RDD的执行流程(简略)
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。流程概括:①准备资源②创建Driver和Executor节点②然后将应用程序的数据处理逻辑分解成一个一个的计算任务task。③然后将任务task发到已经分配资源的计算节点executor上,按照指定的计算模型进行数据计算。最后得到计Driver和Executor都是运
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
流程概括:
①准备资源
②创建Driver和Executor节点
②然后将应用程序的数据处理逻辑分解成一个一个的计算任务task。
③然后将任务task发到【已经分配资源】的计算节点executor上, 按照指定的计算模型进行数据计算。最后得到计算结果
1. 启动 Yarn 集群环境(准备资源)
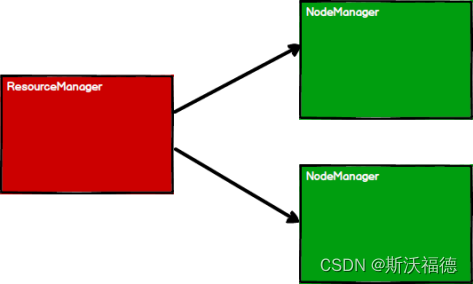
2. Spark 通过申请资源创建调度节点Driver和计算节点Executor
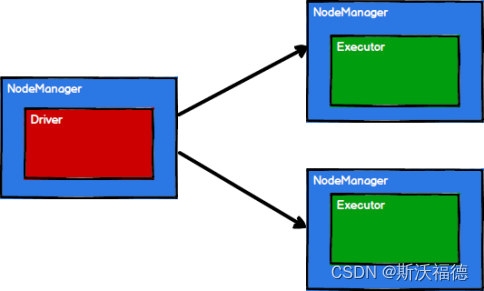
Driver和Executor都是运行在NodeManager上面的 !
ResourceManager是用于管理的,所以真正运行任务的是NodeManager
3. Spark 框架根据需求将计算逻辑根据分区划分成不同的task任务
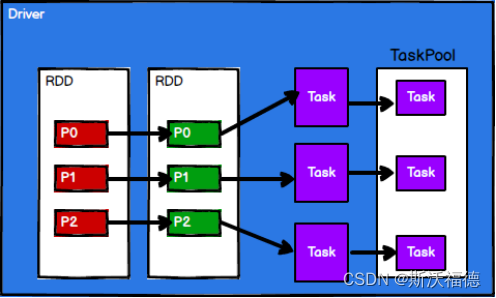
Driver用于在Executor节点之间调度task任务
多个RDD会组合形成关联,再分解为多个Task任务,并放到TaskPool任务池中(因为需要调度task任务)
4. 调度节点Driver将任务根据计算节点状态发送到对应的计算节点进行计算
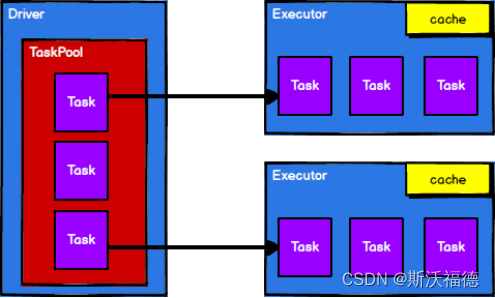
( Executor 通过自身块管理器为用户程序中要求缓存的RDD提供内存式Cache存储 )
调度节点Driver会将Task从任务池中取出,然后根据节点状态、首选位置来发送到不同的Executor进行计算
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)