机器学习--SVM
摘要: 支持向量机(SVM)是一种监督学习算法,擅长解决小样本、非线性及高维分类问题。其核心思想是寻找最优超平面,最大化分类间隔,并通过核函数处理线性不可分数据。SVM使用+1/-1标签区分类别,采用拉格朗日乘子法优化超平面,引入软间隔和松弛因子处理噪声数据。关键参数包括惩罚因子C和核函数(如线性、多项式、高斯核),需通过交叉验证选择。实际应用中,SVM在小样本上表现优异,但对大规模数据效率低,且
1、SVM是什么?
SVM(支持向量机,Support Vector Machine) 是一种经典的监督学习算法,主要用于分类和回归任务,特别擅长解决小样本、非线性、高维度的分类问题。
2、核心
想象你在平面上有两类点(红点和蓝点),SVM的目标是找到一条最优的分界线(决策边界),使得:
两类点被正确分开
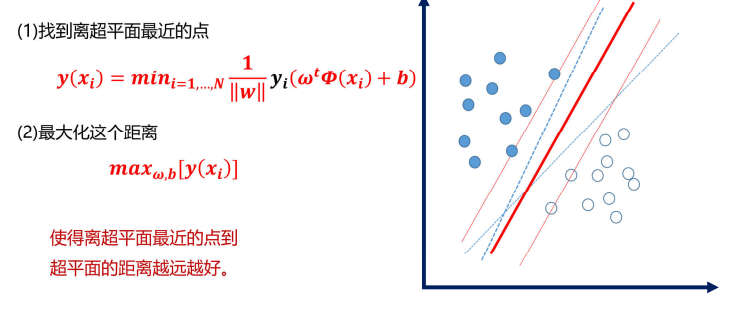
边界到最近点的距离最大化(这就是"最大间隔")
3、超平面方程

4、标签问题
在SVM中我们不用0和1来区分,使用+1和-1来区分,这样更严格,假设超平面可以将训练的样本正确分类,那么对于任意样本:
如果y=+1,则为正例
y=-1,则为负例
5、决策函数
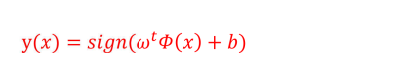
符号函数
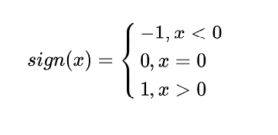
整合

6、距离问题
(1)点到直线的距离:
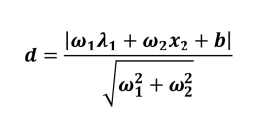
(2)点到平面的距离:
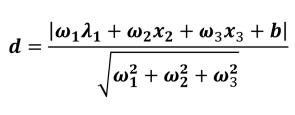
(3)点到超平面的距离
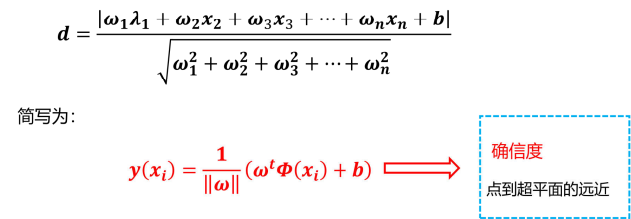
改进

如何寻找最优的超平面
拉格朗日乘子法:

7、软间隔
什么是软间隔?
数据中存在一些噪音,如果考虑这些噪音点的话,超平面可能表现的效果不好,这时就要用到软间隔
解决
允许个别样本点出现在间隔带里面
量化指标
引入松弛因子
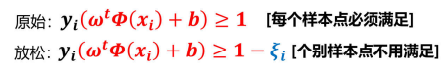
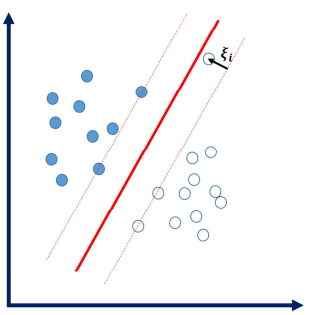
新的目标函数
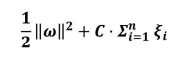
C:惩罚因子
(1)当C值比较大时,说明分类比较严格,不容有误
(2)当C值比较小时,说明分类比较宽松,可以有误
所以在我们写代码时,更要关注的是C的值,
8、核函数
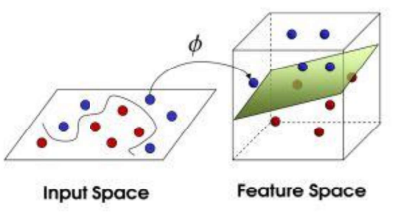
线性不可分情况
在二维空间无法用一条直线分开,映射到三维(或者更高维)空间即可解决
目标
找到一个![]() ,对原始数据做一个变换
,对原始数据做一个变换
![]() :就是核函数
:就是核函数
举例:
假如有两个数据,x1=(x1,×2,×3)x2=(Y1,y2:Y3),如果数据在三维空间无法线性可分,我们通过核函数将其从三维空间映射到更高的九维空间,那么此时:
f(X)=(x1x1,x1x2,x1x3,x2x1,x2x2,x2x3,x3x1,x3x2,x3x3)
如果计算内积的话,x1与x2计算即<f(x1)·f(x2)>,此时计算复杂度为:9*9=81,原始数据复杂度为
3*3=9,那么对于映射到n为空间,复杂度为:O(n^2)
对于数据点:x1=(1,2,3), x2=(4,5,6),则f(x1)=(1,2,3,2,4,6,3,6,9),f(x2)=(16,20,24,20,25,30,24,30,36),
此时计算<f(x1)·f(x2)>=16+240+72+40+100+180+72+180+324=1024
K(x,y)=(<x1,x2>)^2=(4+10+18)^2=32^2=1024
即:K(x,y)=(<x,y>)^2=<f(x1)·f(x2)>[先内积再平方与先映射再内积结果一致]
特性:在低维空间完成高维空间的运算,结果一致,大大降低了高维空间计算的复杂度。
本质:在找到一个(核)函数,将原始数据变换到高维空间,但是高维数据可以在低维运算。
常用核函数
(1)线性核函数
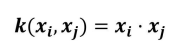
(2)多项式核函数
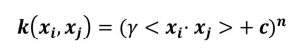
![]()
假如有两个数据,x1=(x1,x2),x2=(y1,y2),如果数据在二维空间无法线性可分,我们通过核函数将其从二维空间映射到更高的三维空间,那么此时:
![]()
更具体的例子:x1=(1,2),x2=(3,4)
(1)转换到三维再内积(高维运算)
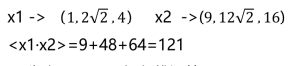
(2)先内积,再平方(低维运算)
![]()
(3)高斯核函数
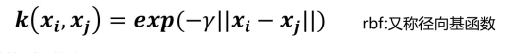
对于数据点1,转换到二维空间:
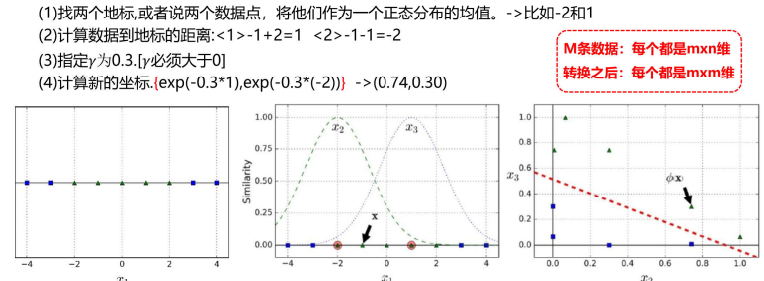
谈一下
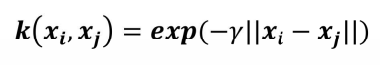
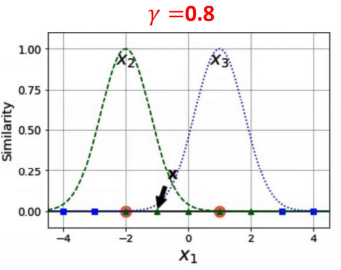
1.当![]() 越小的时候,正态分布越胖,辐射的数据范围越大,过拟合风险越低。
越小的时候,正态分布越胖,辐射的数据范围越大,过拟合风险越低。
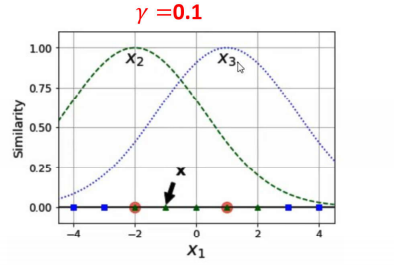
2.当![]() 越大的时候,正态分布越瘦,辐射的数据范围越小,过拟合风险越高。
越大的时候,正态分布越瘦,辐射的数据范围越小,过拟合风险越高。
优缺点介绍
优点:
1.有严格的数学理论支持,可解释性强,不同于传统的统计方法能简化我们遇到的问题。
2.能找出对任务有关键影响的样本,即支持向量。
3.软间隔可以有效松弛目标函数。
4.核函数可以有效解决非线性问题。
5.最终决策函数只由少量的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”
6.SVM在小样本训练集上能够得到比其它算法好很多的结果。
缺点:
1.对大规模训练样本难以实施。
SVM的空间消耗主要是存储训练样本和核矩阵,当样本数目很大时该矩阵的存储和计算将
耗费大量的机器内存和运算时间。超过十万及以上不建议使用SVM。
2.对参数和核函数选择敏感。
支持向量机性能的优劣主要取决于核函数的选取,所以对于一个实际问题而言,如何根据
实际的数据模型选择合适的核函数从而构造SVM算法。目前没有好的解决方法解决核函数的选择问题。
3.模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂
度较高。
9、支持向量机的API文档
class sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)[source]
重要的参数有:C、kernel、degree、gamma。
1.C :惩罚因子【浮点数,默认为1.】【软间隔】
(1)C越大,对误分类的惩罚增大,希望松弛变量接近0,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱;
(2)C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
->>建议通过交叉验证来选择
2. kernel: 核函数【默认rbf(径向基核函数|高斯核函数)】
可以选择线性(linear)、多项式(poly)、sigmoid
->>多数情况下选择rbf
3.degree:【整型,默认3维】
4. gamma: ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’。
(1)如果gamma是’auto’,那么实际系数是1 / n_features,也就是数据如果有10个特征,那么gamma值维0.1。(sklearn0.21版本)
(2)在sklearn0.22版本中,默认为’scale’,此时gamma=1 / (n_features*X.var())
#X.var()数据集所有值的方差。
<1>gamma越大,过拟合风险越高
<2> gamma越小,过拟合风险越低
->>建议通过交叉验证来选择
10、实际运用
通过网盘分享的文件:spambase.csv
链接: https://pan.baidu.com/s/1Z6KiBKAAoxq2szctSQum1Q 提取码: gs9r
import pandas as pd
import numpy as np
from sklearn.svm import SVC
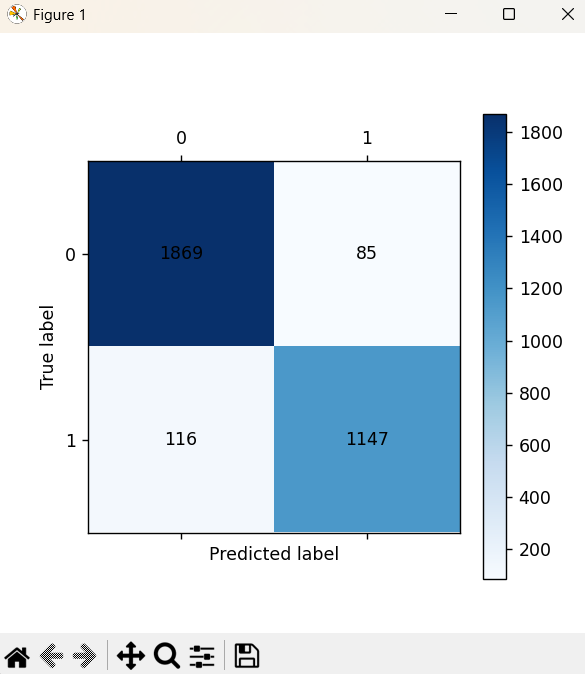
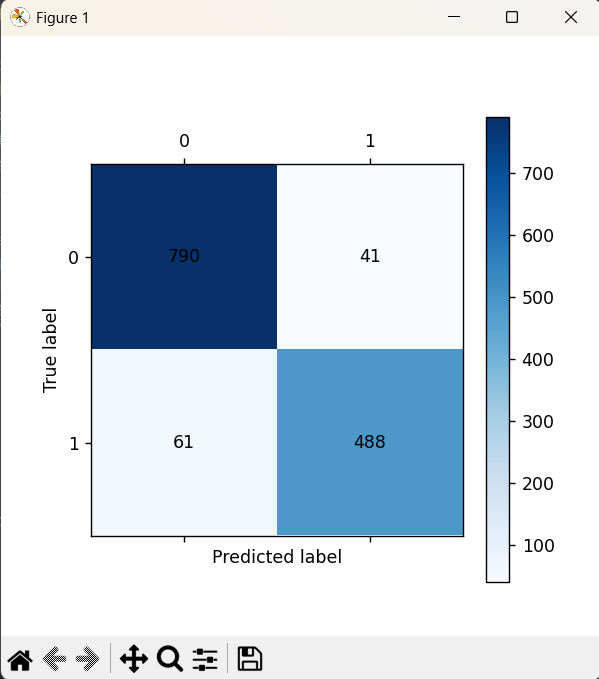
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y,yp)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
datas = pd.read_csv("spambase.csv")
x = datas.iloc[:, :-1]
y = datas.iloc[:, -1]
'''标准化'''
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test =train_test_split(x_scaled,y, test_size=0.3, random_state=0)
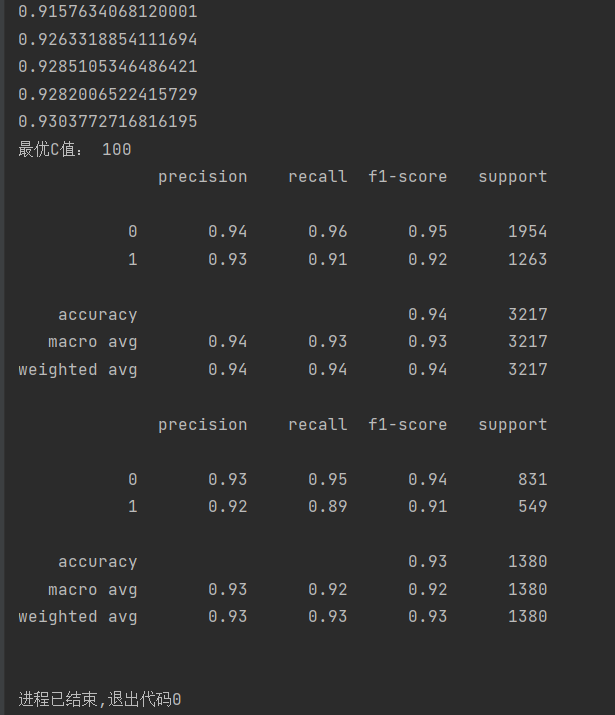
'''交叉验证方法、选取最优C值'''
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.01,0.1,1,10,100]
for i in c_param_range:
svm=SVC(kernel='linear',C=i,random_state=0)
score=cross_val_score(svm,x_train,y_train,cv=7)
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best=c_param_range[np.argmax(scores)]
print("最优C值:",best)
svm=SVC(kernel='linear',C=best,random_state=0)
svm.fit(x_train,y_train)
train_predict=svm.predict(x_train)
from sklearn import metrics
print(metrics.classification_report(y_train,train_predict))
cm_plot(y_train,train_predict).show()
test_predict=svm.predict(x_test)
print(metrics.classification_report(y_test,test_predict))
cm_plot(y_test,test_predict).show()注意c_param_range=[0.01,0.1,1,10,100]的取值不要太大,否则会运行的很慢,若取这些还是很慢,可以将cv=7降低成小于7的折数,再重新运行

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 40
40 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)