问题,规范了BCI数据结构和预处理流程,开发了通用的算法框架。使用anconda管理python环境,及安装jupyter notebook便于后续Metabci环境的使用
文章目录
- 前言
- 一、安装Anconda
-
- 1.换conda源
- 2.换pip源
- 3.安装python3.8环境
- 二、安装MteaBCI
-
- 1.下载项目压缩包
- 2.安装依赖环境
- 三、jupyter notebook
-
- 1.安装jupyter
- 2.使用jupyter notebook
前言
天津大学神经工程团队在《Computers in Biology and Medicine》期刊(SCI一区TOP期刊)上发表了一篇论文,介绍了中国首个脑机接口开源软件平台——MetaBCI的技术架构和实现方法。MetaBCI针对BCI领域中数据分布零散、算法难以复现以及在线系统效率低下的问题,规范了BCI数据结构和预处理流程,开发了通用的算法框架,并通过双进程和双线程技术提升了在线实时效率。这些创新有助于降低脑机接口系统构建的技术门槛,减少研发成本,推动技术的转化和应用落地。
github项目地址: https://github.com/TBC-TJU/MetaBCI
本文讲解如何安装Metabci环境
一、安装Anconda
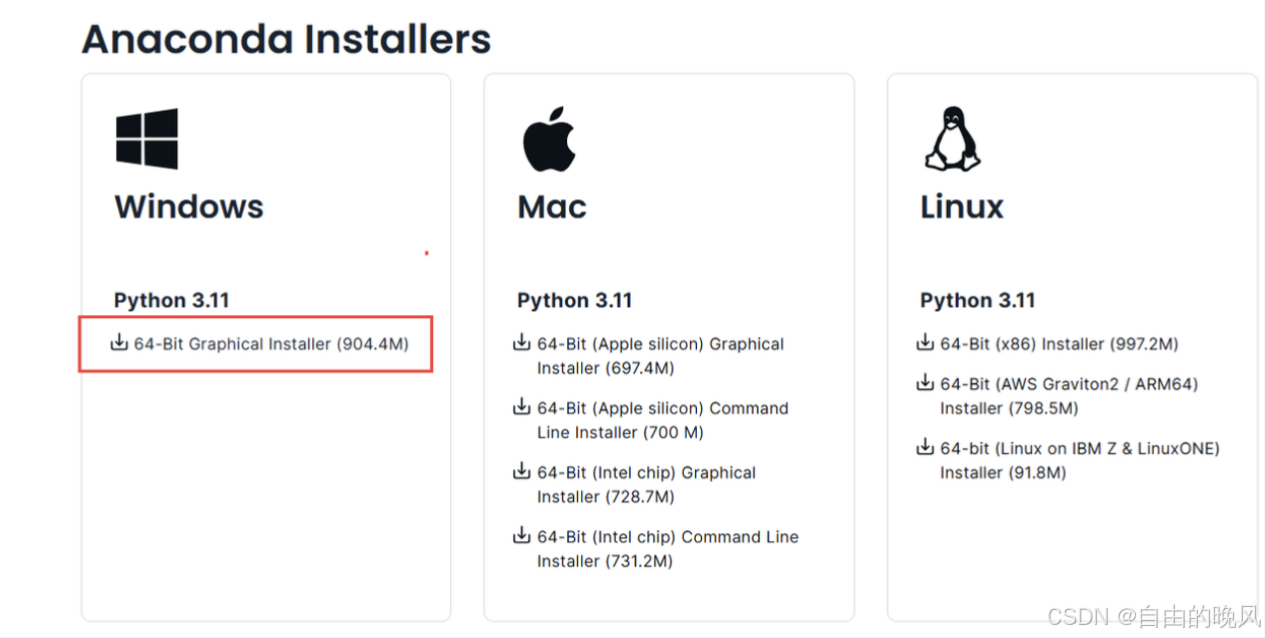
先下载一个可以管理环境的软件Anconda。因为不同项目要求的编译环境,如python版本,是不一样的。如果电脑上放着两个不同的项目,用的python版本不一样。两边使用还要重新下载安装对应版本的环境。用anconda就可以创建不同的环境,在一台电脑上进行使用管理。这里在win11用的所以下载windows版本,进行安装。
下载网址 https://www.anaconda.com/download/success
安装完成后,就可以在windows左下角菜单中,找到Anaconda Navigator打开cmd命令行。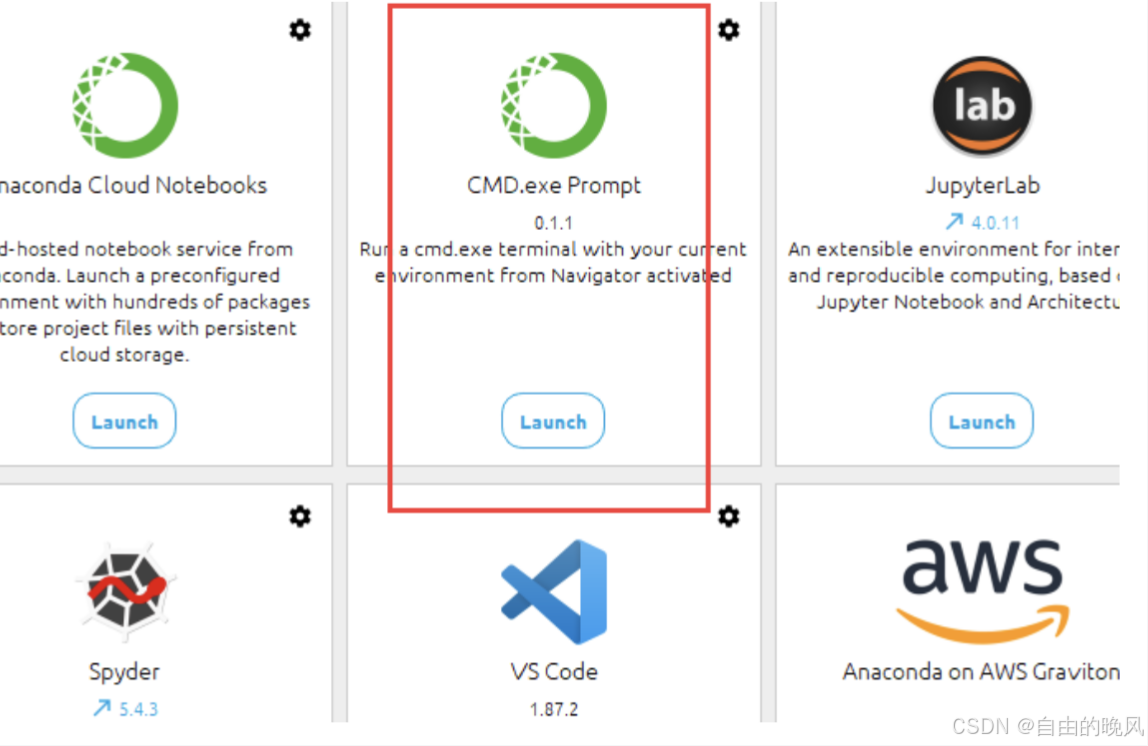
1.换conda源
实测conda默认使用直接下载,大部分情况比较慢,容易断联。所以这里进行换源操作,把下载源改为国内源。先改conda下载的源,对于conda insall指令速度有改善。依次输入,回车确认。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud//pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --set show_channel_urls yes
2.换pip源
上面改的conda安装的源,只更改这个,pip安装还是很慢。所以再改pip源。
到C:\Users\user_name目录下,Users部分电脑叫用户,user_name是电脑用户名。新建pip文件夹。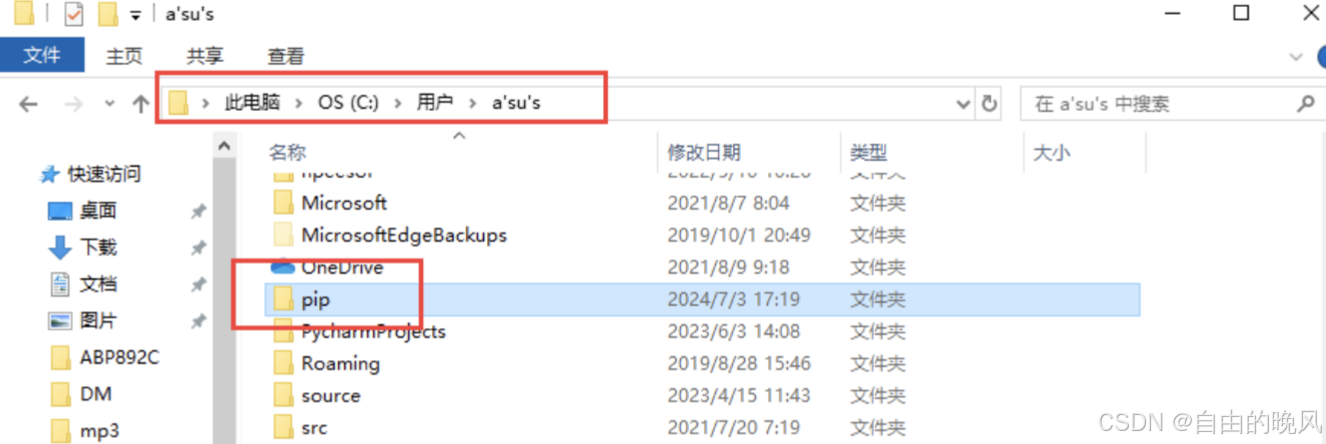
然后在pip文件夹内新建pip.ini![[图片]](https://i-blog.csdnimg.cn/direct/9f8359e9d7784724a49824b48cbda453.png)
然后在该文件内粘贴以下信息。
[global]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=pypi.tuna.tsinghua.edu.cn
disable-pip-version-check = true
timeout = 6000
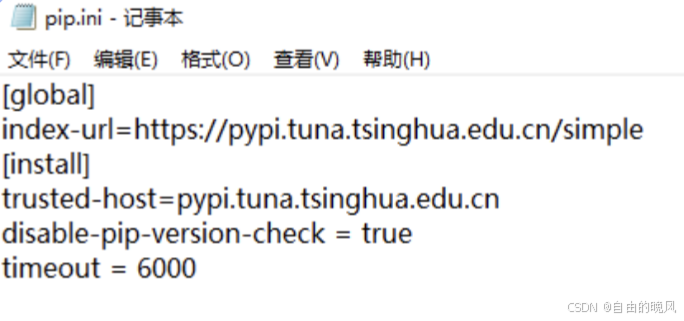
之后保存即可关闭。
3.安装python3.8环境
然后根据metabci的github项目issue中,作者的回答,最好是用python3.8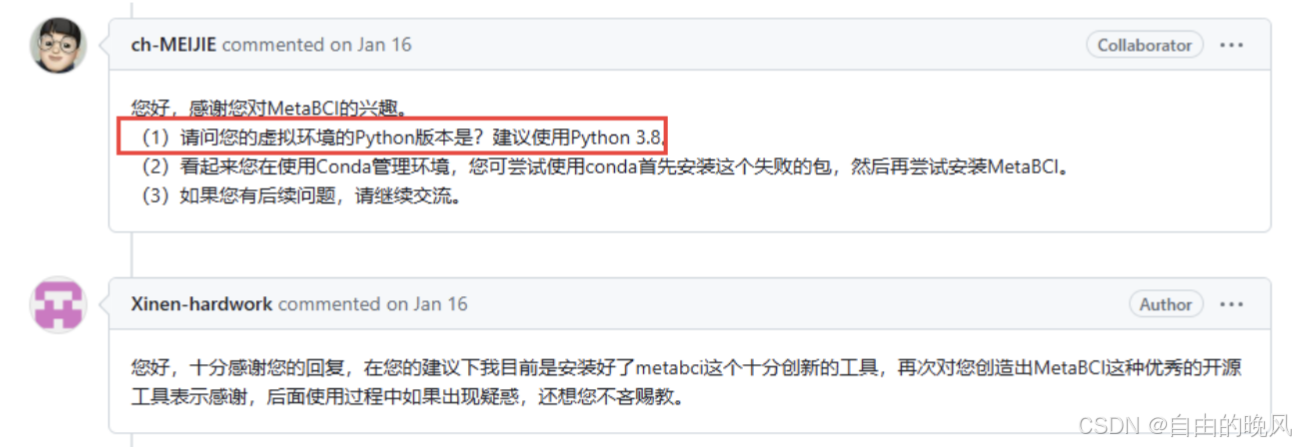
首先创建一个名为metabci的环境
conda create -n metabci python=3.8
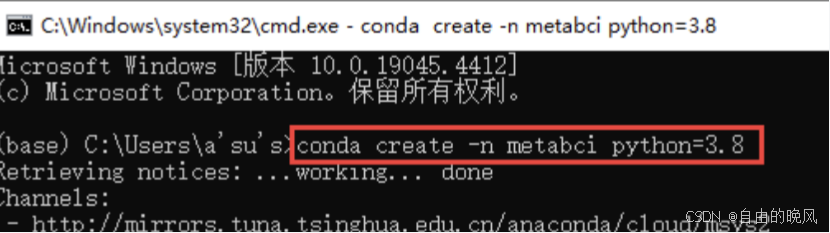
回车后,如下图询问时,按y确认安装。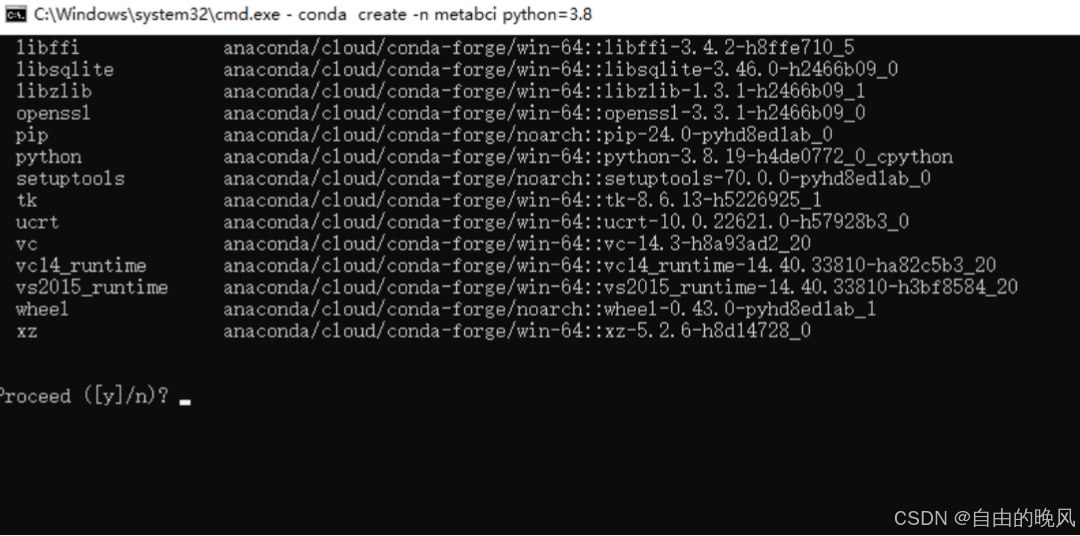
等一段时间,就装好了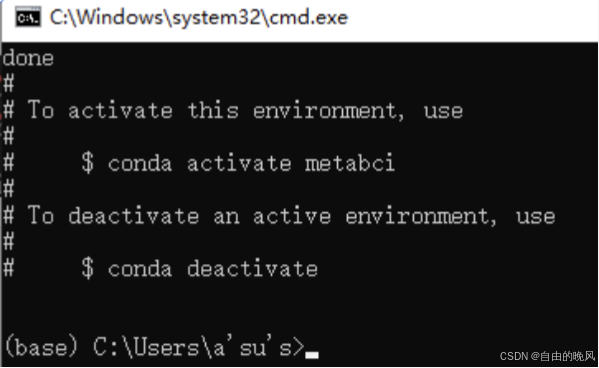
二、安装MteaBCI
1.下载项目压缩包
去项目地址下载,下载后解压缩。用git方式下载也可以,不赘述。
github项目地址: https://github.com/TBC-TJU/MetaBCI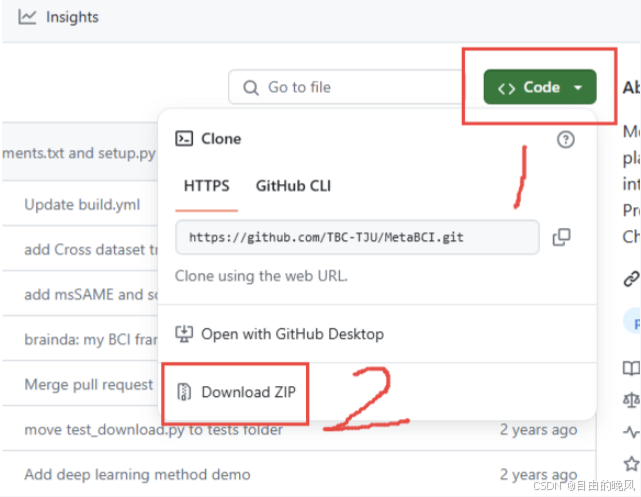
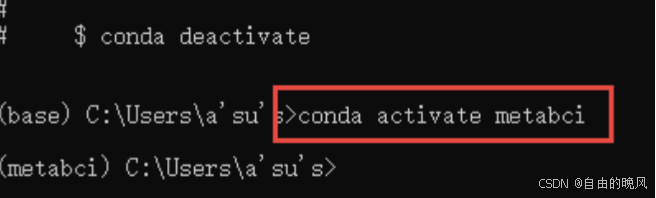
打开conda的cmd后,输入conda activate metabci 就可以打开刚刚创建的环境
conda activate metabci
2.安装依赖环境
然后切换到解压的项目文件夹内。这里cd切换文件夹,C盘换D盘,需要先退回到C盘根目录,然后才能切换到D盘,之后才能cd路径,切换到D盘的文件夹内
退回上一级
cd ..
在C盘根目录切换到D盘
D:
最后cd切换到解压后的项目目录下
然后输入以下命令,按回车安装依赖环境,等待下载安装完毕即可。
pip install -r requirements.txt
三、jupyter notebook
1.安装jupyter
在metabci环境下使用
conda install ipykernel
为当前环境(前面括号里的)安装ipykernel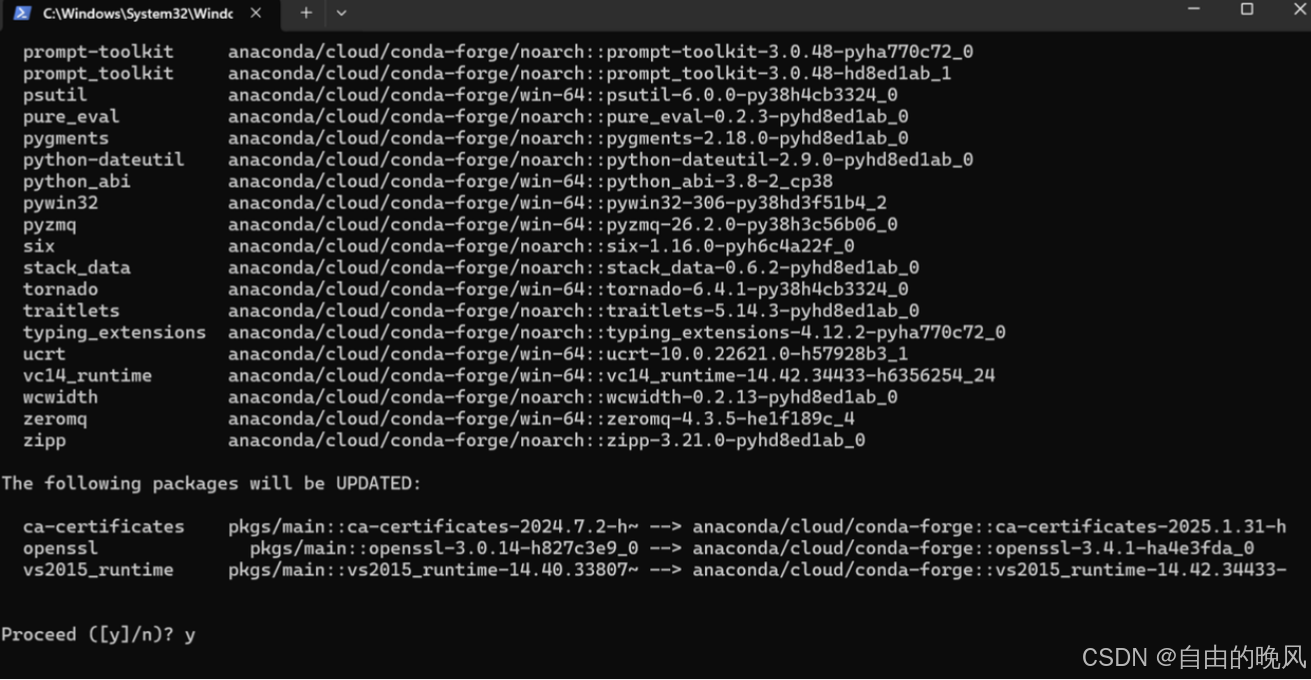
使用如下指令,出现版本号,即表示安装成功。
python -m ipykernel --version

使用如下这行,添加内核
python -m ipykernel install --user --name=metabci --display-name metabci
使用如下指令,检查内核路径是否添加正确。
jupyter kernelspec list

2.使用jupyter notebook
使用如下指令进入conda的metabci环境,然后进入jupyter
conda activate metabci
jupyter notebook
弹出使用浏览器打开,然后按如下图片创建notebook。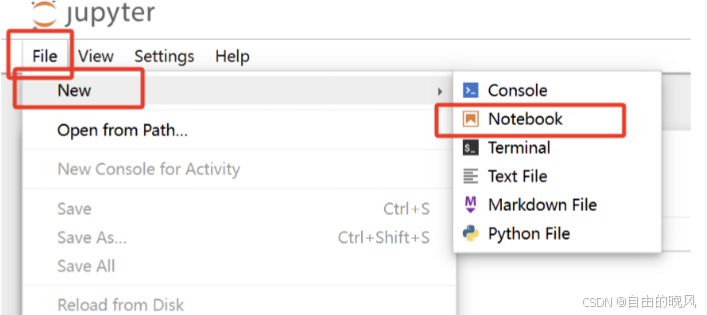
核kernel选择刚刚创建的metabci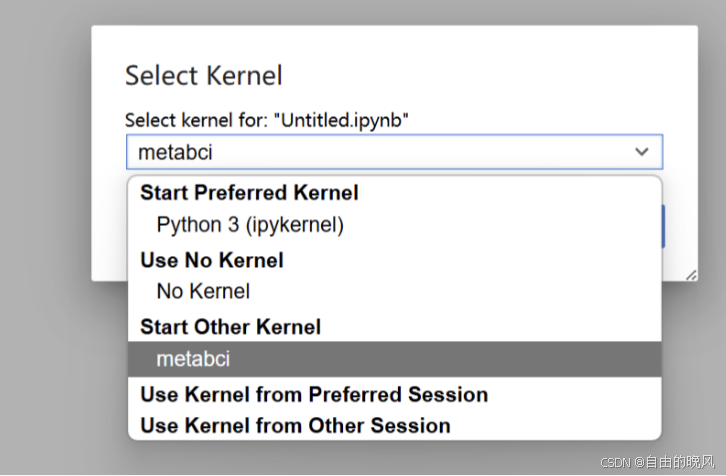
然后就可以在jupyter notebook里写python了。Jupyter Notebook 的一个显著特点是可以交互式地执行代码,程序可以放在一个一个代码块里,可以选择代码块分别,依次运行,每个代码块可以单独输出运行结果。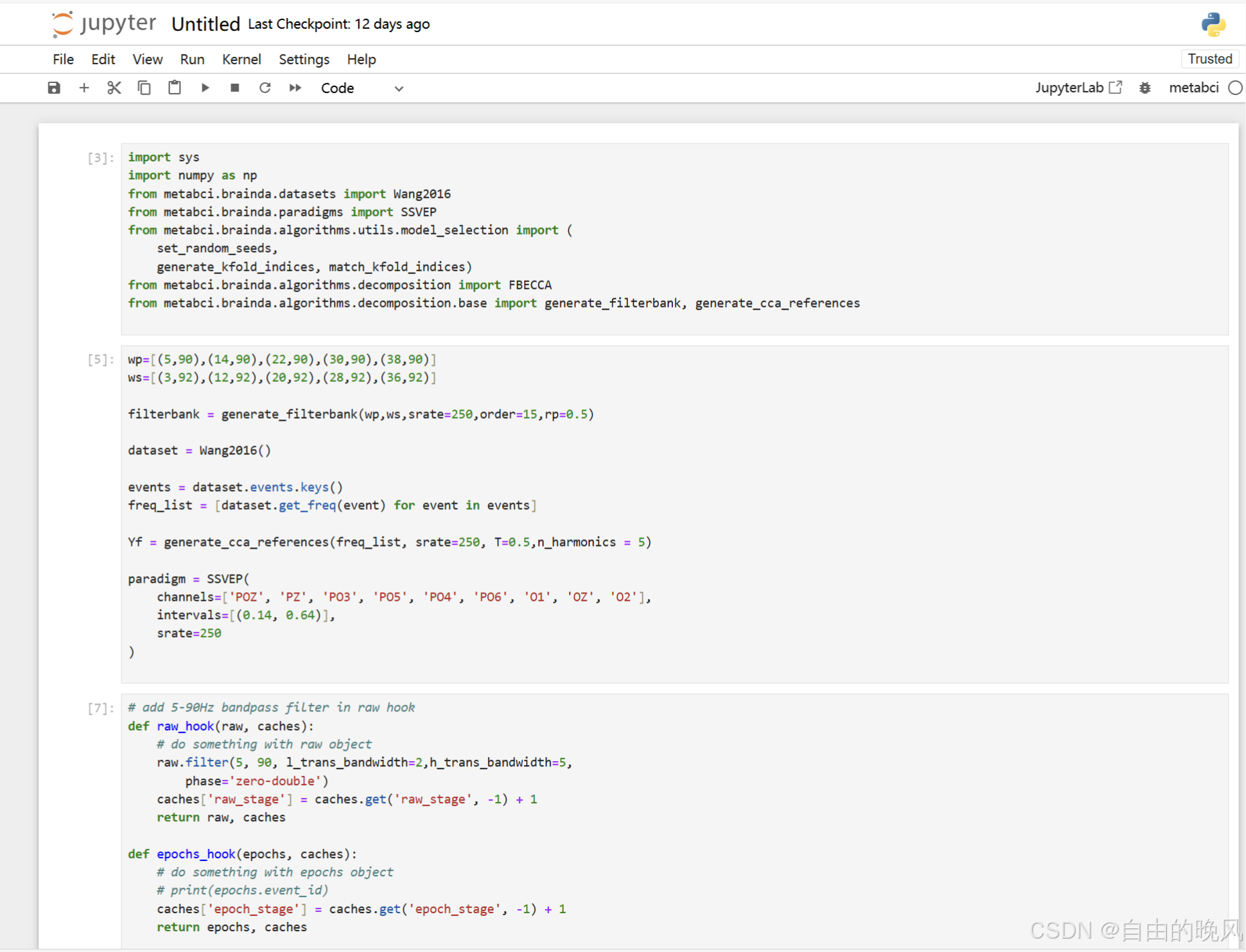
测试代码运行输出结果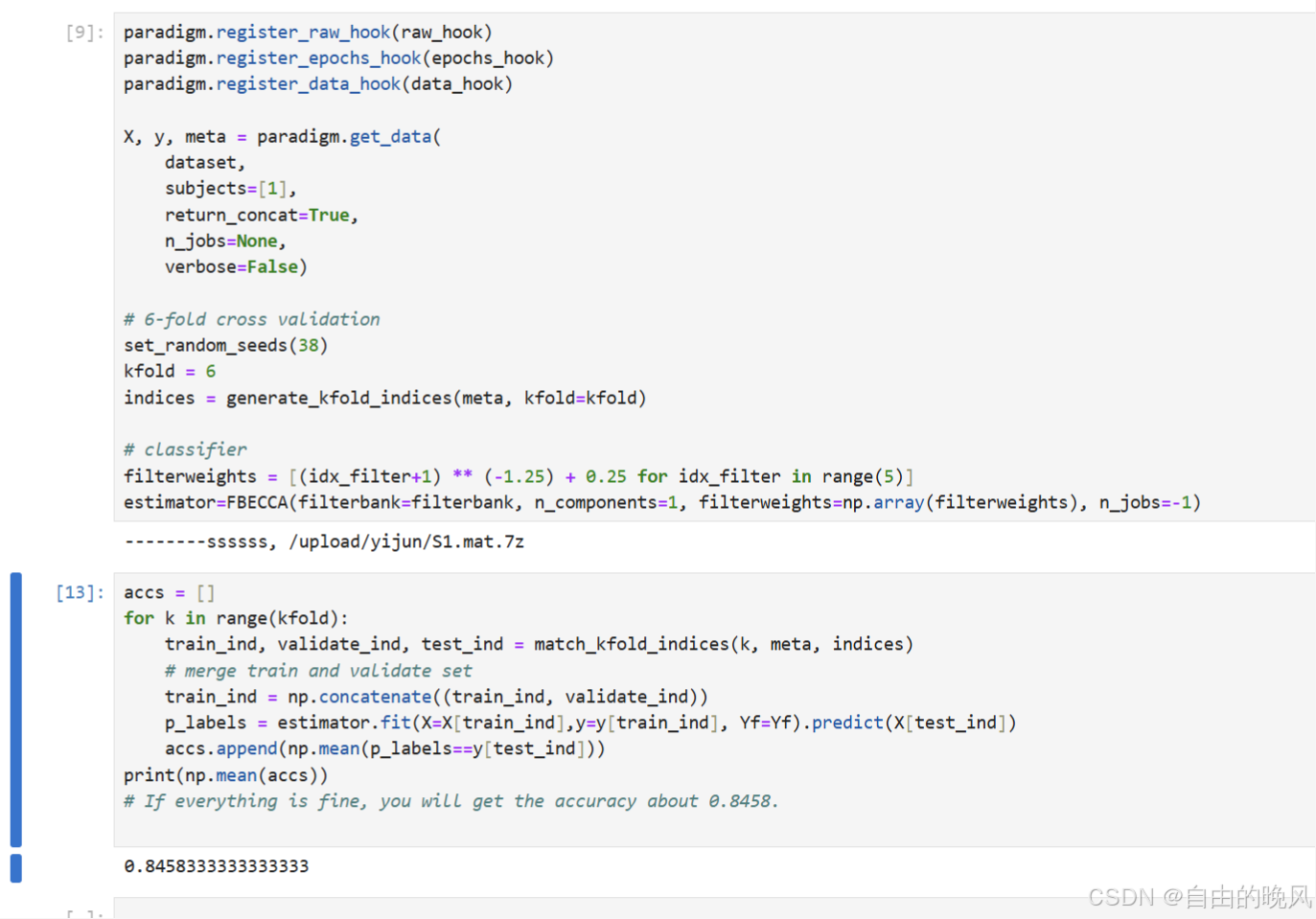
测试用代码,fbcca
import sys
import numpy as np
from metabci.brainda.datasets import Wang2016
from metabci.brainda.paradigms import SSVEP
from metabci.brainda.algorithms.utils.model_selection import (
set_random_seeds,
generate_kfold_indices, match_kfold_indices)
from metabci.brainda.algorithms.decomposition import FBECCA
from metabci.brainda.algorithms.decomposition.base import generate_filterbank, generate_cca_references
wp=[(5,90),(14,90),(22,90),(30,90),(38,90)]
ws=[(3,92),(12,92),(20,92),(28,92),(36,92)]
filterbank = generate_filterbank(wp,ws,srate=250,order=15,rp=0.5)
dataset = Wang2016()
events = dataset.events.keys()
freq_list = [dataset.get_freq(event) for event in events]
Yf = generate_cca_references(freq_list, srate=250, T=0.5,n_harmonics = 5)
paradigm = SSVEP(
channels=['POZ', 'PZ', 'PO3', 'PO5', 'PO4', 'PO6', 'O1', 'OZ', 'O2'],
intervals=[(0.14, 0.64)],
srate=250
)
# add 5-90Hz bandpass filter in raw hook
def raw_hook(raw, caches):
# do something with raw object
raw.filter(5, 90, l_trans_bandwidth=2,h_trans_bandwidth=5,
phase='zero-double')
caches['raw_stage'] = caches.get('raw_stage', -1) + 1
return raw, caches
def epochs_hook(epochs, caches):
# do something with epochs object
# print(epochs.event_id)
caches['epoch_stage'] = caches.get('epoch_stage', -1) + 1
return epochs, caches
def data_hook(X, y, meta, caches):
# retrive caches from the last stage
# print("Raw stage:{},Epochs stage:{}".format(caches['raw_stage'], caches['epoch_stage']))
# do something with X, y, and meta
caches['data_stage'] = caches.get('data_stage', -1) + 1
return X, y, meta, caches
paradigm.register_raw_hook(raw_hook)
paradigm.register_epochs_hook(epochs_hook)
paradigm.register_data_hook(data_hook)
X, y, meta = paradigm.get_data(
dataset,
subjects=[1],
return_concat=True,
n_jobs=None,
verbose=False)
# 6-fold cross validation
set_random_seeds(38)
kfold = 6
indices = generate_kfold_indices(meta, kfold=kfold)
# classifier
filterweights = [(idx_filter+1) ** (-1.25) + 0.25 for idx_filter in range(5)]
estimator=FBECCA(filterbank=filterbank, n_components=1, filterweights=np.array(filterweights), n_jobs=-1)
accs = []
for k in range(kfold):
train_ind, validate_ind, test_ind = match_kfold_indices(k, meta, indices)
# merge train and validate set
train_ind = np.concatenate((train_ind, validate_ind))
p_labels = estimator.fit(X=X[train_ind],y=y[train_ind], Yf=Yf).predict(X[test_ind])
accs.append(np.mean(p_labels==y[test_ind]))
print(np.mean(accs))
# If everything is fine, you will get the accuracy about 0.8458.

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 39
39 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)