聊聊Unsloth微调DeepSeek-R1蒸馏模型 - 构建医疗专家模型
最近提供了DeepSeek-R1模型的复现与GRPO算法的高效实现,而GRPO算法是DeepSeek模型中最关键的RL算法,而Unsloth增强优化了GRPO算法,使其使用更少的huggingface少80%的VRAM,支持在仅仅7GB的VRAM上基于Qwen 2.5-1.5b重新RL-Zero的"aha moment"。可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副
概述
Unsloth[1]是一个支持Llama系列、DeepSeek R1系列更快速,更少占用内存的微调库。最近提供了DeepSeek-R1模型的复现与GRPO算法的高效实现,而GRPO算法是DeepSeek模型中最关键的RL算法,而Unsloth增强优化了GRPO算法,使其使用更少的huggingface少80%的VRAM,支持在仅仅7GB的VRAM上基于Qwen 2.5-1.5b重新RL-Zero的"aha moment"。
DeepSeek的蒸馏模型是建立在Llama和Qwen架构上的,因此它们与Unsloth完全兼容。
微调
环境信息
基座模型:DeepSeek-R1-Distill-Llama-8B
微调库:Unsloth
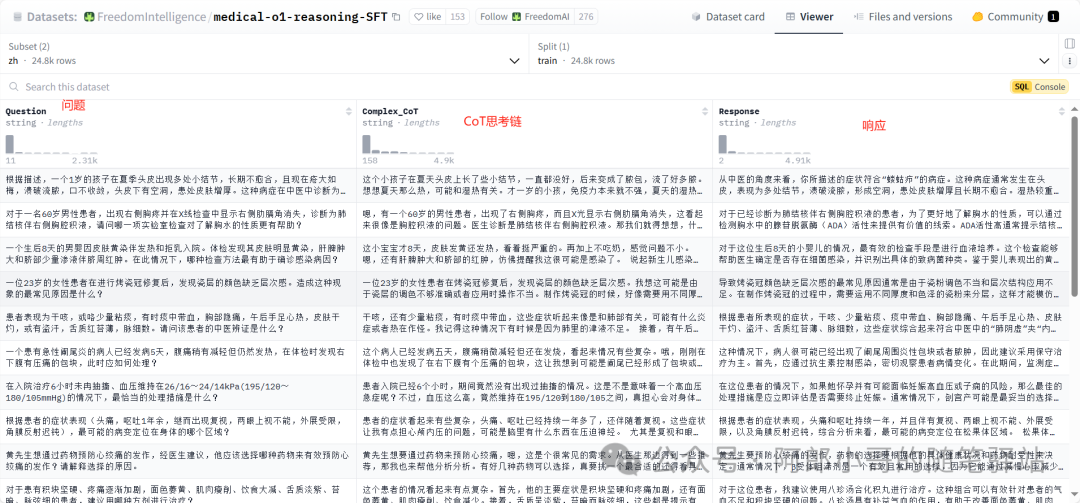
医疗数据集:medical-o1-reasoning-SFT[2]
数据集一览
下载库及加载模型
下载依赖库,并加载模型
pip install unsloth
# Also get the latest nightly Unsloth!
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
pip install bitsandbytes unsloth_zoo
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 基于unsloth加载Llama的蒸馏模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
推理测试
提示词如下:
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
输出:
<think>
首先,急性阑尾炎的常见症状包括急性发热、腹痛和腹部压痛。病人已经发病5天,腹痛有所减轻,但仍有发热,这可能意味着炎症正在缓解,但仍需密切观察。
体检发现右下腹有压痛的包块,这可能提示存在阑尾炎的复发性病变,或者是其他类型的炎症,如appendicitis perforans。需要进一步的影像学检查,如超声或CT,来明确包块的性质和位置,以确定是否有脓肿或其他结构异常。
此外,病人仍有发热,说明炎症可能未完全消退,需要考虑继续使用抗生素治疗,以防止感染延迟或扩散。同时,应密切监测病情,必要时进行进一步的治疗干预,如引流或手术。
在处理过程中,应与微生物学进行相互配合,根据病人的病原体培养结果,调整治疗方案,确保病毒、细菌的敏感性。
最后,病人的整体状况和病情变化应随时评估,以便及时调整治疗策略,确保病情得到有效控制。
</think>
在这种情况下,正确的处理步骤如下:
1. **进一步的影像学检查**:使用超声或CT检查右下腹部的包块,以确定其性质(如脓肿、腺体炎等)和位置。
2. **细菌培养和病原体检测**:进行病人的血液、脓液或包块的培养,以确定病原体的种类和抗生素敏感性。
3. **抗生素治疗**:根据病原体检测结果,选择敏感的抗生素,通常在明确病原体前开始治疗,以覆盖可能的细菌感染。
4. **监测病情变化**:密切观察病人的发热、腹痛和包块情况,必要时进行进一步的影像学或手术干预。
5. **联合治疗**:与微生物学及其他相关科室密切配合,调整治疗方案,确保病情得到控制。
6. **预防措施**:建议病人避免辛辣食物,保持饮食清淡,必要时进行护理,避免感染扩散。
通过以上步骤,可以全面评估病情,制定合理的治疗方案,确保病人的恢复。<|end▁of▁sentence|>
准备数据集
按如上数据集准备数据,训练时的提示词如下:
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
注意事项
在每个训练数据集条目的末尾添加EOS(序列结束)令牌是至关重要的,否则您可能会遇到无限生成。
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
# 迭代训练集数据,处理prompt
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train[0:500]", trust_remote_code=True)
print(dataset.column_names)
dataset = dataset.map(formatting_prompts_func, batched = True)
print(dataset["text"][0])
处理完后的单个训练数据格式如下:
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
根据描述,一个1岁的孩子在夏季头皮出现多处小结节,长期不愈合,且现在疮大如梅,溃破流脓,口不收敛,头皮下有空洞,患处皮肤增厚。这种病症在中医中诊断为什么病?
### Response:
<think>
这个小孩子在夏天头皮上长了些小结节,一直都没好,后来变成了脓包,流了好多脓。想想夏天那么热,可能和湿热有关。才一岁的小孩,免疫力本来就不强,夏天的湿热没准就侵袭了身体。
用中医的角度来看,出现小结节、再加上长期不愈合,这些症状让我想到了头疮。小孩子最容易得这些皮肤病,主要因为湿热在体表郁结。
但再看看,头皮下还有空洞,这可能不止是简单的头疮。看起来病情挺严重的,也许是脓肿没治好。这样的情况中医中有时候叫做禿疮或者湿疮,也可能是另一种情况。
等一下,头皮上的空洞和皮肤增厚更像是疾病已经深入到头皮下,这是不是说明有可能是流注或瘰疬?这些名字常描述头部或颈部的严重感染,特别是有化脓不愈合,又形成通道或空洞的情况。
仔细想想,我怎么感觉这些症状更贴近瘰疬的表现?尤其考虑到孩子的年纪和夏天发生的季节性因素,湿热可能是主因,但可能也有火毒或者痰湿造成的滞留。
回到基本的症状描述上看,这种长期不愈合又复杂的状况,如果结合中医更偏重的病名,是不是有可能是涉及更深层次的感染?
再考虑一下,这应该不是单纯的瘰疬,得仔细分析头皮增厚并出现空洞这样的严重症状。中医里头,这样的表现可能更符合‘蚀疮’或‘头疽’。这些病名通常描述头部严重感染后的溃烂和组织坏死。
看看季节和孩子的体质,夏天又湿又热,外邪很容易侵入头部,对孩子这么弱的免疫系统简直就是挑战。头疽这个病名听起来真是切合,因为它描述的感染严重,溃烂到出现空洞。
不过,仔细琢磨后发现,还有个病名似乎更为合适,叫做‘蝼蛄疖’,这病在中医里专指像这种严重感染并伴有深部空洞的情况。它也涵盖了化脓和皮肤增厚这些症状。
哦,该不会是夏季湿热,导致湿毒入侵,孩子的体质不能御,其病情发展成这样的感染?综合分析后我觉得‘蝼蛄疖’这个病名真是相当符合。
</think>
从中医的角度来看,你所描述的症状符合“蝼蛄疖”的病症。这种病症通常发生在头皮,表现为多处结节,溃破流脓,形成空洞,患处皮肤增厚且长期不愈合。湿热较重的夏季更容易导致这种病症的发展,特别是在免疫力较弱的儿童身上。建议结合中医的清热解毒、祛湿消肿的治疗方法进行处理,并配合专业的医疗建议进行详细诊断和治疗。<|end▁of▁sentence|>
训练模型
基于HuggingFace的SFTTrainer训练
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
# num_train_epochs = 1, # For longer training runs!
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # Use this for WandB etc
),
)
# 训练
trainer_stats = trainer.train()
微调验证
基于微调后的model,重新推理之前的question,看看新的效果:
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
<think>
嗯,这个病人已经有5天的急性阑尾炎了。最近的症状是腹痛稍微减轻,但他还是发热的。看来他的病情还没完全好转。
在体检时发现了右下腹有压痛的包块,这让我想到可能有了阻塞。也许是阑尾炎引起的炎症块,或者是其他感染性问题。
接下来,我得考虑进一步的检查。X光或者超声检查可能会帮助我更好地了解这个包块的具体位置和性质。
如果检查证实有阻塞,可能需要考虑引流手术。毕竟,阑尾炎如果没有及时处理,可能会发展成急性阑尾炎的急性阻塞炎症,甚至可能引发感染性腹膜炎。
还有,我需要确保病人的整体状况稳定。有时候,可能需要先用抗生素处理,消除感染的可能,以免阻塞情况变得更严重。
所以,综合考虑,我觉得应该首先做个X光或超声检查,评估这个包块的具体情况,然后根据检查结果决定是否需要进行引流手术。
</think>
在这种情况下,首先进行X光或超声检查是非常重要的,因为它可以帮助我们更好地了解这个包块的具体位置和性质。根据检查结果,如果发现有阻塞,我们需要考虑进行引流手术。同时,确保病人的整体状况稳定,可能需要使用抗生素来消除感染的可能性,以防止阻塞情况变得更严重。因此,建议先进行进一步的影像学检查,然后根据检查结果决定是否需要进行引流手术。<|end▁of▁sentence|>
保存模型
要将最终模型保存为LoRA适配器,可以使用Huggingface的push_to_hub进行在线保存,或者使用save_pretrained进行本地保存。
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
# model.push_to_hub("your_name/lora_model", token = "...") # Online saving
# tokenizer.push_to_hub("your_name/lora_model", token = "...") # Online saving
小结
小结
基于蒸馏模型Llama 3.1 8B,在医疗数据集上做了一次微调训练,最后得到我们要的医疗模型。其实整个过程与以前的微调逻辑是差不多的,只是数据集是CoT式的,而最终的数据也是带有思考的。
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
那么应该如何学习大模型
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【
保证100%免费】
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)