“MUSER: A MUlti-Step Evidence Retrieval Enhancement Framework for Fake News Detection” 论文阅读
个人难以区分社交媒体上泛滥的假新闻的真伪,假新闻的爆炸式增长对社会稳定构成了重大威胁。为了减轻假新闻传播的后果,及时在社交平台上识别它们至关重要。本文受脑科学的启发,提出了一个通过多步骤证据检索增强的假新闻推理框架。本文模型能够通过维基百科自动检索现有证据,进行证据收集,并通过多步骤检索捕捉证据之间的依赖关系。该框架模拟人类在阅读新闻、总结、查阅资料以及推断新闻是否真实的过程中所经历的步骤。模型可
英文名称: MUSER: A MUlti-Step Evidence Retrieval Enhancement Framework for Fake News Detection
中文名称: MUSER: 一种用于假新闻检测的多步骤证据检索增强框架
文章: https://dl.acm.org/doi/pdf/10.1145/3580305.3599873
作者: Hao Liao, Jiahao Peng, Zhanyi Huang, Wei Zhang, Guanghua Li, Kai Shu, Xing Xie
日期: 2023-08-04
研究背景
假新闻的爆炸式增长对社会稳定构成了重大威胁,但仅凭个人很难区分社交媒体上新闻的真伪。为了减轻假新闻传播的后果,需要在社交平台上及时识别它们。
随着新闻数据量的增加,数据的多样性和复杂性使得手人工验证成为一项费时且无法扩展的过程。面对这些挑战,自动化假新闻检测逐渐引起了广泛关注。
研究现状
现有假新闻检测方法可以分为以下三类:
1)基于内容的方法:
基于内容的方法利用新闻文本、写作风格或关于新闻实体的外部知识来区分真实新闻和伪造新闻。
有研究通过提取新闻文本特征来检测假新闻。例如,n-gram分布、利用语言查询、Word计数(LIWC)特征、基于修辞结构理论(RST)的句子关系。
基于风格特征的方法通过捕捉假新闻文本内容中常见的特定写作风格和情感来区分真假新闻。
有研究通过将新闻知识与知识图谱中的知识实体进行比较,直接评估新闻的真实性。
基于内容的方法通常用于假新闻的早期检测,以在新闻传播的早期阶段遏制谣言的扩散传播。
这些方法虽然有效,但也表现出一些局限性:假新闻往往在文本特征上与真实新闻相似,且缺乏重要信息,如社会背景。
2)基于社会背景的方法;
社交媒体在假新闻检测中起着重要作用,可以通过整合社交平台上的上下文信息(如用户特征、评论和立场等),来提高假新闻检测的性能。
基于社会背景信息的方法需要大量的社会背景数据,存在检测的时间延迟问题,无法及时遏制假新闻的传播。而且该方法还面临着用户隐私保护的挑战。
3)基于证据的方法:
近年来的研究工作越来越多地集中在基于证据检索的假新闻检测方法上,这种方法将假新闻检测视为一个推理过程,在该过程中利用外部证据审查新闻文章中声明的真实性。通过提取和整合相关证据信息进行声明验证,计算新闻中的证据与声明之间的文本一致性。即通过搜索维基百科或事实核查网站新闻中的声明,利用声明-证据对的语义相似性(或冲突)来判断新闻的真实性。这种方法提高了虚假新闻检测的可靠性和可解释性。早期研究方法使用序列模型嵌入语义,并应用注意力机制捕捉声明-证据的语义关系。例如,DeClare利用BiLSTM嵌入证据语义,并通过注意力交互机制计算证据得分。MAC提出了结合词注意力和证据注意力的多层多头注意网络来检测假新闻。GET将声明-证据建模为图结构数据,首次提出了基于证据图的统一假新闻检测方法。基于证据验证的方法能够揭示声明中的虚假部分,为用户提供辨别真伪新闻的证据,从而提高假新闻检测的可解释性。
但基于证据的检测方法假设证据很容易获取,忽略了收集证据所需的大量人工工作。
尽管有效,上述方法都假设新闻中声明的证据已然存在,但在实际过程中,证据的收集和整理往往需要大量的手动操作。此外,现有的研究尚未充分探讨证据中的复杂的、远程的语义依赖关系,忽视了信息之间错综复杂的关系。
本文方法
不同于上述研究,本文受脑科学的启发,提出了一个通过多步骤证据检索增强的假新闻推理框架。本文模型能够通过维基百科自动检索现有证据,进行证据收集,并通过多步骤检索捕捉证据之间的依赖关系。
本文提出的假新闻推理框架——多步骤证据检索框架(MUSER),引入了数据挖掘和机器学习技术来检测假新闻。该框架模拟人类在阅读新闻、总结、查阅资料以及推断新闻是否真实的过程中所经历的步骤。模型可以显式地建模多项证据之间的依赖关系,并通过多步检索进行新闻验证所需证据的多步骤关联。此外,模型能够通过段落检索和关键证据选择自动收集现有证据,从而节省繁琐的手动证据收集过程。
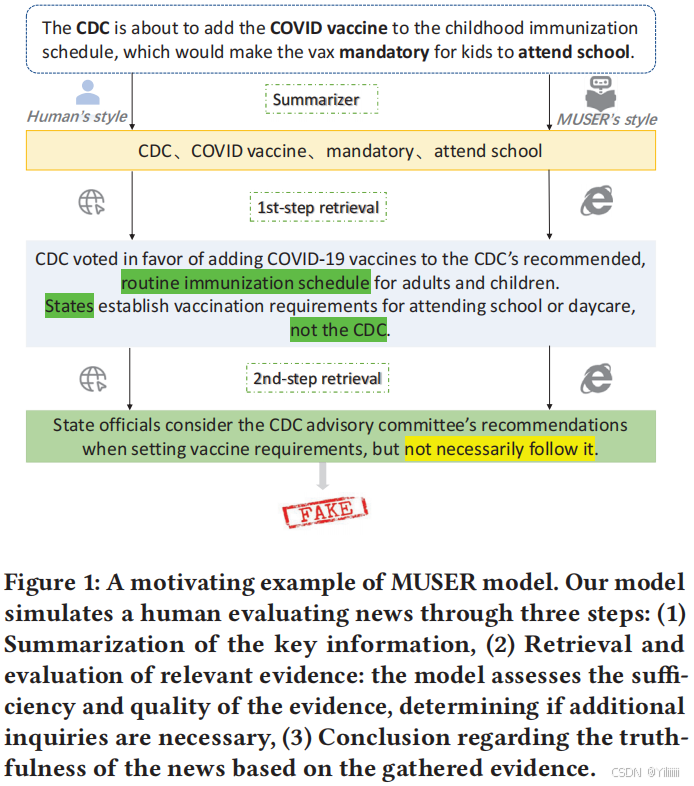
人类在新闻消费时涉及的认知过程通常包含三个步骤,如上图所示:
首先,对文本中的关键发现或声明进行总结;
其次,寻找并评估支持声明的证据,这些证据可能包括网站数据、官方实验或研究;
最后,根据评估过的证据得出结论。
通过遵循这些步骤,就能明确信息来源、使用的证据、证据质量及其局限性,从而帮助做出关于信息有效性的明智判断。
MUSER通过段落检索和关键证据选择,自动从维基百科中检索现有证据,消除了手动证据收集的需求。新闻验证所需的证据通过多步骤检索进行关联。此外,模型能够在不依赖社会背景信息的情况下进行早期检测,并通过检索到的证据为新闻真实性提供依据。
主要贡献
• 提出了一种基于多步骤证据检索的自动化假新闻检测事实核查框架,能够显式地建模多个证据之间的依赖关系,并通过多步骤检索获取新闻验证所需的证据。该框架模拟了人们在互联网上验证新闻内容时的搜索行为,计算机和人类专家在假新闻检测中的差距得以缩小。
• 提出的模型实现包括三个核心模块:文本摘要、多步骤检索和文本推理。在多步骤检索模块中,采用关键证据选择的方法来控制跳跃次数,实现自适应的检索步长控制。
• 在三个真实数据集上进行了广泛实验,结果表明,与最先进的模型相比,模型在提高可解释性和良好性能方面具有有效性。
相关工作
检索增强
最近的研究表明,检索附加信息可以提高多种下游任务的性能。这些任务包括开放域问答、事实核查、事实补全、长篇问答、维基百科文章生成和对话。在经典且最简单的事实核查形式中,使用声明作为查询条件,获取验证声明所需的𝑘个相关段落𝐾𝑆 = {𝑃1, 𝑃2,...,𝑃|𝐾𝑆|}。证据可能包含在一个段落中,甚至在一个句子中。通过给定查询𝑄检索多个相关段落𝑃𝑖 ∈ 𝐾𝑆,并让阅读理解模型从𝑃𝑖中提取答案。
以上这些研究都使用了单步搜索。与单步检索的情况相反,对于某些类型的查询,使用单次检索无法获得证据,需要多次迭代查询。文中称这种多次迭代信息检索的能力为多步骤检索。在多步骤检索中,需要利用前一次搜索的附加信息获取证据,否则可能会因为初步查询不完全相关而找不到证据。本文将多步骤检索的能力扩展到假新闻声明验证中,通过迭代检索的方式查询相关的证据段落。
自然语言推理(NLI)
给定一个声明和选定的证据句子,NLI的任务是预测它们的关系标签𝑦。随着大规模标注数据集的出现(如SNLI、CreditAssess、FEVER),许多不同的神经网络NLI模型得到了发展,促进了该任务的模型开发。与自然语言推理相关的事实验证任务旨在将从维基百科中提取的声明和证据对分类为三种类型:蕴涵、矛盾或中立。NSMN使用了一个由三个同质神经语义匹配模型组成的连接系统,共同执行文档检索、句子选择和声明验证,以完成事实提取和验证。Soleimani等人使用BERT模型检索和验证声明。随着图神经网络的普及,基于图的模型也被用于语义推理。EVIN提出了一种证据推理网络,通过提取声明的核心语义冲突作为证据来解释验证结果。本文研究与之前的工作不同,重点是通过全面检查相关证据,将新闻声明分类为真实或虚假。
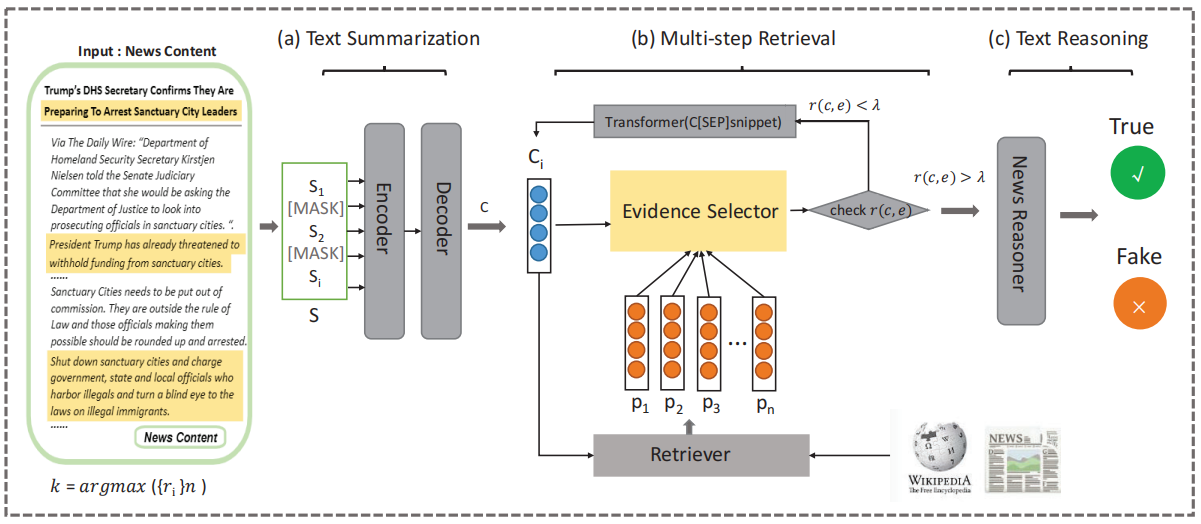
方法实现
问题陈述
本文基于证据检索增强来定义假新闻检测问题,将假新闻的检测过程类比于人类验证新闻真实性的过程。具体来说,首先阅读新闻内容并总结新闻中表达的关键信息(内容摘要);然后基于摘要分多步检索证据(多步检索);最后推断新闻的真实性(自然语言推理)。
问题定义如下:
输入仅为新闻文本 A,然后通过文本摘要模块获取新闻关键陈述 C。通过 C 在维基百科中检索相关段落,得到 ![]() ,随后进行证据提取,获得
,随后进行证据提取,获得 。输出是新闻真实性的预测概率
![]() ,其中 f 是自然语言推理验证模型。而
,其中 f 是自然语言推理验证模型。而 ![]() 表示二分类标签。在此语境下,
表示二分类标签。在此语境下,![]() 表示假新闻,
表示假新闻,![]() 表示真实新闻。
表示真实新闻。
模型提出
下图展示了MUSER的整体架构,模型主要由三个模块组成: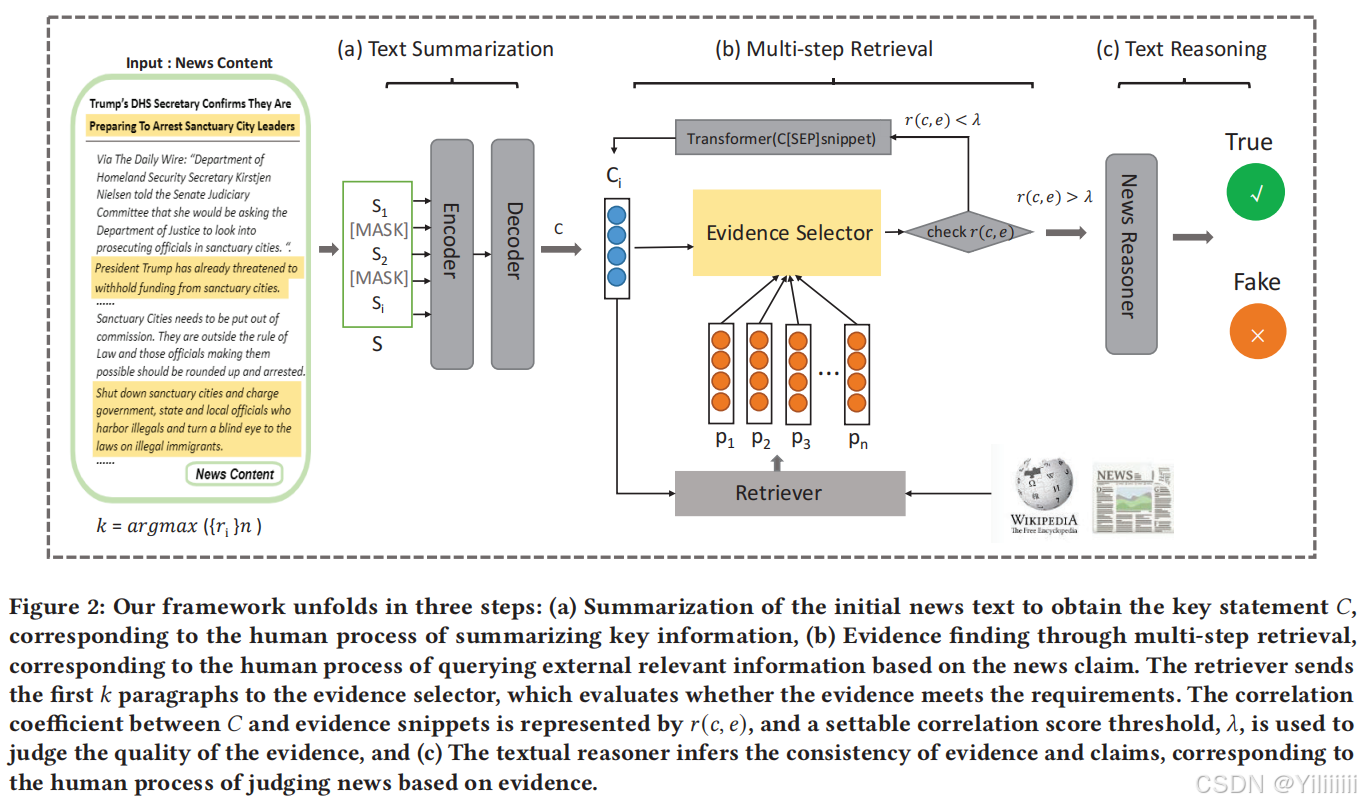
第1部分:文本摘要模块
该模块模拟人类阅读新闻并总结关键信息的行为,提取新闻中的关键信息,过滤掉冗余或不重要的信息干扰。
第2部分:多步检索模块
该模块模拟人类针对新闻陈述查询外部相关信息的行为,将检索模块集成到模型中。
为了解决初始检索的段落可能不包含答案的情况,本文采用了一种多步迭代检索方法。此过程通过关键信息和当前查询向量更新查询向量,随后检索模块利用更新后的查询向量进行再次检索,从而实现对相关证据的更深入探索。
第3部分:文本推理模块
该模块模拟人类根据查询到的补充信息判断新闻真伪的行为,能够提取新闻陈述与证据之间的语义联系,并将新闻分类为真实新闻或假新闻。通过证据检索增强的方法,提高了假新闻检测的可解释性,从而减少了人工证据提取的繁琐过程。
以上三个模块的细节实现如下:
文本摘要模块
在阅读新闻文章时,人们通常会总结其中传达的核心内容。为了模拟人类总结新闻信息的能力,本文首先预训练了一个文本摘要模块。该模块的目标是提取新闻中的关键信息,即提取值得核实的陈述。
尽管预训练语言模型(如BERT 和 UniLM )在自然语言处理(NLP)场景中取得了显著成果,但这些模型中使用的单词和子词掩码语言模型可能不适用于生成式文本摘要任务。这是因为摘要任务需要较粗粒度的语义理解,例如句子和段落语义层次的理解,以生成有效摘要。
受近期在掩码单词和连续片段方面成功经验的启发,本文在一个大型文本语料库上预训练了一个基于Transformer的编码器-解码器模型,用于新闻摘要生成。为了充分利用大规模文本语料进行预训练,文章中设计了一个序列到序列的自监督目标,而非抽象摘要。从新闻文本中掩码句子,并根据剩余句子生成输出序列,以提取新闻摘要。为了增强生成摘要的相关性,选择对新闻重要或核心的句子进行掩码操作。
一篇新闻 A 包含多个句子,即 ,其中 N 为句子数。根据重要性选出得分最高的 m 个句子组成集合 S。作为重要性的代理指标,计算句子与新闻其余部分之间的ROUGE1-F1 分数:
![]()
其中,表示剩余句子,S 初始为空集。
ROUGE-1 F1 是一种评估文本生成质量的指标,用于衡量生成文本与参考文本之间的单词级别重叠情况。具体来说,它基于unigram 的匹配情况来计算 F1 分数,综合了精确度(Precision)和召回率(Recall)两方面的表现。
然后根据重要性分数 选择重要句子:
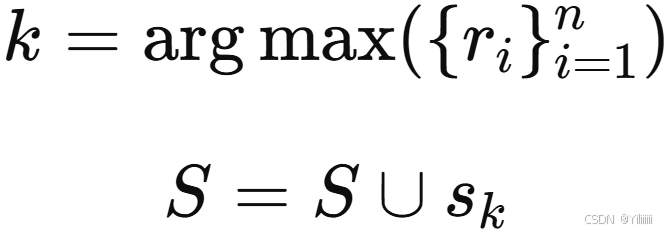
每次选择的句子对应位置被替换为掩码标记 [MASK] 以提示模型。在完成 m 次选择后,从文档中选择被掩码的 m 个句子,并将这些句子连接成伪摘要。随后模块从剩余句子生成输出序列,预测被掩码的句子。
掩码句子比例(Mask Sentence Ratio, MSR)是指所选间隔句子数与文档总句子数的比例,是一个重要的超参数,类似于其他工作中的掩码率 。较低的MSR降低了预训练的难度和计算成本,而较高的MSR会丢失生成指导所需的上下文信息。实验中发现30%的MSR表现较为有效。
多步检索模块
该模块旨在基于前一步提取的新闻关键信息进行增强检索,模拟人类查阅数据以获取补充信息,从而辅助判断新闻的真伪。单步检索可能导致辅助信息不足,因此采用多步迭代检索方法以提高信息的充分性。通过迭代检索与补充,可更全面地提取相关信息,从而更好地辅助新闻真实性的判断。在实现该模块时,重点考虑如何有效提取检索到的关键信息以及在多步迭代检索过程中如何保持信息的充分性。
多步检索问题分为以下三个步骤:
- 使用新闻声明 C 从维基百科语料库中检索相关段落 P。
- 从检索到的长段落中提取证据,并抽取段落中的关键证据。
- 当在当前检索的段落中未发现证据时,将本次检索到的信息与声明 C 融合生成新声明,并进行迭代检索。当在检索片段中找到证据时,搜索终止。
段落检索:段落检索旨在从维基百科中选择与给定声明相关的段落。段落检索模块基于 BERT,通过计算每个段落的平均 token 嵌入来生成稠密向量。段落 p 与声明 c 的相关性由其点积计算:
![]()
其中![]() 是一个嵌入函数,用于将段落和声明映射为稠密向量。点积搜索可利用 FAISS 库的近似最近邻索引实现检索效率的提升。
是一个嵌入函数,用于将段落和声明映射为稠密向量。点积搜索可利用 FAISS 库的近似最近邻索引实现检索效率的提升。
对于嵌入函数![]() ,使用经过多任务微调的 BERT-base 语言模型计算段落 p 的平均 token 嵌入:
,使用经过多任务微调的 BERT-base 语言模型计算段落 p 的平均 token 嵌入:
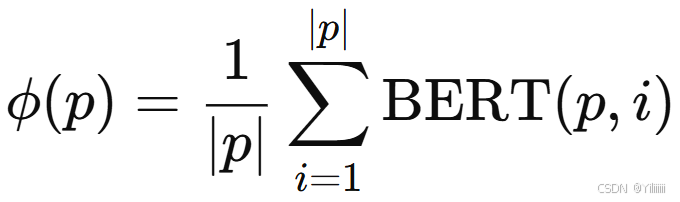
其中 是段落 p 中 第 i 个token 的嵌入,
是段落 p 的 token 数。
关键证据选择:关键证据选择旨在从检索到的相关段落中提取与证据相关的关键句子。类似于段落检索,句子选择也可以视为语义匹配任务,其中每段的句子与给定声明进行对比,以识别最可能的证据内容。由于搜索空间通过前一步的段落检索已缩小至可控大小,可以直接遍历所有相关段落以寻找关键证据。
提出两种方法进行关键证据选择:
-
基于相关性评分的方法:基于声明和段落中句子的向量表示。对于给定声明 C ,从检索到的相关段落
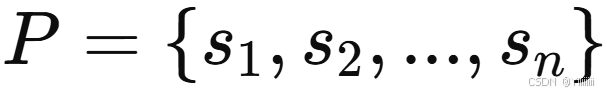 中选择相关性评分
中选择相关性评分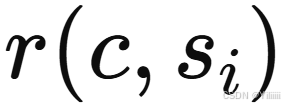 高于某一实验设定阈值 λ 的句子
高于某一实验设定阈值 λ 的句子。
-
基于上下文的句子选择方法:采用基于 BERT 的序列标注模型。将声明
与段落
拼接,并使用特殊标记分隔:[CLS]C[SEP]P[EOS]。模型的输出采用 BIO 标注格式,将所有无关 token 分类为 O,证据句的第一个 token 标记为 B,其余 token 标记为 I。基于 RoBERTa-large 模型进行训练,优化以下交叉熵损失函数:
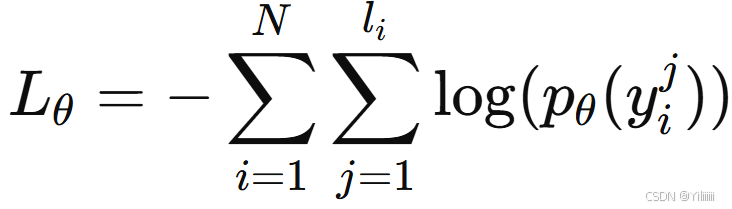
其中 N 为训练批次中的样本数, 为第 i 个样本的非填充 token 数,
为第 i 个样本中第 j 个 token 的正确标签的 softmax 概率。
本文在 Factual-NLI 数据集上以批量大小 64、Adam 优化器和初始学习率 训练该模型,直至收敛。
多步检索: 在选择关键证据的过程中,通过设定阈值 λ 来评估证据相关性的充分性。如果证据不足,采用迭代检索来补充信息。为了优先选择段落中最重要的片段,根据片段的得分对其进行排序。类似于人类通过逐步查询外部资源直至找到所需信息的行为,仅保留得分最高的片段。得分最高的片段(称为“优胜片段”)将被合并到当前查询中,格式为 [C[SEP]snippet]。
通过 transformer 模型更新生成新的查询:
![]()
重新生成的查询将被送回检索模块,用于重新格式化并对语料库中的段落进行排序。通过 transformer 模型,当前查询 与片段充分交互,避免了嵌入过程中信息的丢失。新查询
再次经过段落检索和关键证据选择,从而实现多步迭代检索。这种多步迭代方法使模型能够结合多个 Wikipedia 页面上的信息来验证新闻的真实性。
文本推理模块
模型的最后一步是通过多步检索得到的证据与新闻声明推断新闻的真实性。这一过程模仿了人类个体从外部来源收集信息,并根据这些信息评估新闻的可信度的行为。
给定一个新闻声明 C 和通过多步检索得到的相关证据 E,文本推理模块通过逻辑推理来判断证据与声明是否一致。推理模型充当评估者,判断声明与相关证据在逻辑上是一致还是矛盾的,从而将声明和相关证据对标记为“真”或“假”。因此,文本推理模型的训练任务可以看作是一个二分类任务,目标是最小化每条新闻及其相关证据的二元交叉熵损失函数:
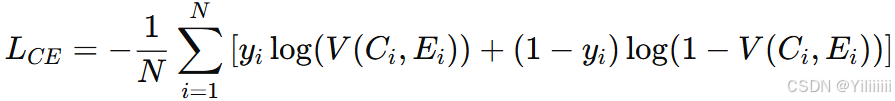
其中,N 是当前批次的样本数量,y=1 表示声明 C 与证据 E 在逻辑上一致,y=0 表示 C 与 E 矛盾。函数 V 是一个能够执行判别分类任务的预训练语言模型,如 BERT 、ALBERT 和 RoBERTa 。将声明 C 和证据 E 拼接为判别器的输入,格式为 [CLS]C[SEP]E[SEP]。批次大小 N 为 64,优化器为 Adam,初始学习率为 ,直到收敛为止。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)