智能医疗新时代:“脑启-素问”类脑医疗大模型引领未来
利用有限的矩阵状态来实现对历史信息的处理和存储,能够打破传统大模型在存储上的负担、也减少了时序建模中的计算开销,使模型。随着更多合作伙伴加入,预计这一平台将在未来发挥更加重要的作用,促进科学研究与实际应用之间的紧密结合,为社会创造更大的价值。阶段,整合高质量,多维度的通用领域和垂直领域训练数据集进行训练,在不丢失通用能力的情况下,医学专业能力得到显著提升。在偏好优化对齐阶段,采取了。进一步,这种矩
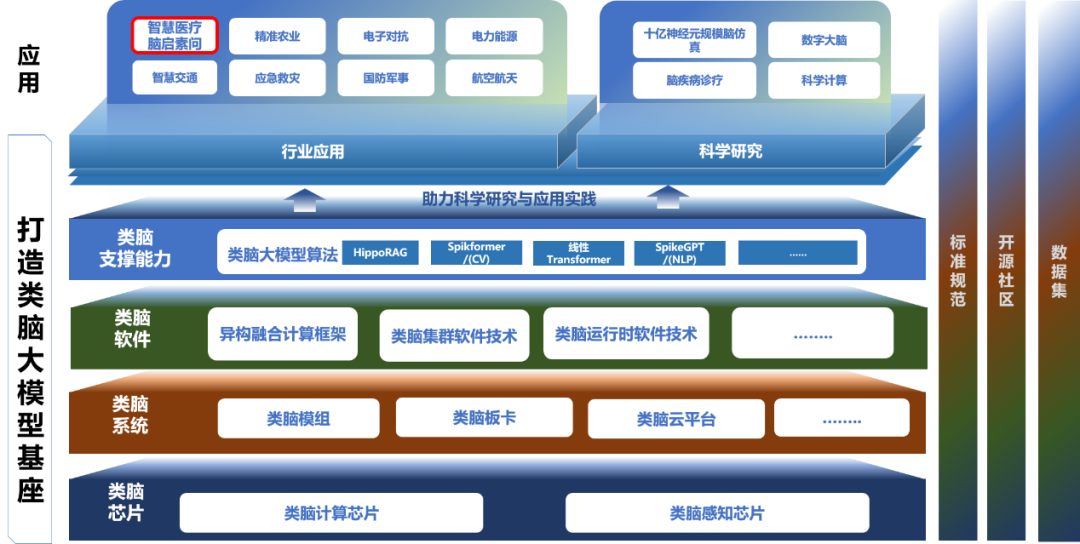
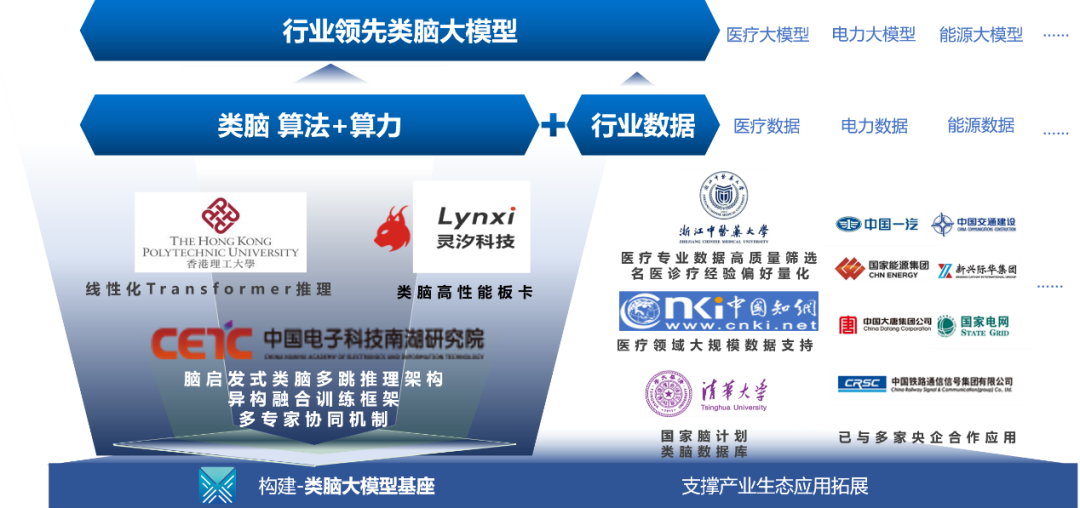
在人工智能技术的推动下,医疗行业正经历着前所未有的变革。中国电子科技南湖研究院成功研发基于类脑芯片、高性能类脑服务器以及先进的融合框架算力底座,为行业大模型的应用提供了坚实的硬件支持和技术保障,并率先在医疗行业落地,推出类脑医疗大模型产品-“脑启素问”。
类脑大模型基座的核心来自受生物脑启发的新一代计算模式-类脑计算,它不仅能够实现高效的数据处理能力,还能在能耗上展现出巨大优势。“脑启-素问”是基于类脑计算技术的前沿成果,旨在通过模拟生物大脑的记忆机制来提供高效且准确的智能医疗辅助和专业信息检索服务。该产品的核心在于其独特的类脑大模型技术。通过对现有大规模预训练模型进行改造,研究团队成功地将其转换成一种动态神经网络结构,大大减少了所需的计算资源,同时保持了高水平的性能。这种创新性的方法不仅提高了系统的响应速度,也降低了使用和维护的成本,使得更多医疗机构可以负担得起这项前沿技术。该模型的研发也标志着人工智能在大模型领域朝着更高效、更节能的方向迈进了重要一步。
类脑计算的优势
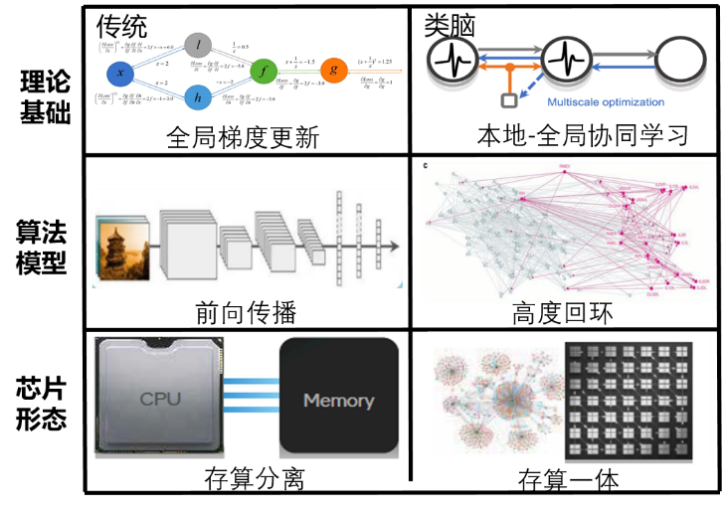
类脑计算是一种模仿生物大脑结构与功能的新一代计算模式。它不仅能够实现高效的数据处理能力,在能耗方面也具有显著优势。以人脑为例,拥有约860亿神经元的人脑仅需20瓦左右的功率;而传统超级计算机达到类似规模时则需要高达790万瓦的电力消耗。这种对比突显了类脑计算在能源效率上的巨大潜力。

硬件支持和技术保障
南湖研究院依托自主研发的类脑芯片、高性能类脑服务器以及先进的异构融合框架算力基座,为行业大模型的应用提供了坚实的硬件支持和技术保障。“脑启-素问”使用了灵汐科技的新型高性能类脑计算卡,该卡配置了多颗KA200芯片,支持深度学习模型的推理、训练以及类脑算法的复杂运算,可为云端大模型的推理和训练提供低功耗、高密度算力支持。
训练方法与优化策略
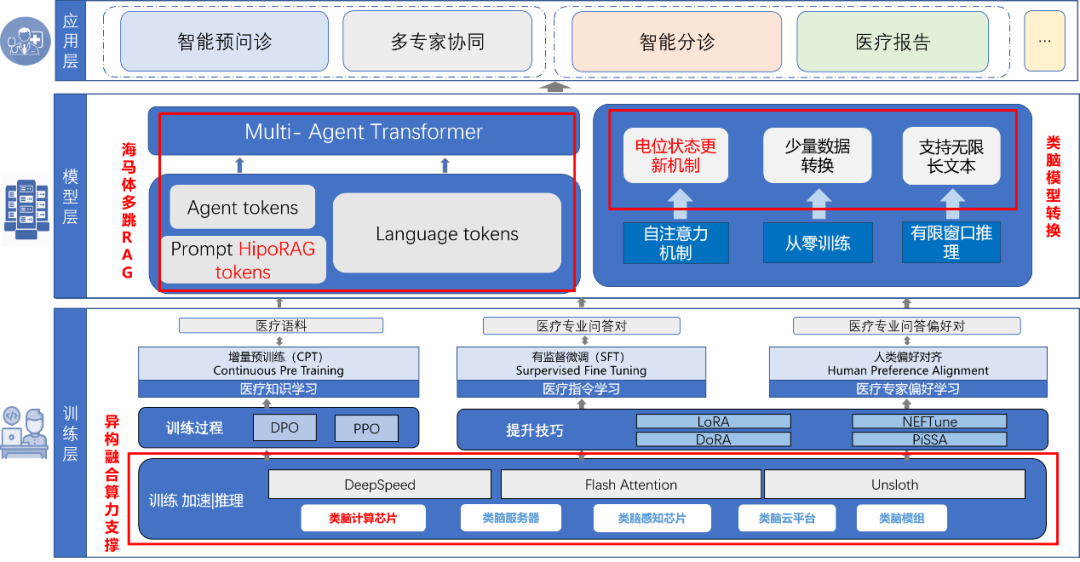
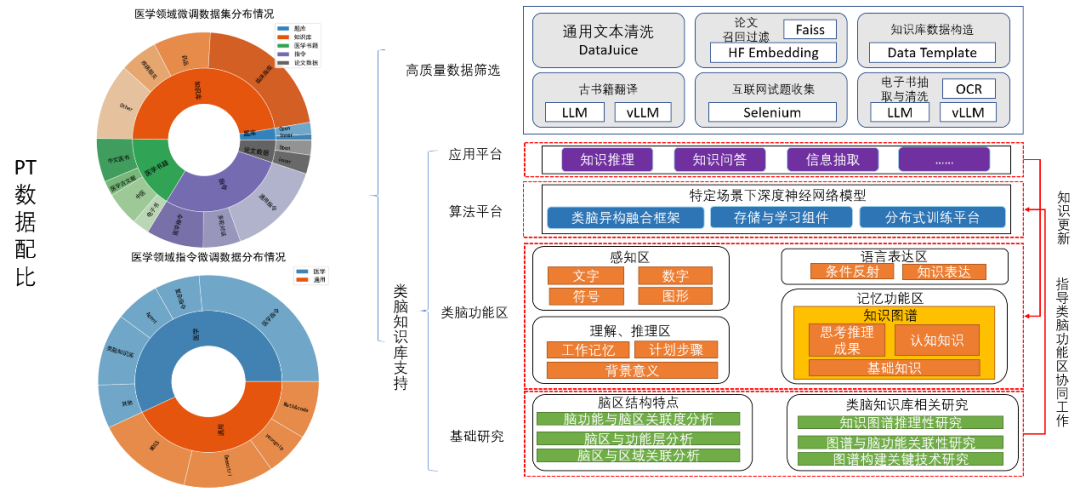
为了进一步提升模型在医学领域的专业性,团队从多个中医数据库中整合了大量数据,并经过清洗、分类和构建知识模块,形成了一个高质量、多维度的通用及垂直领域训练数据集。同时,为提高训练效率,集成了DeepSpeed框架与ZERO技术来优化多GPU训练过程,引入了Flash-Attention以减少内存和计算需求,并结合Liger Kernel进一步降低了约20%的GPU内存使用。同时研究人员采用了包括增量预训练(CPT)、有监督微调(SFT)及人类偏好对齐(DPO)在内的多种训练方法,使“脑启-素问”具备了强大的医疗知识理解和应用能力。
数据集构建与处理
脑启-素问”项目在数据构建方面,通过融合国家脑计划类脑知识库数据,为知识感知、理解、推理及认知提供强有力的支持,然后进行了广泛的数据收集工作,覆盖了书籍、医学对话记录、科研论文以及病例等多种类型的信息来源。这些原始材料经过严格的质量评估实验,包括过滤、OCR识别、文言文转换和去重等处理步骤,以确保数据集的高质量和多样性。最终形成的训练数据集由80%的专业医学内容和20%的通用领域信息组成,总容量达到30GB。
为了进一步提升模型性能,项目引入了一种基于类脑海马体机制的多跳RAG算法,结合类脑数据库来构造多条推理样本。同时,还利用开源医学指令数据增加了复杂指令、通用指令、数学与编程任务、文学创作以及多任务处理等方面的训练内容。在整个过程中,动态学习与自适应优化策略被应用于针对测试中发现的问题案例调整数据配比,并针对性地强化相关问题解决能力。对于监督微调(SFT)阶段,整合高质量,多维度的通用领域和垂直领域训练数据集进行训练,在不丢失通用能力的情况下,医学专业能力得到显著提升。在偏好优化对齐阶段,采取了直接偏好优化(DPO)方法,通过反馈循环和人类评审,优化模型对人类需求的响应,确保其应用更人性化和合规。整个流程强调了从数据准备到模型训练再到持续迭代优化的闭环管理,确保“脑启-素问”能够高效准确地服务于医疗健康领域。
创新性类脑架构
“脑启-素问”引入了一种创新性的类脑多跳RAG技术,借鉴了人类大脑中海马体与新皮层之间的工作原理,提高了信息检索的速度和准确性。在人类大脑中,海马体是记忆形成、存储以及空间导航的关键区域。它能够将短期记忆转化为长期记忆,并且在回忆过程中起到关键作用。新皮层则负责处理复杂的认知功能,如语言理解、视觉感知、决策制定等。当人们需要检索特定信息时,海马体会激活相关的记忆片段,然后新皮层会对这些片段进行加工和解释,最终完成信息的检索过程。这种从海马体到新皮层的信息传递机制,使得人类能够在面对大量信息时快速而准确地找到所需内容。
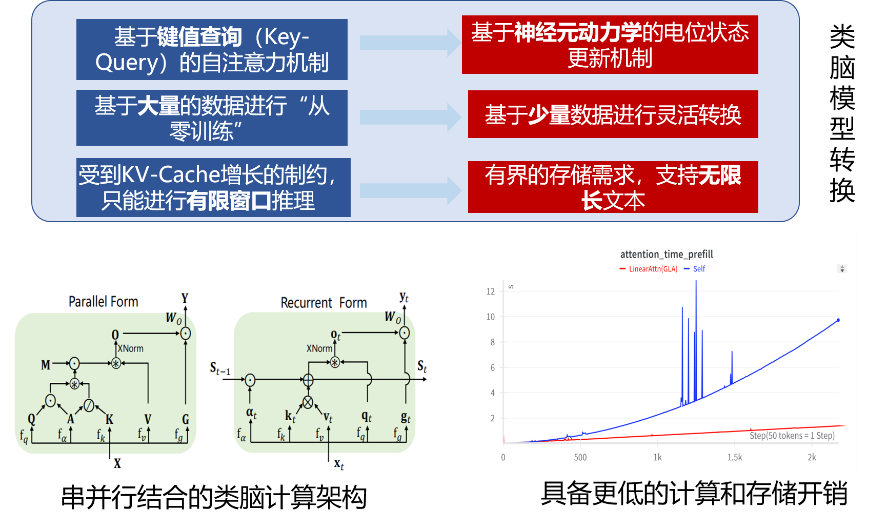
“脑启-素问”的大模型架构也模仿了类脑机制。该模型通过构建高质量多维度的数据集,利用树突神经元动力学模型(非Transformer架构)进行类脑化转换,实现增量预训练和医疗偏好对齐。具体来说,这种架构运用矩阵状态来替代KV-Cache,用以模拟神经突触的电位变化。这一基于神经动力学的架构撼动了基于KV-Cache的Self-Attention注意力机制的统治地位。利用有限的矩阵状态来实现对历史信息的处理和存储,能够打破传统大模型在存储上的负担、也减少了时序建模中的计算开销,使模型更轻更快。进一步,这种矩阵更新的时序建模模式使该模型同时具备传统人工神经网络的运算效率,也具备神经动力学上的可解释性和丰富的表达性。
这种设计方式提高了数据处理效率,大幅减少了算力开销,展现出巨大的能耗优势。在实际应用中,“脑启-素问”模拟人脑的记忆机制,深度学习临床指南、药品知识、疾病知识、检查体系和中医学等专业知识,针对不同医疗场景提供精准诊断支持。此外,“脑启-素问”具备多层次语义理解能力,这得益于其强大的算力底座和动态灵活的学习模型。该系统部署于自主研发的脑启云,也可以根据需求本地化集群部署,以满足不同类型的应用场景。对于普通用户而言,他们可以通过简单的线上操作与“脑启-素问”互动,获取定制化的健康咨询、初步诊断及科学用药建议;而对于专业医护人员来说,这款工具则成为了一个强大的医学助手,帮助医生更加快速便捷地了解患者情况,做出更加精准的治疗方案。
“脑启-素问”的成功开发并非孤立事件,而是中国电科南湖研究院协同多家机构共同努力的结果。在整个研发过程中,清华大学、香港理工大学、浙江中医药大学、同方知网等多个技术团队共同参与了医疗数据准备、清洗、模型训练以及产品研发等工作。正是这种跨学科合作模式,才使得“脑启-素问”能够在中文医疗模型评估(CMB-Exam)排名中以平均分94.12的成绩夺得第一。
产业生态合作与发展
目前,“脑启-素问”已与多家中央企业达成合作,共同推动智慧医疗等多个领域的智能化发展。随着更多合作伙伴加入,预计这一平台将在未来发挥更加重要的作用,促进科学研究与实际应用之间的紧密结合,为社会创造更大的价值。
“脑启-素问”代表了当前人工智能研究领域的一个重要里程碑,它不仅展示了类脑计算技术的巨大潜力,也为解决复杂问题提供了新的思路和工具。随着技术不断进步和完善,相信“脑启-素问”将在更多应用场景下展现其独特魅力。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)