【AI论文】Dragon Hatchling:Transfomer与大脑模型之间的缺失环节
摘要:本研究提出"龙之幼崽"(BDH)模型,一种基于无标度生物网络的创新大语言模型架构。BDH结合了Transformer的性能优势与生物神经网络的可解释特性,通过局部神经元粒子的相互连接实现推理过程。实验表明,在10M-1B参数规模下,BDH在语言建模和翻译任务上表现与GPT2相当,同时展现出类脑网络的高模块化特征。模型采用稀疏激活和Hebbian学习机制,在处理特定概念时能
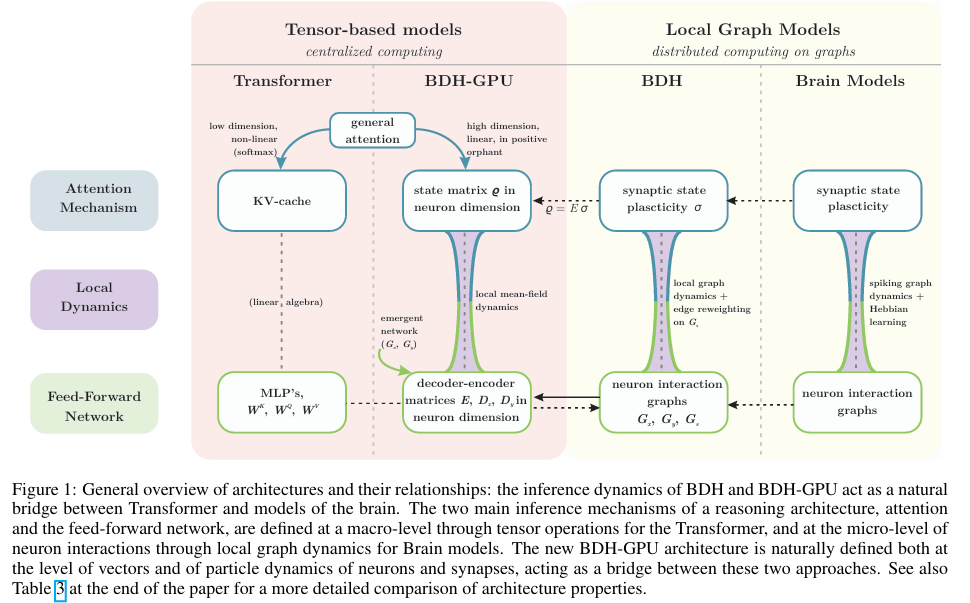
摘要:自约翰·冯·诺依曼(John von Neumann)和艾伦·图灵(Alan Turing)以来,计算系统与大脑之间的关系一直是先锋理论家们的动力源泉。诸如大脑这类统一且无标度的生物网络具有强大的特性,包括随时间进行泛化推理的能力,而这正是机器学习在通往通用推理模型道路上遇到的主要障碍。我们引入了“龙之幼崽”(BDH,Baby Dragon Hatchling),这是一种基于无标度生物启发网络的新型大语言模型架构,该网络由局部相互作用的神经元粒子构成。BDH在具备强大理论基础和内在可解释性的同时,并未牺牲类似Transformer模型的性能。BDH是一种实用、高效且先进的基于注意力的状态空间序列学习架构。除了作为图模型外,BDH还支持便于GPU处理的公式表达。它展现出与Transformer类似的缩放规律:实证表明,在相同参数数量(1000万到10亿)和相同训练数据下,BDH在语言和翻译任务上的性能可与GPT2相媲美。BDH可以被视为一种大脑模型。在推理过程中,BDH的工作记忆完全依赖于具有赫布学习规则(Hebbian learning)的突触可塑性,该规则利用脉冲神经元进行学习。我们通过实证确认,每当BDH在处理语言输入时听到或推理某个特定概念时,特定的单个突触就会加强连接。BDH的神经元交互网络是一个具有高度模块化和重尾度分布的图。BDH模型在生物学上是合理的,它解释了人类神经元可能用于实现言语的一种可能机制。BDH的设计注重可解释性。BDH的激活向量是稀疏且为正的。我们在语言任务上展示了BDH的单义性。状态的可解释性(这超出了神经元和模型参数的可解释性)是BDH架构的固有特性。Huggingface链接:Paper Page,论文链接:2509.26507
研究背景和目的
研究背景:
自约翰·冯·诺依曼和艾伦·图灵以来,计算系统与大脑之间的关系一直是理论先驱们的灵感来源。大脑作为一种均匀、无标度的生物网络,具有强大的泛化能力,尤其是在时间上的泛化,这是机器学习在迈向通用推理模型过程中面临的主要障碍。
传统Transformer模型虽然在自然语言处理任务中取得了巨大成功,但其推理能力在面对比训练时更长的场景时,往往无法系统地泛化链式推理(Chain-of-Thought, CoT)。与此同时,大脑作为一种由约8×1010个神经元和超过1014个神经连接组成的极其复杂的图基分布式计算系统,其直接模拟对语言模型来说需要数十亿的CoT标记来表示大脑推理的一个步骤,这在实际应用中显然不现实。因此,寻找一种更接近大脑功能且能高效模拟人类推理过程的计算模型成为当前研究的热点。
研究目的:
本研究旨在引入一种名为“Dragon Hatchling”(BDH)的新型大语言模型架构,该架构基于无标度的生物启发网络,由本地交互的神经元粒子组成。
BDH不仅结合了强大的理论基础和固有的可解释性,还不牺牲Transformer般的性能。通过BDH,研究者希望揭示模型行为在大规模和长时间推理下的理论基础,提供对语言和推理模型的新理解,并推动通用近似正确(Probably Approximately Correct, PAC)类泛化推理边界的研究。
研究方法
模型架构设计:
BDH模型采用了一种基于本地分布式图动态的大语言模型架构。
其核心在于通过局部边缘重加权过程(edge-reweighting process)实现注意力机制,这一过程被定义为“推理的方程”(equations of reasoning)。BDH的神经元互动网络是一个高模块化、重尾度分布的图结构,其中神经元被组织为兴奋性和抑制性电路,并利用整合-发放阈值机制处理输入信号。工作记忆在BDH推理过程中完全依赖于具有Hebbian学习机制的突触可塑性,每次处理语言输入时,特定的突触连接会在听到或推理特定概念时得到加强。
BDH-GPU实现:
为了提升计算效率,研究还提出了BDH-GPU架构,该架构是BDH的一种张量友好型版本。
BDH-GPU通过低秩分解和线性注意力机制,在保持参数和状态大小的同时,实现了高效的GPU计算。具体实现中,BDH-GPU利用ReLU-低秩前馈网络和线性注意力机制,在相同的神经元维度上操作,使用正激活向量,并通过LayerNorm进行归一化处理。
实验验证:
研究通过多个实验验证了BDH和BDH-GPU模型的性能。
实验包括语言建模和翻译任务,使用Europarl语料库进行训练和评估。在语言建模任务中,BDH-GPU模型在不同参数规模下(从10M到1B)均展示了与GPT2架构Transformer相当的性能。此外,研究还通过模型合并实验展示了BDH-GPU的可扩展性和模块化特性。
研究结果
性能表现:
实验结果表明,BDH-GPU模型在语言建模和翻译任务中均取得了优异的表现。
在相同参数数量和训练数据的情况下,BDH-GPU与GPT2架构的Transformer性能相当,甚至在某些情况下超越了后者。这一结果证明了BDH架构的有效性和高效性。
模块化与无标度结构:
研究还发现,BDH-GPU模型在训练过程中自然形成了具有高模块化和无标度特性的神经元互动网络。
这种结构不仅提高了信息传播的效率,还增强了模型的泛化能力。通过分析参数矩阵的重尾元素分布和模块性,研究证实了BDH-GPU模型能够自发地形成有效的信息传播路径和社区结构。
注意力机制与稀疏激活:
BDH-GPU模型中的线性注意力机制能够放大查询和键之间微小差异,从而实现高效的注意力计算。
同时,模型的激活向量表现出稀疏性,这不仅提高了模型的可解释性,还降低了计算复杂度。实验表明,BDH-GPU模型在不同层次的神经元中均表现出稀疏激活特性,尤其是在处理可预测输入时,神经元活动显著减少。
研究局限
尽管BDH和BDH-GPU模型在多个方面取得了显著成果,但研究仍存在一些局限性。首先,BDH模型的理论基础虽然强大,但在实际应用中仍需进一步验证其泛化能力和鲁棒性。
其次,BDH-GPU架构虽然提高了计算效率,但其实现复杂度仍然较高,尤其是在处理大规模数据集时。此外,模型的稀疏激活特性虽然提高了可解释性,但也可能导致在某些复杂任务中表现不佳。
未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
-
泛化能力与鲁棒性验证:通过更多的实验和实际应用场景,验证BDH和BDH-GPU模型在不同任务和数据集上的泛化能力和鲁棒性。
这有助于进一步巩固模型的理论基础,并推动其在实际中的应用。 -
架构优化与简化:针对BDH-GPU架构的实现复杂度问题,研究可以探索更高效的实现方式和优化策略。
例如,通过改进低秩分解和线性注意力机制,减少计算量和参数数量,提高模型的训练和推理速度。 -
多模态与跨模态学习:将BDH和BDH-GPU模型扩展到多模态和跨模态学习任务中,探索其在处理图像、音频等多种类型数据时的性能和表现。这有助于推动模型在更广泛领域的应用和发展。
-
可解释性与透明性提升:进一步研究BDH和BDH-GPU模型的可解释性和透明性,探索如何通过改进模型结构和训练策略,提高模型决策过程的可解释性。
这有助于增强用户对模型的信任度,并推动模型在关键领域的应用。 -
长期依赖与记忆机制:研究BDH和BDH-GPU模型在处理长期依赖和记忆机制方面的能力,探索如何通过改进模型结构和训练策略,提高模型在处理长序列数据时的性能和表现。
这有助于推动模型在自然语言处理、时间序列分析等领域的应用和发展。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 27
27 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)