马尔可夫链蒙特卡洛(MCMC)——用随机探索破解复杂概率分布
MCMC方法之美在于它将两个看似简单的概念——蒙特卡洛随机抽样和马尔可夫链——结合成一个强大的工具,解决了贝叶斯推断中的核心计算难题。正如我们的探险家通过随机游走最终能找到宝藏分布一样,MCMC让我们能够在高维、复杂的概率空间中进行有效探索。从Metropolis-Hastings的接受-拒绝机制到Gibbs采样的条件更新策略,这些算法为我们提供了在不同场景下应对挑战的工具。虽然MCMC不是万能的
引言:用随机探索破解复杂概率分布
你得到一张神秘的藏宝图,上面没有坐标,只有深浅不一的颜色——颜色越深,埋藏宝藏的可能性越高。但地图太大,无法逐一检查;颜色变化太复杂,也无法用公式计算。传统方法束手无策。
这时,你采取了一个巧妙的策略:随机选择一个起点,每天随机移动到一个新位置。比较新旧位置的颜色深浅后:
- 新位置颜色更深,就留下
- 新位置颜色更浅,则以一定概率决定是否留下
经过长时间探索,你在各处停留的时间比例,恰好反映了地图的颜色深浅分布。这就是马尔可夫链蒙特卡洛(MCMC)的核心思想:通过构建一个特殊的随机游走过程,使其最终访问各处的频率正好等于目标概率分布。你不必计算整个分布,只需通过"体验"就能逐渐揭示其全貌。
一、MCMC:在复杂世界中找到方向的数学艺术
马尔可夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)是一种通过随机模拟来近似复杂概率分布的计算方法。它由两个核心部分组成:
- 马尔可夫链:一个随机过程,其下一个状态只依赖于当前状态
- 蒙特卡洛:通过随机采样来近似计算数学问题
MCMC的核心逻辑很直观:我们构造一个马尔可夫链,让这个链运行足够久后,状态分布能稳定在我们想研究的“目标概率分布”上。这时,链产生的一系列状态,就相当于从目标分布中采来的样本,我们通过分析这些样本,就能摸清目标分布的规律。
在贝叶斯统计、机器学习、统计物理等领域,我们经常需要处理复杂的概率分布。这些分布通常:高维、没有解析形式、无法直接采样、计算归一化常数困难。MCMC通过巧妙构造马尔可夫链,让我们能够间接地从这些复杂分布中采样,进而估计期望、方差、置信区间等统计量。
二、马尔可夫链:随机游走的数学基础
一个马尔可夫链由以下元素定义:
- 状态空间:所有可能状态的集合 S={s1,s2,… }S = \{s_1, s_2, \dots\}S={s1,s2,…};比如探索的藏宝图区域,每个位置就是一个“状态”,所有位置的集合就是状态空间;
- 转移概率:P(Xt+1=sj∣Xt=si)P(X_{t+1} = s_j | X_t = s_i)P(Xt+1=sj∣Xt=si),表示从状态 sis_isi 转移到状态 sjs_jsj 的概率;比如从位置A走到位置B的概率、留在A的概率,都是转移概率;
- 初始分布:P(X0)P(X_0)P(X0),链的起始状态分布;一开始选择的状态的概率分布。比如你随机站在藏宝图的某个点,这个随机选择的规则就是初始分布。
马尔可夫链的核心是“马尔可夫性质”(也就是前面说的无记忆性),用通俗的话解释就是:下一个状态只和现在的状态有关,和过去的状态无关。比如你现在在位置C,不管你是从A走到C,还是从B走到C,明天走到D的概率都是一样的。
对于马尔可夫链,有一个关键概念叫“平稳分布”:当链运行足够久后,状态的分布会稳定下来,不再随时间变化。
π(sj)=∑si∈Sπ(si)P(si→sj)对所有sj \pi(s_j) = \sum_{s_i \in S} \pi(s_i) P(s_i \to s_j) \quad \text{对所有} s_j π(sj)=si∈S∑π(si)P(si→sj)对所有sj
要让一个分布成为平稳分布,有个简单的判断条件(细致平衡条件):对于任意两个状态A和B,“在平稳分布下处于A的概率×从A走到B的概率”,等于“处于B的概率×从B走到A的概率”。满足这个条件的分布,一定是平稳分布,而且链是“可逆”的——从A到B和从B到A的概率在长期来看是平衡的。
π(si)P(si→sj)=π(sj)P(sj→si)对所有si,sj \pi(s_i) P(s_i \to s_j) = \pi(s_j) P(s_j \to s_i) \quad \text{对所有} s_i, s_j π(si)P(si→sj)=π(sj)P(sj→si)对所有si,sj
如果马尔可夫链满足:
- 不可约:任何一个状态,都能通过有限步走到其他任意状态。比如藏宝图上没有完全隔绝的区域,你总能从一个点走到另一个点;
- 非周期性:没有固定的“循环周期”。比如不会出现“每3步必回到原点”的规律,否则状态分布会一直周期性波动,无法稳定;
- 正常返:每个状态都会被无限次访问。比如不会走到某个状态后,永远再也回不来。
只要满足这三个条件,不管你一开始从哪个点出发,走足够久之后,位置分布都会收敛到唯一的平稳分布——这也是MCMC能“摸清”目标分布的基础。
limt→∞P(Xt=sj)=π(sj)对所有sj \lim_{t \to \infty} P(X_t = s_j) = \pi(s_j) \quad \text{对所有} s_j t→∞limP(Xt=sj)=π(sj)对所有sj
三、Metropolis-Hastings算法
3.1 算法思想
Metropolis-Hastings(M-H)算法是MCMC的经典核心算法,思路为“智能随机游走”:基于目标分布概率高低决定是否接受新状态,兼顾探索性与高概率区域聚焦性。
核心流程:初始状态→生成候选状态→计算接受概率→判断是否接受→迭代记录。
- 从当前状态 θt\theta_tθt 出发
- 提出一个候选状态 θ∗\theta^*θ∗(从一个提议分布中采样)
- 计算接受概率 α\alphaα
- 以概率 α\alphaα 接受新状态,否则停留在当前状态
3.2 算法步骤
输入:目标分布 π(θ)\pi(\theta)π(θ)(可以只到比例常数),提议分布 q(θ∗∣θ)q(\theta^*|\theta)q(θ∗∣θ)
- 初始化 θ0\theta_0θ0
- 对 t=0,1,2,…,N−1t = 0, 1, 2, \dots, N-1t=0,1,2,…,N−1:
a. 从 q(θ∗∣θt)q(\theta^*|\theta_t)q(θ∗∣θt) 采样候选点 θ∗\theta^*θ∗
b. 计算接受概率:
α=min(1,π(θ∗)q(θt∣θ∗)π(θt)q(θ∗∣θt)) \alpha = \min\left(1, \frac{\pi(\theta^*)q(\theta_t|\theta^*)}{\pi(\theta_t)q(\theta^*|\theta_t)}\right) α=min(1,π(θt)q(θ∗∣θt)π(θ∗)q(θt∣θ∗))
c. 从均匀分布 U(0,1)U(0,1)U(0,1) 采样 uuu
d. 如果 u<αu < \alphau<α,则 θt+1=θ∗\theta_{t+1} = \theta^*θt+1=θ∗,否则 θt+1=θt\theta_{t+1} = \theta_tθt+1=θt
输出:样本序列 {θ0,θ1,…,θN}\{\theta_0, \theta_1, \dots, \theta_N\}{θ0,θ1,…,θN}
3.3 算法解读
接受概率的直观理解:
- 如果 π(θ∗)>π(θt)\pi(\theta^*) > \pi(\theta_t)π(θ∗)>π(θt) 且提议分布对称,则 α=1\alpha = 1α=1,总是移动到概率更高的点
- 如果 π(θ∗)<π(θt)\pi(\theta^*) < \pi(\theta_t)π(θ∗)<π(θt),则以概率 π(θ∗)π(θt)\frac{\pi(\theta^*)}{\pi(\theta_t)}π(θt)π(θ∗) 移动到概率较低的点
- 这保证了在平稳状态下,停留在高概率区域的时间更长
提议分布的选择:
- 对称提议:q(θ∗∣θt)=q(θt∣θ∗)q(\theta^*|\theta_t) = q(\theta_t|\theta^*)q(θ∗∣θt)=q(θt∣θ∗),如高斯分布,此时 α=min(1,π(θ∗)π(θt))\alpha = \min\left(1, \frac{\pi(\theta^*)}{\pi(\theta_t)}\right)α=min(1,π(θt)π(θ∗))
- 独立提议:q(θ∗∣θt)=q(θ∗)q(\theta^*|\theta_t) = q(\theta^*)q(θ∗∣θt)=q(θ∗),不依赖当前状态
- 随机游走提议:θ∗=θt+ϵ\theta^* = \theta_t + \epsilonθ∗=θt+ϵ,其中 ϵ\epsilonϵ 来自某个分布
四、Gibbs采样
4.1 算法思想
Gibbs采样是M-H算法的特例,专为高维分布设计,核心思想:一次仅更新一个维度参数,固定其他维度,将高维问题拆解为低维问题。
示例:探索“温度-湿度”二维分布时,先固定湿度更新温度,再固定新温度更新湿度,循环迭代。
4.2 算法步骤
假设目标分布是 p(θ1,θ2,…,θd)p(\theta_1, \theta_2, \dots, \theta_d)p(θ1,θ2,…,θd)
- 初始化 (θ1(0),θ2(0),…,θd(0))(\theta_1^{(0)}, \theta_2^{(0)}, \dots, \theta_d^{(0)})(θ1(0),θ2(0),…,θd(0))
- 对 t=0,1,2,…,N−1t = 0, 1, 2, \dots, N-1t=0,1,2,…,N−1:
a. 采样 θ1(t+1)∼p(θ1∣θ2(t),…,θd(t))\theta_1^{(t+1)} \sim p(\theta_1 | \theta_2^{(t)}, \dots, \theta_d^{(t)})θ1(t+1)∼p(θ1∣θ2(t),…,θd(t))
b. 采样 θ2(t+1)∼p(θ2∣θ1(t+1),θ3(t),…,θd(t))\theta_2^{(t+1)} \sim p(\theta_2 | \theta_1^{(t+1)}, \theta_3^{(t)}, \dots, \theta_d^{(t)})θ2(t+1)∼p(θ2∣θ1(t+1),θ3(t),…,θd(t))
c. …
d. 采样 θd(t+1)∼p(θd∣θ1(t+1),…,θd−1(t+1))\theta_d^{(t+1)} \sim p(\theta_d | \theta_1^{(t+1)}, \dots, \theta_{d-1}^{(t+1)})θd(t+1)∼p(θd∣θ1(t+1),…,θd−1(t+1))
4.3 算法特点
- 总是接受:M-H算法不同,Gibbs采样中每个维度的更新都不用计算接受概率,一定会接受新采样的数值。这是因为它的更新规则天然满足平稳分布的条件,简化了计算;
- 需要条件分布:核心要求是“知道每个维度的条件分布”——也就是固定其他参数时,当前参数的概率分布。如果条件分布容易获取(比如是常见的正态分布、均匀分布),Gibbs采样效率很高;但如果条件分布很复杂,就很难应用;
- 顺序更新:可以按固定的顺序更新(比如先更参数1、再更参数2),也可以随机选择更新的维度,不影响最终的收敛结果;
- 块Gibbs采样:如果某些参数之间相关性很强,把它们分成一组一起更新,能提高算法的收敛速度。比如探索“身高”和“体重”的联合分布,把两者作为一个“块”一起更新,比单独更新更高效。
五、实际应用示例
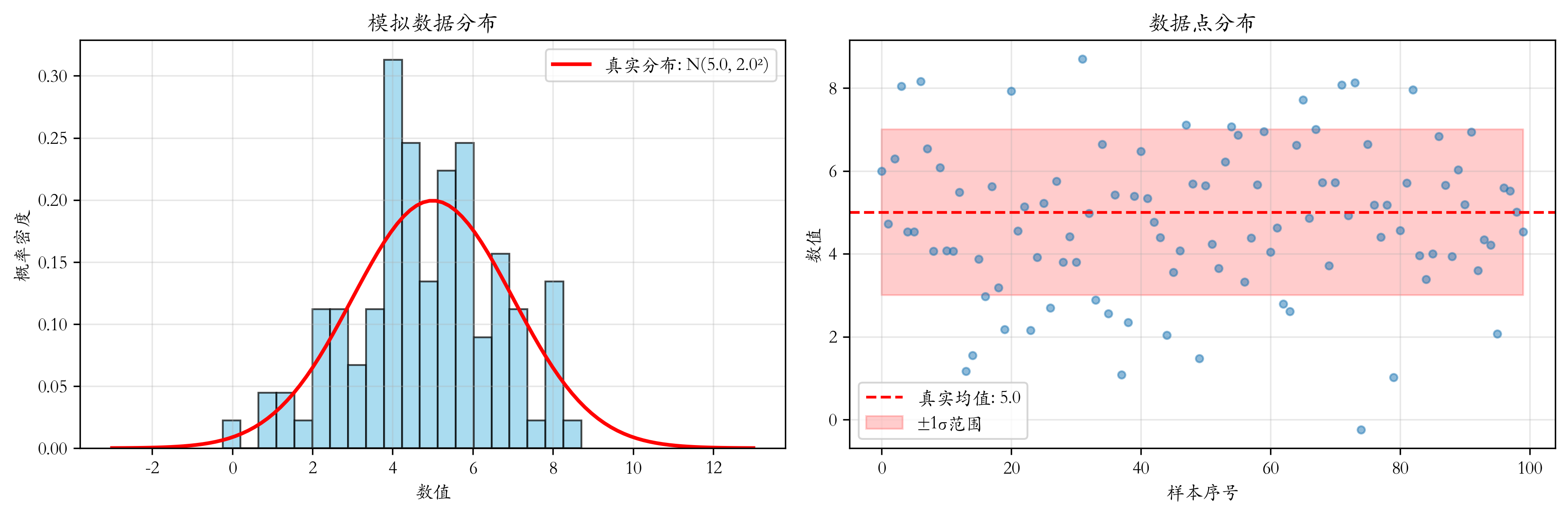
假设我们有一组观测数据 x1,x2,…,xnx_1, x_2, \dots, x_nx1,x2,…,xn,来自未知的正态分布 N(μ,σ2)N(\mu, \sigma^2)N(μ,σ2)。我们不知道真实的均值 μ\muμ 和标准差 σ\sigmaσ,需要用MCMC方法估计这两个参数。
在贝叶斯推断中,我们为参数指定先验分布:
- μ∼N(0,102)\mu \sim N(0, 10^2)μ∼N(0,102)
- σ∼Uniform(0,10)\sigma \sim \text{Uniform}(0, 10)σ∼Uniform(0,10)
目标是从后验分布 p(μ,σ∣x)∝p(x∣μ,σ)p(μ)p(σ)p(\mu, \sigma | x) \propto p(x | \mu, \sigma)p(\mu)p(\sigma)p(μ,σ∣x)∝p(x∣μ,σ)p(μ)p(σ) 中采样,其中似然函数为:
p(x∣μ,σ)=∏i=1nN(xi∣μ,σ2) p(x | \mu, \sigma) = \prod_{i=1}^n N(x_i | \mu, \sigma^2) p(x∣μ,σ)=i=1∏nN(xi∣μ,σ2)
使用Metropolis-Hastings算法,每次迭代包含两个步骤:
1. 更新均值 μ\muμ
- 提出新值:μ∗∼N(μt,δμ2)\mu^* \sim N(\mu_t, \delta_\mu^2)μ∗∼N(μt,δμ2)
- 计算接受概率:
αμ=min(1,p(μ∗,σt∣x)p(μt,σt∣x)) \alpha_\mu = \min\left(1, \frac{p(\mu^*, \sigma_t | x)}{p(\mu_t, \sigma_t | x)}\right) αμ=min(1,p(μt,σt∣x)p(μ∗,σt∣x))
2. 更新标准差 σ\sigmaσ(在对数空间)
-
定义 η=log(σ)\eta = \log(\sigma)η=log(σ)
-
提出新值:η∗∼N(ηt,δη2)\eta^* \sim N(\eta_t, \delta_\eta^2)η∗∼N(ηt,δη2)
-
变换回原始空间:σ∗=exp(η∗)\sigma^* = \exp(\eta^*)σ∗=exp(η∗)
-
计算接受概率(考虑雅可比行列式):
ασ=min(1,p(μt+1,σ∗∣x)⋅σ∗p(μt+1,σt∣x)⋅σt) \alpha_\sigma = \min\left(1, \frac{p(\mu_{t+1}, \sigma^* | x) \cdot \sigma^*}{p(\mu_{t+1}, \sigma_t | x) \cdot \sigma_t}\right) ασ=min(1,p(μt+1,σt∣x)⋅σtp(μt+1,σ∗∣x)⋅σ∗) -
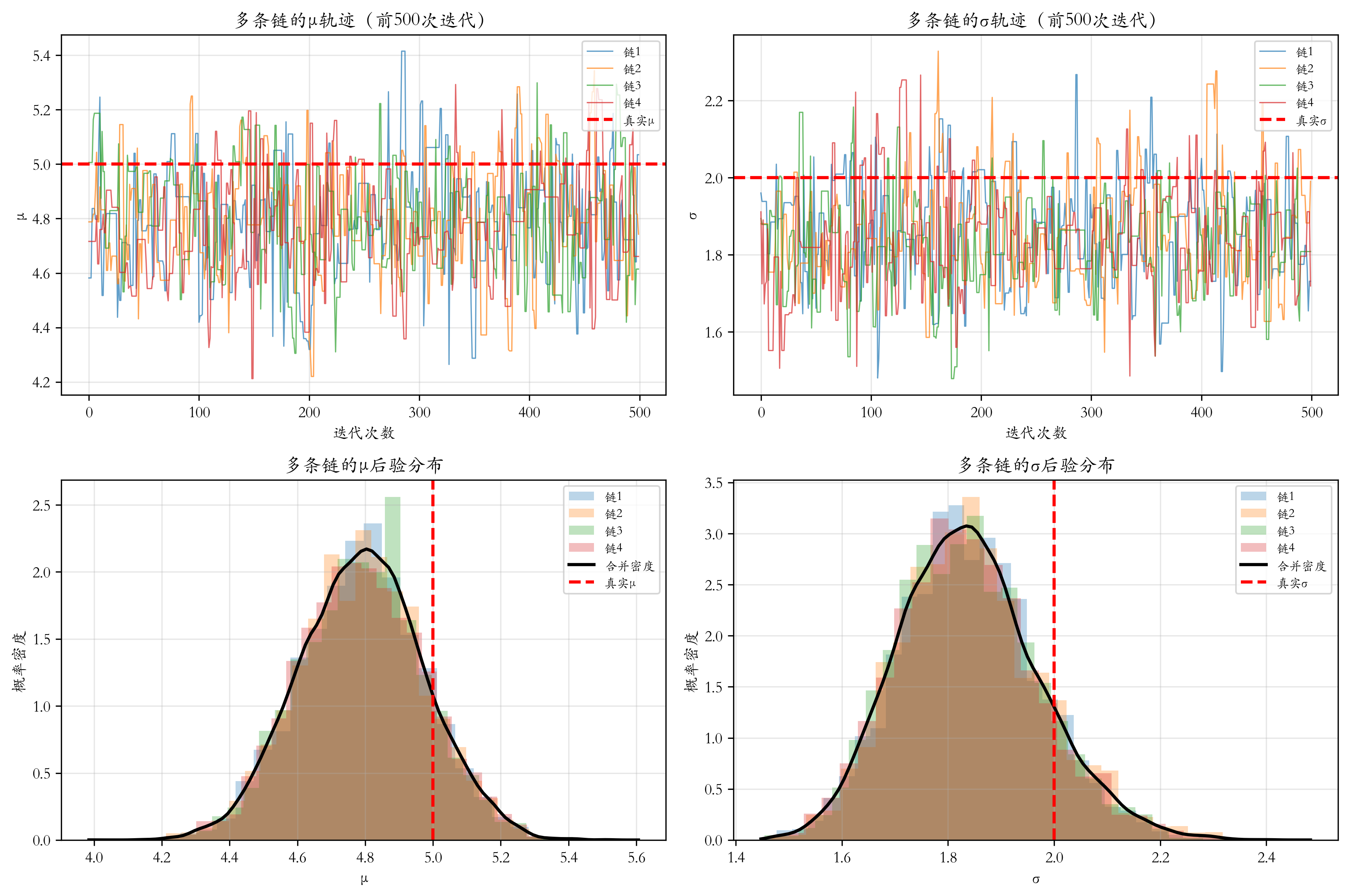
预烧期:丢弃前20-50%的样本,消除初始值影响
-
多条链:从不同初始值运行多条链,比较结果的一致性
-
Gelman-Rubin统计量:比较链内和链间方差,R^≈1\hat{R} \approx 1R^≈1 表示收敛
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import warnings
import os # 新增:导入os模块用于文件/目录操作
warnings.filterwarnings('ignore')
# ==================== 新增:创建图片保存目录 ====================
save_dir = './mcmc_plots' # 图片保存路径
if not os.path.exists(save_dir):
os.makedirs(save_dir) # 目录不存在则自动创建
print(f"已创建图片保存目录:{save_dir}")
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Kaiti SC']
plt.rcParams['axes.unicode_minus'] = False
# ==================== 1. 生成模拟数据 ====================
np.random.seed(42)
true_mu = 5.0 # 真实均值
true_sigma = 2.0 # 真实标准差
n_samples = 100 # 样本数
# 生成来自正态分布的数据
data = np.random.normal(true_mu, true_sigma, n_samples)
# 可视化生成的数据
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 直方图
axes[0].hist(data, bins=20, density=True, alpha=0.7, color='skyblue', edgecolor='black')
x_range = np.linspace(true_mu - 4 * true_sigma, true_mu + 4 * true_sigma, 100)
axes[0].plot(x_range, stats.norm.pdf(x_range, true_mu, true_sigma),
'r-', linewidth=2, label=f'真实分布: N({true_mu}, {true_sigma}²)')
axes[0].set_xlabel('数值')
axes[0].set_ylabel('概率密度')
axes[0].set_title('模拟数据分布')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 数据点图
axes[1].plot(range(len(data)), data, 'o', alpha=0.5, markersize=4)
axes[1].axhline(y=true_mu, color='r', linestyle='--', label=f'真实均值: {true_mu}')
axes[1].fill_between(range(len(data)), true_mu - true_sigma, true_mu + true_sigma,
alpha=0.2, color='red', label=f'±1σ范围')
axes[1].set_xlabel('样本序号')
axes[1].set_ylabel('数值')
axes[1].set_title('数据点分布')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
# ==================== 新增:保存第一张图 ====================
plt.savefig(os.path.join(save_dir, '模拟数据分布.png'), dpi=300, bbox_inches='tight')
plt.show()
# ==================== 2. 定义目标分布 ====================
def log_posterior(mu, sigma, data):
"""计算对数后验概率(忽略常数)"""
# 检查参数有效性
if sigma <= 0:
return -np.inf
# 先验分布
# μ的先验:N(0, 10),σ的先验:Uniform(0, 10)
log_prior_mu = stats.norm.logpdf(mu, 0, 10) # N(0, 10)
log_prior_sigma = 0 # Uniform(0, 10)的密度是常数,忽略
# 如果σ超出(0, 10)范围,返回负无穷
if sigma <= 0 or sigma >= 10:
return -np.inf
# 似然函数
log_likelihood = np.sum(stats.norm.logpdf(data, mu, sigma))
return log_prior_mu + log_prior_sigma + log_likelihood
# ==================== 3. Metropolis-Hastings算法实现 ====================
def metropolis_hastings(data, n_iterations=10000,
mu_init=0.0, sigma_init=1.0,
mu_step=0.5, sigma_step=0.3):
"""运行Metropolis-Hastings算法"""
# 初始化
mu_current = mu_init
sigma_current = sigma_init
log_p_current = log_posterior(mu_current, sigma_current, data)
# 存储结果
mu_samples = np.zeros(n_iterations)
sigma_samples = np.zeros(n_iterations)
accept_mu = 0
accept_sigma = 0
for i in range(n_iterations):
# 存储当前值
mu_samples[i] = mu_current
sigma_samples[i] = sigma_current
# 更新μ
mu_proposed = np.random.normal(mu_current, mu_step)
log_p_proposed = log_posterior(mu_proposed, sigma_current, data)
# 计算接受概率
log_alpha = log_p_proposed - log_p_current
if np.log(np.random.random()) < log_alpha:
mu_current = mu_proposed
log_p_current = log_p_proposed
accept_mu += 1
# 再次计算当前的对数概率
log_p_current = log_posterior(mu_current, sigma_current, data)
# 更新σ
# 注意:σ必须为正,我们在对数空间提出建议
log_sigma_current = np.log(sigma_current)
log_sigma_proposed = np.random.normal(log_sigma_current, sigma_step)
sigma_proposed = np.exp(log_sigma_proposed)
log_p_proposed = log_posterior(mu_current, sigma_proposed, data)
# 计算接受概率(考虑对数变换的雅可比行列式)
# 变换后的密度:p(μ, logσ|data) = p(μ, σ|data) * σ
# 所以比较的是 p(μ, σ|data) * σ
log_alpha = (log_p_proposed + np.log(sigma_proposed)) - \
(log_p_current + np.log(sigma_current))
if np.log(np.random.random()) < log_alpha:
sigma_current = sigma_proposed
log_p_current = log_p_proposed
accept_sigma += 1
# 再次计算当前的对数概率
log_p_current = log_posterior(mu_current, sigma_current, data)
# 计算接受率
acceptance_rate_mu = accept_mu / n_iterations
acceptance_rate_sigma = accept_sigma / n_iterations
return mu_samples, sigma_samples, acceptance_rate_mu, acceptance_rate_sigma
# ==================== 4. 运行MCMC ====================
print("开始运行MCMC...")
mu_samples, sigma_samples, acc_rate_mu, acc_rate_sigma = metropolis_hastings(
data, n_iterations=20000, mu_init=0.0, sigma_init=1.0,
mu_step=0.5, sigma_step=0.2
)
print(f"μ的接受率: {acc_rate_mu:.3f}")
print(f"σ的接受率: {acc_rate_sigma:.3f}")
print("理想接受率应在0.2-0.5之间")
# 去除预烧期 (burn-in)
burn_in = 5000
mu_samples_burned = mu_samples[burn_in:]
sigma_samples_burned = sigma_samples[burn_in:]
# 计算后验估计
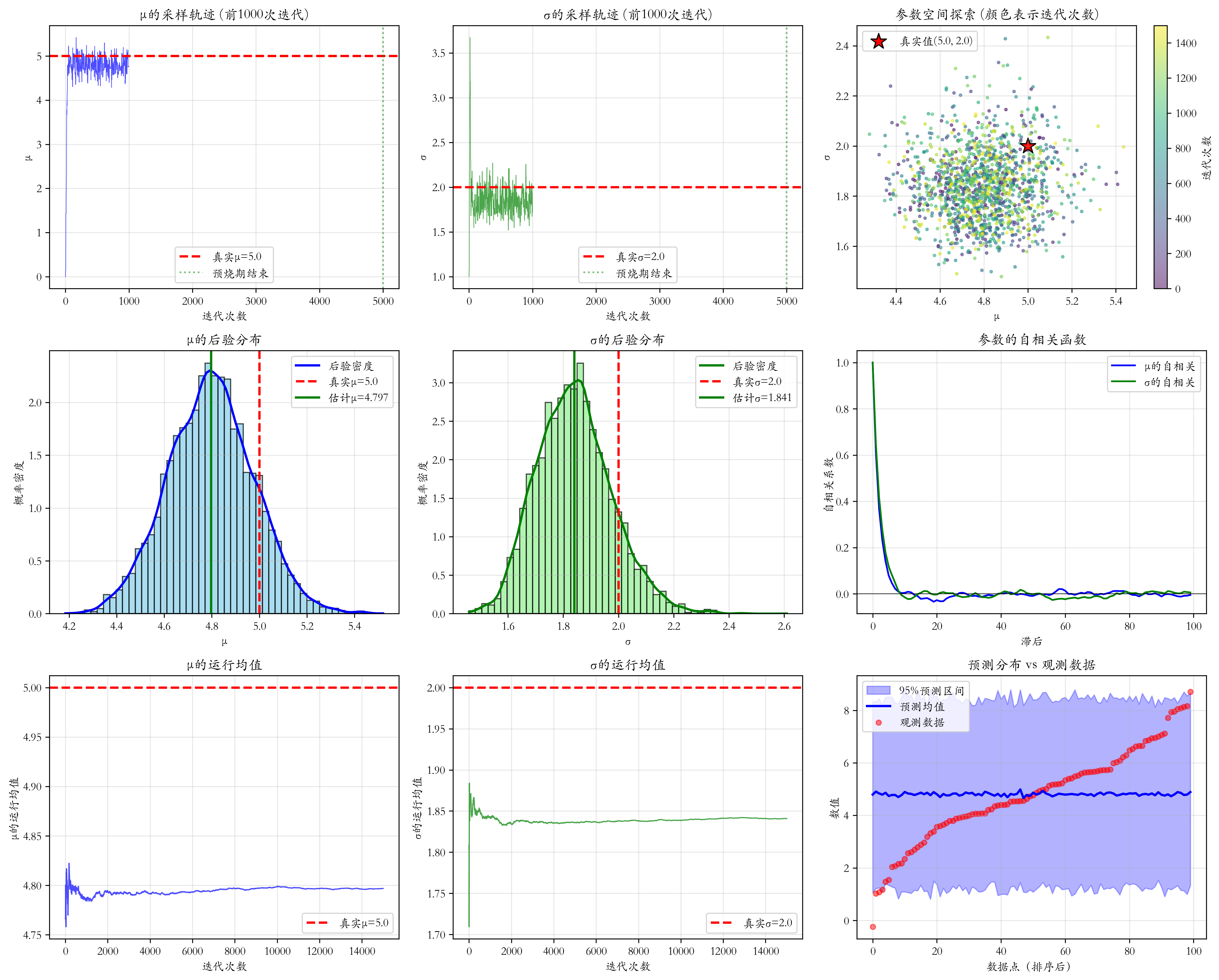
mu_est = np.mean(mu_samples_burned)
sigma_est = np.mean(sigma_samples_burned)
mu_std = np.std(mu_samples_burned)
sigma_std = np.std(sigma_samples_burned)
print(f"\n参数估计结果:")
print(f" 均值μ: {mu_est:.4f} ± {mu_std:.4f} (真实: {true_mu})")
print(f" 标准差σ: {sigma_est:.4f} ± {sigma_std:.4f} (真实: {true_sigma})")
# 与最大似然估计比较
ml_mu = np.mean(data)
ml_sigma = np.std(data, ddof=1) # 样本标准差
print(f"\n估计方法比较:")
print(f" 最大似然估计:")
print(f" μ = {ml_mu:.4f}")
print(f" σ = {ml_sigma:.4f}")
print(f" MCMC后验均值:")
print(f" μ = {mu_est:.4f}")
print(f" σ = {sigma_est:.4f}")
# ==================== 5. 可视化结果 ====================
fig, axes = plt.subplots(3, 3, figsize=(15, 12))
# 1. 参数轨迹图
ax = axes[0, 0]
ax.plot(mu_samples[:1000], 'b-', alpha=0.7, linewidth=0.5)
ax.axhline(y=true_mu, color='r', linestyle='--', linewidth=2, label=f'真实μ={true_mu}')
ax.axvline(x=burn_in, color='g', linestyle=':', alpha=0.5, label='预烧期结束')
ax.set_xlabel('迭代次数')
ax.set_ylabel('μ')
ax.set_title('μ的采样轨迹 (前1000次迭代)')
ax.legend()
ax.grid(True, alpha=0.3)
ax = axes[0, 1]
ax.plot(sigma_samples[:1000], 'g-', alpha=0.7, linewidth=0.5)
ax.axhline(y=true_sigma, color='r', linestyle='--', linewidth=2, label=f'真实σ={true_sigma}')
ax.axvline(x=burn_in, color='g', linestyle=':', alpha=0.5, label='预烧期结束')
ax.set_xlabel('迭代次数')
ax.set_ylabel('σ')
ax.set_title('σ的采样轨迹 (前1000次迭代)')
ax.legend()
ax.grid(True, alpha=0.3)
# 2. 参数空间探索
ax = axes[0, 2]
# 绘制散点图,颜色表示迭代次数
sc = ax.scatter(mu_samples_burned[::10], sigma_samples_burned[::10],
c=np.arange(len(mu_samples_burned[::10])),
cmap='viridis', alpha=0.5, s=5)
ax.scatter(true_mu, true_sigma, s=200, marker='*', color='red',
label=f'真实值({true_mu}, {true_sigma})', edgecolor='black')
ax.set_xlabel('μ')
ax.set_ylabel('σ')
ax.set_title('参数空间探索 (颜色表示迭代次数)')
ax.legend()
ax.grid(True, alpha=0.3)
plt.colorbar(sc, ax=ax, label='迭代次数')
# 3. 后验分布直方图
ax = axes[1, 0]
ax.hist(mu_samples_burned, bins=50, density=True, alpha=0.7, color='skyblue', edgecolor='black')
x_range = np.linspace(np.min(mu_samples_burned), np.max(mu_samples_burned), 100)
# 用核密度估计拟合
kde = stats.gaussian_kde(mu_samples_burned)
ax.plot(x_range, kde(x_range), 'b-', linewidth=2, label='后验密度')
ax.axvline(x=true_mu, color='r', linestyle='--', linewidth=2, label=f'真实μ={true_mu}')
ax.axvline(x=mu_est, color='g', linestyle='-', linewidth=2, label=f'估计μ={mu_est:.3f}')
ax.set_xlabel('μ')
ax.set_ylabel('概率密度')
ax.set_title('μ的后验分布')
ax.legend()
ax.grid(True, alpha=0.3)
ax = axes[1, 1]
ax.hist(sigma_samples_burned, bins=50, density=True, alpha=0.7, color='lightgreen', edgecolor='black')
x_range = np.linspace(np.min(sigma_samples_burned), np.max(sigma_samples_burned), 100)
kde = stats.gaussian_kde(sigma_samples_burned)
ax.plot(x_range, kde(x_range), 'g-', linewidth=2, label='后验密度')
ax.axvline(x=true_sigma, color='r', linestyle='--', linewidth=2, label=f'真实σ={true_sigma}')
ax.axvline(x=sigma_est, color='g', linestyle='-', linewidth=2, label=f'估计σ={sigma_est:.3f}')
ax.set_xlabel('σ')
ax.set_ylabel('概率密度')
ax.set_title('σ的后验分布')
ax.legend()
ax.grid(True, alpha=0.3)
# 4. 自相关图
ax = axes[1, 2]
max_lag = 100
acf_mu = np.correlate(mu_samples_burned - np.mean(mu_samples_burned),
mu_samples_burned - np.mean(mu_samples_burned), mode='full')
acf_mu = acf_mu[acf_mu.size // 2:acf_mu.size // 2 + max_lag]
acf_mu = acf_mu / acf_mu[0]
acf_sigma = np.correlate(sigma_samples_burned - np.mean(sigma_samples_burned),
sigma_samples_burned - np.mean(sigma_samples_burned), mode='full')
acf_sigma = acf_sigma[acf_sigma.size // 2:acf_sigma.size // 2 + max_lag]
acf_sigma = acf_sigma / acf_sigma[0]
lags = np.arange(max_lag)
ax.plot(lags, acf_mu, 'b-', label='μ的自相关')
ax.plot(lags, acf_sigma, 'g-', label='σ的自相关')
ax.axhline(y=0, color='k', linestyle='-', linewidth=0.5)
ax.set_xlabel('滞后')
ax.set_ylabel('自相关系数')
ax.set_title('参数的自相关函数')
ax.legend()
ax.grid(True, alpha=0.3)
# 5. 运行均值
ax = axes[2, 0]
running_mean_mu = np.cumsum(mu_samples_burned) / (np.arange(len(mu_samples_burned)) + 1)
ax.plot(running_mean_mu, 'b-', linewidth=1, alpha=0.7)
ax.axhline(y=true_mu, color='r', linestyle='--', linewidth=2, label=f'真实μ={true_mu}')
ax.set_xlabel('迭代次数')
ax.set_ylabel('μ的运行均值')
ax.set_title('μ的运行均值')
ax.legend()
ax.grid(True, alpha=0.3)
ax = axes[2, 1]
running_mean_sigma = np.cumsum(sigma_samples_burned) / (np.arange(len(sigma_samples_burned)) + 1)
ax.plot(running_mean_sigma, 'g-', linewidth=1, alpha=0.7)
ax.axhline(y=true_sigma, color='r', linestyle='--', linewidth=2, label=f'真实σ={true_sigma}')
ax.set_xlabel('迭代次数')
ax.set_ylabel('σ的运行均值')
ax.set_title('σ的运行均值')
ax.legend()
ax.grid(True, alpha=0.3)
# 6. 预测分布
ax = axes[2, 2]
# 从后验中采样参数,生成预测分布
n_predict = 1000
predictive_samples = np.zeros((n_predict, len(data)))
for i in range(n_predict):
# 从后验中随机采样一对参数
idx = np.random.randint(len(mu_samples_burned))
mu_sample = mu_samples_burned[idx]
sigma_sample = sigma_samples_burned[idx]
# 生成预测数据
predictive_samples[i] = np.random.normal(mu_sample, sigma_sample, len(data))
# 计算预测分布的均值和置信区间
predictive_mean = np.mean(predictive_samples, axis=0)
predictive_median = np.median(predictive_samples, axis=0)
predictive_95_lower = np.percentile(predictive_samples, 2.5, axis=0)
predictive_95_upper = np.percentile(predictive_samples, 97.5, axis=0)
# 绘制预测区间
sorted_idx = np.argsort(data)
ax.fill_between(range(len(data)), predictive_95_lower[sorted_idx], predictive_95_upper[sorted_idx],
alpha=0.3, color='blue', label='95%预测区间')
ax.plot(range(len(data)), predictive_mean[sorted_idx], 'b-', linewidth=2, label='预测均值')
ax.scatter(range(len(data)), data[sorted_idx], s=20, alpha=0.5, color='red', label='观测数据')
ax.set_xlabel('数据点(排序后)')
ax.set_ylabel('数值')
ax.set_title('预测分布 vs 观测数据')
ax.legend(loc='upper left')
ax.grid(True, alpha=0.3)
plt.tight_layout()
# ==================== 新增:保存第二张图 ====================
plt.savefig(os.path.join(save_dir, 'MCMC核心结果图.png'), dpi=300, bbox_inches='tight')
plt.show()
# ==================== 6. 诊断指标计算 ====================
def effective_sample_size(samples):
"""计算有效样本量的简化版本"""
n = len(samples)
acf = np.correlate(samples - np.mean(samples),
samples - np.mean(samples), mode='full')
acf = acf[acf.size // 2:] / acf[acf.size // 2]
# 找到第一个小于0的滞后
cutoff = np.where(acf < 0)[0]
if len(cutoff) > 0:
tau = 1 + 2 * np.sum(acf[:cutoff[0]])
else:
tau = 1 + 2 * np.sum(acf[:50]) # 使用前50个滞后
return n / tau
ess_mu = effective_sample_size(mu_samples_burned)
ess_sigma = effective_sample_size(sigma_samples_burned)
print(f"\n诊断指标:")
print(f" μ的有效样本量: {ess_mu:.0f} / {len(mu_samples_burned)}")
print(f" σ的有效样本量: {ess_sigma:.0f} / {len(sigma_samples_burned)}")
print(f" μ的自相关时间: {len(mu_samples_burned) / ess_mu:.2f}")
print(f" σ的自相关时间: {len(sigma_samples_burned) / ess_sigma:.2f}")
# ==================== 7. 置信区间计算 ====================
# 计算参数的95%置信区间
mu_ci_95 = np.percentile(mu_samples_burned, [2.5, 97.5])
sigma_ci_95 = np.percentile(sigma_samples_burned, [2.5, 97.5])
print(f"\n95%置信区间:")
print(f" μ: [{mu_ci_95[0]:.4f}, {mu_ci_95[1]:.4f}]")
print(f" σ: [{sigma_ci_95[0]:.4f}, {sigma_ci_95[1]:.4f}]")
# 检查真实值是否在置信区间内
mu_in_ci = mu_ci_95[0] <= true_mu <= mu_ci_95[1]
sigma_in_ci = sigma_ci_95[0] <= true_sigma <= sigma_ci_95[1]
print(f"真实值检查:")
print(f" μ的真实值在置信区间内: {mu_in_ci}")
print(f" σ的真实值在置信区间内: {sigma_in_ci}")
# ==================== 8. 收敛性检查(简化版本) ====================
# 运行多条链
print("\n运行多条链检查收敛性...")
n_chains = 4
all_mu_samples = []
all_sigma_samples = []
for chain in range(n_chains):
mu_chain, sigma_chain, _, _ = metropolis_hastings(
data, n_iterations=10000, mu_init=np.random.randn() * 2,
sigma_init=np.random.uniform(0.5, 3), mu_step=0.5, sigma_step=0.2
)
# 去除预烧期
chain_burn_in = 2000
all_mu_samples.append(mu_chain[chain_burn_in:])
all_sigma_samples.append(sigma_chain[chain_burn_in:])
# 计算链内和链间方差
def compute_gelman_rubin_statistic(chains):
"""计算Gelman-Rubin统计量的简化版本"""
m = len(chains) # 链的数量
n = len(chains[0]) # 每条链的样本数
# 计算每条链的均值
chain_means = np.array([np.mean(chain) for chain in chains])
# 计算每条链的方差
chain_vars = np.array([np.var(chain, ddof=1) for chain in chains])
# 计算总体均值
overall_mean = np.mean(chain_means)
# 计算链间方差
B = n * np.var(chain_means, ddof=1)
# 计算链内平均方差
W = np.mean(chain_vars)
# 计算加权方差
var_hat = ((n - 1) / n) * W + (1 / n) * B
# 计算R-hat统计量
R_hat = np.sqrt(var_hat / W)
return R_hat
# 计算R-hat,避免除零错误
if len(all_mu_samples[0]) > 0 and np.std([np.mean(chain) for chain in all_mu_samples]) > 0:
mu_r_hat = compute_gelman_rubin_statistic(all_mu_samples)
else:
mu_r_hat = 1.0 # 如果方差为0,设置R-hat为1
if len(all_sigma_samples[0]) > 0 and np.std([np.mean(chain) for chain in all_sigma_samples]) > 0:
sigma_r_hat = compute_gelman_rubin_statistic(all_sigma_samples)
else:
sigma_r_hat = 1.0 # 如果方差为0,设置R-hat为1
print(f"\nGelman-Rubin诊断(R-hat):")
print(f" μ的R-hat: {mu_r_hat:.4f} (应接近1)")
print(f" σ的R-hat: {sigma_r_hat:.4f} (应接近1)")
print("注意:R-hat < 1.1通常被认为是收敛的")
# 可视化多条链
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# μ的多条链轨迹
ax = axes[0, 0]
for i, chain in enumerate(all_mu_samples):
ax.plot(chain[:500], label=f'链{i + 1}', alpha=0.7, linewidth=0.8)
ax.axhline(y=true_mu, color='r', linestyle='--', linewidth=2, label='真实μ')
ax.set_xlabel('迭代次数')
ax.set_ylabel('μ')
ax.set_title('多条链的μ轨迹(前500次迭代)')
ax.legend(loc='upper right', fontsize=8)
ax.grid(True, alpha=0.3)
# σ的多条链轨迹
ax = axes[0, 1]
for i, chain in enumerate(all_sigma_samples):
ax.plot(chain[:500], label=f'链{i + 1}', alpha=0.7, linewidth=0.8)
ax.axhline(y=true_sigma, color='r', linestyle='--', linewidth=2, label='真实σ')
ax.set_xlabel('迭代次数')
ax.set_ylabel('σ')
ax.set_title('多条链的σ轨迹(前500次迭代)')
ax.legend(loc='upper right', fontsize=8)
ax.grid(True, alpha=0.3)
# μ的多条链密度
ax = axes[1, 0]
for i, chain in enumerate(all_mu_samples):
ax.hist(chain, bins=30, alpha=0.3, density=True, label=f'链{i + 1}')
# 合并所有链
combined_mu = np.concatenate(all_mu_samples)
x_range = np.linspace(np.min(combined_mu), np.max(combined_mu), 100)
kde = stats.gaussian_kde(combined_mu)
ax.plot(x_range, kde(x_range), 'k-', linewidth=2, label='合并密度')
ax.axvline(x=true_mu, color='r', linestyle='--', linewidth=2, label='真实μ')
ax.set_xlabel('μ')
ax.set_ylabel('概率密度')
ax.set_title('多条链的μ后验分布')
ax.legend(loc='upper right', fontsize=8)
ax.grid(True, alpha=0.3)
# σ的多条链密度
ax = axes[1, 1]
for i, chain in enumerate(all_sigma_samples):
ax.hist(chain, bins=30, alpha=0.3, density=True, label=f'链{i + 1}')
# 合并所有链
combined_sigma = np.concatenate(all_sigma_samples)
x_range = np.linspace(np.min(combined_sigma), np.max(combined_sigma), 100)
kde = stats.gaussian_kde(combined_sigma)
ax.plot(x_range, kde(x_range), 'k-', linewidth=2, label='合并密度')
ax.axvline(x=true_sigma, color='r', linestyle='--', linewidth=2, label='真实σ')
ax.set_xlabel('σ')
ax.set_ylabel('概率密度')
ax.set_title('多条链的σ后验分布')
ax.legend(loc='upper right', fontsize=8)
ax.grid(True, alpha=0.3)
plt.tight_layout()
# ==================== 新增:保存第三张图 ====================
plt.savefig(os.path.join(save_dir, 'MCMC收敛性检查.png'), dpi=300, bbox_inches='tight')
plt.show()
print(f"\n所有图片已保存至:{os.path.abspath(save_dir)}")
print("\nMCMC示例完成!")
在这里插入代码片

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)