论文解读:Denoising Diffusion Probabilistic Models(DDPM,去噪扩散概率模型)
在深度学习领域,生成模型一直被视为皇冠上的明珠。从早期的变分自编码器(VAE)和生成对抗网络(GAN),到强大的自回归模型(如PixelCNN),研究者们一直在探索如何让机器学会“创造”。2020年,Google Research的Jonathan Ho等人在论文《Denoising Diffusion Probabilistic Models》中提出了一种新的生成模型——去噪扩散概率模型,它不仅
一、论文解读
引言:从判别式模型到生成式模型的范式转变
在深度学习领域,生成模型一直被视为皇冠上的明珠。从早期的变分自编码器(VAE)和生成对抗网络(GAN),到强大的自回归模型(如PixelCNN),研究者们一直在探索如何让机器学会“创造”。2020年,Google Research的Jonathan Ho等人在论文《Denoising Diffusion Probabilistic Models》中提出了一种新的生成模型——去噪扩散概率模型,它不仅能够生成高质量图像,更在理论上建立了与去噪得分匹配、朗之万动力学等多种方法的深刻联系。
DDPM的核心思想既直观又深刻:如果我们教会一个模型如何一步步地将一张完全随机的噪声图片“去噪”还原成一张清晰的真实图片,那么我们就可以通过从随机噪声开始,反复应用这个去噪模型,最终生成全新的图片。

1 核心原理:扩散与去噪
DDPM包含两个关键过程:前向扩散过程和反向去噪过程。
1.1 前向扩散过程:逐步加噪
前向过程是一个固定的马尔可夫链,逐步向数据添加高斯噪声,直到数据完全退化为随机噪声。
q(x1:T∣x0):=∏t=1Tq(xt∣xt−1),q(xt∣xt−1):=N(xt;1−βtxt−1,βtI) q(x_{1:T} \mid x_0) := \prod_{t=1}^{T} q(x_t \mid x_{t-1}), \quad q(x_t \mid x_{t-1}) := \mathcal{N}\left(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t I\right) q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)
其中βt\beta_tβt是预先定义的噪声调度参数。
想象给一张清晰照片逐步添加"马赛克"。每一步都按照固定规则加入少量噪声,就像调酒时一步步加入配料。这个过程的巧妙之处在于,我们可以"跳步"计算——不需要一步步加噪,而是可以直接算出任意步骤后的结果:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)I)q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
- x0x_0x0:原始数据(如图像)。
- ttt:时间步,t=1,2,…,Tt = 1, 2, \ldots, Tt=1,2,…,T,TTT是总步数(通常为 1000)。
- βt\beta_tβt:噪声调度参数,预先定义的小正数(如从 10−410^{-4}10−4 线性增加到0.020.020.02),控制每一步的噪声量。
- αt\alpha_tαt:αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt,表示每一步保留的原始信号比例。
- αˉt\bar{\alpha}_tαˉt:累积乘积因子,αˉt:=∏s=1tαs\bar{\alpha}_t := \prod_{s=1}^{t} \alpha_sαˉt:=∏s=1tαs,表示到步数ttt时原始信号的累积保留比例。
- ϵ\epsilonϵ:标准高斯噪声,ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0, I)ϵ∼N(0,I)。
1.2 反向去噪过程:学习生成
反向过程是前向过程的逆过程,通过参数化的马尔可夫链从噪声中逐步重建数据。其核心是一个神经网络(如 U-Net)学习去噪。
pθ(x0:T):=p(xT)∏t=1Tpθ(xt−1∣xt),pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t)) p_\theta(x_{0:T}) := p(x_T) \prod_{t=1}^{T} p_\theta(x_{t-1} \mid x_t), \quad p_\theta(x_{t-1} \mid x_t) := \mathcal{N}\left(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)\right) pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt),pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
先验分布:p(xT)=N(xT;0,I)p(x_T) = \mathcal{N}(x_T; 0, I)p(xT)=N(xT;0,I)
- θ\thetaθ:神经网络参数。
- μθ(xt,t)\mu_\theta(x_t, t)μθ(xt,t):神经网络预测的xt−1x_{t-1}xt−1的均值。
- Σθ(xt,t)\Sigma_\theta(x_t, t)Σθ(xt,t):协方差矩阵,常简化为固定值(如 σt2I\sigma_t^2 Iσt2I,其中σt2=βt\sigma_t^2 = \beta_tσt2=βt或β~t\tilde{\beta}_tβ~t)。
这就像是教AI"修复老照片"的能力。从完全模糊的噪声开始,一步步猜测原始图像应该是什么样子。神经网络(通常是U-Net)就是学习这个"修复技巧"的学生。
关键点:
- 从纯噪声p(xT)=N(xT;0,I)p(x_T) = \mathcal{N}(x_T; 0, I)p(xT)=N(xT;0,I)开始
- 神经网络需要学习两个东西:均值(猜下一步图像)和方差(不确定性)
- 实践中,方差通常固定,让网络专注学习均值预测
1.3 变分下界优化
DDPM的训练通过优化负对数似然的变分下界实现:
E[−logpθ(x0)]≤Eq[−logpθ(x0:T)q(x1:T∣x0)]=:LE[-\log p_\theta(x_0)] \leq E_q\left[-\log \frac{p_\theta(x_{0:T})}{q(x_{1:T}|x_0)}\right] =: LE[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=:L
通过数学推导,这个目标可以分解为:
L=Eq[DKL(q(xT∣x0)∥p(xT))⏟LT+∑t>1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))⏟Lt−1−logpθ(x0∣x1)⏟L0]L = E_q[\underbrace{D_{KL}(q(x_T|x_0)\|p(x_T))}_{L_T} + \sum_{t>1} \underbrace{D_{KL}(q(x_{t-1}|x_t,x_0)\|p_\theta(x_{t-1}|x_t))}_{L_{t-1}} \underbrace{-\log p_\theta(x_0|x_1)}_{L_0}]L=Eq[LT
DKL(q(xT∣x0)∥p(xT))+t>1∑Lt−1
DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0
−logpθ(x0∣x1)]
通俗理解:训练目标就像是一个"多科目考试":
- LTL_TLT:最终状态要接近纯噪声(这科很简单,基本是送分题)
- Lt−1L_{t-1}Lt−1:主要科目!让神经网络学的去噪步骤接近真实的逆过程
- L0L_0L0:最后一步要能完美重建原图
1.4 关键参数化:预测噪声而非均值
论文的一个重要贡献是提出了预测噪声的参数化方法。前向过程后验q(xt−1∣xt,x0)q(x_{t-1}|x_t, x_0)q(xt−1∣xt,x0)有闭式解:
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)q(x_{t-1}|x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I)q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)
其中μ~t=αˉt−1βt1−αˉtx0+αt(1−αˉt−1)1−αˉtxt\tilde{\mu}_t = \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0 + \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_tμ~t=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt
作者发现,与其让神经网络直接预测μ~t\tilde{\mu}_tμ~t,不如预测添加到图像中的噪声ϵ\epsilonϵ。这导致了简化的训练目标:
Lsimple(θ):=Et,x0,ϵ[∥ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∥2]L_{simple}(\theta) := E_{t,x_0,\epsilon}[\|\epsilon - \epsilon_\theta(\sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon, t)\|^2]Lsimple(θ):=Et,x0,ϵ[∥ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∥2]
这种参数化不仅简化了训练,还建立了与去噪得分匹配的理论联系。
通俗理解:与其让AI直接"画出一张完整的修复图",不如让它"指出哪里是噪声需要去除"。这就像:
- 旧方法:“请画出这张照片去掉马赛克后的样子”
- 新方法:“请圈出这张照片中哪些是马赛克噪点”
这种"预测噪声"的参数化有三大优势:
- 训练更稳定:预测噪声比预测整张图像更容易
- 理论更优美:与去噪得分匹配建立了联系
- 实践更有效:在实验中表现更好
实际训练过程:
- 随机选一张训练图片x0x_0x0
- 随机选一个时间步ttt
- 生成带噪图片xt=αˉtx0+1−αˉtϵx_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilonxt=αˉtx0+1−αˉtϵ
- 让网络预测噪声ϵθ(xt,t)\epsilon_\theta(x_t, t)ϵθ(xt,t)
- 比较预测噪声与真实噪声的差异作为损失
2 架构与实现:U-Net上的扩散过程
DDPM 对原始用于图像分割的 U-Net 架构进行了多项关键性修改,以更好地适应图像生成任务,特别是去噪这一核心目标。这些修改旨在提升网络的特征提取能力、训练稳定性,以及在不同噪声水平下进行条件生成的能力。
2.1 主干网络:从 VGG 到 ResNet
- 原始 U-Net (2015):编码器和解码器主要由简单的卷积层和池化层构成,基础单元是连续的两个卷积层。
- DDPM U-Net:借鉴了 PixelCNN++ 和 Wide ResNet 的思想,将基础的卷积块替换为残差块(ResNet Block)。
- 缓解梯度消失:更深的网络能够有效学习更复杂的去噪函数。
- 提升特征复用:残差连接使梯度流动更顺畅,加快了训练收敛。
- 增强特征表示:残差块本身具有更强的特征提取能力。
2.2 归一化层:从批归一化(BN)到组归一化(GN)
- 原始 U-Net:未明确使用归一化层,或使用批归一化(Batch Normalization)。
- DDPM U-Net:使用组归一化(Group Normalization),对小批量大小不敏感:扩散模型训练时,由于内存限制,每个设备的批量大小(per-device batch size)通常很小(可能为1或2)。BN 在小批量下表现不佳,因为其统计量估计不准确。而 GN 将通道分组进行归一化,不依赖批量维度,因此在小批量训练中更加稳定和有效。
2.3 引入自注意力机制
- 原始 U-Net:纯粹由卷积层构成,感受野有限,难以建模图像中的长距离依赖关系。
- DDPM U-Net:在编码器中间层(例如在 16x16 分辨率的特征图上)加入了自注意力层(Self-Attention Layer)。
- 捕获全局上下文:自注意力机制允许网络在每个位置关注图像的所有其他位置,这对于生成结构一致、全局协调的图像至关重要。例如,在生成一张脸时,网络需要确保左眼和右眼的对称性。
- 弥补卷积的局部性:卷积操作具有局部性,自注意力是对其的有效补充。
2.4 时间步嵌入(Timestep Embedding)
- 动机:去噪网络 ‘ϵθ(xt,t)‘`\epsilon_\theta(x_t, t)`‘ϵθ(xt,t)‘ 需要知道当前的时间步 ‘t‘`t`‘t‘,因为不同 ‘t‘`t`‘t‘ 对应的噪声水平和去噪任务是不同的。网络必须根据 ‘t‘`t`‘t‘ 来调整其行为。
- 实现:将时间步 ‘t‘`t`‘t‘ 通过一个 Transformer 式的正弦位置编码 映射为一个高维向量。这个向量之后会被注入到网络的多个地方,通常是:
- 添加到每个残差块的组归一化之后的特征上(通过一个特定的投影层)。
- 或者作为自适应归一化(如 AdaGN)的参数。
- 作用:这使得同一个网络能够处理从重度噪声(‘t‘`t`‘t‘ 接近 T)到轻度噪声(‘t‘`t`‘t‘ 接近 1)的整个谱系上的去噪任务。
2.5 参数共享
所有时间步 ttt 共享同一套网络参数。时间步信息通过上述的时间步嵌入来条件化网络。这大大减少了模型参数量,是一种非常高效的设计。
2.6 训练算法&采样生成
Algorithm 1 DDPM训练过程
输入: 数据分布q(x₀),噪声调度β₁...β_T,网络ε_θ
输出: 训练好的去噪网络ε_θ
1: repeat
2: x₀ ∼ q(x₀) # 从训练集采样真实图像
3: t ∼ Uniform({1, ..., T}) # 均匀采样时间步
4: ε ∼ N(0, I) # 采样随机噪声
5: x_t = √(ᾱ_t)x₀ + √(1-ᾱ_t)ε # 前向加噪
6: 计算梯度 ∇θ‖ε - ε_θ(x_t, t)‖² # 优化噪声预测误差
7: 更新参数θ
8: until 收敛
训练完成后,可以从纯噪声开始逐步生成新样本:
Algorithm 2 DDPM采样过程
输入: 训练好的ε_θ,时间步数T,噪声调度
输出: 生成的图像x₀
1: x_T ∼ N(0, I) # 从标准高斯分布采样初始噪声
2: for t = T, ..., 1 do # 从T到1逆向去噪
3: z ∼ N(0, I) if t > 1 else z = 0
4: x_{t-1} = 1/√α_t (x_t - (1-α_t)/√(1-ᾱ_t) ε_θ(x_t, t)) + σ_t z
5: end for
6: return x_0 # 最终生成的清晰图像
3 理论贡献
论文证明了DDPM的训练目标与多尺度去噪得分匹配等价。预测噪声ϵ\epsilonϵ本质上是在估计数据分布的对数概率梯度(得分函数):这一联系为理解扩散模型提供了新的视角。
∇xtlogp(xt)≈−ϵθ(xt,t)1−αˉt\nabla_{x_t} \log p(x_t) \approx -\frac{\epsilon_\theta(x_t, t)}{\sqrt{1-\bar{\alpha}_t}}∇xtlogp(xt)≈−1−αˉtϵθ(xt,t)
采样过程可以视为退火朗之万动力学,其中DDPM提供了学习到的梯度估计和自动的步长调度。
xt−1=xt+η2∇xtlogp(xt)+ηzx_{t-1} = x_t + \frac{\eta}{2} \nabla_{x_t} \log p(x_t) + \sqrt{\eta} zxt−1=xt+2η∇xtlogp(xt)+ηz
从率失真理论看,DDPM实现了一种渐进式有损压缩:在低码率区域,DDPM优先保留语义信息,细节信息随后补充。
- 码率:传输xT,...,x0x_T, ..., x_0xT,...,x0所需的信息量
- 失真:重建图像与原始图像的差异
4 使用示例
下面的示例代码展示了如何使用预训练的DDPM模型生成多组对比图像,直观展示不同生成步数对结果的影响。
import matplotlib.pyplot as plt
import torch
from diffusers import DDPMPipeline, DDIMScheduler
import time
from datetime import datetime
# 设置设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Device: {device}")
# 加载模型
pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to(device)
# 定义参数
steps_list = [1, 5, 50, 200] # 4种步长
seeds_list = [42, 123, 456, 789] # 4个随机种子
results = []
print(f"Generating {len(steps_list)} step variations × {len(seeds_list)} seeds = {len(steps_list)*len(seeds_list)} images")
# 生成图片
total_start_time = time.time()
for steps in steps_list:
for seed in seeds_list:
start_time = time.time()
# 为每个组合创建随机生成器
generator = torch.Generator(device=device).manual_seed(seed)
with torch.no_grad():
# 生成图片
images = pipe(
batch_size=1,
num_inference_steps=steps,
generator=generator
).images
generation_time = time.time() - start_time
img = images[0]
results.append((steps, seed, img, generation_time))
# 保存图片
img_path = f"ddpm_steps{steps}_seed{seed}.png"
img.save(img_path, "PNG")
print(f"Steps {steps}, Seed {seed}: {generation_time:.2f}s -> {img_path}")
total_time = time.time() - total_start_time
print(f"\nTotal generation time: {total_time:.2f}s")
# 创建4x4网格显示所有图片
fig, axes = plt.subplots(4, 4, figsize=(16, 16))
fig.suptitle(f"DDPM Generation Results ({len(steps_list)} steps × {len(seeds_list)} seeds)", fontsize=16, y=0.95)
for i, steps in enumerate(steps_list):
for j, seed in enumerate(seeds_list):
# 找到对应的结果
for result in results:
if result[0] == steps and result[1] == seed:
_, _, img, _ = result
axes[i, j].imshow(img)
axes[i, j].set_title(f'Steps: {steps}', fontsize=12) # 只显示步数
axes[i, j].axis('off')
break
plt.tight_layout()
# 保存网格图
grid_path = "ddpm_grid_all_results.png"
plt.savefig(grid_path, dpi=150, bbox_inches='tight')
print(f"\nGrid image saved: {grid_path}")
plt.show()
# 保存生成数据
data_path = "generation_data.txt"
with open(data_path, "w") as f:
f.write("DDPM Multi-step Multi-seed Generation Results\n")
f.write("=" * 60 + "\n")
f.write(f"Generation time: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"Device: {device}\n")
f.write(f"Model: google/ddpm-celebahq-256\n")
f.write(f"Steps tested: {', '.join(map(str, steps_list))}\n")
f.write(f"Seeds tested: {', '.join(map(str, seeds_list))}\n")
f.write("-" * 60 + "\n")
# 按步数分组
for steps in steps_list:
f.write(f"\nSteps: {steps}\n")
f.write("-" * 40 + "\n")
step_results = [r for r in results if r[0] == steps]
avg_time = sum(r[3] for r in step_results) / len(step_results)
f.write(f"Average time: {avg_time:.2f}s\n")
for r in step_results:
_, seed, _, gen_time = r
f.write(f" Seed {seed}: {gen_time:.2f}s\n")
f.write("-" * 60 + "\n")
f.write(f"Total images generated: {len(results)}\n")
f.write(f"Total generation time: {total_time:.2f}s\n")
print(f"Generation data saved: {data_path}")
# 打印性能摘要
print("\nPerformance summary:")
for steps in steps_list:
step_results = [r for r in results if r[0] == steps]
avg_time = sum(r[3] for r in step_results) / len(step_results)
print(f"Steps {steps}: average {avg_time:.2f}s per image")
print(f"\nAll {len(results)} images saved to current directory!")

二、论文翻译:去噪扩散概率模型
摘要
我们使用扩散概率模型展示了高质量的图像合成结果,这是一类受非平衡热力学启发的潜变量模型。我们的最佳结果是通过训练一个加权的变分界获得的,该变分界的设计基于扩散概率模型与使用朗之万动力学的去噪得分匹配之间的新颖联系。我们的模型自然地允许一种渐进式有损解压缩方案,可以解释为自回归解码的泛化。在无条件CIFAR10数据集上,我们获得了9.46的Inception分数和目前最先进的3.17的FID分数。在256x256 LSUN上,我们获得了与ProgressiveGAN相似的样本质量。我们的实现可在 https://github.com/hojonathanho/diffusion 获取。
1 引言
各种类型的深度生成模型最近在各种数据模态中产生了高质量的样本。生成对抗网络、自回归模型、流模型和变分自编码器已经合成了令人瞩目的图像和音频样本。基于能量的建模和得分匹配也取得了显著进展,产生了与GAN相媲美的图像。
本文展示了扩散概率模型方面的进展。扩散概率模型(为简洁起见,我们称之为“扩散模型”)是一个参数化的马尔可夫链,通过变分推理进行训练,以在有限时间后产生与数据匹配的样本。该链的转移被学习用于逆转扩散过程,扩散过程是一个马尔可夫链,在采样的相反方向上逐渐向数据添加噪声,直到信号被破坏。当扩散由少量高斯噪声组成时,将采样链转移也设置为条件高斯分布就足够了,这允许一种特别简单的神经网络参数化。
扩散模型易于定义且训练高效,但据我们所知,尚未有证据表明它们能够生成高质量样本。我们证明扩散模型实际上能够生成高质量样本,有时优于其他类型生成模型的已发表结果(第4节)。此外,我们表明扩散模型的某种参数化揭示了训练期间与多噪声水平下的去噪得分匹配的等价性,以及采样期间与退火朗之万动力学的等价性(第3.2节)。我们使用这种参数化获得了最佳样本质量结果(第4.2节),因此我们认为这种等价性是我们的主要贡献之一。
尽管样本质量很高,但我们的模型与其他基于似然的模型相比,其对数似然并不具有竞争力(然而,我们的模型的对数似然确实优于据报道使用退火重要性采样为基于能量的模型和得分匹配产生的大估计值)。我们发现我们模型的无损代码长度大部分用于描述难以察觉的图像细节(第4.3节)。我们从有损压缩的角度对这种现象进行了更精细的分析,并表明扩散模型的采样过程是一种渐进式解码,类似于沿比特顺序的自回归解码,这大大泛化了自回归模型通常可能实现的范围。
2 背景

扩散模型是形式为 pθ(x0):=∫pθ(x0:T)dx1:Tp_{\theta}\left(x_{0}\right):=\int p_{\theta}\left(x_{0: T}\right) d x_{1: T}pθ(x0):=∫pθ(x0:T)dx1:T 的潜变量模型,其中 x1,…,xTx_{1},\ldots, x_{T}x1,…,xT 是与数据 x0∼q(x0)x_{0}\sim q\left(x_{0}\right)x0∼q(x0) 同维度的潜变量。联合分布 pθ(x0:T)p_{\theta}\left(x_{0: T}\right)pθ(x0:T) 称为反向过程,它被定义为一个从 p(xT)=N(xT;0,I)p\left(x_{T}\right)=\mathcal{N}\left(x_{T}; 0, I\right)p(xT)=N(xT;0,I) 开始的、具有学习到的高斯转移的马尔可夫链:
pθ(x0:T):=p(xT)∏t=1Tpθ(xt−1∣xt),pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))(1)p_{\theta}\left(x_{0: T}\right):=p\left(x_{T}\right)\prod_{t=1}^{T} p_{\theta}\left(x_{t-1}\mid x_{t}\right),\quad p_{\theta}\left(x_{t-1}\mid x_{t}\right):=\mathcal{N}\left(x_{t-1};\mu_{\theta}\left(x_{t}, t\right),\Sigma_{\theta}\left(x_{t}, t\right)\right)\qquad(1)pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt),pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))(1)
扩散模型与其他类型潜变量模型的不同之处在于,近似后验 q(x1:T∣x0)q\left(x_{1: T}\mid x_{0}\right)q(x1:T∣x0)(称为前向过程或扩散过程)被固定为一个根据方差调度 β1,…,βT\beta_{1},\ldots,\beta_{T}β1,…,βT 逐渐向数据添加高斯噪声的马尔可夫链:
q(x1:T∣x0):=∏t=1Tq(xt∣xt−1),q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)(2)q\left(x_{1: T}\mid x_{0}\right):=\prod_{t=1}^{T} q\left(x_{t}\mid x_{t-1}\right),\quad q\left(x_{t}\mid x_{t-1}\right):=\mathcal{N}\left(x_{t};\sqrt{1-\beta_{t}} x_{t-1},\beta_{t} I\right)\qquad(2)q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)(2)
训练通过优化负对数似然上的常规变分界来执行:
E[−logpθ(x0)]≤Eq[−logpθ(x0:T)q(x1:T∣x0)]=Eq[−logp(xT)−∑t≥1logpθ(xt−1∣xt)q(xt∣xt−1)]=:L(3)E\left[-\log p_{\theta}\left(x_{0}\right)\right]\leq E_{q}\left[-\log\frac{p_{\theta}\left(x_{0: T}\right)}{q\left(x_{1: T}\mid x_{0}\right)}\right]=E_{q}\left[-\log p\left(x_{T}\right)-\sum_{t\geq 1}\log\frac{p_{\theta}\left(x_{t-1}\mid x_{t}\right)}{q\left(x_{t}\mid x_{t-1}\right)}\right]=: L\qquad(3)E[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]=:L(3)
前向过程方差 βt\beta_{t}βt 可以通过重参数化学习或作为超参数保持恒定,反向过程的表达能力部分通过 pθ(xt−1∣xt)p_{\theta}(x_{t-1}|x_{t})pθ(xt−1∣xt) 中高斯条件分布的选择来确保,因为当 βt\beta_{t}βt 很小时,两个过程具有相同的函数形式。前向过程的一个显著特性是它允许以闭式形式在任意时间步 t 采样 xtx_{t}xt:使用符号 αt:=1−βt\alpha_{t}:=1-\beta_{t}αt:=1−βt 和 αˉt:=∏s=1tαs\bar{\alpha}_{t}:=\prod_{s=1}^{t}\alpha_{s}αˉt:=∏s=1tαs,我们有
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)(4)q(x_{t}|x_{0})=\mathcal{N}(x_{t};\sqrt{\bar{\alpha}_{t}}x_{0},(1-\bar{\alpha}_{t})I)\qquad(4)q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)(4)
因此,通过使用随机梯度下降优化 L 的随机项可以实现高效训练。进一步的改进来自于通过将 L(3) 重写为以下形式来减少方差:
Eq[DKL(q(xT∣x0)∥p(xT))⏟LT+∑t>1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))⏟Lt−1−logpθ(x0∣x1)⏟L0](5)E_{q}[\underbrace{D_{KL}(q(x_{T}\mid x_{0})\parallel p(x_{T}))}_{L_{T}}+\sum_{t>1}\underbrace{D_{KL}(q(x_{t-1}\mid x_{t},x_{0})\parallel p_{\theta}(x_{t-1}\mid x_{t}))}_{L_{t-1}}\underbrace{-\log p_{\theta}(x_{0}\mid x_{1})}_{L_{0}}]\qquad(5)Eq[LT
DKL(q(xT∣x0)∥p(xT))+t>1∑Lt−1
DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0
−logpθ(x0∣x1)](5)
(详情见附录 A。项的标签在第 3 节中使用。)方程 (5) 使用 KL 散度直接比较 pθ(xt−1∣xt)p_{\theta}\left(x_{t-1}\mid x_{t}\right)pθ(xt−1∣xt) 与前向过程后验,后者在给定 x0x_{0}x0 时是易处理的:
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI),(6)q(x_{t-1}|x_{t},x_{0})=\mathcal{N}(x_{t-1};\tilde{\mu}_{t}(x_{t},x_{0}),\tilde{\beta}_{t}I),\qquad(6)q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI),(6)
其中 μ~t(xt,x0):=αˉt−1βt1−αˉtx0+αt(1−αˉt−1)1−αˉtxt\quad\tilde{\mu}_{t}\left(x_{t}, x_{0}\right):=\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_{t}}{1-\bar{\alpha}_{t}} x_{0}+\frac{\sqrt{\alpha_{t}}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_{t}} x_{t}\quadμ~t(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt 且 β~t:=1−αˉt−11−αˉtβt\quad\tilde{\beta}_{t}:=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}}\beta_{t}β~t:=1−αˉt1−αˉt−1βt
因此,方程 (5) 中的所有 KL 散度都是高斯分布之间的比较,因此它们可以用闭式表达式以 Rao-Blackwellized 的方式计算,而不是使用高方差的蒙特卡洛估计。
3 扩散模型与去噪自编码器
扩散模型可能看起来是一类受限的潜变量模型,但它们在实现上允许大量的自由度。必须选择前向过程的方差 βt\beta_{t}βt 以及反向过程的模型架构和高斯分布参数化。为了指导我们的选择,我们在扩散模型和去噪得分匹配之间建立了一种新的显式联系(第 3.2 节),这导致了扩散模型的一个简化的、加权的变分界目标(第 3.4 节)。最终,我们的模型设计由简单性和实证结果证明是合理的(第 4 节)。我们的讨论按方程 (5) 的项进行分类。

3.1 前向过程和 LTL_{T}LT
我们忽略前向过程方差 βt\beta_{t}βt 可以通过重参数化学习的事实,而是将它们固定为常数(详见第 4 节)。因此,在我们的实现中,近似后验 q 没有可学习参数,所以 LTL_{T}LT 在训练期间是一个常数,可以被忽略。
3.2 反向过程和 L1:T−1L_{1: T-1}L1:T−1
现在我们讨论在 1<t≤T1<t\leq T1<t≤T 时,pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_\theta\left(x_{t-1}\mid x_t\right)=\mathcal{N}\left(x_{t-1};\mu_\theta\left(x_t, t\right),\Sigma_\theta\left(x_t, t\right)\right)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)) 的选择。首先,我们设置 Σθ(xt,t)=σt2I\Sigma_{\theta}\left(x_{t}, t\right)=\sigma_{t}^{2} IΣθ(xt,t)=σt2I 为未经训练的、时间相关的常数。实验上,σt2=βt\sigma_{t}^{2}=\beta_{t}σt2=βt 和 σt2=β~t=1−αˉt−11−αˉtβt\sigma_{t}^{2}=\tilde{\beta}_{t}=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}}\beta_{t}σt2=β~t=1−αˉt1−αˉt−1βt 产生了相似的结果。第一种选择对于 x0∼N(0,I)x_{0}\sim\mathcal{N}(0, I)x0∼N(0,I) 是最优的,第二种选择对于 x0x_{0}x0 确定性地设置为一个点是最优的。这些是对应于具有坐标方向单位方差的数据的反向过程熵的上界和下界的两种极端选择。
其次,为了表示均值 μθ(xt,t)\mu_{\theta}\left(x_{t}, t\right)μθ(xt,t),我们提出了一种特定的参数化,其动机来自对 LtL_{t}Lt 的以下分析。对于 pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I)p_{\theta}\left(x_{t-1}\mid x_{t}\right)=\mathcal{N}\left(x_{t-1};\mu_{\theta}\left(x_{t}, t\right),\sigma_{t}^{2} I\right)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I),我们可以写出:
Lt−1=Eq[12σt2∥μ~t(xt,x0)−μθ(xt,t)∥2]+C(8) L_{t-1} = E_{q}\left[\frac{1}{2\sigma_{t}^{2}} \|\tilde{\mu}_{t}(x_{t}, x_{0}) - \mu_{\theta}(x_{t}, t)\|^{2}\right] + C \qquad (8) Lt−1=Eq[2σt21∥μ~t(xt,x0)−μθ(xt,t)∥2]+C(8)
其中 C 是一个不依赖于 θ\thetaθ 的常数。因此,我们看到 μθ\mu_{\theta}μθ 最直接的参数化是一个预测 μ~t\tilde{\mu}_{t}μ~t(前向过程后验均值)的模型。然而,我们可以通过将方程 (4) 重参数化为 xt(x0,ϵ)=αˉtx0+1−αˉtϵx_{t}\left(x_{0},\epsilon\right)=\sqrt{\bar{\alpha}_{t}} x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilonxt(x0,ϵ)=αˉtx0+1−αˉtϵ(其中 ϵ∼N(0,I)\epsilon\sim\mathcal{N}(0, I)ϵ∼N(0,I))并应用前向过程后验公式 (7) 来进一步展开方程 (8):
Lt−1−C=Ex0,ϵ[12σt2∥μ~t(xt(x0,ϵ),1αˉt(xt(x0,ϵ)−1−αˉtϵ))−μθ(xt(x0,ϵ),t)∥2]\begin{align*} L_{t-1}-C&=E_{x_{0},\epsilon}\left[\frac{1}{2\sigma_{t}^{2}}\left\|\tilde{\mu}_{t}\left(x_{t}\left(x_{0},\epsilon\right),\frac{1}{\sqrt{\bar{\alpha}_{t}}}\left(x_{t}\left(x_{0},\epsilon\right)-\sqrt{1-\bar{\alpha}_{t}}\epsilon\right)\right)-\mu_{\theta}\left(x_{t}\left(x_{0},\epsilon\right), t\right)\right\|^{2}\right]\\ \end{align*}Lt−1−C=Ex0,ϵ[2σt21
μ~t(xt(x0,ϵ),αˉt1(xt(x0,ϵ)−1−αˉtϵ))−μθ(xt(x0,ϵ),t)
2]
=Ex0,ϵ[12σt2∥1αt(xt(x0,ϵ)−βt1−αˉtϵ)−μθ(xt(x0,ϵ),t)∥2]=E_{x_{0},\epsilon}\left[\frac{1}{2\sigma_{t}^{2}}\left\|\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}\left(x_{0},\epsilon\right)-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\epsilon\right)-\mu_{\theta}\left(x_{t}\left(x_{0},\epsilon\right), t\right)\right\|^{2}\right]=Ex0,ϵ[2σt21
αt1(xt(x0,ϵ)−1−αˉtβtϵ)−μθ(xt(x0,ϵ),t)
2]
方程 (10) 揭示出 μθ\mu_\thetaμθ 必须在给定 xtx_txt 的情况下预测 1αt(xt−βt1−αˉtϵ)\frac{1}{\sqrt{\alpha_t}}\left(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon\right)αt1(xt−1−αˉtβtϵ)。由于 xtx_txt 可作为模型的输入,我们可以选择参数化
μθ(xt,t)=μ~t(xt,1αˉt(xt−1−αˉtϵθ(xt)))=1αt(xt−βt1−αˉtϵθ(xt,t))(11)\mu_{\theta}\left(x_{t}, t\right)=\tilde{\mu}_{t}\left(x_{t},\frac{1}{\sqrt{\bar{\alpha}_{t}}}\left(x_{t}-\sqrt{1-\bar{\alpha}_{t}}\epsilon_{\theta}\left(x_{t}\right)\right)\right)=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\epsilon_{\theta}\left(x_{t}, t\right)\right)\qquad(11)μθ(xt,t)=μ~t(xt,αˉt1(xt−1−αˉtϵθ(xt)))=αt1(xt−1−αˉtβtϵθ(xt,t))(11)
其中 ϵθ\epsilon_{\theta}ϵθ 是一个函数逼近器,旨在从 xtx_{t}xt 预测 ϵ\epsilonϵ。从 pθ(xt−1∣xt)p_{\theta}\left(x_{t-1}\mid x_{t}\right)pθ(xt−1∣xt) 采样 xt−1x_{t-1}xt−1 就是计算 xt−1=1αˉt(xt−βt1−αˉtϵθ(xt,t))+σtzx_{t-1}=\frac{1}{\sqrt{\bar{\alpha}_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\epsilon_{\theta}\left(x_{t}, t\right)\right)+\sigma_{t} zxt−1=αˉt1(xt−1−αˉtβtϵθ(xt,t))+σtz,其中 z∼N(0,I)z\sim\mathcal{N}(0, I)z∼N(0,I)。完整的采样过程,算法 2,类似于朗之万动力学,其中 ϵθ\epsilon_{\theta}ϵθ 作为数据密度的学习梯度。此外,使用参数化 (11),方程 (10) 简化为:
Ex0,ϵ[βt22σt2αt(1−αˉt)∥ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∥2](12) E_{x_0,\epsilon}\left[\frac{\beta_t^2}{2\sigma_t^2\alpha_t\left(1-\bar{\alpha}_t\right)}\left\|\epsilon-\epsilon_\theta\left(\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t}\epsilon, t\right)\right\|^2\right]\qquad(12)Ex0,ϵ[2σt2αt(1−αˉt)βt2
ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)
2](12)
这类似于在由ttt索引的多个噪声尺度上的去噪得分匹配。由于方程 (12) 等于(类似朗之万的反向过程 (11) 的)变分界的一项,我们看到优化一个类似于去噪得分匹配的目标等价于使用变分推理来拟合一个类似于朗之万动力学的采样链的有限时间边际。
总结来说,我们可以训练反向过程均值函数逼近器 μθ\mu_{\theta}μθ 来预测 μ~t\tilde{\mu}_{t}μ~t,或者通过修改其参数化,我们可以训练它来预测 ϵ\epsilonϵ。(也存在预测 x0x_{0}x0 的可能性,但我们发现在早期的实验中这会导致更差的样本质量。)我们已经表明,ϵ\epsilonϵ-预测参数化既类似于朗之万动力学,又将扩散模型的变分界简化为一个类似于去噪得分匹配的目标。尽管如此,它只是 pθ(xt−1∣xt)p_{\theta}\left(x_{t-1}\mid x_{t}\right)pθ(xt−1∣xt) 的另一种参数化,因此我们在第 4 节的消融实验中验证了其有效性,比较了预测 ϵ\epsilonϵ 与预测 μ~t\tilde{\mu}_{t}μ~t。
3.3 数据缩放、反向过程解码器和 L0L_{0}L0
我们假设图像数据由 {0,1,…,255}\{0,1,\ldots, 255\}{0,1,…,255} 中的整数组成,并线性缩放到 [−1,1][-1,1][−1,1]。这确保了神经网络反向过程在从标准正态先验 p(xT)p\left(x_{T}\right)p(xT) 开始的一致的缩放输入上操作。为了获得离散对数似然,我们将反向过程的最后一项设置为一个独立的离散解码器,该解码器源自高斯分布 N(x0;μθ(x1,1),σ12I)\mathcal{N}\left(x_0;\mu_\theta\left(x_1, 1\right),\sigma_1^2 I\right)N(x0;μθ(x1,1),σ12I):
pθ(x0∣x1)=∏i=1D∫δ−(x0i)δ+(x0i)N(x;μθi(x1,1),σ12)dxδ+(x)={∞ ifx=1x+1255 ifx<1δ−(x)={−∞ ifx=−1x−1255 ifx>−1(13)\begin{align*}p_{\theta}\left(x_{0}\mid x_{1}\right)&=\prod_{i=1}^{D}\int_{\delta_{-}\left(x_{0}^{i}\right)}^{\delta_{+}\left(x_{0}^{i}\right)}\mathcal{N}\left(x;\mu_{\theta}^{i}\left(x_{1}, 1\right),\sigma_{1}^{2}\right) d x\\ \delta_{+}(x)&=\left\{\begin{array}{ll}\infty&\text{ if} x=1\\ x+\frac{1}{255}&\text{ if} x<1\end{array}\quad\delta_{-}(x)=\left\{\begin{array}{ll}-\infty&\text{ if} x=-1\\ x-\frac{1}{255}&\text{ if} x>-1\end{array}\right.\right.\end{align*}\qquad(13)pθ(x0∣x1)δ+(x)=i=1∏D∫δ−(x0i)δ+(x0i)N(x;μθi(x1,1),σ12)dx={∞x+2551 ifx=1 ifx<1δ−(x)={−∞x−2551 ifx=−1 ifx>−1(13)
其中 D 是数据维度,上标iii表示提取一个坐标。(合并一个更强大的解码器,如条件自回归模型,是很直接的,但我们将其留给未来工作。)与 VAE 解码器和自回归模型中使用的离散化连续分布类似,我们这里的选择确保了变分界是离散数据的无损代码长度,而无需向数据添加噪声或将缩放操作的雅可比矩阵纳入对数似然。在采样结束时,我们无噪声地显示 μθ(x1,1)\mu_{\theta}\left(x_{1}, 1\right)μθ(x1,1)。
3.4 简化的训练目标
使用上面定义的反向过程和解码器,由方程 (12) 和 (13) 导出的变分界显然是关于 θ\thetaθ 可微的,并已准备好用于训练。然而,我们发现为了样本质量(并且实现更简单),训练以下变分界的变体是有益的:
Lsimple(θ):=Et,x0,ϵ[∥ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∥2](14)L_{simple}(\theta):=E_{t,x_{0},\epsilon}{[}{\|}\epsilon-\epsilon_{\theta}(\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon,t){\|}^{2}{]}\qquad(14)Lsimple(θ):=Et,x0,ϵ[∥ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∥2](14)
其中ttt在 1 和 TTT 之间均匀分布。t=1t=1t=1 的情况对应于 L0L_{0}L0,其中离散解码器定义 (13) 中的积分由高斯概率密度函数乘以 bin 宽度近似,忽略了 σ12\sigma_{1}^{2}σ12 和边缘效应。t>1t>1t>1 的情况对应于方程 (12) 的一个未加权版本,类似于 NCSN 去噪得分匹配模型使用的损失加权。(LTL_TLT 没有出现,因为前向过程方差 βt\beta_{t}βt 是固定的。)算法 1 展示了使用这个简化目标的完整训练过程。
由于我们的简化目标 (14) 丢弃了方程 (12) 中的加权,它是一个加权的变分界,与标准变分界相比,强调了重建的不同方面。特别是,我们在第 4 节中的扩散过程设置导致简化目标降低了对对应于小 t 的损失项的权重。这些项训练网络用非常少量的噪声去噪数据,因此降低它们的权重是有益的,这样网络可以专注于在更大 t 项上更困难的任务。我们将在实验中看到这种重新加权导致了更好的样本质量。
4 实验
我们将所有实验的 T=1000T=1000T=1000 设置,使得采样期间所需的神经网络评估次数与先前工作匹配。我们将前向过程方差设置为从 β1 = 10−4\beta_{1}\,=\,10^{-4}β1=10−4 线性增加到 βT = 0.02\beta_{T}\,=\,0.02βT=0.02 的常数。选择这些常数相对于缩放到 [-1,1] 的数据较小,确保反向和前向过程具有大致相同的函数形式,同时保持 xT 处的信噪比尽可能小(在我们的实验中,LT=L_{T}=LT= DKL(q(xT∣x0)∥N(0,I))≈10−5 比特每维度D_{KL}(q(x_{T}|x_{0})\parallel\mathcal{N}(0, I))\approx 10^{-5}\, \text{比特每维度}DKL(q(xT∣x0)∥N(0,I))≈10−5比特每维度)。
为了表示反向过程,我们使用一个 U-Net 主干,类似于未掩码的 PixelCNN++,全程使用组归一化。参数跨时间共享,使用 Transformer 正弦位置嵌入指定给网络。我们在 16x16 特征图分辨率上使用自注意力。详情见附录 B。
4.1 样本质量
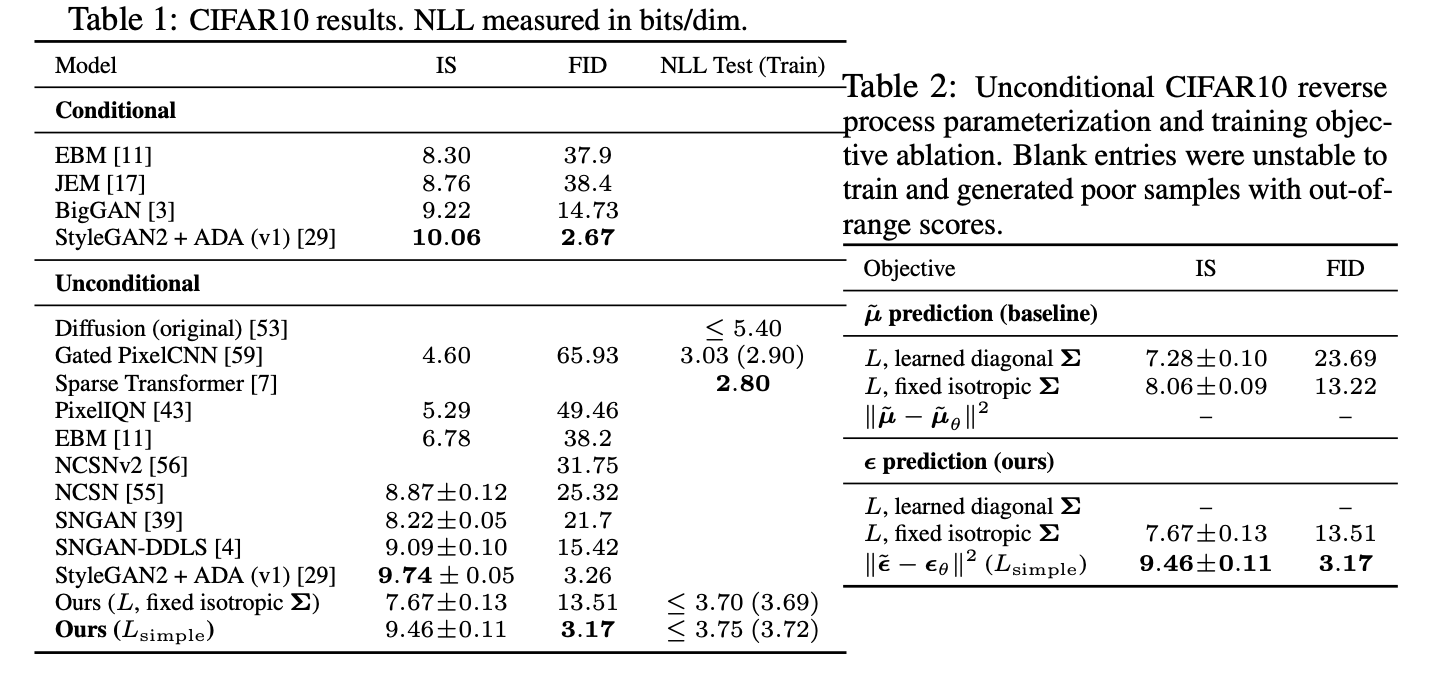
表 1 显示了 CIFAR10 上的 Inception 分数、FID 分数和负对数似然(无损代码长度)。凭借 3.17 的 FID 分数,我们的无条件模型实现了比文献中大多数模型(包括类别条件模型)更好的样本质量。我们的 FID 分数是相对于训练集计算的,这是标准做法;当我们相对于测试集计算时,分数是 5.24,这仍然优于文献中许多训练集 FID 分数。
我们发现,正如预期的那样,在真实变分界上训练我们的模型比在简化目标上训练产生更好的代码长度,但后者产生最佳的样本质量。CIFAR10 和 CelebA-HQ 256x256 样本见图 1,LSUN 256x256 样本见图 3 和图 4,更多样本见附录 D。
4.2 反向过程参数化和训练目标消融
在表 2 中,我们展示了反向过程参数化和训练目标(第 3.2 节)对样本质量的影响。我们发现,预测 μ~\tilde{\mu}μ~ 的基线选项仅在真实变分界上训练时才表现良好,而不是在未加权的均方误差(类似于方程 (14) 的简化目标)上训练。我们还看到,学习反向过程方差(通过将参数化的对角 Σθ(xt)\Sigma_{\theta}(x_t)Σθ(xt) 纳入变分界)会导致训练不稳定和比固定方差更差的样本质量。如我们提出的,预测 ϵ\epsilonϵ 在具有固定方差的变分界上训练时表现与预测 μ~\tilde{\mu}μ~ 大致相同,但在使用我们的简化目标训练时表现要好得多。
4.3 渐进式编码
表1还展示了我们CIFAR10模型的代码长度。训练和测试之间的差距最多为每维度0.03比特,这与其他基于似然的模型报告的差距相当,表明我们的扩散模型没有过拟合(参见附录D的最近邻可视化)。尽管如此,虽然我们的无损代码长度优于使用退火重要性采样为基于能量的模型和得分匹配报告的大估计值,但它们与其他类型的基于似然的生成模型相比并不具有竞争力。
由于我们的样本质量很高,我们得出结论,扩散模型具有一种归纳偏差,使其成为优秀的有损压缩器。将变分界项视为码率,将 L0L_0L0 视为失真,我们具有最高质量样本的CIFAR10模型的码率为1.78比特/维度,失真为1.97比特/维度,这相当于在0到255的尺度上均方根误差为0.95。超过一半的无损代码长度用于描述难以察觉的失真。
渐进式有损压缩:我们可以通过引入一种反映方程(5)形式的渐进式有损代码来进一步探究我们模型的率失真行为:参见算法3和算法4,它们假设可以访问一个程序(例如最小随机编码),该程序平均可以使用大约 DKL(q(x)∣∣p(x))D_{KL}(q(x)|| p(x))DKL(q(x)∣∣p(x)) 比特来传输一个样本 x∼q(x)x \sim q(x)x∼q(x),对于任何分布 ppp 和 qqq,只有 ppp 是接收者事先可用的。当应用于 x0∼q(x0)x_0 \sim q(x_0)x0∼q(x0) 时,算法3和算法4按顺序传输 xT,...,x0x_T, ..., x_0xT,...,x0,使用的总期望代码长度等于方程(5)。接收者在任何时间 ttt 都完全拥有部分信息 xtx_txt,并可以渐进地估计:
x0≈x^0=(xt−1−αˉtϵθ(xt))/αˉt(15)x_{0}\approx\hat{x}_{0}=\left(x_{t}-\sqrt{1-\bar{\alpha}_{t}}\epsilon_{\theta}(x_{t})\right)/\sqrt{\bar{\alpha}_{t}}\qquad(15)x0≈x^0=(xt−1−αˉtϵθ(xt))/αˉt(15)
这源于方程(4)。(随机重建 x0∼pθ(x0∣xt)x_{0}\sim p_{\theta}(x_{0}|x_{t})x0∼pθ(x0∣xt) 也是有效的,但我们这里不考虑它,因为它使失真更难以评估。)图5显示了CIFAR10测试集上的 resulting 率失真图。在每个时间 ttt,失真计算为均方根误差 ∥x0−x^0∥2/D\sqrt{\|x_{0}-\hat{x}_{0}\|^{2}/D}∥x0−x^0∥2/D,码率计算为到时间 ttt 为止累计接收的比特数。失真在率失真图的低码率区域急剧下降,表明大部分比特确实被分配给了难以察觉的失真。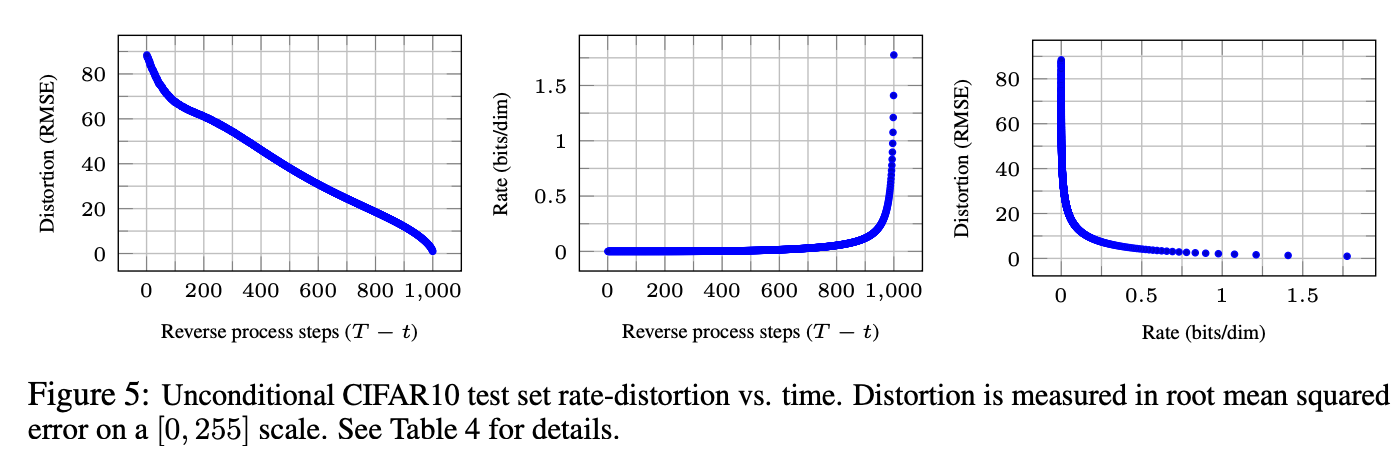
渐进式生成: 我们还运行了一个渐进式无条件生成过程,该过程由从随机比特进行渐进式解压缩给出。换句话说,我们在使用算法2从反向过程采样的同时,预测反向过程的结果 x^0\hat{x}_{0}x^0。图6和图10展示了 x^0\hat{x}_{0}x^0 在反向过程期间的 resulting 样本质量。大规模的图像特征首先出现,细节最后出现。图7显示了对于不同的 ttt,在 xtx_txt 固定的情况下,随机预测 x0∼pθ(x0∣xt)x_{0}\sim p_{\theta}(x_{0}|x_{t})x0∼pθ(x0∣xt)。当 ttt 较小时,除精细细节外所有特征都被保留,而当 ttt 较大时,仅保留大规模特征。也许这些是概念压缩的暗示。
与自回归解码的联系 :注意变分界(5)可以重写为:
L=DKL(q(xT)∥p(xT))+Eq[∑t≥1DKL(q(xt−1∣xt)∥pθ(xt−1∣xt))]+H(x0)(16)L=D_{KL}(q(x_{T})\parallel p(x_{T}))+E_{q}\left[\sum_{t\geq 1}D_{KL}(q(x_{t-1}|x_{t})\parallel p_{\theta}(x_{t-1}|x_{t}))\right]+H(x_{0})\qquad(16)L=DKL(q(xT)∥p(xT))+Eq[t≥1∑DKL(q(xt−1∣xt)∥pθ(xt−1∣xt))]+H(x0)(16)
(推导见附录A。)现在考虑将扩散过程长度 TTT 设置为数据的维度,定义前向过程使得 q(xt∣x0)q\left(x_{t}\mid x_{0}\right)q(xt∣x0) 将所有概率质量放在 x0x_{0}x0 上,但前 ttt 个坐标被掩盖(即 q(xt∣xt−1)q\left(x_{t}\mid x_{t-1}\right)q(xt∣xt−1) 掩盖第 ttt 个坐标),将 p(xT)p\left(x_{T}\right)p(xT) 设置为将所有质量放在空白图像上,并且为了论证,将 pθ(xt−1∣xt)p_{\theta}\left(x_{t-1}\mid x_{t}\right)pθ(xt−1∣xt) 视为一个完全表达性的条件分布。有了这些选择,DKL(q(xT)∥p(xT))=0D_{KL}(q(x_{T})\parallel p(x_{T}))=0DKL(q(xT)∥p(xT))=0,并且最小化 DKL(q(xt−1∣xt)∥pθ(xt−1∣xt))D_{\text{KL}}(q(x_{t-1}|x_{t})\parallel p_{\theta}(x_{t-1}| x_{t}))DKL(q(xt−1∣xt)∥pθ(xt−1∣xt)) 会训练 pθp_{\theta}pθ 去原样复制坐标 t+1,…,Tt+1,\ldots,Tt+1,…,T 并预测第 ttt 个坐标给定 t+1,…,Tt+1,\ldots,Tt+1,…,T。因此,用这种特定的扩散训练 pθp_{\theta}pθ 就是在训练一个自回归模型。
因此,我们可以将高斯扩散模型(2)解释为一种具有广义比特排序的自回归模型,这种排序不能通过重新排列数据坐标来表达。先前的工作表明,这种重新排序会引入对样本质量有影响的归纳偏差,因此我们推测高斯扩散具有类似的目的,可能效果更好,因为与掩盖噪声相比,向图像添加高斯噪声可能更自然。此外,高斯扩散的长度不限于等于数据维度;例如,我们使用 T=1000T=1000T=1000,这小于我们实验中 32×32×332 \times 32 \times 332×32×3 或 256×256×3256 \times 256 \times 3256×256×3 图像的维度。高斯扩散可以做得更短以进行快速采样,或更长以增加模型表达能力。
4.4 插值
我们可以在潜空间中对源图像 x0,x0′∼q(x0)x_{0},x_{0}^{\prime}\sim q(x_{0})x0,x0′∼q(x0) 进行插值,使用 qqq 作为随机编码器,xt,xt′∼q(xt∣x0)x_{t},x_{t}^{\prime}\sim q(x_{t}|x_{0})xt,xt′∼q(xt∣x0),然后通过反向过程将线性插值的潜变量 xˉt=(1−λ)x0+λx0′\bar{x}_{t}=(1-\lambda)x_{0}+\lambda x_{0}^{\prime}xˉt=(1−λ)x0+λx0′ 解码回图像空间,xˉ0 ∼ p(x0∣xˉt)\bar{x}_{0}\,\sim\,p(x_{0}|\bar{x}_{t})xˉ0∼p(x0∣xˉt)。实际上,我们使用反向过程来消除对损坏的源图像进行线性插值产生的伪影,如图8(左)所示。我们固定了不同 λ\lambdaλ 值的噪声,所以 xtx_{t}xt 和 xt′x_{t}^{\prime}xt′ 保持不变。图8(右)显示了原始CelebA-HQ 256×256256 \times 256256×256 图像(t=500t=500t=500)的插值和重建。反向过程产生了高质量的重建和合理的插值,这些插值在姿态、肤色、发型、表情和背景等属性上平滑变化,但没有眼镜。更大的 ttt 会导致更粗糙和更多样的插值,在 t=1000t=1000t=1000 时会产生新颖样本(附录图9)。
5 相关工作
虽然扩散模型可能类似于流模型和VAE,但扩散模型被设计为使得 qqq 没有参数,并且顶层潜变量 xTx_TxT 与数据 x0x_{0}x0 的互信息几乎为零。我们的 ϵ\epsilonϵ-预测反向过程参数化在扩散模型与去噪得分匹配之间建立了联系,后者在多个噪声水平上使用退火朗之万动力学进行采样。然而,扩散模型允许直接进行对数似然评估,并且训练过程使用变分推理显式地训练朗之万动力学采样器(详见附录C)。这种联系也具有反向含义,即某种加权形式的去噪得分匹配等同于使用变分推理来训练类似朗之万的采样器。学习马尔可夫链转移算子的其他方法包括注入训练、变分随机回退、生成随机网络等。
通过得分匹配与基于能量的建模之间的已知联系,我们的工作可能对其他最近关于基于能量的模型的工作产生影响。我们的率失真曲线是在一次变分界评估中随时间计算的,这让人想起率失真曲线如何在退火重要性采样的一次运行中随失真惩罚计算。我们的渐进式解码论证可以在卷积DRAW及相关模型中看到,并可能为自回归模型带来更一般的子尺度排序或采样策略设计。
6 结论
我们使用扩散模型展示了高质量的图像样本,并且我们发现了扩散模型与用于训练马尔可夫链的变分推理、去噪得分匹配和退火朗之万动力学(以及扩展的基于能量的模型)、自回归模型以及渐进式有损压缩之间的联系。由于扩散模型似乎对图像数据具有出色的归纳偏差,我们期待研究它们在其他数据模态中的效用,以及作为其他类型的生成模型和机器学习系统中的组件。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)