回归模型评估指标
引言在机器学习中,回归模型用于预测连续数值,例如房价、温度或销售额。构建一个回归模型后,评估其性能至关重要。如何判断模型预测的准确性和可靠性?这就需要用到回归模型的评估指标。1. 常见的回归模型评估指标1.1 均方误差 (MSE)均方误差 (Mean Squared Error) 是最常用的回归模型评估指标之一,它计算模型预测值与真实值之间差异的平方的平均值。公式如下:其中:是真实值。是预测值。是
引言
在机器学习中,回归模型用于预测连续数值,例如房价、温度或销售额。构建一个回归模型后,评估其性能至关重要。
如何判断模型预测的准确性和可靠性?这就需要用到回归模型的评估指标。
1. 常见的回归模型评估指标
1.1 均方误差 (MSE)
均方误差 (Mean Squared Error) 是最常用的回归模型评估指标之一,它计算模型预测值与真实值之间差异的平方的平均值。公式如下:
其中:
是真实值。
是预测值。
是样本数量。
MSE 的值越小,说明模型的预测效果越好。
优点:MSE 对于大误差更加敏感,因为误差是被平方的。这使得它在模型训练过程中倾向于减少大误差。
缺点:由于平方的特性,MSE 的值受到离群值的影响,可能导致误导性的评估。
1.2 均方根误差 (RMSE)
均方根误差 (Root Mean Squared Error) 是均方误差的平方根。它与MSE相似,但RMSE的单位与因变量的单位相同,更容易解释。公式如下:
优点:RMSE 提供了模型误差的标准单位,使得它更容易理解和比较。
缺点:同样受到离群值的影响,可能在某些情况下给出偏差的评估。
1.3 平均绝对误差 (MAE)
平均绝对误差 (Mean Absolute Error) 衡量预测值与真实值之间的绝对差异的平均值。与MSE和RMSE不同,MAE不对误差进行平方处理,因此对于离群值的敏感度较低。公式如下:
优点:MAE 对于离群值不那么敏感,因此更稳健,适合于噪声较大的数据集。
缺点:与MSE相比,MAE在优化时的梯度信息不如MSE明确,可能导致收敛速度较慢。
1.4 决定系数 (R²)
决定系数 (R-squared) 是衡量模型解释因变量变异程度的指标。它的值介于0和1之间,值越接近1,说明模型对数据的解释能力越强。公式如下:
其中是因变量的平均值。
优点:R² 值可以直观地表示模型的拟合优度,且具有良好的可解释性。
缺点:R² 值可能会随着模型复杂度的增加而增加,导致过拟合。因此,使用调整后的R² 来评估多项式回归模型可能更合适。
2. Python 实现回归模型评估指标
我们将通过一个简单的回归示例来演示如何计算这些评估指标。假设我们有一组房屋面积和对应的房价数据。以下是实现代码。
2.1 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split2.2 生成数据
我们将生成一些随机数据来模拟房屋面积与房价之间的关系。
# 设置随机种子以确保可重复性
np.random.seed(0)
# 生成自变量 X(房屋面积)
X = np.linspace(50, 200, 100) # 生成从50到200的100个点
Y = 50000 + 2000 * X + np.random.randn(100) * 10000 # 线性关系加上噪声
# 将数据转换为DataFrame以便于处理
data = pd.DataFrame({'X': X, 'Y': Y})
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['X']], data['Y'], test_size=0.2, random_state=42)2.3 训练线性回归模型
# 创建线性回归对象
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)2.4 计算评估指标
# 计算评估指标
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r_squared = r2_score(y_test, y_pred)
print(f'均方误差 (MSE): {mse:.2f}')
print(f'均方根误差 (RMSE): {rmse:.2f}')
print(f'平均绝对误差 (MAE): {mae:.2f}')
print(f'决定系数 (R²): {r_squared:.2f}')均方误差 (MSE): 116479539.04
均方根误差 (RMSE): 10792.57
平均绝对误差 (MAE): 9023.96
决定系数 (R²): 0.98
2.5 可视化结果
我们可以通过绘制预测值与真实值的散点图来直观展示模型的性能。
# 绘制真实值与预测值
plt.scatter(y_test, y_pred, color='blue', alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--') # 理想预测线
plt.title('真实值与预测值的关系')
plt.xlabel('真实值 (房价)')
plt.ylabel('预测值 (房价)')
plt.grid()
plt.show()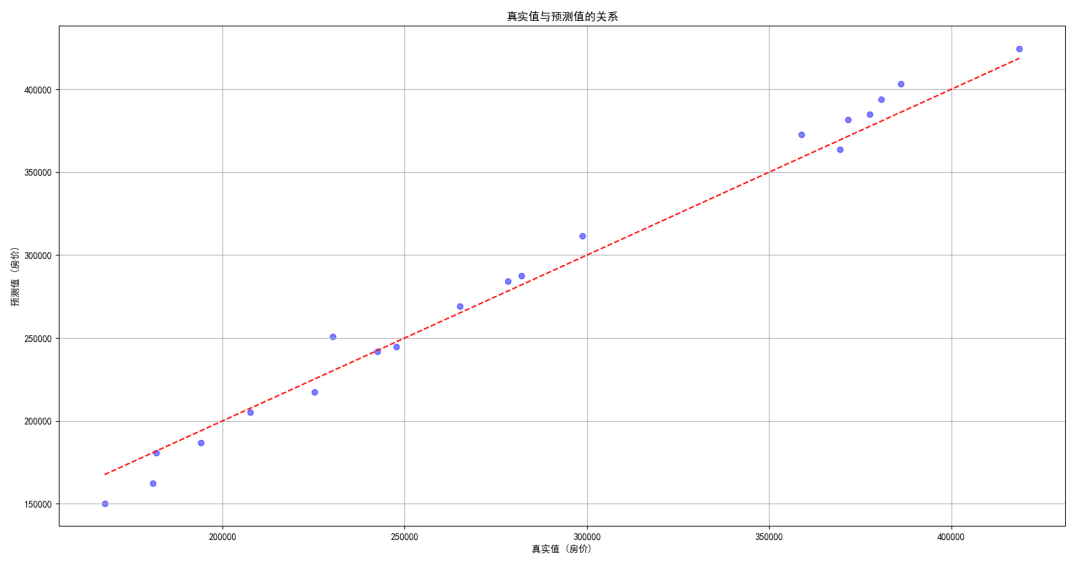
总结
MSE 和 RMSE 适合对大误差敏感的场景,通常用于评估模型的精度。
MAE 更为鲁棒,不容易受到离群值的影响,适用于需要稳定性能的场景。
R² 提供了模型解释能力的量化,帮助我们理解模型对数据的拟合程度。
希望本文能够帮助你理解回归模型的评估指标,并在实际项目中应用这些指标。如果你有任何问题,欢迎在评论区留言!
系列文章:
从零开始搭建机器学习开发环境:PyCharm与Anaconda教程
机器学习100天计划!
视频讲解 + 实战代码 + 社群交流 + 直播答疑
如果你想获得系统性的机器学习理论、代码、实战指导,可以购买我们的《机器学习100天》课程。
《机器学习100天》总共包含 100 个机器学习知识点视频讲解!我会提供所有的教学视频、实战代码,并提供社群一对一交流和直播答疑!
扫描下方二维码,加入学习!

点击「阅读原文」即刻报名,一顿午饭钱,值了。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)