分类分析概述
分类算法也称为模式识别,是一种机器学习算法,其主要目的是从数据中发现规律并将数据分成不同的类别。分类算法通过对已知类别训练集的计算和分析,从中发现类别规则并预测新数据的类别。常见的分类算法包括决策树、朴素贝叶斯、逻辑回归、K-最近邻、支持向量机等。分类算法广泛应用于金融、医疗、电子商务等领域,以帮助人们更好地理解和利用数据。
分类分析
阅读资料:
一文读懂机器学习分类算法(附图文详解)-腾讯云开发者社区-腾讯云
机器学习:分类算法(Classification) - 知乎
算法金 | 一文彻底理解机器学习 ROC-AUC 指标-腾讯云开发者社区-腾讯云
从0开始机器学习-Bagging和Boosting - 知乎
k-近邻算法(K-Nearest Neighbors, KNN)详解:机器学习中的经典算法-云社区-华为云
1.6. K近邻 — scikit-learn 1.8.0 documentation - scikit-learn 机器学习库
目录
假正率
假负率
1. 分类概述:从原理到应用
核心定义
本质:分类属于有监督学习。这意味着模型的学习过程需要“数据的标签”指导。
目标函数:学习一个映射函数f:X->Y,其中X是特征空间,Y是预定义的类别集合。这个函数(分类器)能对未见过的样本进行准确归类。
分类任务的三种形态
二分类
最基础的形式,非黑即白。
比如,判断邮件是否为垃圾邮件;医学诊断判断是否患病。
多分类
类别超过两个,且样本只能属于其中一个。
比如,手写数字识别(0-9);面部表情识别(开心、愤怒、悲伤);像种子品种鉴别(品种1/2/3)。
多标签分类
一个样本可以同时具有多个类别标签。
比如,一篇新闻报道可以同时被标记为“政治”、“财经”、“国际”。
分类 vs 聚类(核心区别)
|
比较维度 |
分类 |
聚类 |
|
数据性质 |
分类数据的标签是已知的(有目标变量)。输入数据既包含特征 XX,也包含正确的类别标签 YY。 |
聚类数据的标签是未知的(无目标变量,仅靠特征自发分组)。输入数据只有特征 XX,没有预先定义的类别。 |
|
学习方式 |
判别式学习(给定 XX 预测 YY)。目标是学习一个从特征到标签的映射函数,以便对未知样本进行预测。 |
描述式学习(探索 XX 内部的结构)。目标是发现数据内在的分组模式或结构。 |
|
形象类比 |
分类像是“考前有标准答案的复习”。你知道题目对应的正确答案,通过练习来掌握规律。 |
聚类像是“把一堆杂乱物品按相似性整理归类”。你不知道分类标准,只是把外观或性质相似的物品堆放在一起。 |
|
输出结果 |
输出明确的类别标签(如:是/否,A/B/C类)。 |
输出数据的簇或分组(如:簇1、簇2),具体代表什么含义需要人工去分析。 |
|
典型算法 |
KNN、朴素贝叶斯、逻辑回归、决策树、SVM、神经网络。 |
K-Means、层次聚类、DBSCAN。 |
2. 分类全流程:从数据到模型
步骤一:数据准备与预处理
- 缺失值处理:
直接删除或填充(均值、中位数、众数)。 “异常0值”处理(如血糖为0是不合理的),这比简单的缺失值处理更隐蔽,需要领域知识。
- 数据标准化:
如果特征的量纲差异巨大(如年龄20岁 vs 收入20000元),距离-based的算法(如KNN)会被大数值特征主导。
StandardScaler(Z-score标准化,均值为0,方差为1)或 MinMaxScaler(归一化到[0,1])。
- 特征矩阵构建:
将数据整理为(N,M)的矩阵,N为样本数,M为特征数。
步骤二:划分训练集与测试集
- 黄金法则:
绝对不能用测试集来训练模型!测试集是“期末考试”,平时训练不能看到真题。
- 划分比例:
常用 7:3 或 8:2。如果数据量很大,9:1甚至99:1也是可能的。
- 关键参数(基于 sklearn.model_selection.train_test_split):
test_size=0.3:测试集占比。
random_state=42:随机种子。设置固定值(如42)可以保证每次运行代码拆分的数据集一致,这对结果复现至关重要。
stratify=y:分层抽样。确保训练集和测试集中各类别的比例与原始数据集一致(如原始数据患病率20%,拆分后训练集和测试集的患病率都约是20%),这对不平衡数据集非常关键。
步骤三:模型选择与训练
- 初始化:
实例化模型对象,设置超参数(如KNN的 n_neighbors=5)。
- 拟合:
调用 .fit(X_train, y_train)。模型会在特征空间中寻找规律。
- KNN视角:
其实就是把训练数据“存”起来,并没有显式的计算过程,这叫“懒惰学习”。
- 逻辑回归视角:
通过梯度下降调整权重参数,最小化预测误差。
步骤四:模型评估
- 预测:
调用 .predict(X_test) 得到预测标签 y_pred。
- 对比:
将 y_pred 与真实的 y_test 进行对比,计算各项指标。
3. 分类评价指标:不仅仅是准确率
这是考试和实战的重难点,尤其是对于不平衡数据集。
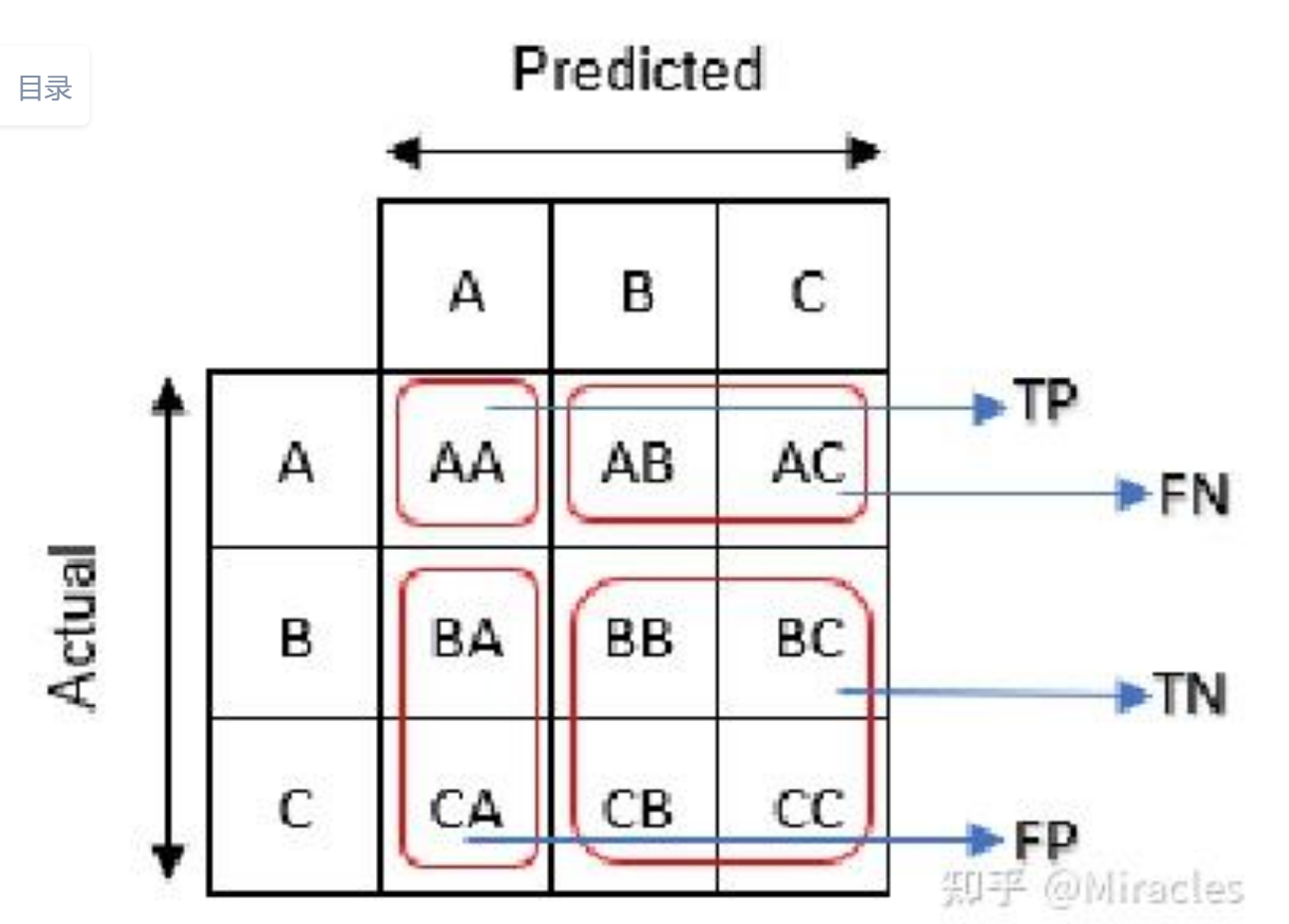
混淆矩阵:评估分类性能的基础基石
|
指标 |
名称 |
定义 |
解释 |
|
TP |
真阳性 |
预测为正,实际也为正 |
抓对了,正确识别出正例 |
|
TN |
真阴性 |
预测为负,实际也为负 |
排除了对的,正确识别出负例 |
|
FP |
假阳性 |
预测为正,实际为负 |
误报/第一类错误,将负例误判为正例 |
|
FN |
假阴性 |
预测为负,实际为正 |
漏报/第二类错误,将正例误判为负例 |
核心指标详解

准确率——(真的预测真+假的预测假)/全部四种情况
公式:((TP+TN) / (TP+TN+FP+FN))
陷阱:在样本极度不平衡时失效。例如,癌症发病率仅0.01%,模型全部预测为"健康",准确率高达99.99%,但毫无价值。
精准率
公式:(TP / (TP+FP))——真的预测真/(真的预测真+假的预测真)
应用场景:宁可漏报,不可误报。如股票推荐(预测涨的必须真涨)或垃圾邮件过滤(别把重要邮件当垃圾邮件删了)。
召回率(真正率)
公式:(TP / (TP+FN))——真的预测真/(真的预测真+真的预测假)
应用场景:宁可误报,不可漏报。如癌症筛查(宁可把良性判为恶性复查,也不能漏掉一个病人)、贷款违约识别。
真负率(特异性)
公式:(TN / (TN+FP))——假的预测假/(假的预测假+假的预测真)
含义:模型正确识别负样本的能力,与召回率互补。
假正率 (FPR)
公式:(FP / (TN+FP))——假的预测真/(假的预测假+假的预测真)
说明:假正率表示在所有实际为负类的样本中,被模型错误预测为正类的比例。
该指标衡量了模型对负样本的“误判”程度。
FPR 越低,说明模型把负样本错判成正样本的情况越少。
在 ROC 曲线中,横轴通常就是 FPR(假正率)。
假负率 (FNR)
公式:(FN / (FN + TP))
说明:假负率表示在所有实际为正类的样本中,被模型错误预测为负类的比例(即“漏报”)。
F1得分
公式:(2×Precision×RecallPrecision+Recall)
优势:精准率和召回率的调和平均,取值范围[0,1]。当两者都高时,F1才会高。特别适用于类别分布不平衡的任务。
ROC与AUC
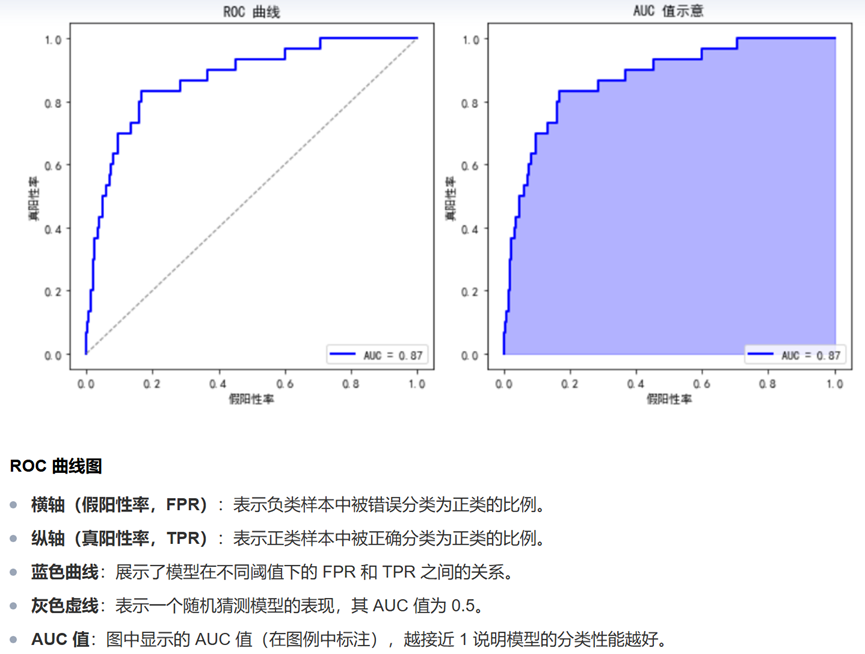
ROC曲线:
横轴为FPR(假正率),纵轴为TPR(召回率)。通过改变分类阈值(如从概率>0.5改为>0.8)绘制出的曲线。
AUC (Area Under Curve):
ROC曲线下的面积。

4. 常见分类器深度解析
K近邻
核心思想
“近朱者赤,近墨者黑”。
一个样本的类别由它距离最近的K个邻居投票决定。
算法流程
计算距离 -> 排序 -> 取前K个 -> 统计类别频率 -> 输出最多者。
距离度量
最常用的是欧氏距离(两点间直线距离)。
K值的选择艺术
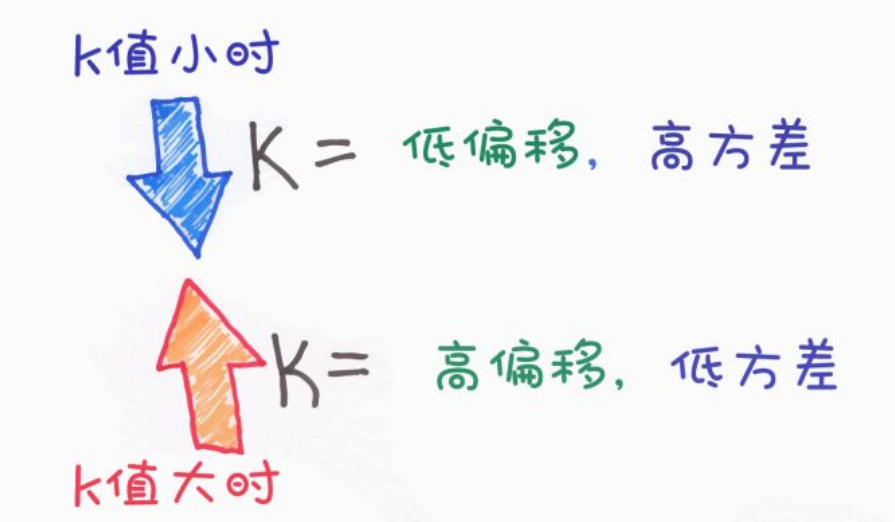
- K太小(如K=1)
模型过于复杂,容易过拟合。对噪声数据极其敏感,容易把异常点当成规律。
- K太大
模型过于简单,容易欠拟合。分类边界变得模糊,忽略了局部细节。
- 经验法则
K一般取奇数(避免投票平局),通常小于样本数的平方根。最佳做法是通过交叉验证来选取使验证误差最小的K值。
优缺点
优点
简单直观,无需训练过程(适合新数据的快速加入),天然支持多分类。
缺点
计算复杂度高(预测时需要计算与所有训练样本的距离),对特征缩放极其敏感,可解释性差(不能像决策树那样给出规则)。
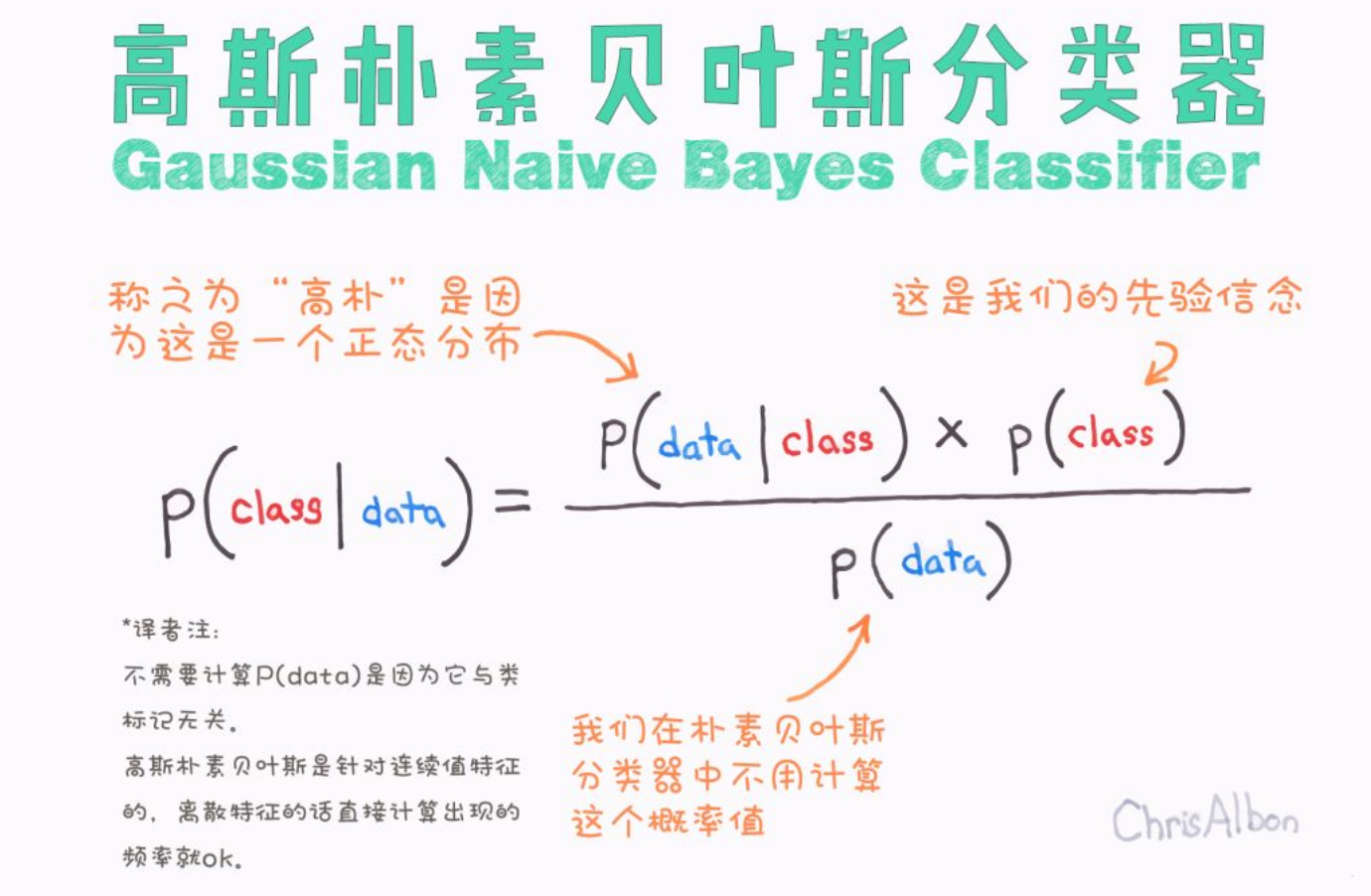
朴素贝叶斯
核心思想
基于贝叶斯定理,利用特征条件独立性假设来计算后验概率。
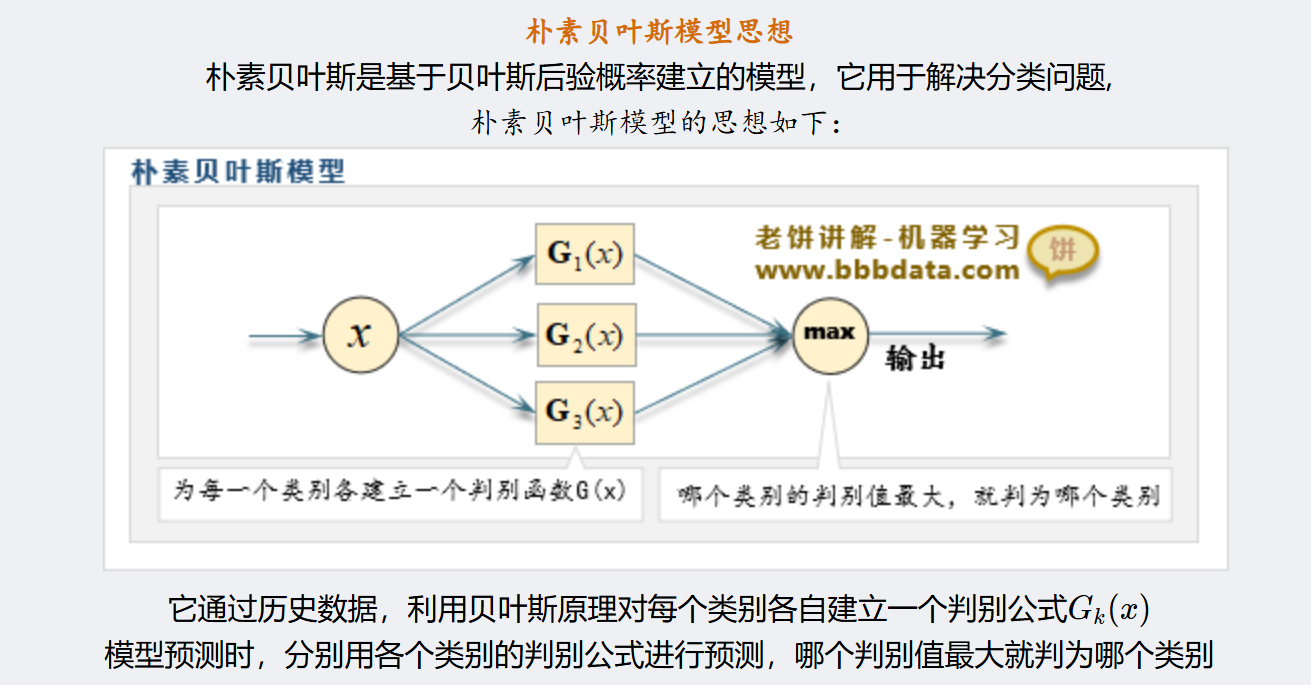
概率基础
- 先验概率:根据以往经验得到的概率(如全校考研成功率20%)。
- 条件概率:在已知某类别下出现某特征的概率(如考上的人中,每天学8小时的比例)。
- 后验概率:看到证据后更新的概率(已知某人每天学8小时,他考上的概率)。
为什么“朴素”?
它假设所有特征之间是相互独立的。虽然现实中很少成立(例如“免费”和“中奖”这两个词经常一起出现,并不独立),但这种假设极大地简化了计算,且在实际应用中(尤其是文本分类)效果出奇地好。
常见变体
- MultinomialNB:适用于离散特征,如文本分类中的词频统计。
- GaussianNB:适用于连续特征,假设特征服从高斯分布(正态分布)。
- BernoulliNB:适用于二值特征(0/1出现与否)。

优缺点
优点
对缺失数据不敏感,训练速度快,对小规模数据表现很好,擅长文本分类。
缺点
特征独立性的假设是其主要短板,如果特征之间相关性很强,分类效果会受影响。
其他分类器(补充)
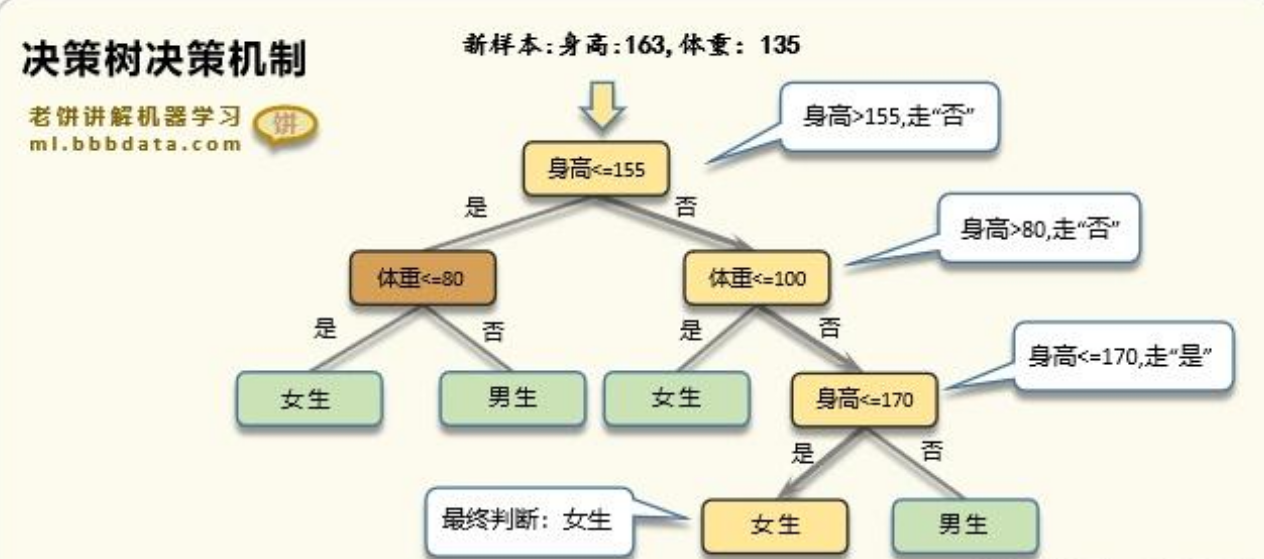
决策树
通过一系列 if-then 规则进行判断。可解释性极强(像流程图),但容易过拟合。
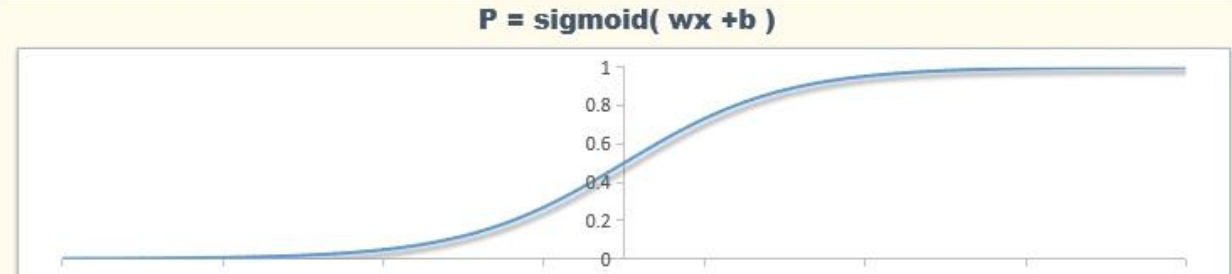
逻辑回归
虽然有“回归”二字,但本质是线性分类器。输出的是概率值,通过Sigmoid函数映射到[0,1]。
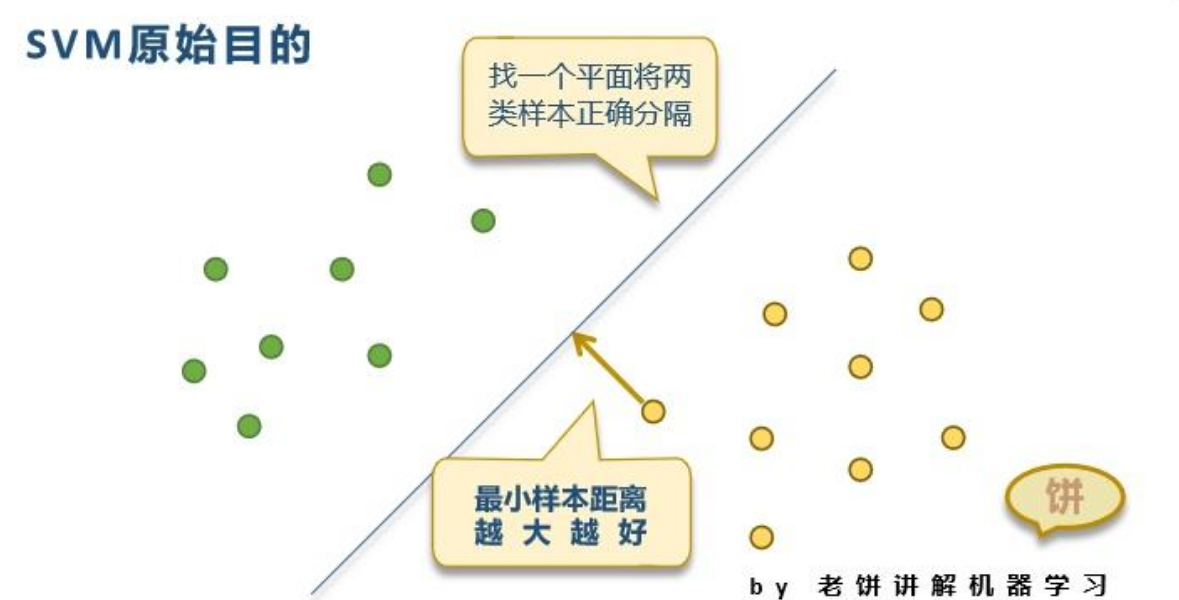
支持向量机 (SVM)
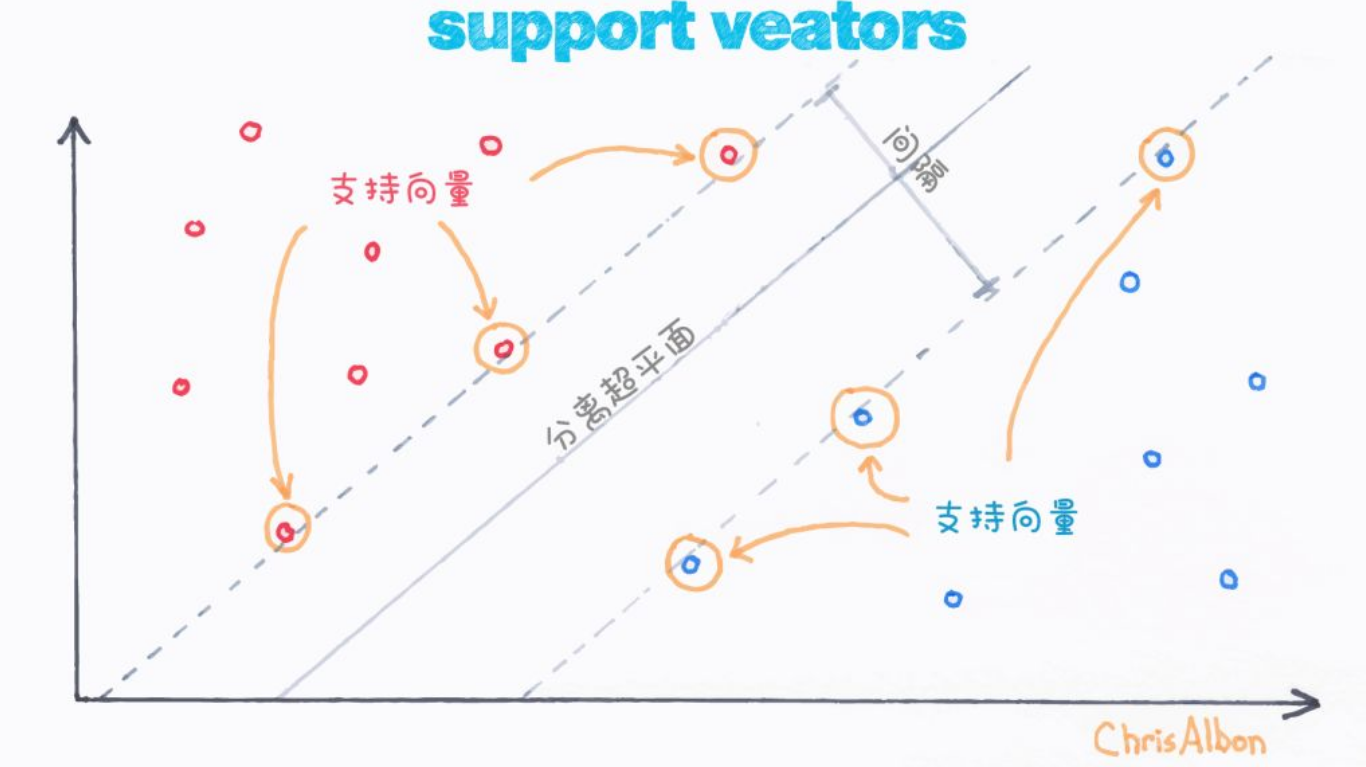
寻找能将两类数据分开且间隔最大的“超平面”。对高维数据表现好。
神经网络
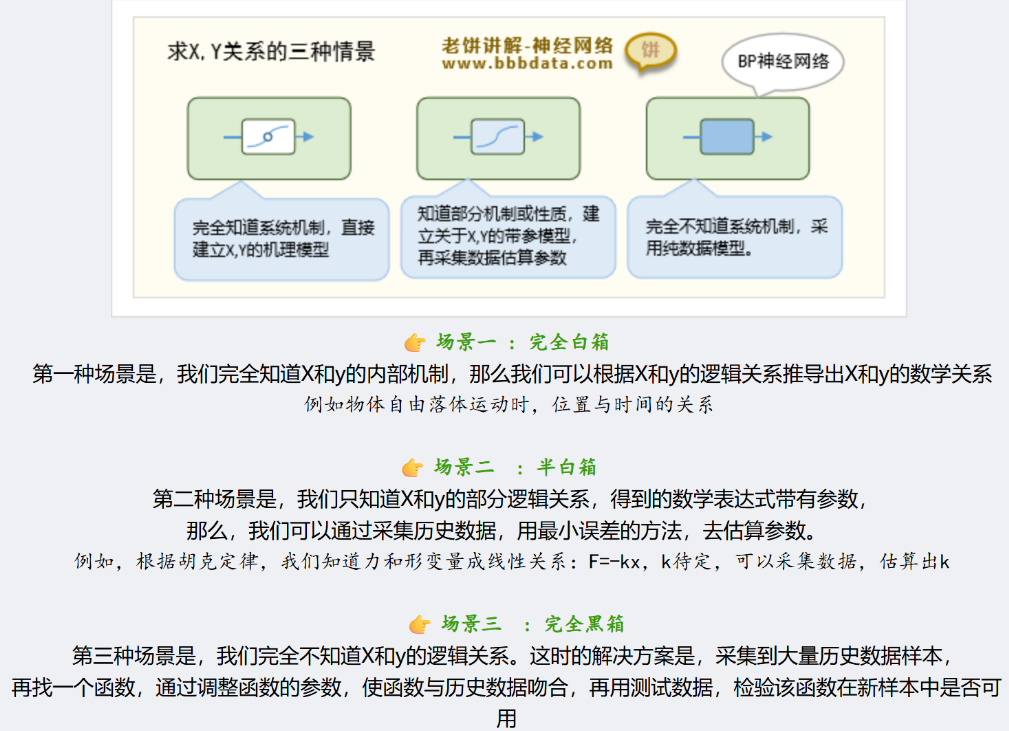
模拟人脑神经元,通过多层网络提取深层特征。适合处理图像、语音等非结构化复杂数据。
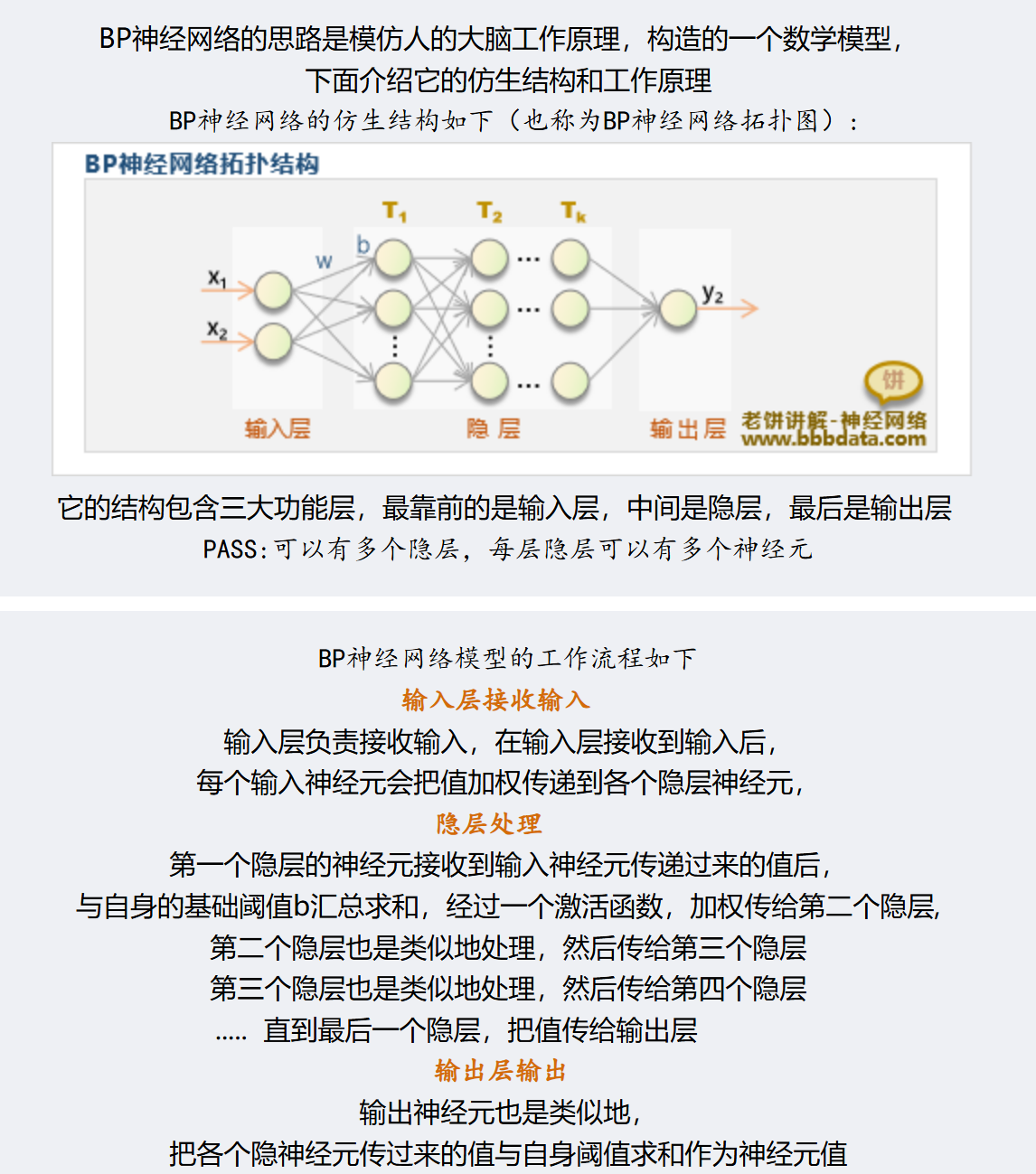
5. 进阶与补充知识点
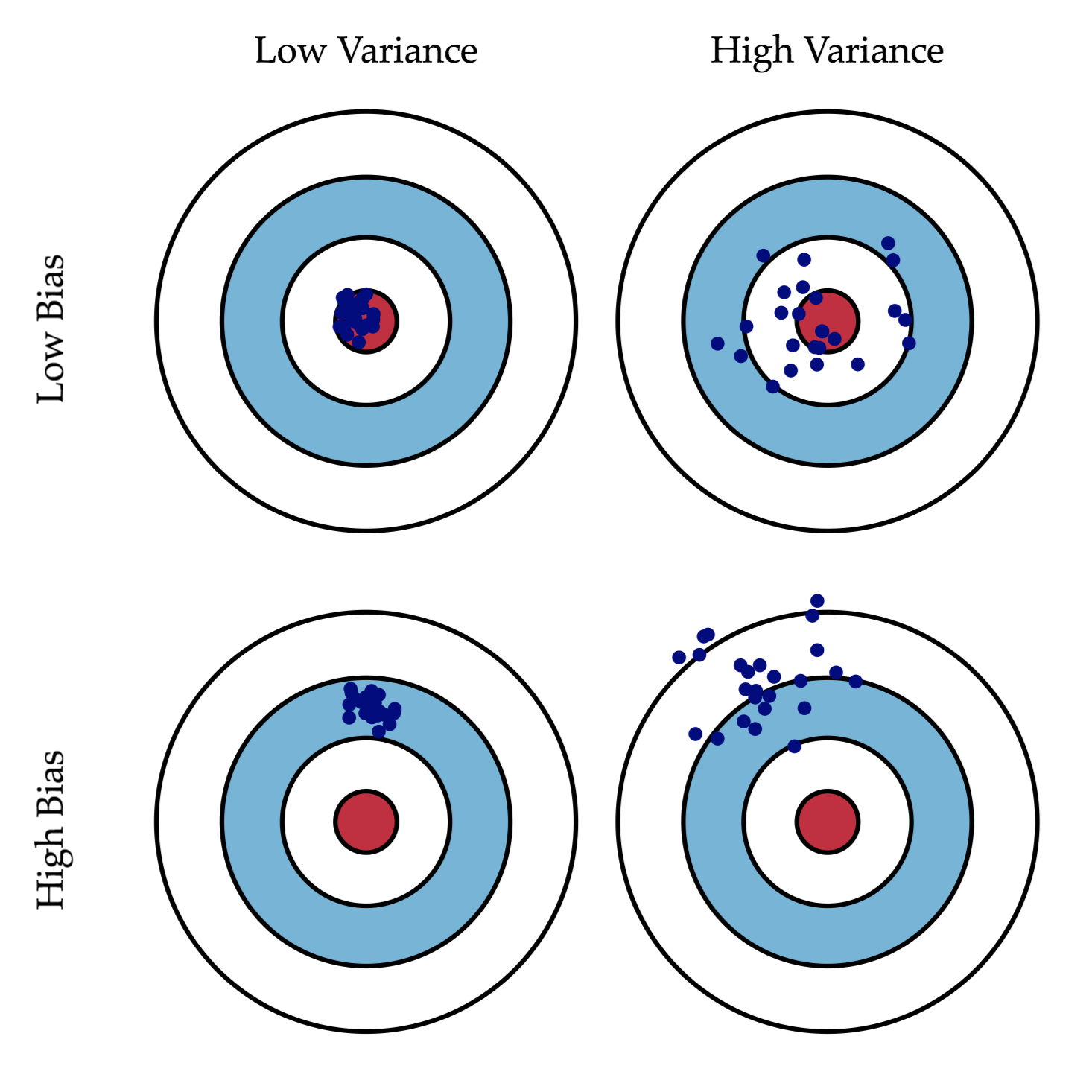
过拟合 vs 欠拟合
- 过拟合:
模型在训练集上表现极好,但在测试集上表现很差。就像“死记硬背”了考题,换个题就不会了。原因通常是模型太复杂或训练数据太少。
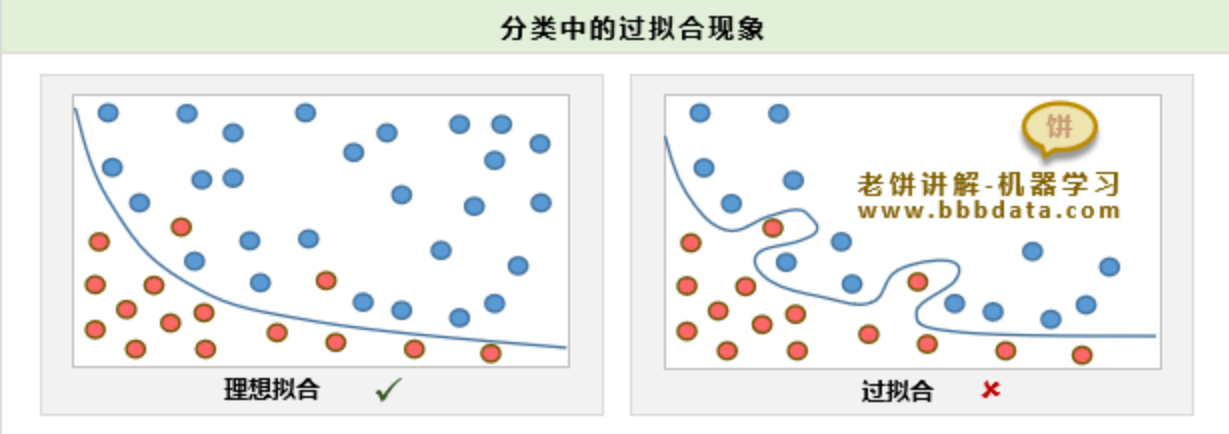
- 欠拟合:
模型连训练集的数据规律都没学好。原因通常是模型太简单或特征没选好。
- 解决方法:
过拟合可通过正则化、减少特征、增加数据量、集成学习来解决;欠拟合可通过增加模型复杂度、特征工程来解决。
特征工程
这是决定模型上限的关键。包括特征提取(从原始数据中提取有效信息)、特征构建(组合现有特征)、特征选择(剔除无关特征)。
集成学习
“三个臭皮匠,顶个诸葛亮”。通过组合多个弱分类器(如决策树)来构建一个强分类器。
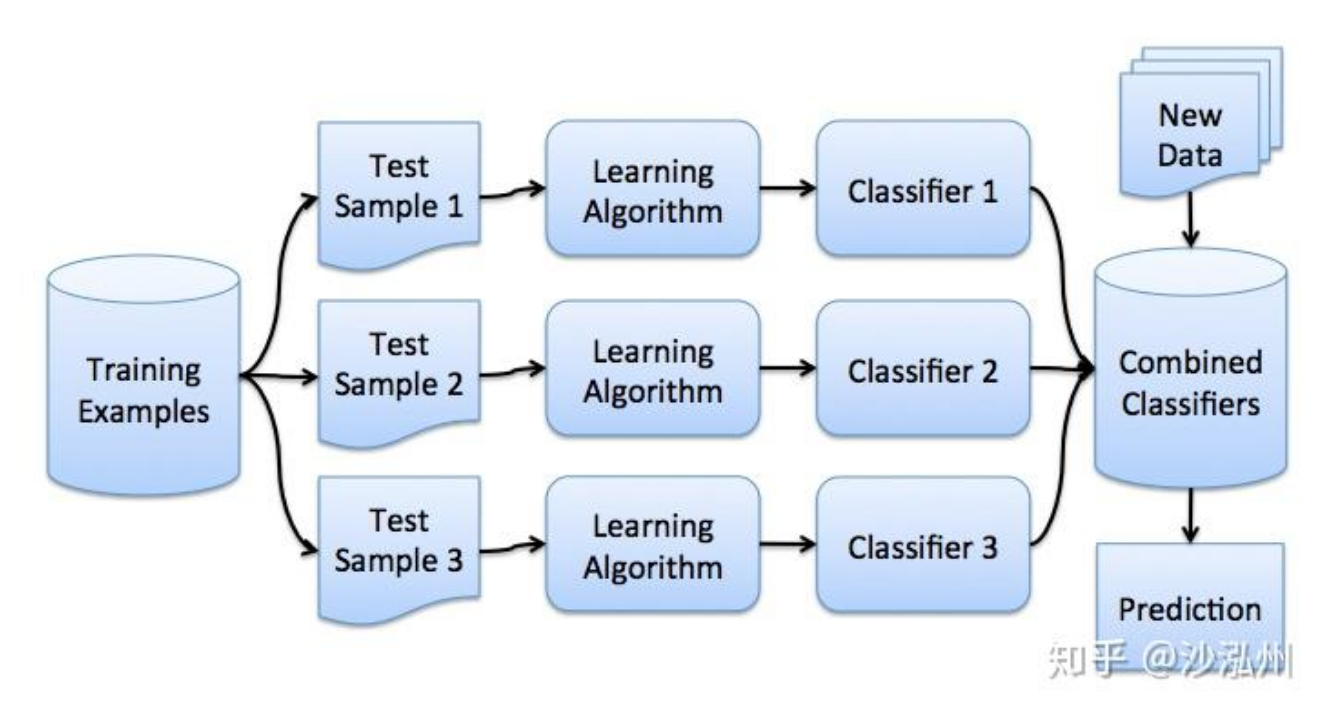
- Bagging:并行训练,随机抽样(如 Random Forest 随机森林)。降低方差,防过拟合。
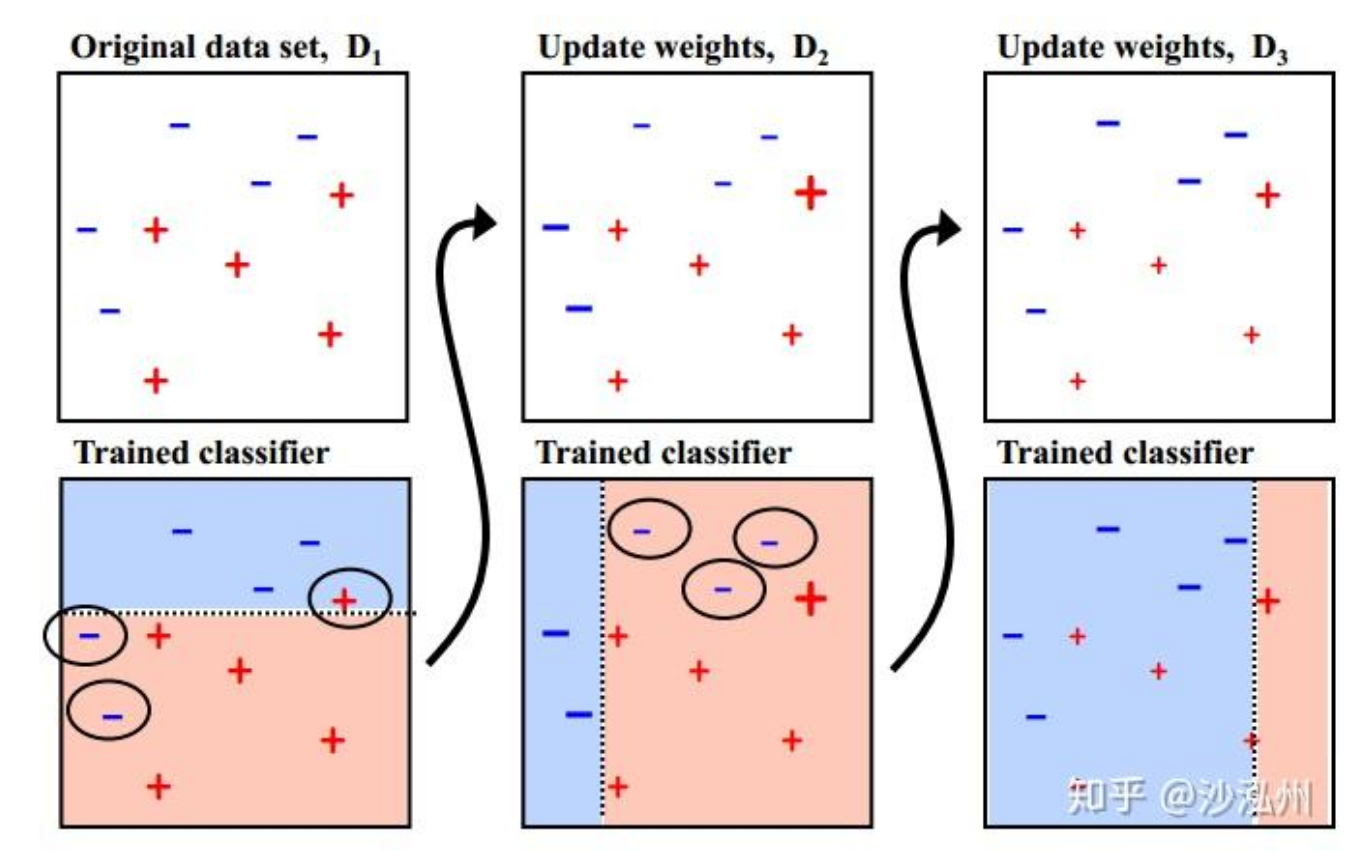
- Boosting:串行训练,关注错分样本(如 AdaBoost, XGBoost, LightGBM)。降低偏差,提升精度。
-
这两个都是集成学习方法,但策略完全不同。
Bagging 关注降低方差,Boosting 关注降低偏差。
比较维度
Bagging (Bootstrap Aggregating)
Boosting (如 AdaBoost, XGBoost)
核心思想
个体并行,集成求平均。通过训练多个独立的强分类器并取平均(或投票),降低模型的方差,防止过拟合。
个体串行,纠错累加。通过训练一系列弱分类器,每个新分类器都专注于纠正前一个分类器的错误,逐步降低偏差。
1)样本选择
有放回随机采样。每个基学习器使用的训练集是从原始集中有放回随机选取的,各轮训练集之间是独立的。
权重调整。每一轮的训练集不变(或基于权重的分布变化),但每个样例的权重会根据上一轮的分类结果进行调整。上一轮分错的样本权重增加,分对的权重降低。
2)样例权重
权重相等。使用均匀取样,每个样例在初始时的权重是相等的。
动态调整。根据错误率不断调整样例的权值,错误率越大的样例权重越大,迫使后续模型更关注“难分”的样本。
3)预测函数
权重相等。所有基分类器(预测函数)的地位相同,最终结果通过简单投票(分类)或平均(回归)得出。
权重不等。每个弱分类器都有相应的权重,分类误差小的分类器会有更大的权重(即说话更“响亮”),对最终结果影响更大。
4)并行计算
可以并行。各个基分类器之间没有依赖关系,可以同时生成,计算效率高。
只能串行。各个预测函数只能顺序生成,因为后一个模型参数(或样本权重)的计算需要依赖前一轮模型的结果。
代表算法
随机森林 是最典型的代表。
AdaBoost, GBDT, XGBoost, LightGBM 等。
优势与劣势
优势:不易过拟合,适合高维数据,易于并行化。
劣势:对噪声数据不敏感,可能导致模型性能提升有限。优势:预测精度通常很高,能有效处理偏差。
劣势:对异常值敏感,难以并行训练(虽然XGBoost等做了优化),容易过拟合。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)