基于混沌-高斯变异-麻雀搜索算法(CGSSA)优化BP神经网络(CGSSA-BP)的回归预测(...
本套代码实现了一种基于改进混沌-高斯变异-麻雀搜索算法(CGSSA)优化BP神经网络的回归预测方案,核心目标是通过改进的智能优化算法提升传统BP神经网络的预测精度与稳定性。整体流程涵盖数据预处理、传统BP神经网络建模、CGSSA算法优化BP神经网络权值与阈值、模型预测与性能评估四大模块,最终通过多维度指标对比与可视化展示,验证CGSSA-BP模型相对于传统BP模型的优越性。代码采用MATLAB编写
基于混沌-高斯变异-麻雀搜索算法(CGSSA)优化BP神经网络(CGSSA-BP)的回归预测(含优化前后对比)MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,容易上手。 (电厂运行数据为例)
一、整体功能概述
本套代码实现了一种基于改进混沌-高斯变异-麻雀搜索算法(CGSSA)优化BP神经网络的回归预测方案,核心目标是通过改进的智能优化算法提升传统BP神经网络的预测精度与稳定性。整体流程涵盖数据预处理、传统BP神经网络建模、CGSSA算法优化BP神经网络权值与阈值、模型预测与性能评估四大模块,最终通过多维度指标对比与可视化展示,验证CGSSA-BP模型相对于传统BP模型的优越性。代码采用MATLAB编写,结构清晰、模块间耦合度低,可灵活适配不同回归预测场景的数据输入与参数调整。
二、核心模块功能解析
(一)混沌序列生成模块(Tent.m)
1. 功能定位
该模块为种群初始化提供混沌序列支持,通过Tent映射生成具有随机性、遍历性的初始值,解决传统随机初始化易陷入局部最优的问题,为后续智能优化算法的全局搜索能力奠定基础。
2. 核心逻辑
- Tent映射原理:基于分段函数生成混沌序列,当序列当前值小于设定参数
a(代码中默认0.7)时,下一个值通过“当前值/参数a”计算;当当前值大于等于参数a时,下一个值通过“(1-当前值)/(1-参数a)”计算,确保序列在[0,1]区间内均匀分布且具有混沌特性。 - 初始值设置:通过
rand()函数生成[0,1]区间内的随机初始值,避免固定初始值导致的序列重复性问题。 - 序列长度控制:接收外部传入的“最大长度”参数
max,生成长度为max的混沌序列,可根据后续种群规模与维度需求灵活调整输出序列长度。
3. 输入输出参数
- 输入参数:
max(整数),需生成的混沌序列长度。 - 输出参数:
x(向量),长度为max的Tent映射混沌序列,元素取值范围为[0,1]。
(二)预测误差计算模块(calc_error.m)
1. 功能定位
作为模型性能评估的核心模块,该模块接收“实际值”与“预测值”两组数据,计算回归预测场景中常用的多维度误差指标,并自动输出结果,为不同模型的性能对比提供量化依据。
2. 核心逻辑
- 数据格式统一:判断输入的实际值
x1与预测值x2是否为列向量,若为列向量则转换为行向量,避免因维度不匹配导致的计算错误。 - 误差指标计算:
- 绝对误差(error):直接通过“预测值-实际值”计算每个样本的误差,反映单一样本的预测偏差方向与大小。
- 绝对百分比误差(errorPercent):通过“绝对误差/实际值”计算,消除数据量级差异对误差评估的影响,便于跨场景误差对比。
- 平均绝对误差(MAE):对绝对误差取平均值,反映整体预测偏差的平均水平,指标值越小说明预测精度越高。
- 均方误差(MSE):对误差平方取平均值,放大较大误差的影响,可突出模型对极端值的预测能力。
- 均方根误差(RMSE):对MSE取平方根,将误差单位转换为与原始数据一致的单位,增强误差结果的可读性。
- 平均绝对百分比误差(MAPE):对绝对百分比误差取平均值,以百分比形式展示误差,直观反映预测值与实际值的相对偏差。
- 决定系数(R²):通过计算“实际值与预测值的协方差平方”与“实际值方差、预测值方差乘积”的比值,衡量模型对数据变化趋势的解释能力,R²越接近1说明模型拟合效果越好。
- 参数合法性校验:通过
nargin判断输入参数个数是否为2,若参数个数不符则输出错误提示,避免函数调用方式错误导致的运行异常。
3. 输入输出参数
- 输入参数:
x1(向量),实际值序列;x2(向量),预测值序列,要求两向量长度一致。 - 输出参数:
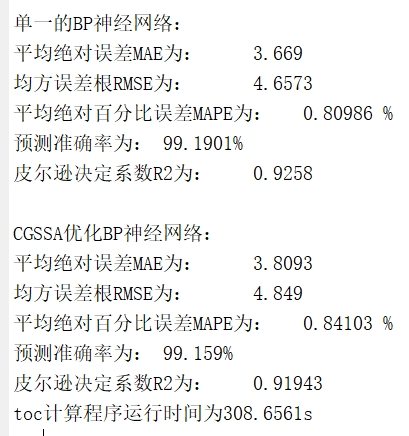
mae( scalar)、mse(scalar)、rmse(scalar)、mape(scalar)、error(向量)、errorPercent(向量),分别对应上述6类误差指标与2类基础误差序列;同时通过disp函数直接在命令行输出MAE、RMSE、MAPE(百分比形式)、预测准确率(1-MAPE)、R²的具体数值,便于快速查看。
(三)适应度计算模块(fitness.m)
1. 功能定位
作为CGSSA算法与BP神经网络的衔接核心,该模块将优化算法生成的“潜在最优解”(权值与阈值序列)转换为BP神经网络的可配置参数,通过网络训练与预测计算适应度值,为优化算法提供迭代方向依据。
2. 核心逻辑
- 参数解析与重构:接收长度为“输入层-隐含层权值数+隐含层阈值数+隐含层-输出层权值数+输出层阈值数”的一维向量
x,按对应维度将其拆分为输入层-隐含层权值(w1)、隐含层阈值(B1)、隐含层-输出层权值(w2)、输出层阈值(B2),并通过reshape函数将一维向量重构为符合BP神经网络要求的矩阵格式(如将w1重构为“隐含层节点数×输入层节点数”的矩阵)。 - 网络配置与训练:关闭BP神经网络的训练仿真界面(
net.trainParam.showWindow=0),避免迭代过程中界面弹窗干扰;将解析后的权值与阈值赋值给神经网络,使用训练集数据(inputn、outputn)进行网络训练。 - 适应度值计算:分别对训练集与测试集进行预测,通过
mapminmax函数将预测结果反归一化至原始数据量级;适应度值定义为“训练集RMSE与测试集RMSE的平均值”,该定义既保证模型对训练数据的拟合精度,又兼顾对测试数据的泛化能力,适应度值越小说明当前权值阈值组合越优。
3. 输入输出参数
- 输入参数:
x(向量),待评估的权值阈值组合;inputnum(整数),输入层节点数;hiddennum(整数),隐含层节点数;outputnum(整数),输出层节点数;net(BP神经网络对象),待配置的神经网络模型;inputn/outputn(矩阵),归一化后的训练集输入/输出数据;outputtrain(向量),原始训练集输出数据;inputntest(矩阵),归一化后的测试集输入数据;outputps(结构体),输出数据归一化参数;output_test(向量),原始测试集输出数据。 - 输出参数:
error(scalar),适应度值(训练集与测试集RMSE平均值);net(BP神经网络对象),配置当前权值阈值并训练后的神经网络模型。
(四)种群初始化模块(initializationNew.m)
1. 功能定位
基于Tent混沌序列实现CGSSA算法的种群初始化,生成分布均匀、覆盖整个搜索空间的初始种群,避免传统随机初始化导致的种群聚集问题,提升优化算法的全局搜索起点。
2. 核心逻辑
- 边界类型判断:通过
size(ub,2)判断变量边界类型,分为“所有变量边界相同”与“各变量边界不同”两种场景,确保初始化过程适配不同维度变量的边界约束。 - 混沌序列映射:调用
Tent.m生成[0,1]区间的混沌序列,通过“混沌值×(上边界-下边界)+下边界”的公式,将混沌序列映射至各变量的实际搜索区间[lb, ub]。 - 边界约束控制:对映射后的种群个体进行边界检查,若某维度数值超出[lb, ub]范围,则强制将其赋值为对应的边界值(超出上边界则取ub,超出下边界则取lb),确保种群个体始终在合法搜索空间内。
3. 输入输出参数
- 输入参数:
SearchAgents_no(整数),种群规模;dim(整数),变量维度(即权值阈值总个数);ub(向量/标量),变量上边界;lb(向量/标量),变量下边界。 - 输出参数:
Positions(矩阵),尺寸为“种群规模×变量维度”的初始种群矩阵,每行代表一个种群个体(一组权值阈值组合)。
(五)主程序模块(main.m)
1. 功能定位
作为整个系统的控制核心,该模块串联所有子模块,实现“数据读取-预处理-模型构建-优化迭代-预测评估-结果可视化”的全流程自动化运行,是用户交互与功能执行的入口。
2. 核心逻辑
- 环境初始化:通过
clear、close all、clc清空MATLAB工作区变量、关闭所有图形窗口、清除命令行内容,避免历史数据与窗口对当前运行的干扰;warning off关闭非关键警告提示,提升运行过程的简洁性;tic记录程序开始时间,用于后续计算总运行时长。 - 数据读取与划分:
- 读取Excel数据文件(默认路径与文件名可修改),提取“输入特征”(所有列除最后一列)与“输出目标”(最后一列)。
- 设定测试集样本数(默认100),按“前N-测试集数为训练集、后测试集数为测试集”的规则划分数据,并将输入输出数据转换为BP神经网络要求的行向量格式。
- 数据归一化:使用
mapminmax函数将训练集输入/输出数据归一化至[0,1]区间(输入)与默认区间(输出),同时保存归一化参数(inputps、outputps);通过mapminmax('apply')将测试集输入数据按训练集归一化参数进行处理,确保数据分布一致性。 - 传统BP神经网络建模与评估:
- 定义BP神经网络结构:输入层节点数为特征维度、输出层节点数为目标维度、隐含层节点数默认12,激活函数分别为
tansig(隐含层)与purelin(输出层),训练算法为trainlm(Levenberg-Marquardt算法)。 - 配置训练参数:训练次数1000次、学习率0.01、目标误差1e-5、显示频率25次/次、动量因子0.01、最小性能梯度1e-6、最大失败次数6,参数可根据数据复杂度调整。
- 模型训练与预测:使用训练集数据训练网络,对测试集进行预测,通过
mapminmax('reverse')反归一化预测结果,调用calc_error.m计算传统BP模型的误差指标。 - CGSSA算法优化BP神经网络:
- 初始化优化参数:种群规模20、最大进化代数17、预警值0.6、发现者比例0.7、危险麻雀比例0.2、变量上边界3、下边界-3,参数可通过实验调试优化。
- 种群初始化:调用
initializationNew.m生成基于Tent混沌序列的初始种群,计算初始种群的适应度值(调用fitness.m),对适应度值排序并记录全局最优适应度与位置。 - 优化迭代过程:
1. 发现者更新:根据随机数与预警值的大小关系,采用不同策略更新发现者位置,平衡全局搜索与局部探索能力。
2. 加入者更新:分为两类加入者,分别采用“跟随最优个体”与“随机扰动”策略更新位置,提升种群多样性。
3. 危险麻雀更新:对意识到危险的麻雀,根据其适应度值与全局最优的关系,采用“向最优个体靠拢”或“远离最差个体”策略更新位置,避免种群陷入局部最优。
4. 边界控制:对更新后的种群个体进行边界检查,确保所有个体在合法搜索空间内。
5. 高斯变异与混沌扰动:计算种群平均适应度,对适应度优于平均值的个体进行高斯变异(增加局部搜索精度),对适应度差于平均值的个体进行Tent混沌扰动(扩大搜索范围),进一步提升优化算法的寻优能力。
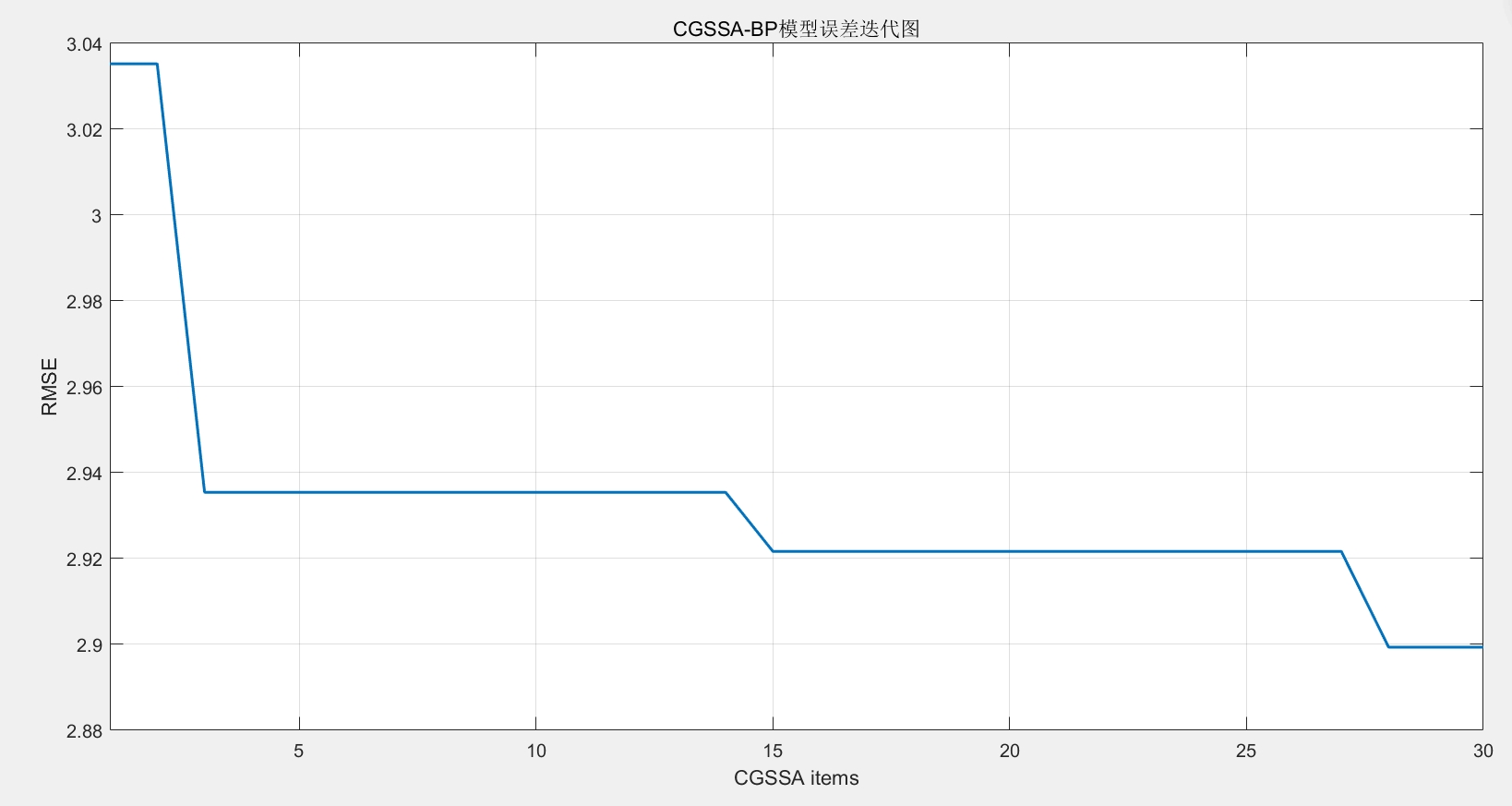
6. 最优解更新:每次迭代后排序适应度值,更新全局最优适应度与位置,记录迭代曲线(每代全局最优适应度)。 - 优化结果应用:将迭代得到的全局最优位置(Best_pos)解析为BP神经网络的权值与阈值,重构网络并重新训练,得到CGSSA-BP优化模型。
- CGSSA-BP模型评估与可视化:
- 模型预测:使用优化后的网络对测试集进行预测,反归一化结果后调用
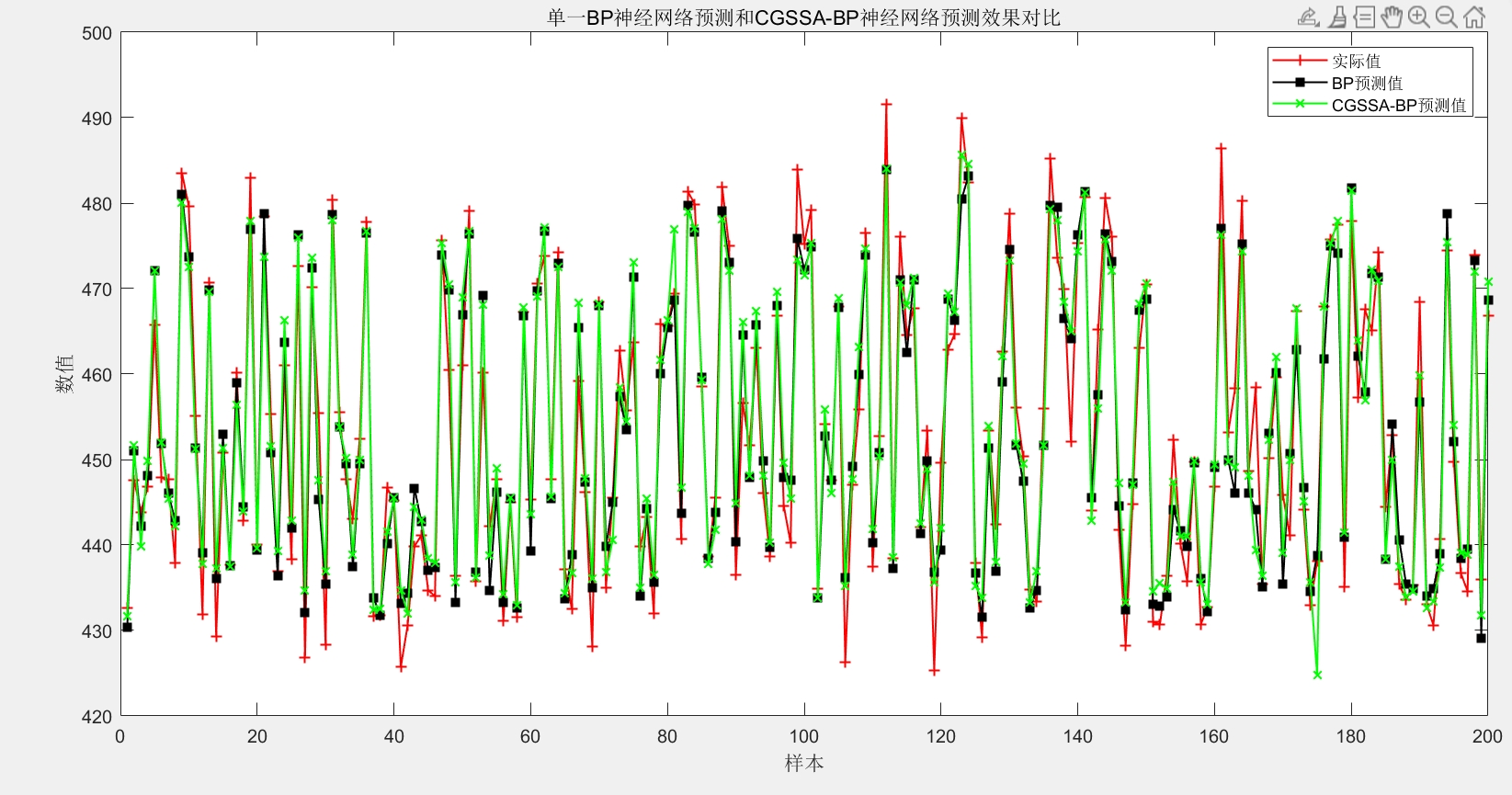
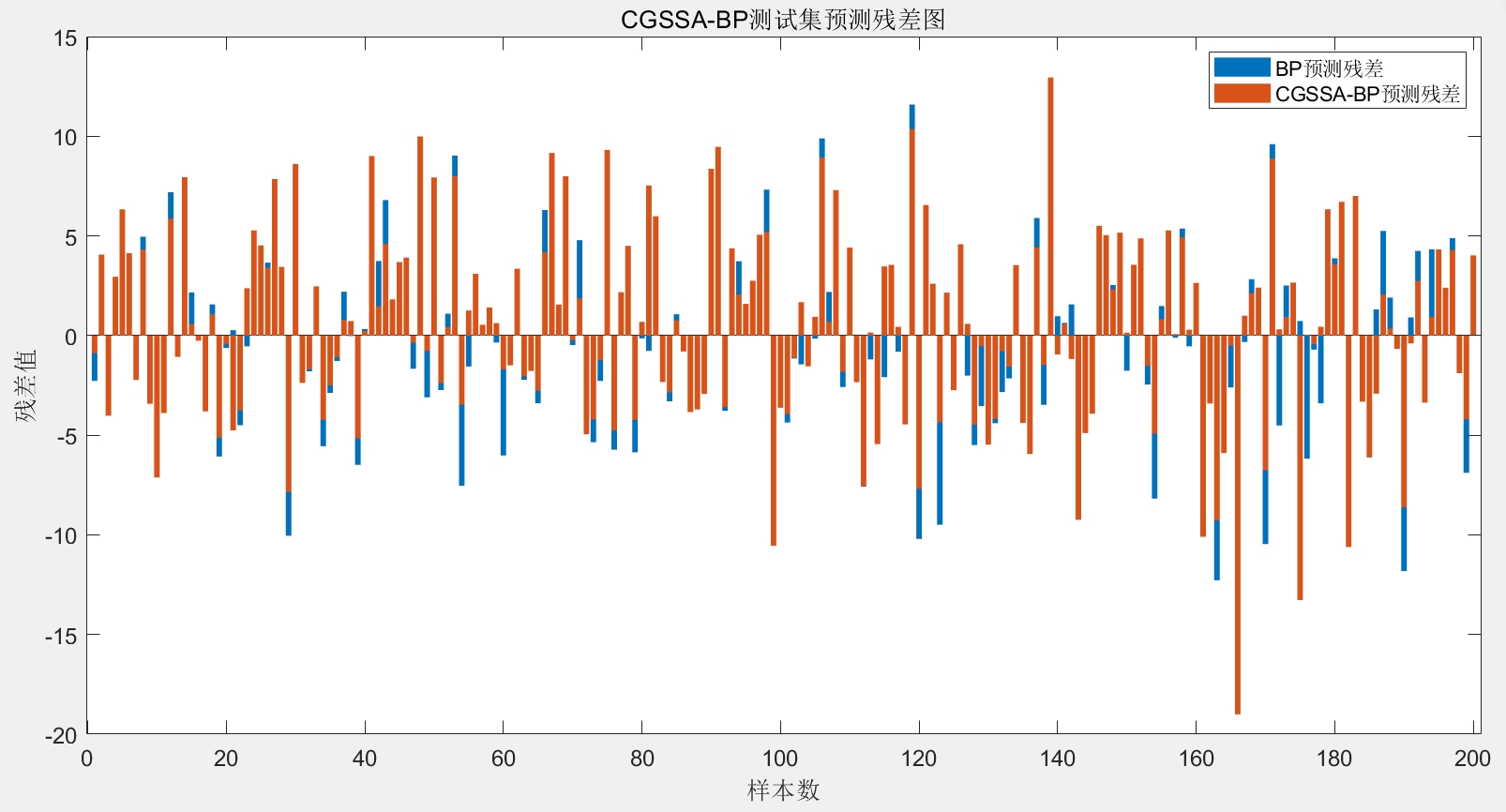
calc_error.m计算误差指标,与传统BP模型对比。 - 结果可视化:生成三张图表——CGSSA算法误差迭代图(展示适应度值随迭代次数的变化趋势)、实际值与两种模型预测值对比图(直观展示预测精度差异)、两种模型残差对比图(展示误差分布情况),通过图形化方式清晰呈现优化效果。
- 程序收尾:
toc计算程序总运行时长并输出,delete(h0)关闭进度条窗口,完成整个流程。
3. 输入输出参数
- 输入参数:无显式输入,通过修改代码中“数据文件路径”“测试集数”“网络参数”“优化参数”等变量实现自定义输入。
- 输出参数:无显式输出,通过命令行输出两种模型的误差指标与程序运行时长,通过图形窗口输出三张可视化图表,结果可直接用于模型性能分析与报告撰写。
三、模块间调用关系
各模块通过参数传递形成紧密协作的整体,调用关系如下:
- 主程序→种群初始化模块→混沌序列生成模块:main.m调用initializationNew.m时,initializationNew.m进一步调用Tent.m生成混沌序列,为种群初始化提供数据支持。
- 主程序→适应度计算模块→误差计算模块:main.m在计算种群适应度时调用fitness.m,fitness.m在训练网络后计算误差时,间接依赖calcerror.m的误差计算逻辑(虽未直接调用,但核心指标计算方法一致,且最终模型评估直接调用calcerror.m)。
- 主程序→误差计算模块:main.m在传统BP模型与CGSSA-BP模型评估阶段,均直接调用calc_error.m计算误差指标,为模型对比提供统一标准。
- 主程序→其他所有模块:main.m作为控制核心,直接或间接调用所有子模块,是模块间协同工作的枢纽,各子模块仅在主程序的调度下执行特定功能,不直接相互调用,降低了模块间的耦合度。
四、关键技术亮点
- 混沌优化增强全局搜索:通过Tent映射生成混沌序列用于种群初始化,解决传统随机初始化种群分布不均的问题,使初始种群更均匀地覆盖搜索空间,提升优化算法的全局寻优起点。
- 高斯变异与混沌扰动结合:在CGSSA迭代过程中,针对不同适应度水平的个体采用差异化改进策略——高斯变异提升优个体的局部搜索精度,混沌扰动扩大差个体的搜索范围,兼顾算法的收敛速度与寻优精度。
- 多维度误差评估体系:整合MAE、MSE、RMSE、MAPE、R²五类核心误差指标,从“绝对偏差”“平方偏差”“相对偏差”“拟合程度”四个维度全面评估模型性能,避免单一指标的局限性。
- 模块化设计便于扩展:各功能模块独立封装,参数接口清晰,可根据实际需求替换核心模块(如将Tent映射替换为Logistic映射、将BP神经网络替换为RBF神经网络),同时支持参数灵活调整,适配不同回归预测场景。
五、使用建议与注意事项
- 参数调整建议:
- 隐含层节点数:默认12,可通过“试错法”调整(如5-20范围内测试),避免节点数过少导致欠拟合或过多导致过拟合。
- 优化参数:种群规模建议20-50、最大进化代数建议15-30,参数过大会增加计算成本,过小可能导致寻优不充分;预警值、发现者比例等参数可参考同类文献或通过控制变量法调试。
- 训练参数:学习率建议0.001-0.05,目标误差建议1e-4-1e-6,需根据数据噪声水平与收敛速度需求调整。 - 数据预处理注意事项:
- 确保输入数据无缺失值与异常值,需在读取数据前通过插值、删除等方法处理异常数据,避免影响模型训练效果。
- 若数据各特征量级差异较大,建议在归一化前进行标准化处理(如Z-Score标准化),提升模型对特征的敏感度。 - 运行环境要求:需安装MATLAB R2016b及以上版本,确保
nntoolbox(神经网络工具箱)已正确安装,避免因版本兼容或工具箱缺失导致的运行错误。 - 结果分析建议:除关注误差指标外,需结合可视化图表分析模型的稳定性——如残差图中残差是否随机分布、无明显趋势,迭代图中适应度值是否平稳收敛,避免仅依赖单一指标判断模型优劣。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)