RBF模糊神经网络在自适应调整PID中的奇妙之旅
RBF模糊神经网络用于自适应调整PID;包含三个独立的程序:传统PID、梯度下降学习网络参数、以及PSO离线优化网络与梯度下降在线调整网络参数。包含了详细的说明:传递函数的离散化处理方法、模糊神经网络的理论说明以及程序说明等四部分内容。请注意:不提供修改传递函数、输入的服务(这一部分的修改方法已经在说明当中注明了)嘿,大家好!今天来聊聊超有趣的 RBF 模糊神经网络用于自适应调整 PID 这个话题
RBF模糊神经网络用于自适应调整PID; 包含三个独立的程序:传统PID、梯度下降学习网络参数、以及PSO离线优化网络与梯度下降在线调整网络参数。 包含了详细的说明:传递函数的离散化处理方法、模糊神经网络的理论说明以及程序说明等四部分内容。 请注意:不提供修改传递函数、输入的服务(这一部分的修改方法已经在说明当中注明了)
嘿,大家好!今天来聊聊超有趣的 RBF 模糊神经网络用于自适应调整 PID 这个话题。这其中包含了三个非常有意思且独立的程序,咱们一个个来扒一扒。
传统PID
PID 控制想必各位搞控制的小伙伴都不陌生,它简单又强大。咱们先来看看简单的 PID 代码实现(以Python为例):
class PID:
def __init__(self, kp, ki, kd):
self.kp = kp
self.ki = ki
self.kd = kd
self.prev_error = 0
self.integral = 0
def update(self, setpoint, process_variable):
error = setpoint - process_variable
self.integral += error
derivative = error - self.prev_error
output = self.kp * error + self.ki * self.integral + self.kd * derivative
self.prev_error = error
return output在这段代码里,init 函数初始化了比例系数 kp、积分系数 ki 和微分系数 kd,同时记录上一次的误差 preverror 和积分项 integral。update 函数则根据当前的设定值 setpoint 和过程变量 processvariable 计算误差,进而得出积分和微分项,最终返回 PID 的控制输出。传统 PID 控制是经典之作,但在面对复杂多变的系统时,就有点力不从心啦,这时候 RBF 模糊神经网络就闪亮登场咯。
梯度下降学习网络参数
RBF 模糊神经网络是一种结合了模糊逻辑和神经网络优点的智能算法。先讲讲模糊神经网络的理论,它把输入空间通过模糊化处理,映射到模糊规则空间,再经过解模糊得到输出。而 RBF 神经网络则是以径向基函数作为激活函数。
咱们看看梯度下降学习网络参数的代码片段(这里假设使用简单的全连接神经网络结构,以PyTorch为例):
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleRBFNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRBFNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.rbf = nn.Tanh()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.rbf(out)
out = self.fc2(out)
return out
# 假设数据准备好的X和Y
model = SimpleRBFNet(input_size=2, hidden_size=10, output_size=1)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()这里定义了一个简单的 RBF 神经网络模型 SimpleRBFNet,包含一个全连接层 fc1,接着使用 Tanh 作为类似 RBF 的激活函数(实际 RBF 函数形式不同,这里简化说明),再经过另一个全连接层 fc2 输出。在训练过程中,通过均方误差损失函数 MSELoss 计算损失,使用随机梯度下降 SGD 优化器不断更新网络参数,使得损失逐渐减小。
PSO离线优化网络与梯度下降在线调整网络参数
粒子群优化算法(PSO)是一种基于群体智能的优化算法。用 PSO 离线优化网络参数,就是在训练之前,利用 PSO 找到一组较好的初始网络参数。之后,再利用梯度下降在线调整这些参数。
下面简单示意一下 PSO 算法(以Python为例):
import numpy as np
def pso(func, dim, num_particles, max_iter, w, c1, c2, bounds):
positions = np.random.uniform(bounds[0], bounds[1], (num_particles, dim))
velocities = np.zeros((num_particles, dim))
pbest_positions = positions.copy()
pbest_fitness = np.array([func(p) for p in positions])
gbest_index = np.argmin(pbest_fitness)
gbest_position = pbest_positions[gbest_index]
gbest_fitness = pbest_fitness[gbest_index]
for i in range(max_iter):
r1 = np.random.rand(num_particles, dim)
r2 = np.random.rand(num_particles, dim)
velocities = w * velocities + c1 * r1 * (pbest_positions - positions) + c2 * r2 * (gbest_position - positions)
positions = positions + velocities
positions = np.clip(positions, bounds[0], bounds[1])
fitness = np.array([func(p) for p in positions])
improved_indices = fitness < pbest_fitness
pbest_positions[improved_indices] = positions[improved_indices]
pbest_fitness[improved_indices] = fitness[improved_indices]
current_best_index = np.argmin(pbest_fitness)
if pbest_fitness[current_best_index] < gbest_fitness:
gbest_position = pbest_positions[current_best_index]
gbest_fitness = pbest_fitness[current_best_index]
return gbest_position这段代码实现了基本的 PSO 算法,func 是目标函数,dim 是参数维度,numparticles 是粒子数量,maxiter 是最大迭代次数,w 是惯性权重,c1 和 c2 是学习因子,bounds 是参数的取值范围。PSO 通过不断更新粒子的位置和速度,寻找最优解。在 RBF 模糊神经网络中,我们可以把网络参数作为粒子位置,以损失函数作为目标函数,用 PSO 找到一组较好的初始参数,然后结合梯度下降在线微调,进一步优化网络性能。
传递函数的离散化处理方法
在实际应用中,连续的传递函数需要离散化才能在计算机上实现。常见的离散化方法如双线性变换法。假设我们有一个连续传递函数 $G(s)=\frac{1}{s + 1}$,使用双线性变换 $s=\frac{2}{T}\frac{1 - z^{-1}}{1 + z^{-1}}$($T$ 是采样周期)。
将其代入传递函数得到:
\[
\begin{align*}

G(z)&=\frac{1}{\frac{2}{T}\frac{1 - z^{-1}}{1 + z^{-1}}+1}\\
&=\frac{1 + z^{-1}}{\frac{2}{T}(1 - z^{-1})+(1 + z^{-1})}\\
&=\frac{T(1 + z^{-1})}{2(1 - z^{-1})+T(1 + z^{-1})}
\end{align*}
\]
这样就完成了传递函数从连续域到离散域的转换。通过离散化,我们可以方便地在数字控制系统中使用传递函数进行系统分析和设计。
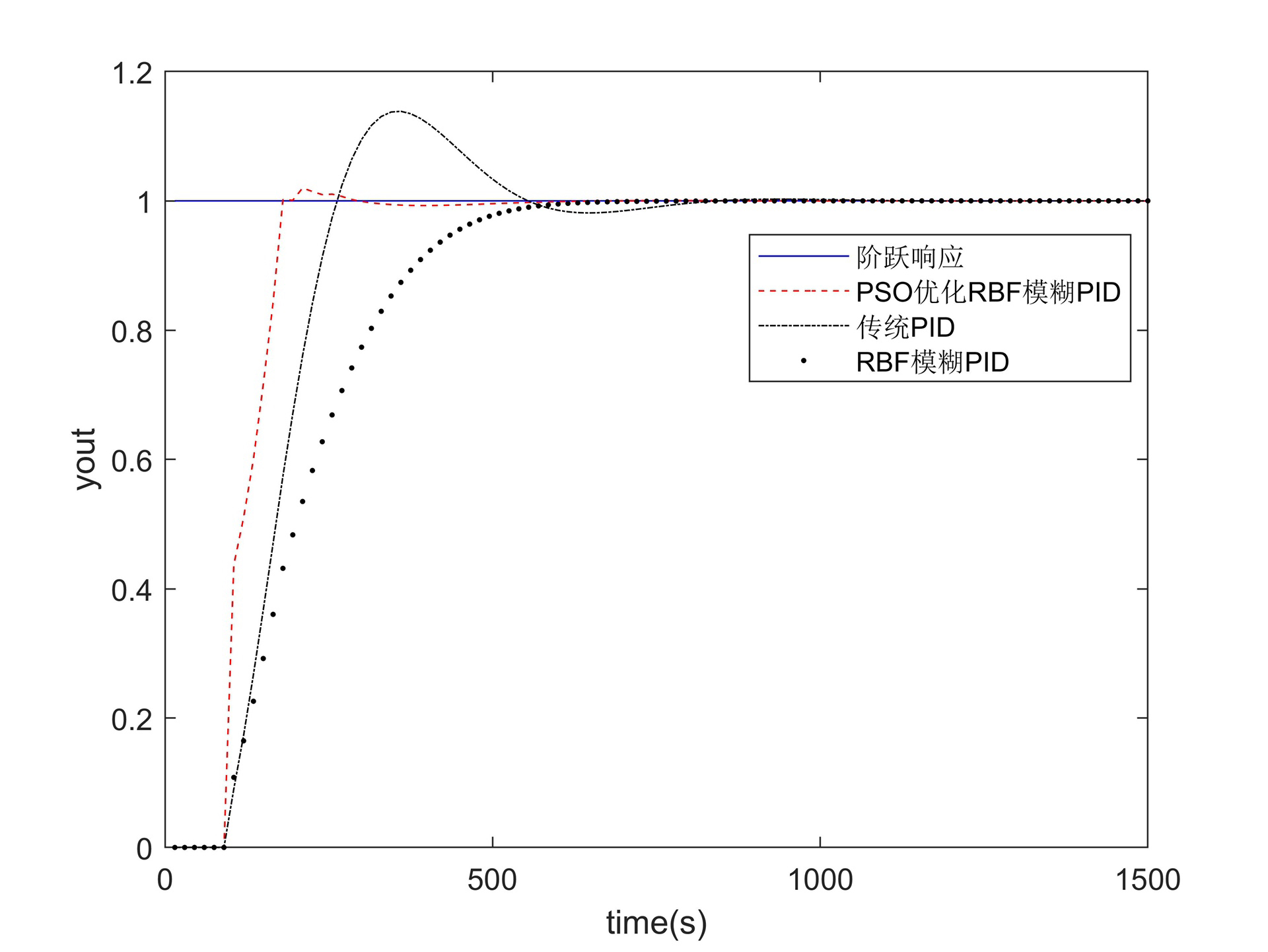
总之,RBF 模糊神经网络与 PID 的结合,通过这三个独立程序以及传递函数离散化等处理,为复杂系统的控制提供了更强大、自适应的解决方案。希望今天的分享能让大家对这个领域有更深入的了解!欢迎一起交流探讨呀。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)