【论文笔记】Du-IN: Discrete units-guided mask modeling for decoding speech... (NeurIPS 2024)
本文提出了一种新的脑机接口技术,使用立体脑电图(sEEG)来解码语音,这是一种侵入性较小的方法。研究者们收集了一个中文单词阅读的sEEG数据集,并开发了Du-IN模型,该模型通过**区域级别的上下文嵌入**来提高语音解码的性能。Du-IN模型在单词分类任务上超越了所有基线模型,**基于区域级别标记的时间建模和自监督的离散码本引导掩码建模等设计对性能有显著贡献**。这种方法基于神经科学发现,利用特定

Code:https://github.com/liulab-repository/Du-IN
Data (仅下游数据,无预训练数据): https://huggingface.co/datasets/liulab-repository/Du-IN
Abstract
本文提出了一种新的脑机接口技术,使用立体脑电图(sEEG)来解码语音,这是一种侵入性较小的方法。研究者们收集了一个中文单词阅读的sEEG数据集,并开发了Du-IN模型,该模型通过区域级别的上下文嵌入来提高语音解码的性能。Du-IN模型在单词分类任务上超越了所有基线模型,基于区域级别标记的时间建模和自监督的离散码本引导掩码建模等设计对性能有显著贡献。这种方法基于神经科学发现,利用特定脑区的区域级别表示,适合于侵入性脑建模,并在脑机接口领域展现出神经启发式AI方法的潜力。代码和部分数据集可在GitHub上获取。
Introduction
- 背景:现有研究建模神经信号主要基于两种建模单元(通道级tokens和集群级tokens)。前者重点将单个通道建模为tokens并且共享相同的embedding,而忽略了大脑计算的特殊性;后者综合所有通道去建模全脑级别的tokens,但忽视了大脑的去同步性。
- 动机:在医学实验中大规模标记数据通常不切实际或成本高昂,因此,利用先前的神经科学发现开发一个有效的预训练框架非常有吸引力,因为它可以充分利用丰富的未标记数据。
- 挑战:
- 时间尺度:由于颅内神经信号具有高时间分辨率和信噪比,因此建模的tokens必须捕获大脑活动的快速动态变化。
- 空间尺度:考虑到大脑的去同步性质,这些tokens应该正确捕获每个大脑区域的信息,以便进一步整合。
- 贡献:
- 一个注释良好的中文阅读字词的 sEEG 数据集,解决 sEEG 语言数据集的匮乏问题。该数据集已公开:https://huggingface.co/datasets/liulab-repository/Du-IN
- 只需要特定脑区的约一整根sEEG电极即可实现最佳解码性能。
- 一种新颖的 sEEG 语音解码框架——Du-IN,它通过离散CodeBook引导的掩码建模来学习区域级上下文embeddings。
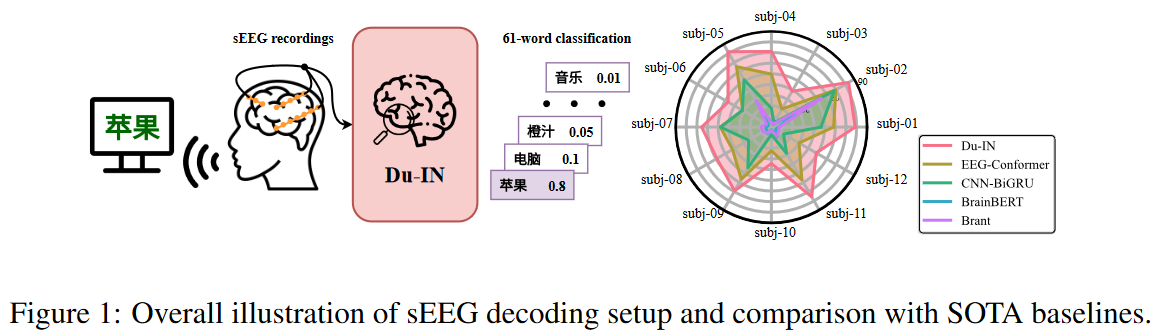
- Du-IN 在 61 词分类任务上实现了 62.70% 的 top-1 准确率,超越了所有其他baselines。
Related Works
Language Decoding in BCI
- 侵入式神经信号在语音解码领域潜力巨大
- 神经-语言的表征模型也是关键:自监督或者与其他模态对齐的预训练方式
- BrainBERT 通过自我监督的掩码建模来学习一般embeddings。
- DeWave 引入了离散CodeBook编码,并将神经表示与 BART 中的文本embeddings对齐,从而增强了从 EEG 记录中提取语义处理相关信息。
- Metzger等人将神经表征与声学的离散embeddings相结合,以改进从 ECoG 信号中提取与发声相关的信息。
Self-supervised Learning in BCI
- BrainBERT(用于 sEEG)将单个通道嵌入到通道级tokens中,并利用掩码建模来学习一般表征。
- Brant(针对 sEEG)、PopT(针对 sEEG)等工作进一步采用时空整合模型来建模它们之间的空间关系。
- 其他一些工作融合所有通道(整个大脑)来构建大脑级别的tokens,并使用自监督学习来学习上下文表征。
- 考虑到不同脑区,MMM(用于 EEG)进一步将通道分为不同的组以构建区域级令牌。
Method
Du-IN Encoder

用于 sEEG 语音解码任务的通用架构,可以处理任意时间长度的任何输入 sEEG 信号:
- sEEG信号patch化:对于每个样本 X ,使用一个没有重叠的 W 长度窗口将其分割成等长的patches,总个数为T
- Spatial Encoder:采用一个由线性投影和几个卷积块组成的空间编码器,将每个 sEEG 块编码为块状embeddings
- Temporal Embedding:为了使模型能够了解patches的embedding的时序信息,利用可学习的Temporal Embedding与上一步的embedings加权
- Transformer Encoder:embeding序列直接输入Transformer编码器获得最终编码。
Du-IN VQ-VAE Training

在通过掩码建模预训练 Du-IN 之前,需要先将 sEEG patches标记为离散tokens。作者引入了矢量量化神经信号回归模型(即VQVAE),它通过重建原始 sEEG 信号进行训练得到离散化tokens。
- Du-IN VQ-VAE:主要由一个 Du-IN Encoder + vector quantizer + Du-IN Regressor 组成
- Loss:重构误差 + CodeBook更新误差

Pre-training Du-IN
基于BERT的掩码建模预训练的方式,从神经信号中预测对应的离散tokens。
Results
Dataset
12个被试(每人72-158通道),分别包括12小时任务无关记录,以及3小时的阅读任务记录(61个中文字词)。
Implementation Details
- Pre-training:无特别指定时,对于每个被试单独进行模型的预训练和微调
- Fine-tuning:使用预训练好的 Du-IN Encoder 参数初始化新的 encoder 用于微调去解码
Channel Contribution and Selection
鉴于植入的 sEEG 电极分布稀疏(每个电极包含 8-16 个通道),排除与发声无关的冗余电极至关重要,从而提高解码性能。作者保留植入相关大脑区域的电极,并根据剩余电极评估性能。表 1 表明,排除大约 85% 的电极甚至会导致解码性能显着提高。
Comparasion with Other Models
如表2所示,Du-IN 模型性能最高。值得注意的是,采用时空整合来建模通道级tokens之间的空间关系的模型(即为大脑信号设计的基础模型)比采用基于区域级tokens的时间建模的模型表现更差。

对以上的结果,本人表示存疑:
- 作者提到sEEG通常需要双极重新参考(或拉普拉斯重新参考)来消除通道之间的高相关性,从而避免模型过度拟合。一旦通道之间的相关性被消除,Brant等方法将失去对通道之间的空间关系进行建模的能力,从而导致性能非常低。
- 这里比较的大部分方法都是针对EEG特别设计的,可能并不适合sEEG数据。
- 对于这个下游任务而言,61分类问题本身并不复杂,但没有给出非深度学习的方法进行对比我觉得不太合理。有可能简单的线性分类如SVM或者LDA都可以有3-40的分类精度。
- Du-IN 即使不经过预训练的性能也有56,轻松领先最高 SOTA 7个百分点,且Neuro-BERT还需要预训练,而比不需要预训练的EEG-Conformer领先11个点。这很难不让人怀疑其他SOTA模型是否性能已经调优。
- Du-IN 的预训练框架在下游数据的4倍数据上进行预训练最高只有6个点的提升,再加上本身不经过预训练的高性能,给人的感觉是预训练在这里显得鸡肋。因为直接训练就可以吊打所有其他SOTA。
Ablation Study
-
Self-Supervision Initialization:如表2所示,包含多种 Du-IN encoder 的不同初始化方式用于下游任务分类
- Du-IN:原始 Du-IN 分类模型。该模型的所有权重都是随机初始化的。
- Du-IN (vqvae+vq):Du-IN Encoder 的权重从预训练的Du-IN VQ-VAE中加载,并且包含 "Vector Quantizer”。
- Du-IN (vqvae):权重从预训练的 Du-IN VQ-VAE 中加载。
- Du-IN (mae):权重从预训练的 Du-IN MAE 中加载。
- Du-IN (poms):权重是从 Du-IN MAE 加载的,该 MAE 在多个受试者上进行了预训练。具体地,对 Du-IN VQ-VAE 和 Du-IN MAE 进行修改以支持跨被试预训练,包括**(1)为不同被试初始化不同的空间编码器以及(2)共享相同的Transformer编码器和神经tokens**。
-
Pre-training with/without Downstream Datasets:在预训练阶段,作者希望 Du-IN VQ-VAE 模型能够提取该大脑区域的通用标记,从而指导 Du-IN MAE 模型学习不特定于任何特定任务的通用表征。虽然预训练阶段没有使用标签数据,但为了消除预训练数据对下游任务的影响,作者比较了将下游任务数据集纳入预训练阶段和未纳入下游任务数据集的结果。表 3 显示排除下游数据集时性能略有下降,但性能仍显著高于其他 SOTA。

-
Discrete Codex:根据不同的CodeBook大小(512 到 8192)以及维度评估性能。
-
Perception Time Window:对不同感受野进行了消融研究,100ms性能最高。

Conclusion
- 一个更有趣但更困难的任务是从 语义层面 解码语言,其中大型语言模型已被广泛使用来提高模型性能。
- 本文提出了一个名为Du-IN的语音解码框架,它通过在特定脑区进行离散码本引导的掩码建模来学习上下文嵌入。为了评估模型,研究者收集了一个标注良好的中文单词阅读sEEG数据集,以解决sEEG语言数据集的缺乏问题。受神经科学发现的启发,他们分析了语音解码的有效脑区,并在特定脑区使用大约一个电极实现了最佳的解码性能,这与过去关于语言的神经科学研究相吻合。全面的实验表明,Du-IN模型超越了监督学习和基于sEEG的自监督基线,有效地捕捉了特定脑区内的复杂动态。这标志着在脑机接口领域,神经启发式AI方法的一个有前景的方向。最后,研究者希望他们的工作能对未来基于sEEG的自监督模型的发展产生影响,特别是在如何构建基本表示单元以便模型能从预训练阶段获得最大收益方面。
Appendix
Experiment Design

Data Augmentation
- Pre-training Dataset:将 sEEG 记录分割成 8 秒的样本,其中有 4 秒的重叠。获取样本时,随机选择0到4秒之间的起点,然后从该点开始提取4秒的样本。
- Downstream Dataset:将 sEEG 记录分割成 3 秒的样本。获取样本时,随机选择 0 到 0.3 秒之间的移动步长,然后将样本向左或向右移动,并用零填充。
Visualization of Mask sEEG Modeling
掩码建模损失稳定下降,精度最终达到约20%:

Effectiveness of Region-Specific Channel Selection
只有在特定区域的通道选择之后,Du-IN VQ-VAE模型才能成功重建原始信号,从而识别大脑区域的细粒度状态:

Subject-Wise Evaluation
表 10、表 11 和表 12 提供了每个受试者不同方法的详细性能,其中最好的以粗体显示,第二个以下划线显示。



Effectiveness of Vector-Quantized Neural Signal Prediction
为了验证矢量量化神经信号预测的有效性,详细说明了两种类型的实验设置,如表 13 所示:

Ablation on Mask Ratio

Ablation on Pre-training Epochs
无预训练时性能为56,预训练5-10 epochs时性能下降,表明预训练本质上为模型找到了一个稍微好一点的初始化局部最优点:


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)