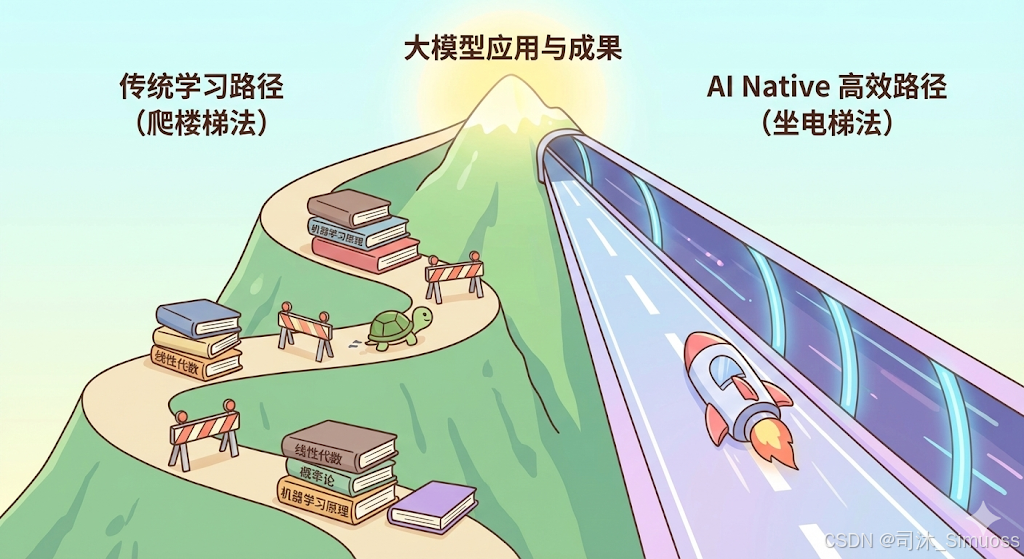
【26届读研/就业必看】基础课太难啃?来用AI时代的学习方法2个月速成大模型!
“学大模型先要看高数和机器学习?”这是传统时代的爬楼梯法!作为Agent架构师,我劝你立刻停下。大模型时代有直通顶楼的电梯。在这场深夜对谈中,我为迷茫的同学规划了一条“野路子”——AI Native高效学习路径。跳过几十年前的算法,用地表最强AI来学AI,直击神经网络和Transformer核心。别买昂贵显卡,去租算力;别只看知网,去刷Arxiv。点进来,司沐老师带你避开弯路,用两个月实现小白到顶
你好,我是司沐
经常有同学问我:“司沐老师,我想学大模型,我是不是得先去把《线性代数》和《概率论》复习一遍,然后去把吴恩达老师的《机器学习》看一遍?”
我的回答通常很直接:“如果你在未来想在学术领域深入研究,并且当下也有充足的时间,这当然是更好的方式;但如果你近一年内并不打算在学术路线深耕,还想做大模型应用开发,或者在研究生阶段快速出成果,请立刻停下!”
为什么?因为那是传统时代的爬楼梯法。在大模型时代,我们有电梯。
在这场深夜对谈中,我给那位 22 级计科专业的同学规划了一条AI Native(AI原生)的高效学习路径。今天,我把它公开分享出来。
01 避坑指南:不要在“旧地图”上找“新大陆”
首先,我要劝退一种最常见的学习方式:按部就班地从机器学习(Machine Learning)学起。
很多同学的学习路径是这样的:
线性回归 -> 逻辑回归 -> 支持向量机 (SVM) -> 决策树 -> … -> 神经网络 -> … -> Transformer -> 大模型
这个路径太慢了!
你要知道,传统的机器学习算法(比如 SVM、随机森林)和现在的大模型(Transformer 架构)之间,隔着巨大的技术鸿沟。
对于大多数不在纯学术领域深究的人来说,花一个月学懂了 SVM 的数学推导,对理解 ChatGPT 几乎没有任何帮助。
司沐老师的建议:
在前期先跳过那些几十年前的“经典算法”。你的目标是 LLM(大模型),那就直接从神经网络(Neural Networks)切入,直奔主题。
02 理论速成:3B1B,YYDS!
那不学高数,怎么理解神经网络?
千万别上来就看枯燥的教材。我强推一个资源,也是我在对谈中按头安利让他去看的——B站/YouTube 上的【3Blue1Brown】(简称 3B1B)。
特别是他的深度学习 Deep Learning系列。
这个系列还少收录了一支讲解大模型MLP层的视频,在这里:【官方双语】直观解释大语言模型如何储存事实 | 【深度学习第7章】

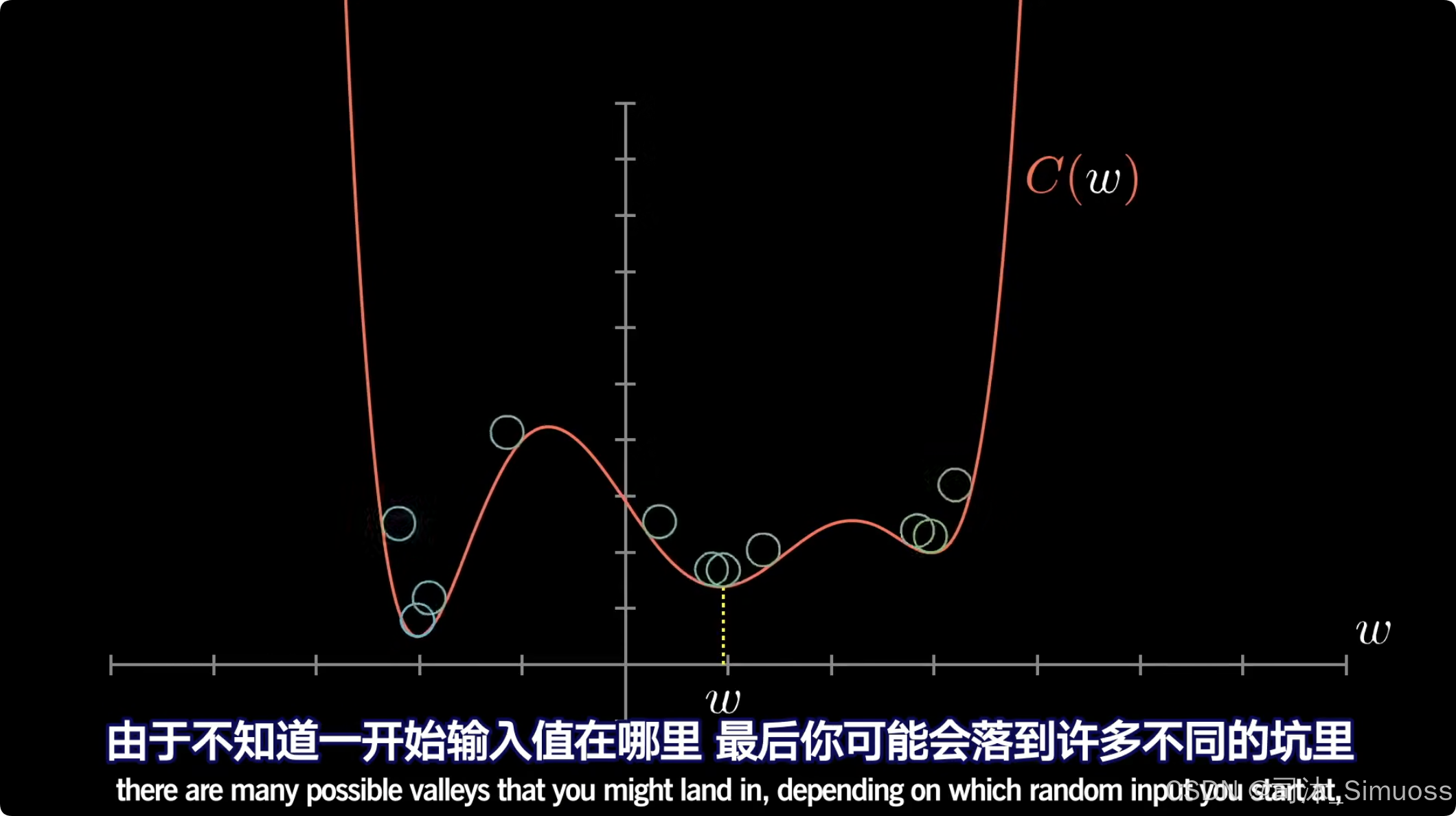
他用无与伦比的动态几何动画,把神经网络的本质——权重、偏置、梯度下降、反向传播——讲得清清楚楚。

- 你不需要盯着公式发呆,看动画你就能明白:哦,原来训练模型就是在一个高维空间里找最低点!
学习路线图(仅需理解概念,不求手推公式):
- NN(全连接网络): 理解最基础的神经元连接。
- CNN(卷积神经网络): 稍微了解一下它怎么处理图片(池化、卷积核),这是视觉模型的基础。
- Transformer(重中之重): 这是大模型的基石。你要理解它的“注意力机制”(Attention)——它是怎么做到“看见”句子里的每一个字并计算它们之间的关联的。
准确来说,当前的大模型并不完全等同于Transformer结构——他们通常只是Transformer的后半部分,仅解码器(Decoder Only)结构。
这个知识点在3B1B的视频中会提到。
看完这几个视频(算上记笔记和反复追问大模型以及四处找资料求证想法的时间,大概只需要几天),你的理论基础就超过了 50% 只会调包的人。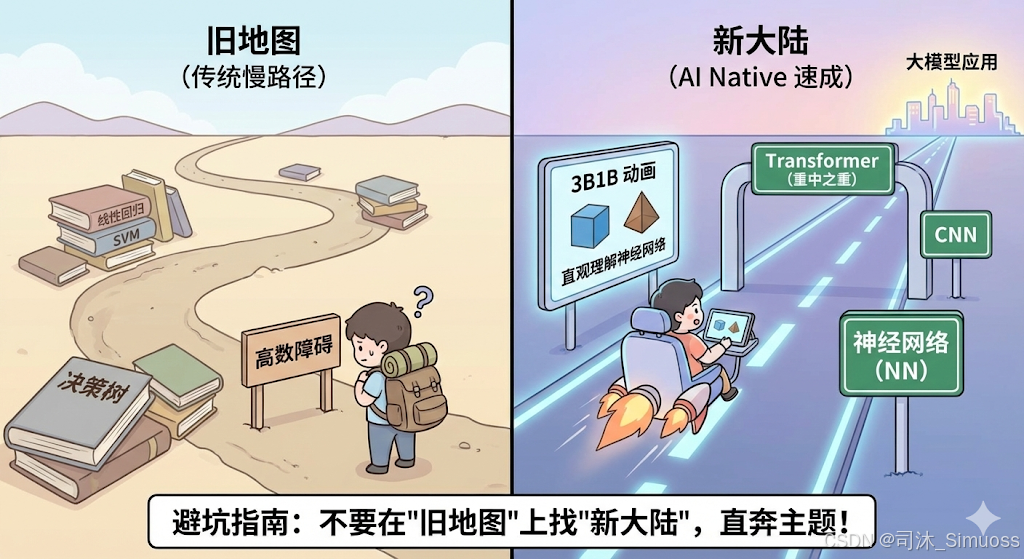
等拥有了一定的基础,就可以考虑一些进阶的学习资源了。
此时,就要隆重的搬出国内AI学习领域的老大哥:Datawhale!
在Datawhale的官网,你能找到任何想要的AI学习资源,从传统机器学习到深度学习再到大模型,以及一些工程教程,趣味项目,应有尽有。
唯独有一个东西找不到:付费渠道。因为里面的所有内容都是免费资源。
这里是倾注了理想主义者心力与奉献精神的一篇热土。我也有参与过其中一些内容贡献。
官网:Datawhale - 学用AI,从此开始
也可以直接在微信搜索Datawhale,关注微信公众号
由于Datawhale的重量级资源内容过于多了,所以就不在本篇内赘述,会在后面单独出一期。
如果你对此有兴趣,可以在评论区扣1告诉我,我会加速赶制
03 工具革命:用 AI 来学 AI(套娃战术)
以前学编程,遇到不懂的代码要查书、搜CSDN(虽然内容质量很烂)、知乎、问老师。
现在,如果你不懂某行代码,或者不懂某个论文里的公式,请直接问目前地表最强的 AI。
截止本文发布,我认为这个最强模型是谷歌出品的Gemini。当下的Gemini版本是Gemini 3。即使你可能因为国内网络原因无法访问,也仍值得想尽一切办法用到它,比如找国内中转。一个可能的搜索关键词是:“Gemini 国内中转 API”
当然,也不是说GPT、DeepSeek这种模型就不堪用,它们也有它们的用武之地,比如学一些难度较大但已经形成普遍共识的领域,比如入门Python、Java语言,学习Git、Linux、Docker、K8S等工具。
但是,如果你在入门一个非常崭新且资料较少的领域,比如大模型领域,那你一定需要一款能力强+最新出品的模型,这样的模型训练素材更新,懂得更多,不会给你帮倒忙。
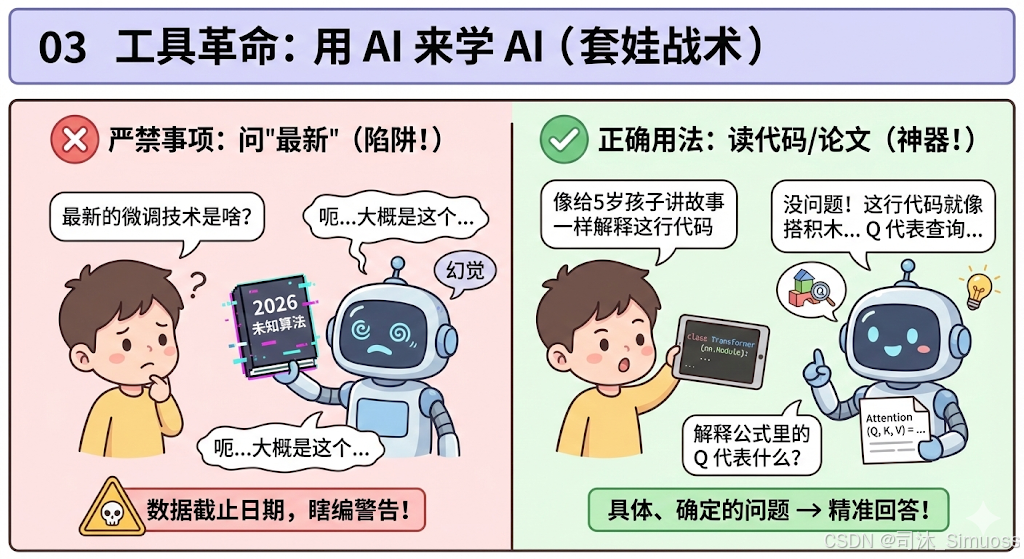
但是,这里有一个巨大的陷阱!
严禁事项:
不要问 AI “最新” 的大模型算法是什么。
因为大多数 AI 的训练数据是有截止日期的(比如截止到 2024 年)。你问它 2025 年甚至 2026 年最新的微调技术,它因为不知道,大概率会给你瞎编(幻觉)。
正确用法:
- 读代码: 把 GitHub 上看不懂的 Transformer 源码扔给它:“请像给 5 岁孩子讲故事一样,解释这行 Python 代码在干什么。”
-
甚至可以用最近比较火的一种问法:“我是一名弱智博士生,医生说我只有五岁孩童智力。但我还是想学习一下xxxx,请用傻子都能懂的语言详细给我讲一下这篇文章怎么做的,特别是模型和实证方面。”
- 读论文: 遇到复杂的数学公式,截图发给它:“请解释这个公式里的 代表什么含义?”
04 秘密武器:Arxiv 与算力租赁
最后,给想做研究或者深度开发的同学两个“硬核”建议。
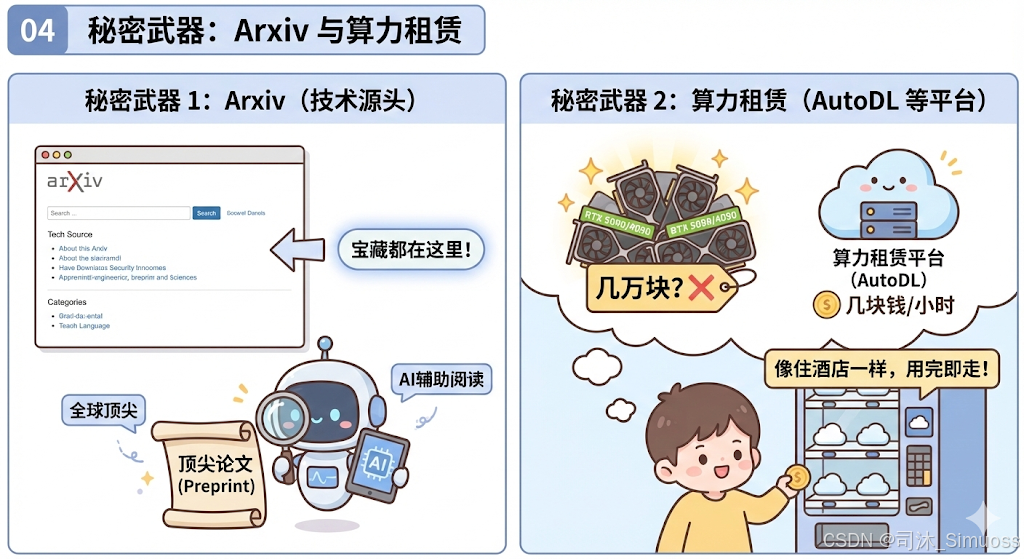
1. 必须知道的网站:Arxiv (arxiv.org)
如果一位计算机科班的同学读到了研究生,还只知道知网(CNKI),那是会被笑话的。
Arxiv 是全球计算机论文的“预印本”平台。全世界最顶尖的大模型论文(比如 DeepSeek 的技术报告),在发表期刊之前,都会先发在这里。
这里是技术的源头。 许多大佬害怕期刊审稿时间太长导致重要结论被别人抢先发表, 都会在投稿之前先把论文发布到这里。
即使前端页面写得很烂,你也得学会每天刷一刷。看不懂?用 AI 翻译+总结插件辅助阅读。
如果实在不会找,或是对英文比较抓瞎,可以尝试以下两个方法:
- 关注一些做论文解读的公众号,看他们推荐的文章;
- 找一些每日/每周AI新闻的账号,如果有企业或实验室发布了新模型/新算法/新框架,就可以有目的地搜他们的论文了。
2. 别买 5090,去“租房”住
很多同学问我:“司沐老师,我想学大模型,是不是得先买块 RTX 4090 或者等 5090?”
别冲动! 现在的显卡动辄几万块,而你初学阶段可能一周只跑几次代码。
去租算力(AutoDL 等平台)。
租一台带高端显卡的服务器,跑一小时可能只要几块钱人民币。像住酒店一样,用完即走。一个月一两百块钱,足够你跑通很多 Demo。
司沐老师的总结
大模型时代的学习逻辑已经变了。
- 以前: 苦学基础 -> 慢慢进阶 -> 终于能跑 Demo。
- 现在(AI Native): 跑通 Demo -> 遇到不懂的 -> 问 AI/看高质量科普视频 -> 补齐知识点。
这是一条自顶向下的野路子,但也是最高效的路子。
不要被那些高大上的名词吓倒。
你手里已经有了人类历史上最强的老师(大模型),你只需要一点点好奇心,和马上开始的行动力。
“种一棵树最好的时间是十年前,其次是现在。”
学大模型也是。
系列结语:
感谢大家陪伴读完这四篇连载。从职业规划到技术原理,再到架构设计和学习路线,希望这套《大模型突围指南》能成为你技术路上的手电筒。
如果你觉得有收获,点赞转发之类的套话就不说了,希望你可以把你认为的关键分享给你的朋友,或者在今后有人求助时,帮他们解解惑,让更多迷茫的同学看到路应该怎么走。
我是司沐,希望我们能在薪火相传中再次相见。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)