粒球相关笔记
粒球计算已经成功地冒险进入不同的人工智能领域,促进了创新理论方法的发展,包括颗粒球分类器、聚类技术、神经网络、粗糙集和进化计算。这大大提高了传统方法的效率、噪声鲁棒性和可解释性。
前言
粒球计算已经成功地冒险进入不同的人工智能领域,促进了创新理论方法的发展,包括颗粒球分类器、聚类技术、神经网络、粗糙集和进化计算。这大大提高了传统方法的效率、噪声鲁棒性和可解释性。
1.粒球
利用粒球作为多粒度特征表示的基本原理是,这些几何形状具有完全对称,提供了任意维度空间中最简单、最统一的数学模型表达,即{𝑥|(𝑥−𝑐)𝑑≤𝑟𝑑},其中𝑥表示粒球内的样本,𝑐和𝑟分别代表其中心和半径。无论尺寸如何,只需两个参数,即中心和半径,就可以对球进行表征。这一特性使得它对高维数据具有很强的适应性。
2.粒球计算模型的形式化
给定数据集𝐷={𝑥𝑖,𝑖= 1,2,…,𝑛},其中,𝑥𝑖表示样本数,𝑛表示在样本总数。𝐺𝐵𝑗(𝑗= 1,2,…,𝑘)表示基于𝐷生成的粒球,𝑘表示𝐷生成的粒球总数。
多粒度粒球计算的标准模型如下: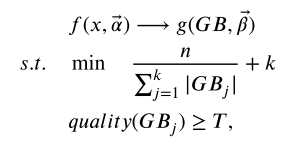
约束条件目标的第一项表示颗粒球对样本的覆盖程度的倒数。一般情况下,被基本不变的其他学习性能所覆盖的样本越多,信息丢失越少;
第二项为粒球数,在其他条件不变的情况下,粒球数越少,粒球计算的效率和鲁棒性越好。
3.颗粒-球分类模型与方法
粒球分类学习方法包括两个方面:一方面是约束中描述的颗粒球的生成,另一方面是以颗粒球为输入的计算模型。颗粒球的分类分为两个维度:第一个维度是颗粒球的表现和质量评价,第二个维度是它们产生时所采用的方法。
3.1 生成
为了实现“全局优先”的认知规律,算法从最少的球数开始生成,当达到约束时停止。
分裂时,每个颗粒球的初始中心是代表球中每个标签的一个点。
3.2 粒球覆盖
在学习目标优化过程中,颗粒球的覆盖效果主要通过以下几个因素来衡量:
- 覆盖程度。在其他因素不变的情况下,覆盖率越高,样本信息丢失越少,表征越准确。
- 在其他因素不变的情况下,颗粒球的数量与球的粗度有关。最大限度地减少这一因素,就是使颗粒球尽可能粗,符合“全球优先”的认知规则。粒度球越少,粒度越粗,相应的粗粒度特征越明显:粒度球计算效率越高,鲁棒性越好。
- 在不同的问题下,为了优化相应的学习目标,粒球本身的质量𝑞𝑢𝑎𝑙𝑖𝑡𝑦(𝐺𝐵𝑗)需要高于给定的阈值𝑇。这个因素也与颗粒球粗度的下限有关,使最小的颗粒球“细”到足以准确地代表问题。该阈值可以通过给定方法、网格搜索或自适应方法获得。
综合来看,因子1保证了一定的覆盖度,因子2和因子3共同作用,得到了具有适当粗度和细度的颗粒球。在因子1和因子2不变的情况下,因子3的阈值越小,粒度球质量越好,粒度球越粗,粒度球越少,计算效率越高,鲁棒性越好,但细节表示可能不够。较高的阈值可以得到更好的细节表示,但可能会降低效率和鲁棒性。
3.3 粒球的表现和质量评价、
中心: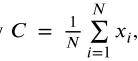
半径: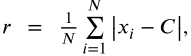
粒球中所有采样点到中心的平均距离:颗粒球的覆盖能力较差,但可以得到球内更均匀的数据分布和更清晰的决策边界,有利于分类目标的优化。
最大距离也可以用来在球内获得良好的样本覆盖
纯度:粒球中所有类中最大标签数的比值
数据集内的纯度分数越高意味着数据分布越均匀。
4.GB𝑘NN
Knn原理:当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
详见:https://blog.csdn.net/weixin_45014385/article/details/123618841
GBknn原理:单个查询样本点的标签等同于最近的粒球的标签,这是由粒球内的大多数样本标签决定的。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)