
论文阅读TCJA-SNN: Temporal-Channel Joint Attention forSpiking Neural Networks
介绍SNN背景,脉冲神经网络具有生物合理性、低能量消耗、时空信息表达能力。
文章标题:
摘要、背景、贡献
Abstract
Spiking Neural Networks (SNNs) are attracting widespread interest due to their biological plausibility, energy efficiency, and powerful spatio-temporal information representation ability. Given the critical role of attention mechanisms in enhancing neural network performance, the integration of SNNs and attention mechanisms exhibits tremendous potential to deliver energy-efficient and high-performance computing paradigms.
介绍SNN背景,脉冲神经网络具有生物合理性、低能量消耗、时空信息表达能力
In this paper, we present a novel Temporal-Channel Joint Attention mechanism for SNNs, referred to as TCJA-SNN. The proposed TCJA-SNN framework can effectively assess the significance of spike sequence from both spatial and temporal dimensions. More specifically, our essential technical contribution lies on: 1) We employ the squeeze operation to compress the spike stream into an average matrix. Then, we leverage two local attention mechanisms based on efficient 1-D convolutions to facilitate comprehensive feature extraction at the temporal and channel levels independently. 2) We introduce the Cross Convolutional Fusion (CCF) layer as a novel approach to model the inter-dependencies between the temporal and channel scopes.
This layer effectively breaks the independence of these two dimensions and enables the interaction between features. Experimental results demonstrate that the proposed TCJA-SNN outperforms the state-of-the-art on all standard static and neuromorphic datasets, including FashionMNIST, CIFAR10, CIFAR100, CIFAR10-DVS, N-Caltech 101, and DVS128 Gesture. Furthermore, we effectively apply the TCJA-SNN framework to image generation tasks by leveraging a variation autoencoder. To the best of our knowledge, this study is the first instance where the SNN-attention mechanism has been employed for high-level classification and low-level generation tasks.
代码链接:https://github.com/ridgerchu/TCJA.
大背景:
与传统神经网络(ANN)相比,脉冲神经网络(SNN)具有降低的功耗以及较高的鲁棒性。今年来,随着脉冲神经网络的发展,残差模块和批归一化等各种模块不断应用在SNN中,大规模的SNN训练不断开展,并且仍然保持着SNN的二进制尖峰特性已经低的能量消耗。
小背景:
- 尽管取得了重大进展,snn尚未充分利用深度学习优越的表达特征的能力,这主要是由于其独特的训练模式,难以有效地模拟复杂的通道-时间关系。由于SNN在每个时间步长上使用同一个网络参数,所以,SNN在时间和通道的维度上存在着较大的开发潜力。
- 在以往的人工智能研究中,注意力机制非常重要,在SNN中同样是一个重要的发展空间。如下图,Yao等人在时间维度添加了注意力机制,可以评估训练期间帧的重要性,并排除无关帧。仅仅在时间维度添加注意力机制就使得模型性能显著提升。
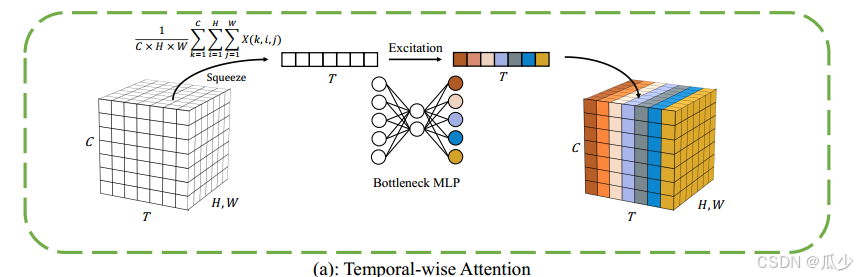
贡献:
本文主要提出一种即用即插的注意力机制模块,如下图所示,本文工作主要分为以下三点:
- 同时考虑时间和通道两个维度,在SNN中引入一个即用即插的注意力机制模块,从而获得更好的生物解释性和适应性。
- 提出一种具有交叉接受域的交叉卷积融合模块(CCF)确保模型能够充分的融合特征信息。不仅可以减少参数量还可以有效的集成时间和通道上面的特征。
- 通过实验证明TCJA-SNN模型在静态和神经形态的数据集上分类任务的精度都要优于其他方法。
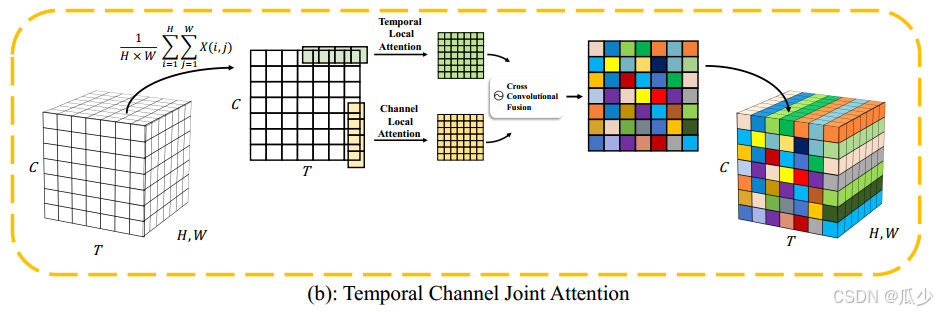
本文方法
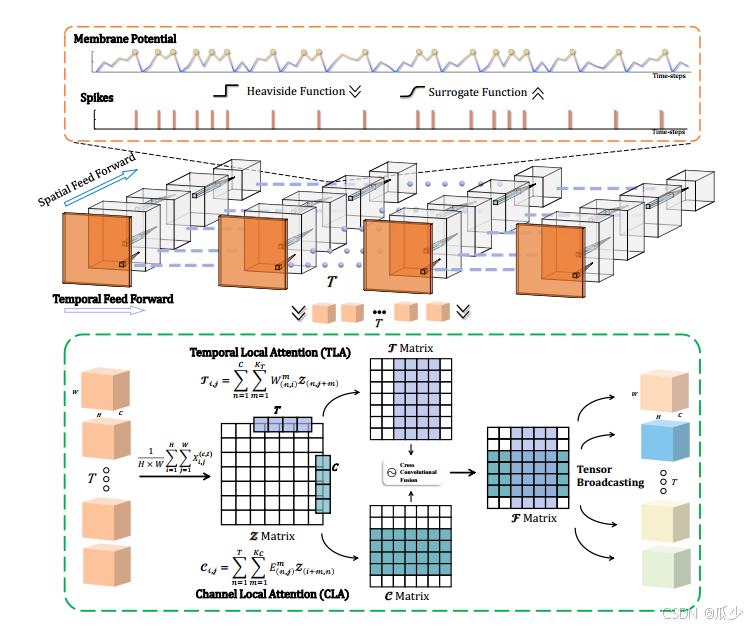
LIF神经元模型
LIF膜电位动力学可以描述为:
其中,为时间常量,
和
分别表示在t时刻的膜电位以及前一个神经元的输入。为了更好的表示计算可追溯性,LIF神经元还可以表示为:
表示第n层神经元在t时刻的膜电位。
为时间常数,
为二值的峰值张量,
为前一层输入,
为Heaviside阶跃函数,
为峰值后的复位过程。本文LIF神经元模型采用代理梯度方法进行训练,训练过程中参数设置为:
。
时间-通道联合注意力机制(TCJA)
本文首先采用全连接来构建注意力机制,但是发现参数量会随着通道数和时间步长呈现的比例增长,随后尝试了使用二维卷积层来构建这种注意力机制,这种方法会将接受域限制在一个区域内。因此,有必要在增加接受野的同时减少参数的数量。
TCJA注意力机制具有交叉感受野的特点,以相对较少的参数()达到有效的效果。下图展示了TCJA注意力机制的整体架构。首先,对输入帧进行压缩操作,然后通过时间注意力机制(TLA)和通道注意力机制(CLA)。最后通过交叉融合机制(CCF)来联合学习时间和通道上的信息。
压缩平均矩阵
为了更好的获得输入帧时间和通道之间的相关性,对输入帧的空间映射执行压缩操作,得到压缩后的矩阵
,计算过程为:
局部时间注意力(TLA)
为获得时间上的相关性,通过一维卷积获得压缩后矩阵每一行的均值,然后累计特征图不同行的卷积均值获得矩阵,具体表示为:
:卷积核的大小,表示卷积考虑时间步数,
:可以学习的权重参数,表示在输入矩阵Z第n行与C个通道进行一维卷积,第i个通道上第m个权重参数,
:表示经过时间局部注意力后的得分矩阵。
局部空间注意力机制(CLA)
在考虑时间维度相邻帧的相关性的同时还要考虑通道维度相邻帧的相关性。对矩阵的每一列进行一维卷积,然后对每一行的卷积结构求和,整个过程可以描述为:
:卷积核的大小
:可以学习的权重参数,表示在输入矩阵Z第n列与T个时间步长进行一维卷积,第j个通道上第m个权重参数
:表示经过空间局部注意力后的得分矩阵。
为了保持输入和输出之间的维度一致性,在TLA和CLA机制中都采用了“相同填充”技术。这种填充策略通过向输入数据添加适当数量的零来确保输出维度与输入维度匹配。具体来说,该技术涉及在输入数组的两边填充零,其中添加的零的数量是根据内核大小和步幅确定的。
交叉卷积融合(CCF)
为了更好的融合通道和时间之间的相关性,本文提出一种快信息域的交叉融合机制(CCF)。CCF目标是为了计算一个融合信息矩阵,用于测量第i个通道和第j个时间之间的潜在相关性。
其中,为Sigmoid函数,下图为整个增强计算过程。
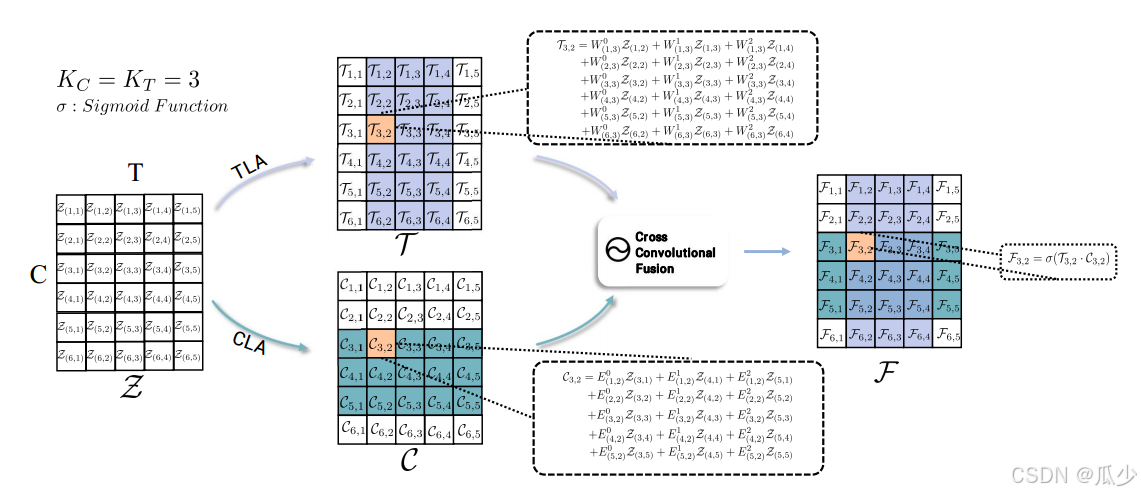
如图所示,设定输入矩阵为(6,5),若要计算
,计算流程如下:
1)通过 TLA 机制计算
;
2)利用 CLA 机制计算;
3)采用 CCF 机制(式 6)联合学习时间和通道信息得到
训练框架
将提出的TCJA模块集成到现有的SNN中,提出TCJA-SNN模型。本文使用推导出的ATan代理函数和类三角函数
,通过反向传播进行训练。实验发现后一种梯度替代函数在TCJA-TET-SNN具有特别的应用。本文使用峰值均方误差作为损失函数,损失函数如下:
其中为时间步长,
为标签数量,
为模型的输出,
为目标标签。同时还使用了时间有效训练(TET)损失,可以表示为:
其中T为模拟的总时间,为交叉熵损失,s为模型的输出,g为标签。交叉熵损失可表示为:
其中M为总的预测数量,为二值指标,
为o属于c类的预测概率。为了能够估计分类精度,将预训练标签
。
实验
数据预处理
本文评估了TCJA-SNN在神经形态数据集(CIFAR10- dvs, N-Caltech 101)和静态数据集(Fashion-MNIST, CIFAR10, CIFAR100)上的性能。并且测试了将TCJA模块集成到其他模型上的性能。
对神经形态数据的预处理集采用常用的集成方法,将事件流转化为帧数据,事件的坐标可以表示为:
其中,和
为事件坐标,
为事件坐标。
为了减少计算消耗,将数据切为T个片,T为模型的时间步长。集成数据中的一帧记为,表示位置
处的像素值,记为
,通过对事件流中的
和
。
为初始累计时间戳,
为最终时间戳。整个过程可以描述为:
其中,为向下取整运算,
是一个指示函数,只有当
时,L=1。这种结构化的数据可以增强SNN模型的兼容性,还可以更好的分析和处理数据。
数据增强
采用神经形态的数据增强来避免过拟合。在每一帧中使用水平翻转和混合(Mixup),翻转概率设置为0.5,Mixup从的贝塔分布中随机采样。然后在Rolling,Rotation,Cutout,Shear中随机选择一个增强。各个增强中的参数设置为:
Rolling:随即滚动范围为5个像素。
Rotation:从α=-15,β=15的均匀分布中采样旋转度。
Cutout:从α=-1,β=8的均匀分布中采样Cutout的边长。
Shear:从α=-8,β=8的均匀分布中采样剪切度。
网络架构
对不同数据集采用的网络架构如下:
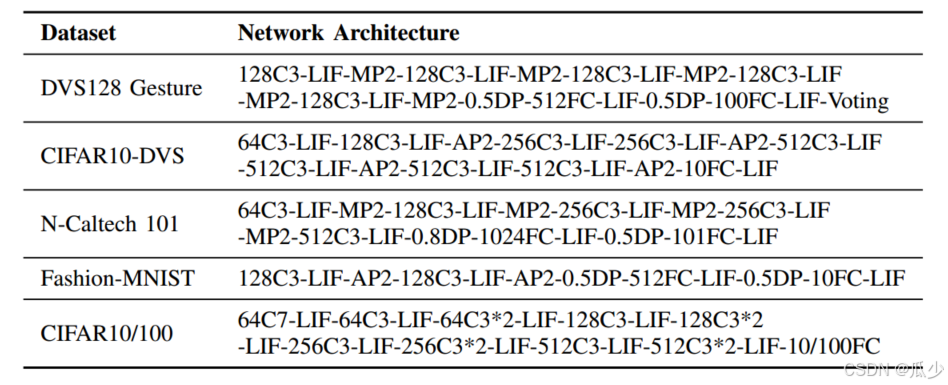
- xCy/MPy/APy为输出通道为 x、核大小为y的CONV2D/MAXPOOLING/AVGPOOLING层
- nFC为输出特征为n的全连通层
- mDP表示DROPOUT率为 m的尖峰退出层
- 投票层为一维平均池化层。
- 对于DVS128数据集,在最后两个池化层之前添加TCJA模块,Dropout设置为0.5,在最后一层添加一个一维的平均池化投票层,产生一个十维矩阵作为输出结果。这是由于DVS128 Gesture的预处理模拟了更长的时间步长(T=20),通过这样一个投票层可以提高模型的鲁棒性。
- 对于DIFAR10-DVS数据集,采用TET中引入类似于VGG11的结构,使用三角形代理函数,消除最后一个LIF层,使用TET损失代替SMSE损失,分别在最后两次池化之前和第一层池化之后添加TCJA注意力机制。
- 对于N-Caltech101数据集,将两个架构组合在一起,并且在最后两个池化层之前添加TCJA模块。首先本文为每一层预留一个池,随着模型加深,空间分辨率随着信道数的增加而降低,为了消除过拟合,将第一层的Dropout比率调整为0.8。
- 对于Fashion-MNIST数据集,采用直接编码,第一层卷积作为一个静态编码层,将静态图像转化为峰值。
- 对于CIFAR10\100,采用MS-ResNet架构建筑TCJA模块的有效性,具体来说是在每个MS-ResNet模块的底部添加TCJA模块。
模型参数各项超参数选择如下:

使用Adam优化器时,学习率调整为,相反使用SGD优化器时,要采用更高的学习率。对于超高分辨率,在N-Caltech101、DVS128中采用自动混合精度。并且分离了反向传播中的重置过程。
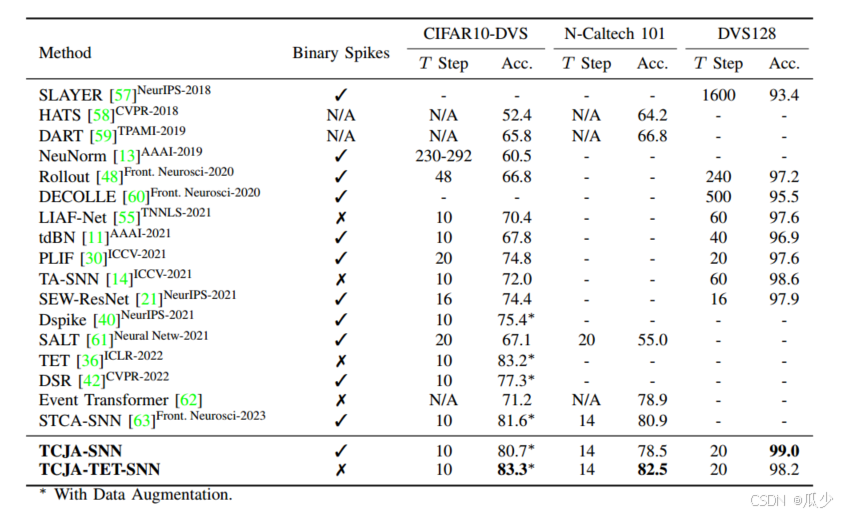
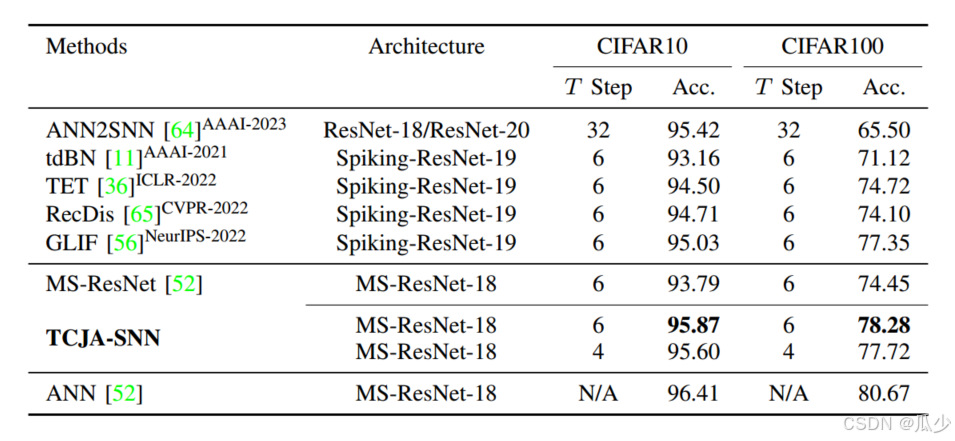
分类结果对比
生成结果对比
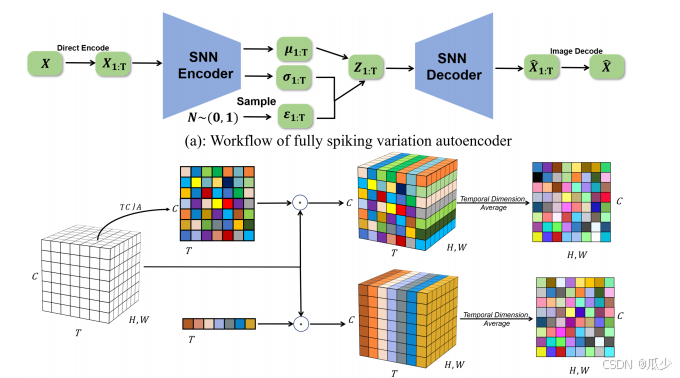
本实验中使用TCJA模块构建了一个用于图像生成的完全脉冲变化自编码器(FSVAE),使用本文提出的方法来替代原有的图像编码方法,将TCJA应用于FSVAE当中。如图所示;
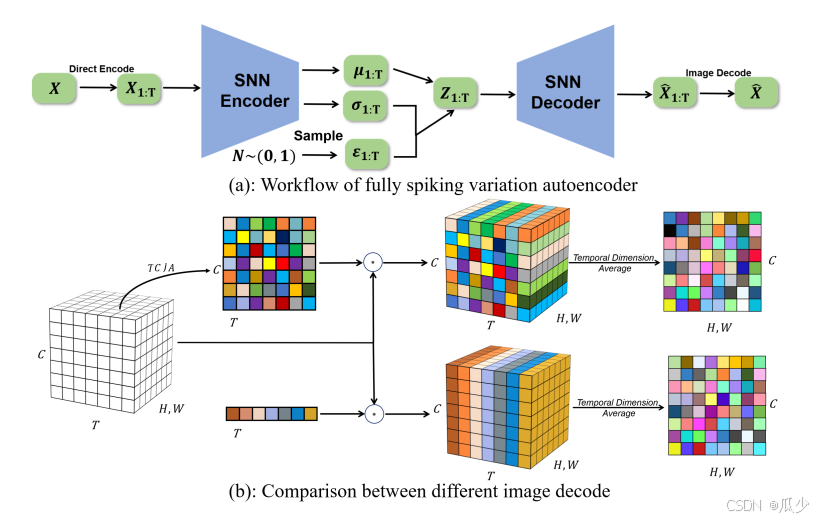
上图展示了FSVAE的体系结构及TCJA在其中的应用。
在输入图像后,被编码为尖峰信号,经过编码后得到特征
,隐编码
随机生成,呈现正太分布。最后通过SNN解码器生成图像。
在生成模型中使用对数似然证据下界损失函数(log-likelihood evidence lower bound,ELBO):
第一项为原始输入与本模型重建输出之间的损失,即均方误差(MSE)。第二项时Kullback-Leibler(KL)散度,表示先验和后验之间的接近程度。
超参数设置:
学习率:0.001(以0.001权重衰减)
epoch:300
bach_size:256
时间步长:16
下表展示了TCJA模型与已有的SOTA模型进行比较,并且采用TCJA模型在指标上展示出的生成效果更好。并且,在图像可视化角度来看,本实验生成的图像要优于以往的方法。此外,还与一些采用其他专用于重建低级图像的带有注意力机制的方法相比,仍处于优势地位。
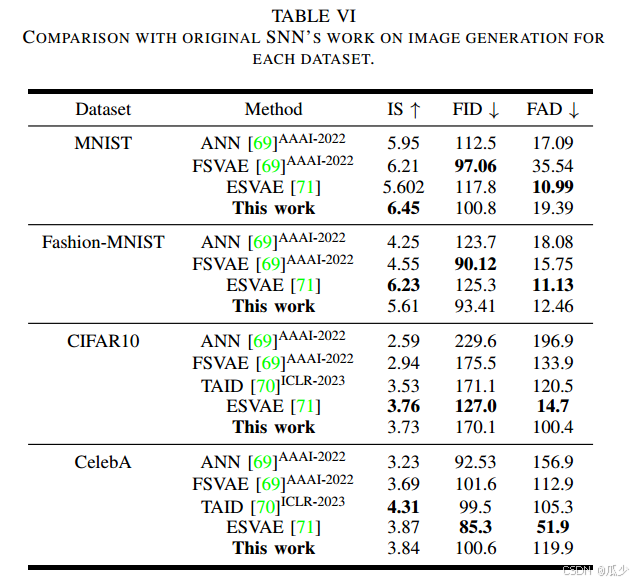

消融实验
为了验证TLA和CLA在实验中的有效性,进行消融实验,下表是实验结果。
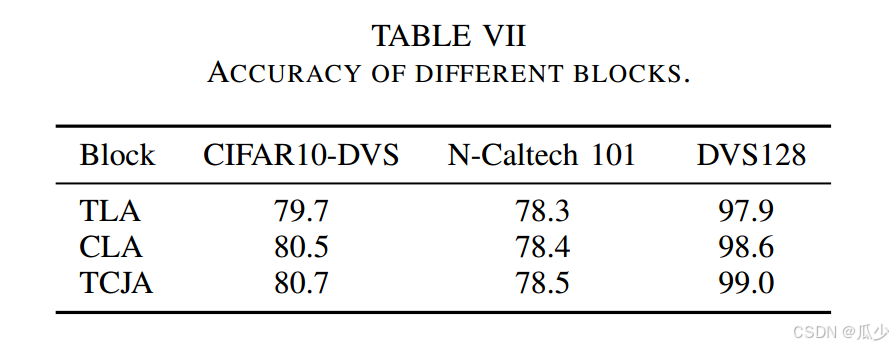
讨论
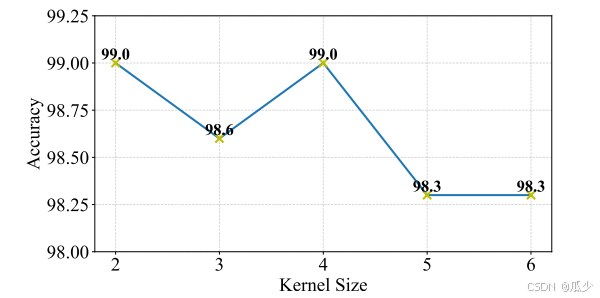
1.卷积核大小
局部注意力机制的接受野并不会随之卷积核的增大而增大,实验结果表明,模型性能会随着卷积核大小增大而波动。当卷积核大小大于4时,总体性能会随之下降。一个合理的解释是一个像素点只与周围的像素点具有相关性,一个较大的接受野会导致模型收到一个不合理的噪声。
2.乘法与加法
为验证本文CCF的有效性,作者设计出一种TCJA的变体,使用加法代替TCJA模块中的乘法。结果如下表所示
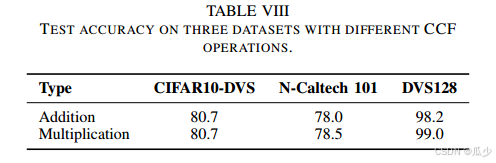
虽然加法也取得了良好的效果,但是与本文结果相比还是处于劣势。这是因为采用加法运算会导致最终结果缺乏交叉项,无法构建帧之间的相关性。
3.收敛性
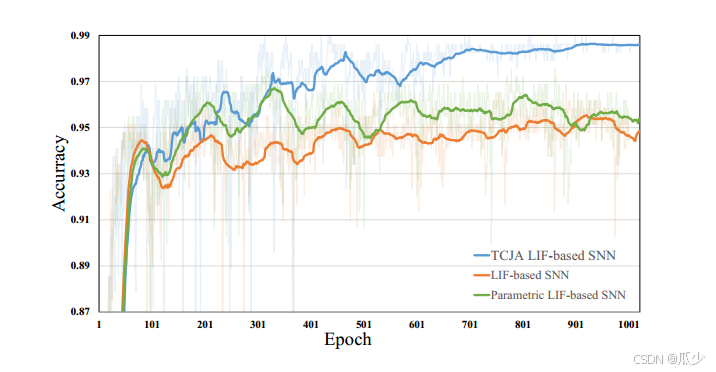
下图为普通SNN、带有参数化LIF神经元的SNN和本文的方法相对比,随着训练周期的增加,模型具有更高的性能。在260左右,本文的方法就已经达到以往先进算法的水平。
4.复杂性分析
本文从TLA和CLA分别来分析时间复杂度。
由上式可知,对于TLA获取每个元素的时间复杂度为,其中K为卷积核的大小,则整个TLA的时间复杂度为
。对于参数方面,对矩阵
进行一维卷积,整个参数量需要
,对于变量方面需要存储一个
的矩阵,所以空间复杂度为
。
分析:上式所示,先遍历整个通道,需要C次运算。然后遍历卷积核大小,需要K次运算。所以,每个元素的时间复杂度为
。而整个TLA的时间复杂度为
。
CLA的时间复杂度和空间复杂度计算方式与TLA相同,时间复杂度为,空间复杂度为
。
5.接受野理论分析
全球接受野是TCJA方法的一个基本特征,以更少的参数来实现全局接受野,从而超越了密集层的限制。通过采取TCJA的模式,使得一维卷积超越了二位卷积的效果。本文提出模型在训练过程中感知和处理信息的特定区域的理论分析,即接受野,来更深入的解释本文的方法。
定理1.(一维卷积的Cross-correlation Scope(CCS))对于输入特图
,如果一维卷积核的大小定义为
,那么其交叉相关范围 (CCS) 可以描述为
,其中
涉及
的第二个维度的信息。
定理2.(两个正交一维卷积的CCS)对于输入特征图
描述(如下图所示),其中
,
,且
和
分别是两个卷积核的大小。
综述两个定理,TCJA可以获得广泛的CCS,T和C存在信息流,可以协同考虑时间和通道之间的相关性。
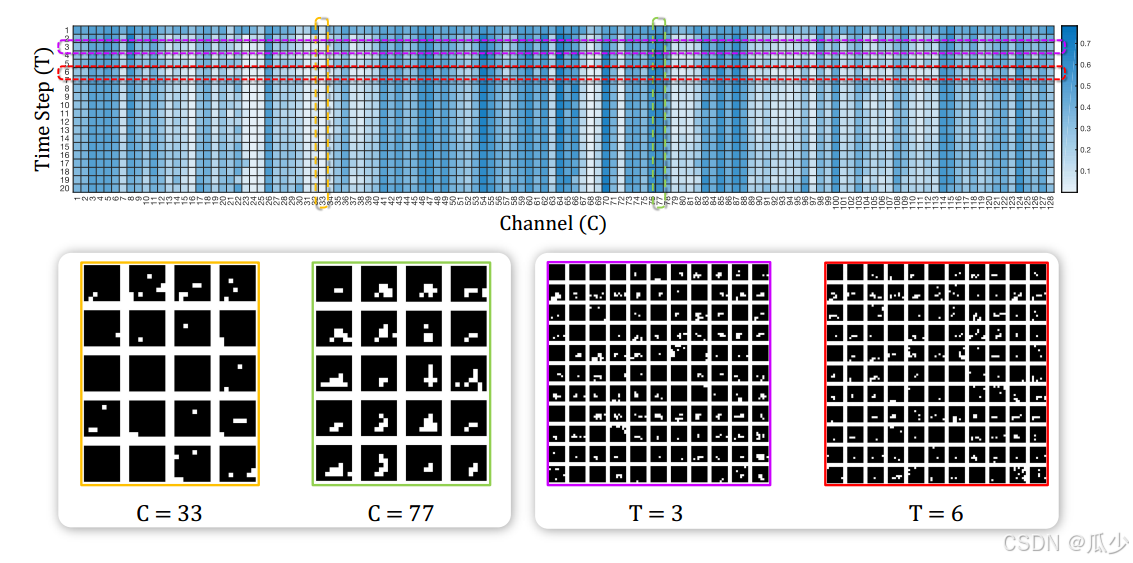
6.注意可视化
为了使注意机制更容易理解,最终将TCJA- snn中第一个TCJA模块在DVS128手势数据集的输出可视化,如下图所示。注意权重的变化主要在通道之间累积,进一步验证了CLA在TCJA模块中发挥的实质性作用。为了体现注意力权重,本文提取了一些时间维度和通道维度的帧。通道维度上的放电模式差异比时间维度上的差异更显著。
7.能耗分析
本文评估了ANN和SNN在DVS128数据集上进行分类所需要的能量消耗。首先评估了SNN模型每层的脉冲率和每秒的浮点运算(FLOPS),结果如下表所示。

ANN模型能耗计算公式:FLOPS × MAC能耗成本(MAC实则为乘加运算)
SNN模型能耗计算公式:FLOPS × 脉冲率 × SNN能耗成本
经过计算得到,TCJA-SNN模型的能耗为J,ANN为
J。ANN模型的能耗大约是TCJA-SNN模型的五倍。表明TCJA-SNN在能耗方面具有明显的优势。
8.传播模式
SNN的正向传播包括时间和空间两个领域,是一个顺序的、逐步的过程。在这一过程中,网络在初始时间步的输出首先被评估,同时更新脉冲神经元的隐状态。接下来的时间步以类似的方式进行评估,保持这种顺序。这意味着网络仅在处理一个时间步后再进入下一个时间步。除了顺序步骤模式,还可以使用层级传播模式。在该模式下,首先在所有时间步中计算第一层的输出,然后将其作为第二层的输入,最终获取最后一层在所有时间步的输出。在GPU等并行计算环境中,层级传播模式更为常见,而在神经形态设备上,更倾向于使用逐步处理模式。这是因为神经形态设备的运作方式更适合串行处理。
在TCJA中,网络是通过层级传播模式进行训练的。但无论如何,当在逐步模式下应用卷积结构时,仍然能够得到一些好处。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)