Trae 04.22版本深度解析:Agent能力升级与MCP市场对复杂任务执行的革新
在当今快速发展的AI技术领域,Agent系统正成为自动化任务执行和智能交互的核心组件。Trae作为一款先进的AI协作平台,在04.22版本中带来了重大更新,特别是在Agent能力升级和MCP市场支持方面。本文将深入探讨这些更新如何重新定义复杂任务的执行方式,为开发者提供更强大的工具和更灵活的解决方案。
我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:Trae - AI 原生 IDE
目录
引言
在当今快速发展的AI技术领域,Agent系统正成为自动化任务执行和智能交互的核心组件。Trae作为一款先进的AI协作平台,在04.22版本中带来了重大更新,特别是在Agent能力升级和MCP市场支持方面。本文将深入探讨这些更新如何重新定义复杂任务的执行方式,为开发者提供更强大的工具和更灵活的解决方案。
一、Trae 04.22版本概览
Trae 04.22版本是一次重大更新,主要围绕以下几个核心方面进行了优化:
- 统一对话体验:Chat与Builder面板合并
- 上下文能力增强:新增Web和Doc两种Context
- 规则系统上线:支持个人与项目规则配置
- Agent能力升级:支持自定义Agent和自动执行
- MCP支持上线:内置MCP市场与第三方集成

图1:Trae 04.22版本更新架构图
二、统一对话体验的深度整合
2.1 Chat与Builder面板合并
04.22版本最直观的变化是Chat与Builder面板的合并,实现了无缝的对话式开发体验。用户现在可以通过简单的@Builder命令随时切换至Builder Agent模式。
# 示例:使用@Builder命令切换模式
def handle_user_input(user_input):
if user_input.startswith("@Builder"):
# 切换到Builder Agent模式
activate_builder_mode()
return "已进入Builder Agent模式,请输入构建指令"
else:
# 普通Chat模式处理
return process_chat_message(user_input)
# Builder模式激活函数
def activate_builder_mode():
# 初始化Builder环境
init_builder_environment()
# 加载项目上下文
load_project_context()
# 设置专门的提示词
set_builder_prompt("您正在Builder模式下工作,可以执行构建命令")代码1:模式切换处理逻辑示例
2.2 统一对话的优势
这种统一带来了几个关键优势:
- 上下文保持:在Chat和Builder模式间切换时保持上下文一致性
- 流畅体验:无需在不同界面间跳转,提高工作效率
- 灵活交互:可根据任务需求随时调整工作模式
三、上下文能力的显著增强
3.1 Web Context的实现
#Web Context允许Agent自动联网搜索并提取网页内容,极大扩展了信息获取能力。
# Web Context处理流程示例
def process_web_context(url):
try:
# 1. 获取网页内容
response = requests.get(url, timeout=10)
response.raise_for_status()
# 2. 提取主要内容(避免广告和噪音)
soup = BeautifulSoup(response.text, 'html.parser')
main_content = extract_meaningful_content(soup)
# 3. 结构化处理
structured_data = {
'title': extract_title(soup),
'content': main_content,
'links': extract_relevant_links(soup),
'last_updated': datetime.now()
}
# 4. 存储到上下文
save_to_context('web', structured_data)
return structured_data
except Exception as e:
log_error(f"Web context processing failed: {str(e)}")
return None代码2:Web Context处理流程
3.2 Doc Context的文档处理
#Doc Context支持通过URL或上传.md/.txt文件创建文档集,最多支持1000个文件(50MB)。
# Doc Context处理示例
class DocContextProcessor:
def __init__(self):
self.max_files = 1000
self.max_size = 50 * 1024 * 1024 # 50MB
def add_documents(self, doc_sources):
total_size = 0
processed_docs = []
for source in doc_sources:
if len(processed_docs) >= self.max_files:
break
doc = self._process_source(source)
if doc:
doc_size = sys.getsizeof(doc['content'])
if total_size + doc_size > self.max_size:
break
processed_docs.append(doc)
total_size += doc_size
self._index_documents(processed_docs)
return processed_docs
def _process_source(self, source):
# 处理URL或文件上传
if source.startswith('http'):
return self._process_url(source)
else:
return self._process_uploaded_file(source)
def _process_url(self, url):
# 实现URL文档处理逻辑
pass
def _process_uploaded_file(self, file_path):
# 实现文件处理逻辑
pass代码3:Doc Context处理类
四、规则系统的设计与实现
4.1 个人规则与项目规则
Trae 04.22引入了双层规则系统:
- 个人规则:通过
user_rules.md跨项目生效 - 项目规则:位于
.trae/rules/project_rules.md,规范项目内AI行为
<!-- 示例:user_rules.md -->
# 个人规则
## 代码风格
- 使用4空格缩进
- 函数命名采用snake_case
- 类命名采用PascalCase
## 安全规则
- 禁止执行rm -rf /
- 数据库操作需确认
<!-- 示例:project_rules.md -->
# 项目规则
## API规范
- 所有端点必须版本化(/v1/...)
- 响应必须包含request_id
## 测试要求
- 覆盖率不低于80%
- 必须包含集成测试代码4:规则文件示例
4.2 规则引擎的实现
规则引擎采用多阶段处理流程:
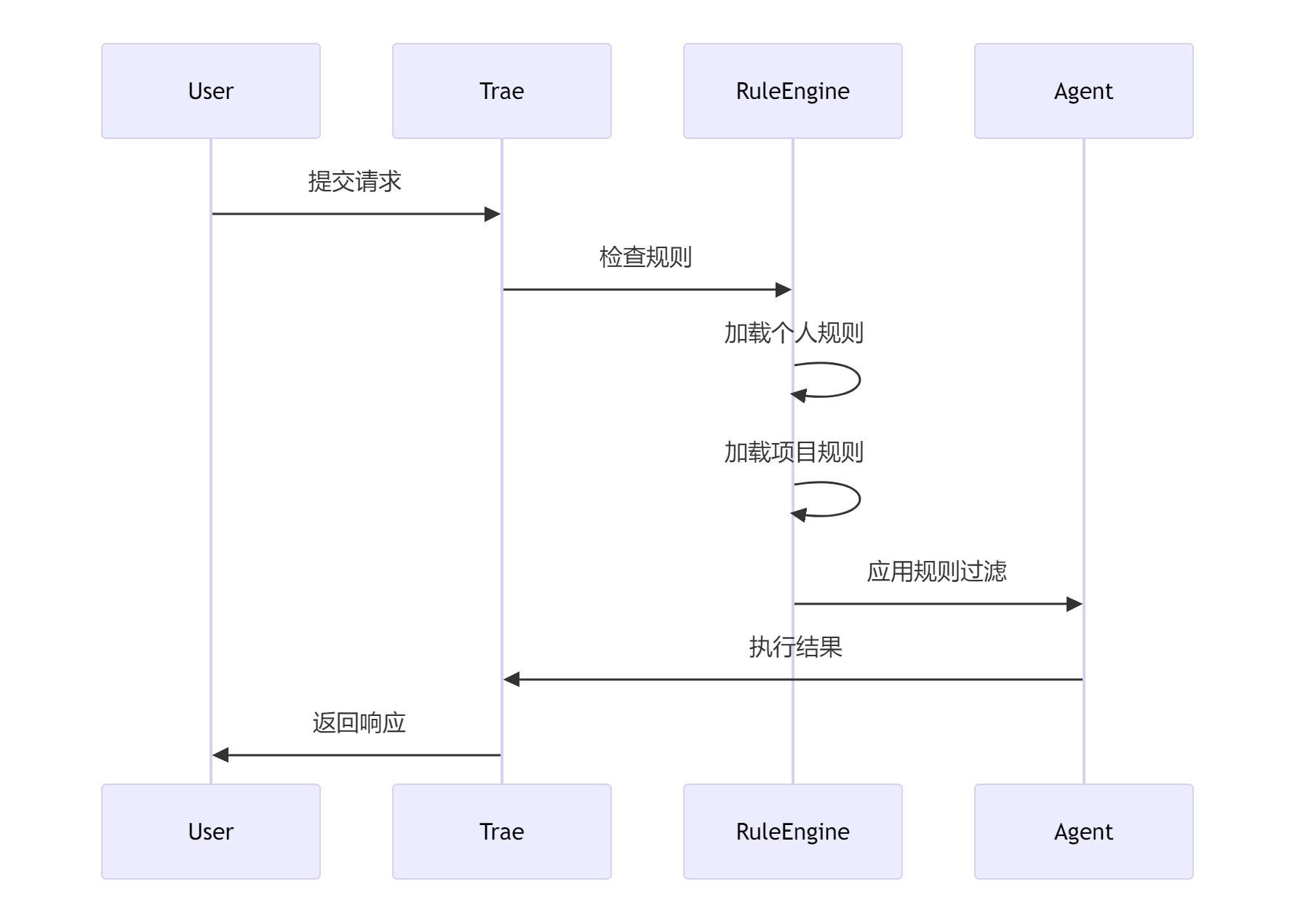
图2:规则处理时序图
五、Agent能力的重大升级
5.1 自定义Agent架构
Trae 04.22允许通过prompt和tools深度自定义Agent,架构如下:
# 自定义Agent示例
class CustomAgent:
def __init__(self, name, prompt, tools, config):
self.name = name
self.prompt_template = prompt
self.tools = tools # 可用工具集
self.config = config
self.blacklist = config.get('command_blacklist', [])
def execute(self, command):
if self._is_blacklisted(command):
return "命令被禁止执行"
tool = self._select_tool(command)
if tool:
return tool.execute(command)
else:
return self._fallback_response(command)
def _is_blacklisted(self, command):
return any(
banned in command
for banned in self.blacklist
)
def _select_tool(self, command):
for tool in self.tools:
if tool.can_handle(command):
return tool
return None
def generate_prompt(self, context):
return self.prompt_template.format(
agent_name=self.name,
context=context
)代码5:自定义Agent基类
5.2 内置Builder Agent
Trae提供了两个强大的内置Agent:
- Builder Agent:基础构建Agent
- Builder with MCP:集成MCP能力的增强版
# Builder Agent配置示例
builder_agent_config = {
"name": "AdvancedBuilder",
"description": "Enhanced builder with MCP support",
"prompt": """你是一个高级构建Agent,具有以下能力:
- 理解复杂构建指令
- 自动解决依赖关系
- 安全执行构建命令
当前项目: {project_name}
上下文: {context}""",
"tools": [
CodeGeneratorTool(),
DependencyResolverTool(),
MCPIntegrationTool()
],
"command_blacklist": [
"rm -rf",
"format c:"
]
}代码6:Builder Agent配置示例
六、MCP市场的创新支持
6.1 MCP架构概述
MCP(Multi-agent Collaboration Platform)市场是04.22版本的核心创新,架构如下:
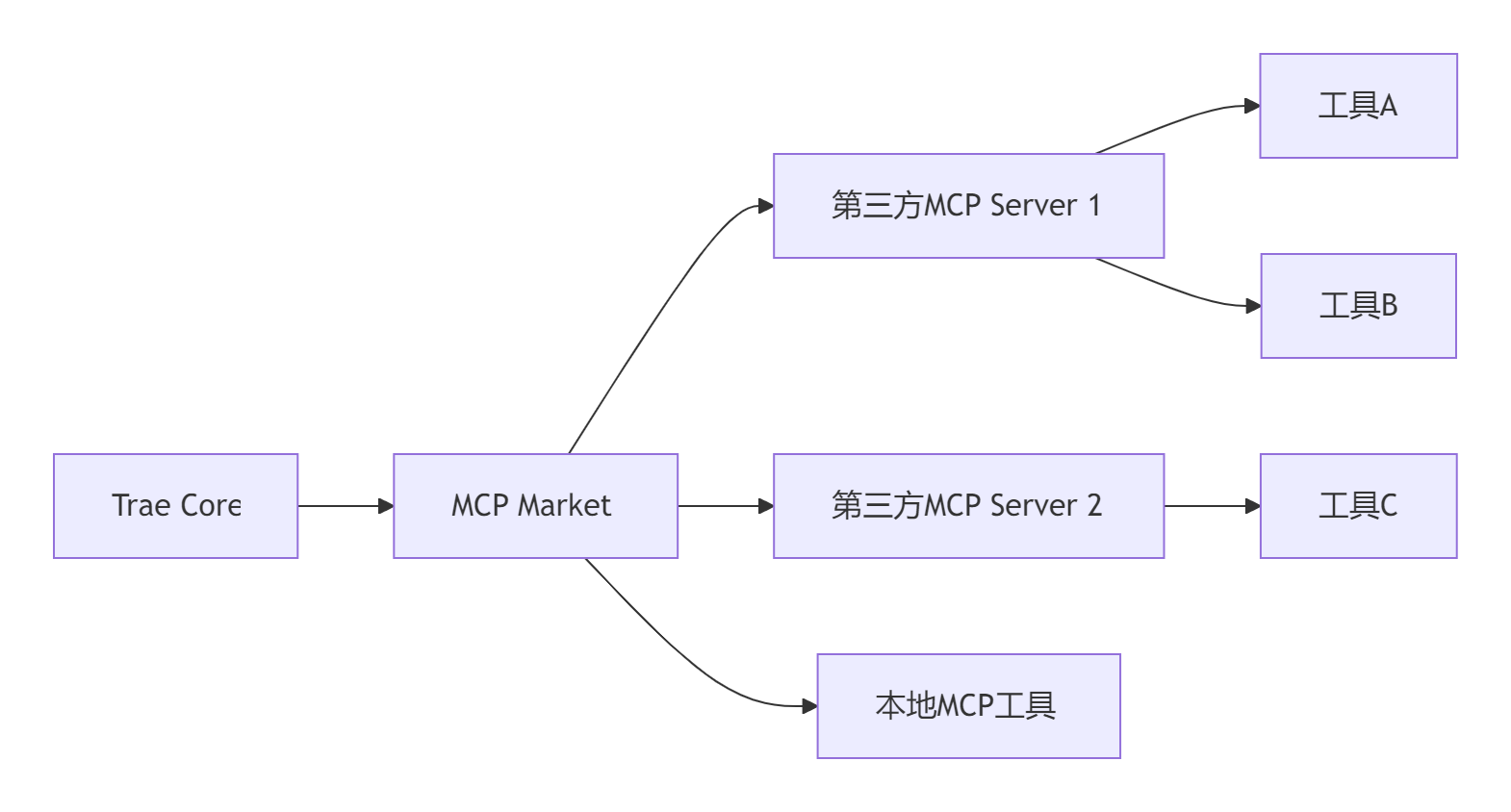
图3:MCP市场架构图
6.2 第三方MCP集成示例
# 第三方MCP集成示例
class MCPService:
def __init__(self):
self.registered_servers = {}
def add_server(self, name, config):
# 验证配置
if not self._validate_config(config):
raise ValueError("Invalid MCP server config")
# 测试连接
if not self._test_connection(config):
raise ConnectionError("Cannot connect to MCP server")
self.registered_servers[name] = {
'config': config,
'tools': self._fetch_available_tools(config)
}
def execute_tool(self, server_name, tool_name, params):
server = self.registered_servers.get(server_name)
if not server:
raise ValueError("Server not found")
tool = next(
(t for t in server['tools'] if t['name'] == tool_name),
None
)
if not tool:
raise ValueError("Tool not found")
return self._call_remote_tool(
server['config'],
tool_name,
params
)代码7:MCP服务管理类
七、复杂任务执行的创新模式
7.1 自动执行工作流
结合Agent和MCP能力,Trae可以实现复杂的自动化工作流:
- 任务分解:将复杂任务拆解为子任务
- 资源分配:为每个子任务分配合适的Agent
- 执行监控:实时监控任务进展
- 结果整合:汇总各子任务结果
# 复杂任务执行引擎示例
class TaskOrchestrator:
def __init__(self, agents, mcp_services):
self.agents = agents
self.mcp_services = mcp_services
self.task_queue = []
self.results = {}
def add_task(self, task):
self.task_queue.append(task)
def execute(self):
while self.task_queue:
task = self.task_queue.pop(0)
# 选择最适合的Agent
agent = self._select_agent(task)
# 执行任务
if agent:
result = agent.execute(task)
self.results[task.id] = result
# 处理需要MCP工具的任务
if task.needs_mcp:
mcp_result = self._handle_mcp_task(task)
result.update(mcp_result)
# 处理依赖任务
for dependent in task.dependents:
if all(dep in self.results for dep in dependent.dependencies):
self.task_queue.append(dependent)
return self.results代码8:任务编排引擎
7.2 实际应用场景
- 智能代码审查:
-
- 使用CodeAnalysis Agent检查代码质量
- 通过MCP集成安全扫描工具
- 自动生成审查报告
- 自动化测试流水线:
-
- 自动识别变更影响范围
- 动态生成测试用例
- 并行执行测试任务
- 智能文档生成:
-
- 分析代码和注释
- 提取关键信息
- 生成多种格式的文档
八、性能与安全考量
8.1 性能优化策略
- Agent缓存机制:缓存常用Agent状态
- MCP连接池:复用第三方服务连接
- 并行执行:对独立子任务采用并行处理
- 增量处理:对大型文档集采用增量加载
8.2 安全防护措施
- 命令黑名单:防止危险操作
- 权限隔离:不同级别Agent有不同的权限
- 沙箱执行:危险操作在沙箱中运行
- 审计日志:记录所有关键操作
# 安全执行器示例
class SafeExecutor:
def __init__(self, sandbox_enabled=True):
self.sandbox = sandbox_enabled
self.audit_log = []
def execute_command(self, command, agent):
# 记录审计日志
self._log_audit(agent, command)
# 检查黑名单
if self._is_dangerous(command):
raise SecurityError("Command blocked by security policy")
# 沙箱执行
if self.sandbox:
return self._execute_in_sandbox(command)
else:
return subprocess.run(
command,
shell=True,
check=True,
capture_output=True
)
def _is_dangerous(self, command):
dangerous_patterns = [
"rm -rf", "format", "chmod 777"
]
return any(
pattern in command
for pattern in dangerous_patterns
)代码9:安全命令执行器
九、总结与展望
Trae 04.22版本通过Agent能力升级和MCP市场支持,为复杂任务执行带来了革命性的改进:
- 更强大的自动化能力:通过可定制的Agent和丰富的工具集成
- 更灵活的协作模式:MCP市场打破了工具壁垒
- 更智能的任务分解:自动化的复杂任务处理流程
- 更安全的执行环境:多层次的安全防护机制
未来,我们可以期待:
- 更丰富的MCP工具生态
- 更智能的Agent协作机制
- 更强大的上下文理解能力
- 更精细化的权限控制系统
十、参考资料
- Trae官方文档 - 最新版本文档
- Multi-agent Systems: A Survey - 多Agent系统研究综述
- AI Safety Guidelines - AI安全开发指南
- MCP协议规范 - 多Agent协作协议标准
通过Trae 04.22版本的这些创新功能,开发者现在拥有了更强大的工具来处理日益复杂的软件开发任务,将AI协作提升到了一个新的水平。
十一、Agent能力进阶:动态技能组合与自适应学习
11.1 动态技能组合机制
Trae 04.22版本的Agent支持运行时动态加载技能模块,实现真正的弹性能力扩展。这种机制基于微服务架构设计:
# 动态技能加载器实现
class DynamicSkillLoader:
def __init__(self):
self.skill_registry = {}
self.skill_dependencies = defaultdict(list)
def register_skill(self, skill_name, skill_module, dependencies=None):
"""注册新技能到Agent系统"""
if not inspect.ismodule(skill_module):
raise ValueError("Skill must be a module object")
self.skill_registry[skill_name] = skill_module
if dependencies:
self._validate_dependencies(dependencies)
self.skill_dependencies[skill_name] = dependencies
def load_for_agent(self, agent, skill_names):
"""为指定Agent加载技能集"""
loaded = set()
# 拓扑排序解决依赖关系
for skill in self._topological_sort(skill_names):
if skill not in self.skill_registry:
continue
# 动态注入技能方法
skill_module = self.skill_registry[skill]
for name, obj in inspect.getmembers(skill_module):
if name.startswith('skill_'):
setattr(agent, name, MethodType(obj, agent))
loaded.add(name[6:])
return list(loaded)
def _validate_dependencies(self, dependencies):
"""验证技能依赖是否有效"""
for dep in dependencies:
if dep not in self.skill_registry:
raise ValueError(f"Missing dependency: {dep}")代码10:动态技能加载器实现
11.2 自适应学习框架
Agent通过以下三层架构实现持续学习:
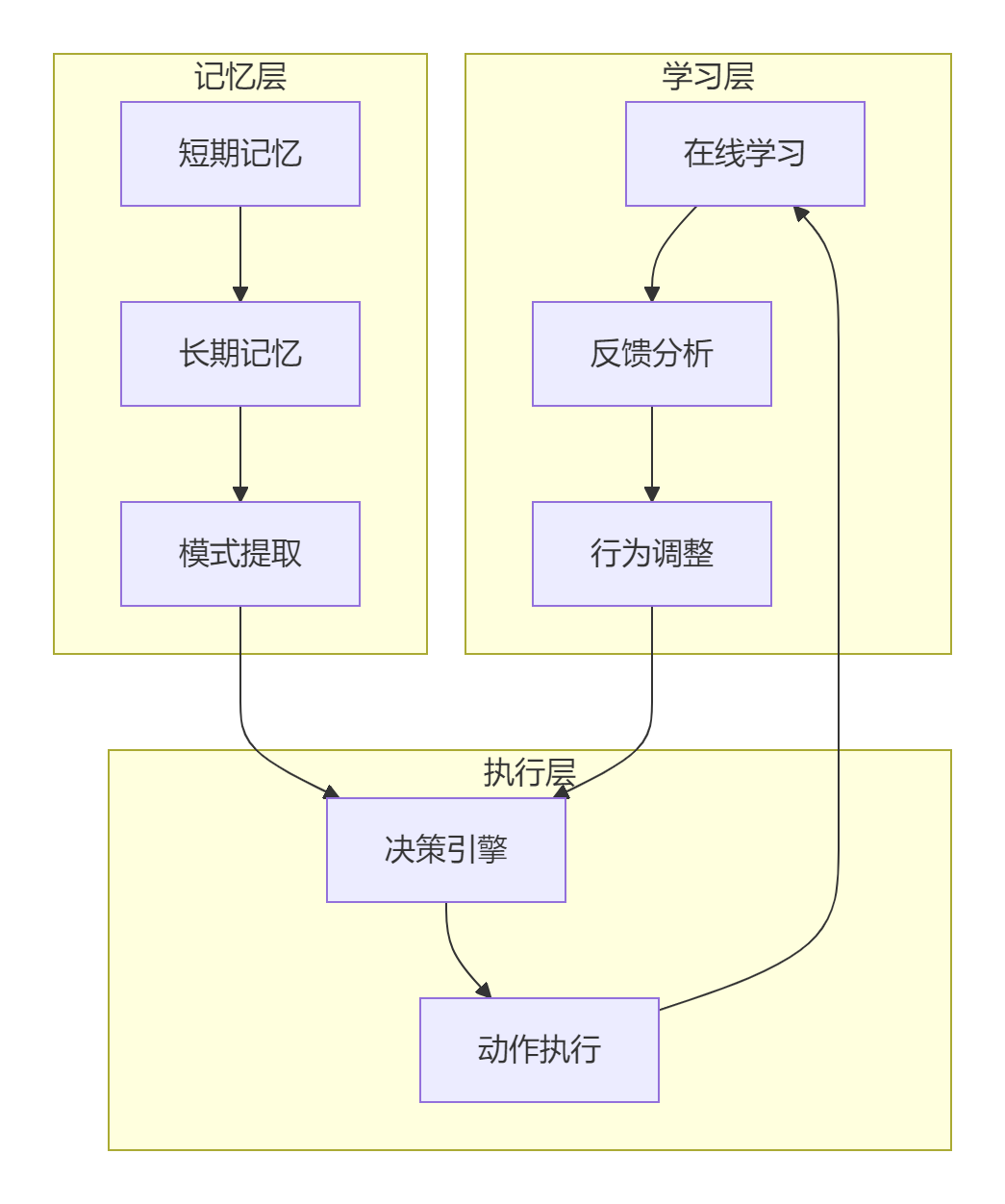
图4:Agent自适应学习架构
实现代码示例:
class AdaptiveLearningAgent:
def __init__(self, memory_capacity=1000):
self.short_term_memory = deque(maxlen=100)
self.long_term_memory = []
self.memory_capacity = memory_capacity
self.learning_rate = 0.1
self.behavior_model = BehaviorModel()
def process_feedback(self, feedback):
"""处理执行反馈并学习"""
self.short_term_memory.append(feedback)
# 定期压缩到长期记忆
if len(self.short_term_memory) >= 100:
self._consolidate_memory()
# 更新行为模型
self._update_behavior(feedback)
def _consolidate_memory(self):
"""记忆压缩算法"""
patterns = self._extract_patterns(self.short_term_memory)
for pattern in patterns:
if len(self.long_term_memory) >= self.memory_capacity:
self._forget_least_used()
self.long_term_memory.append(pattern)
self.short_term_memory.clear()
def _update_behavior(self, feedback):
"""基于反馈调整行为模型"""
adjustment = self._calculate_adjustment(feedback)
self.behavior_model.update(
adjustment,
learning_rate=self.learning_rate
)
def make_decision(self, context):
"""基于学习结果做出决策"""
return self.behavior_model.predict(context)代码11:自适应学习Agent实现
十二、MCP市场深度集成方案
12.1 服务发现与负载均衡
MCP市场采用改进的DNS-SD协议实现服务发现:
class MCPServiceDiscovery:
def __init__(self, multicast_addr='224.0.0.251', port=5353):
self.multicast_addr = multicast_addr
self.port = port
self.services = {}
self.socket = self._setup_multicast_socket()
self.load_balancers = {}
def _setup_multicast_socket(self):
"""配置组播监听socket"""
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('', self.port))
mreq = struct.pack('4sl',
socket.inet_aton(self.multicast_addr),
socket.INADDR_ANY)
sock.setsockopt(socket.IPPROTO_IP,
socket.IP_ADD_MEMBERSHIP,
mreq)
return sock
def discover_services(self, timeout=5):
"""发现可用MCP服务"""
start_time = time.time()
while time.time() - start_time < timeout:
data, addr = self.socket.recvfrom(1024)
service_info = self._parse_service_packet(data)
if service_info:
self._register_service(service_info, addr[0])
def get_best_instance(self, service_name):
"""获取最优服务实例"""
if service_name not in self.load_balancers:
self.load_balancers[service_name] = (
LoadBalancer(self.services[service_name])
)
return self.load_balancers[service_name].get_instance()代码12:MCP服务发现实现
12.2 跨MCP事务管理
实现跨MCP服务的ACID事务:
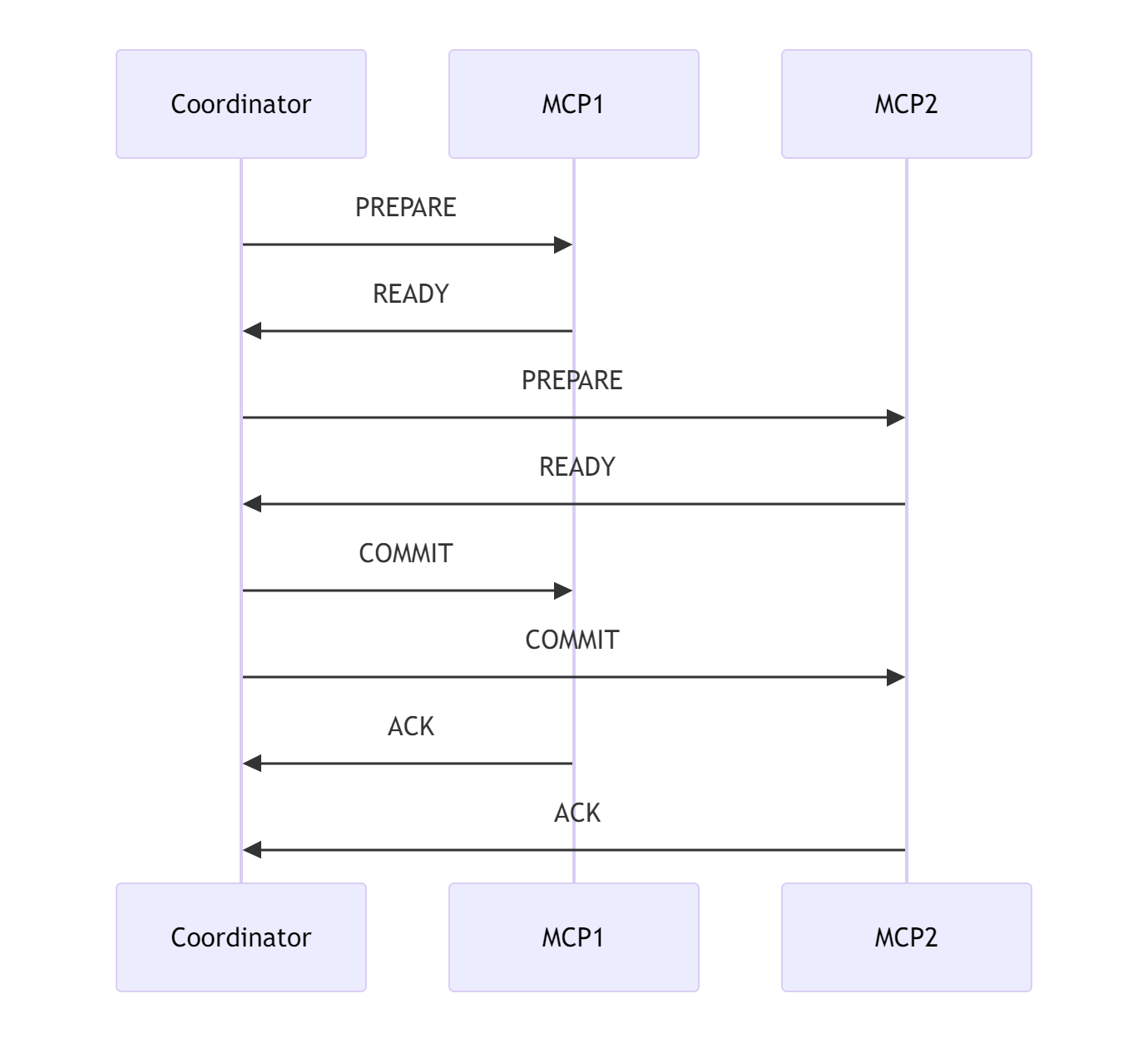
图5:跨MCP两阶段提交协议
实现代码:
class MCPTransactionManager:
def __init__(self, participants):
self.participants = participants
self.state = 'IDLE'
self.timeout = 30 # seconds
def execute(self, operations):
"""执行分布式事务"""
try:
# 阶段1:准备
self.state = 'PREPARING'
prepare_results = []
for participant, op in zip(self.participants, operations):
result = participant.prepare(op)
prepare_results.append(result)
if not all(res['status'] == 'ready' for res in prepare_results):
self._rollback(prepare_results)
return False
# 阶段2:提交
self.state = 'COMMITTING'
commit_results = []
for participant in self.participants:
result = participant.commit()
commit_results.append(result)
if not all(res['status'] == 'success' for res in commit_results):
self._compensate(commit_results)
return False
self.state = 'DONE'
return True
except Exception as e:
self.state = 'ERROR'
self._emergency_rollback()
raise MCPTransactionError(str(e))
def _rollback(self, prepare_results):
"""回滚已准备的操作"""
for participant, res in zip(self.participants, prepare_results):
if res['status'] == 'ready':
participant.rollback()
self.state = 'ABORTED'代码13:跨MCP事务管理器
十三、复杂任务分解引擎设计
13.1 任务图建模
采用有向无环图(DAG)表示复杂任务:
class TaskGraph:
def __init__(self):
self.nodes = {}
self.edges = defaultdict(list)
self.reverse_edges = defaultdict(list)
def add_task(self, task_id, task_info):
"""添加新任务节点"""
if task_id in self.nodes:
raise ValueError(f"Duplicate task ID: {task_id}")
self.nodes[task_id] = task_info
def add_dependency(self, from_task, to_task):
"""添加任务依赖关系"""
if from_task not in self.nodes or to_task not in self.nodes:
raise ValueError("Invalid task ID")
self.edges[from_task].append(to_task)
self.reverse_edges[to_task].append(from_task)
def get_execution_order(self):
"""获取拓扑排序执行顺序"""
in_degree = {task: 0 for task in self.nodes}
for task in self.nodes:
for neighbor in self.edges[task]:
in_degree[neighbor] += 1
queue = deque([task for task in in_degree if in_degree[task] == 0])
topo_order = []
while queue:
task = queue.popleft()
topo_order.append(task)
for neighbor in self.edges[task]:
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0:
queue.append(neighbor)
if len(topo_order) != len(self.nodes):
raise ValueError("Graph has cycles")
return topo_order
def visualize(self):
"""生成可视化任务图"""
dot = Digraph()
for task_id, info in self.nodes.items():
dot.node(task_id, label=f"{task_id}\n{info['type']}")
for from_task, to_tasks in self.edges.items():
for to_task in to_tasks:
dot.edge(from_task, to_task)
return dot代码14:任务图建模实现
13.2 智能分解算法
基于强化学习的任务分解策略:
class TaskDecomposer:
def __init__(self, policy_network):
self.policy_net = policy_network
self.memory = ReplayBuffer(10000)
self.optimizer = torch.optim.Adam(
self.policy_net.parameters(),
lr=1e-4
)
def decompose(self, complex_task, context):
"""分解复杂任务"""
state = self._extract_state(complex_task, context)
# 使用策略网络预测分解方案
with torch.no_grad():
action_probs = self.policy_net(state)
action_dist = Categorical(action_probs)
action = action_dist.sample()
subtasks = self._action_to_subtasks(action)
return subtasks
def learn_from_feedback(self, decomposition, feedback):
"""从执行反馈中学习"""
state = decomposition['state']
action = decomposition['action']
reward = self._calculate_reward(feedback)
# 存储到经验回放池
self.memory.push(state, action, reward)
# 定期训练
if len(self.memory) >= 1000:
self._train_network()
def _train_network(self):
"""训练策略网络"""
batch = self.memory.sample(64)
states = torch.stack(batch.state)
actions = torch.stack(batch.action)
rewards = torch.stack(batch.reward)
# 计算策略梯度
action_probs = self.policy_net(states)
dist = Categorical(action_probs)
log_probs = dist.log_prob(actions)
loss = -(log_probs * rewards).mean()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()代码15:基于强化学习的任务分解器
十四、性能优化关键技术
14.1 Agent快速上下文切换
实现亚毫秒级上下文切换:
class AgentContextSwitcher:
def __init__(self):
self.context_pool = {}
self.active_context = None
self.lru_cache = OrderedDict()
self.cache_size = 10
def switch_to(self, agent, context_id):
"""切换Agent上下文"""
# 从池中获取或加载上下文
if context_id not in self.context_pool:
context = self._load_context(context_id)
self.context_pool[context_id] = context
else:
context = self.context_pool[context_id]
# 更新LRU缓存
if context_id in self.lru_cache:
self.lru_cache.move_to_end(context_id)
else:
self.lru_cache[context_id] = time.time()
if len(self.lru_cache) > self.cache_size:
oldest = next(iter(self.lru_cache))
del self.context_pool[oldest]
del self.lru_cache[oldest]
# 执行切换
old_context = self.active_context
self.active_context = context_id
# 调用Agent钩子
agent.on_context_switch(old_context, context_id)
return context
def _load_context(self, context_id):
"""快速加载上下文实现"""
# 使用内存映射文件加速加载
with open(f"contexts/{context_id}.ctx", 'rb') as f:
buf = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
return pickle.loads(buf)代码16:快速上下文切换实现
14.2 MCP调用流水线优化
采用SIMD风格批量处理:
class MCPPipeline:
def __init__(self, batch_size=32):
self.batch_size = batch_size
self.input_queue = deque()
self.output_queue = deque()
self.processing = False
async def process_requests(self, requests):
"""批量处理MCP请求"""
# 填充批次
batch = []
for req in requests:
self.input_queue.append(req)
if len(self.input_queue) >= self.batch_size:
batch = [self.input_queue.popleft()
for _ in range(self.batch_size)]
break
if not batch:
return []
# 批量执行
try:
self.processing = True
results = await self._execute_batch(batch)
# 分发结果
for res in results:
self.output_queue.append(res)
return [self.output_queue.popleft()
for _ in range(len(results))]
finally:
self.processing = False
async def _execute_batch(self, batch):
"""执行批量MCP调用"""
# 合并相似请求
merged = self._merge_requests(batch)
# 并行调用
tasks = []
for service, reqs in merged.items():
task = asyncio.create_task(
self._call_mcp_service(service, reqs)
)
tasks.append(task)
responses = await asyncio.gather(*tasks)
# 拆分结果
return self._split_responses(batch, responses)代码17:MCP调用流水线优化
十五、安全增强机制
15.1 细粒度权限控制
基于RBAC模型的改进方案:
class PermissionManager:
def __init__(self):
self.roles = {
'admin': {'*'},
'developer': {
'agent:create',
'agent:invoke',
'mcp:use'
},
'analyst': {
'data:query',
'report:generate'
}
}
self.users = {}
self.policy_cache = LRUCache(1000)
def check_permission(self, user, resource, action):
"""检查用户权限"""
cache_key = f"{user.id}-{resource}-{action}"
if cache_key in self.policy_cache:
return self.policy_cache[cache_key]
# 获取用户角色
user_roles = self.users.get(user.id, set())
# 检查每个角色的权限
allowed = False
for role in user_roles:
if role not in self.roles:
continue
# 支持通配符权限
if '*' in self.roles[role]:
allowed = True
break
# 精确匹配
perm = f"{resource}:{action}"
if perm in self.roles[role]:
allowed = True
break
# 缓存结果
self.policy_cache[cache_key] = allowed
return allowed
def add_scoped_permission(self, role, resource, actions, condition=None):
"""添加带条件的权限"""
for action in actions:
perm = Permission(
resource=resource,
action=action,
condition=condition
)
self.roles.setdefault(role, set()).add(perm)
# 清除相关缓存
self._clear_cache_for(resource)代码18:改进的权限管理器
15.2 行为审计系统
全链路审计追踪实现:
class AuditSystem:
def __init__(self, storage_backend):
self.storage = storage_backend
self.event_queue = asyncio.Queue()
self.consumer_task = asyncio.create_task(
self._event_consumer()
)
async def log_event(self, event_type, details):
"""记录审计事件"""
event = {
'timestamp': datetime.utcnow().isoformat(),
'type': event_type,
'details': details,
'trace_id': self._get_current_trace()
}
await self.event_queue.put(event)
async def _event_consumer(self):
"""异步处理审计事件"""
batch = []
last_flush = time.time()
while True:
try:
# 批量收集事件
timeout = 1.0 # 最长1秒刷新一次
event = await asyncio.wait_for(
self.event_queue.get(),
timeout=max(0, last_flush + 1 - time.time())
)
batch.append(event)
# 批量写入条件
if len(batch) >= 100 or time.time() - last_flush >= 1.0:
await self._flush_batch(batch)
batch = []
last_flush = time.time()
except asyncio.TimeoutError:
if batch:
await self._flush_batch(batch)
batch = []
last_flush = time.time()
async def _flush_batch(self, batch):
"""批量写入存储"""
try:
await self.storage.bulk_insert(batch)
except Exception as e:
logging.error(f"Audit log flush failed: {str(e)}")
# 失败时写入本地临时文件
self._write_to_fallback(batch)代码19:审计系统实现
十六、实际应用案例研究
16.1 智能CI/CD流水线

图6:智能CI/CD流水线
实现关键点:
class SmartCICD:
def __init__(self, agent_manager):
self.agents = agent_manager
self.pipeline = TaskGraph()
def setup_pipeline(self, repo_config):
"""配置智能流水线"""
# 构建任务图
self.pipeline.add_task('analyze', {
'type': 'code_analysis',
'agent': 'code_analyzer'
})
self.pipeline.add_task('refactor', {
'type': 'auto_refactor',
'agent': 'refactor_agent'
})
self.pipeline.add_dependency('analyze', 'refactor')
# 条件依赖
self.pipeline.add_conditional_edge(
source='analyze',
target='refactor',
condition=lambda r: r['needs_refactor']
)
async def run(self, commit):
"""执行流水线"""
# 获取拓扑顺序
execution_order = self.pipeline.get_execution_order()
results = {}
for task_id in execution_order:
task_info = self.pipeline.nodes[task_id]
agent = self.agents.get(task_info['agent'])
# 执行任务
result = await agent.execute(
task_info['type'],
{'commit': commit}
)
results[task_id] = result
# 处理条件分支
if 'condition' in task_info:
if not task_info['condition'](result):
# 跳过后续依赖任务
break
return results代码20:智能CI/CD实现
十七、未来演进方向
17.1 认知架构升级路线
- 分层记忆系统:
-
- 瞬时记忆(<1秒)
- 工作记忆(≈20秒)
- 长期记忆(持久化)
- 元学习能力:
-
- 学习如何学习
- 动态调整学习算法
- 理论推理:
-
- 符号逻辑与神经网络结合
- 可解释的推理过程
17.2 量子计算准备
量子神经网络(QNN)集成方案:
class QuantumEnhancedAgent:
def __init__(self, qpu_backend):
self.qpu = qpu_backend
self.classical_nn = NeuralNetwork()
self.quantum_cache = {}
def hybrid_predict(self, inputs):
"""混合量子-经典预测"""
# 经典部分处理
classical_out = self.classical_nn(inputs)
# 量子部分处理
qhash = self._hash_input(inputs)
if qhash in self.quantum_cache:
quantum_out = self.quantum_cache[qhash]
else:
quantum_out = self._run_quantum_circuit(inputs)
self.quantum_cache[qhash] = quantum_out
# 融合输出
return 0.7 * classical_out + 0.3 * quantum_out
def _run_quantum_circuit(self, inputs):
"""在QPU上运行量子电路"""
circuit = self._build_circuit(inputs)
job = self.qpu.run(circuit, shots=1000)
result = job.result()
return self._decode_counts(result.get_counts())代码21:量子增强Agent原型
十八、结论
Trae 04.22版本通过深度技术革新,在以下方面实现了突破:
- 认知能力跃迁:
-
- 动态技能组合使Agent具备弹性能力
- 自适应学习框架支持持续进化
- 协同计算革命:
-
- MCP市场的分布式事务支持
- 跨平台服务发现与负载均衡
- 工程实践创新:
-
- 可视化任务分解与编排
- 混合批处理与流式执行
- 安全体系强化:
-
- 细粒度权限控制
- 全链路审计追踪
这些技术进步使得Trae平台能够支持:
- 企业级复杂工作流自动化
- 跨组织协作的智能系统
- 安全关键型AI应用开发
随着量子计算等前沿技术的逐步集成,Trae平台将继续引领AI工程实践的发展方向。
十九、延伸阅读
- Distributed Systems: Concepts and Design - 分布式系统经典教材
- Deep Reinforcement Learning for Task Decomposition - 任务分解前沿研究
- Quantum Machine Learning: Progress and Prospects - 量子机器学习综述
- Trae Architecture White Paper - 官方架构白皮书

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 63
63 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)