深度学习第五节 分类实战
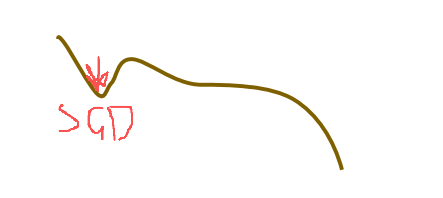
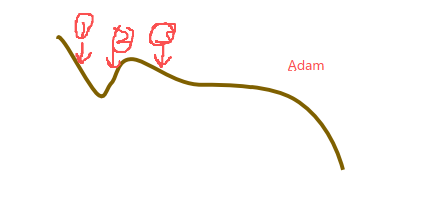
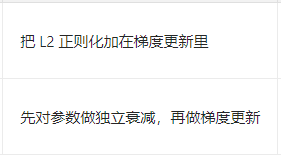
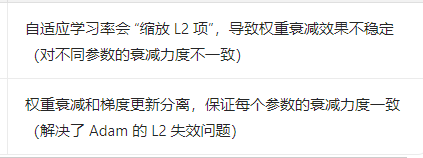
在数据或者图片少的情况下 我们可以通过数据增广来进行增加数据集这只对训练集有效 对验证集则不需要进行变换Adam和AdamW:SGD 比较直接,容易陷入局部最优。Adam 结合了过去和现在的梯度信息,在很多情况下效果会比 SGD 好。AdamW ,就是在 Adam 基础上加入了权重衰减,能更好地防止过拟合,训练效果往往更稳定。Adam(上) Adamw(下)半监督。
在数据或者图片少的情况下 我们可以通过数据增广来进行增加数据集
train_transform = transforms.Compose([
transforms.ToPILImage(), # 把numpy数组转成PIL图片(预处理必须步骤)
transforms.RandomResizedCrop(HW), # 随机裁剪到224x224(模拟不同拍摄角度)
transforms.RandomHorizontalFlip(), # 随机水平翻转(计算量小,效果好)
transforms.ToTensor(), # 转成Tensor格式(PyTorch模型只能处理Tensor)
# 归一化:用ImageNet数据集的均值和标准差(预训练模型都用这个,固定写法)
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])这只对训练集有效 对验证集则不需要进行变换
Adam和AdamW:
SGD 比较直接,容易陷入局部最优。Adam 结合了过去和现在的梯度信息,在很多情况下效果会比 SGD 好。AdamW ,就是在 Adam 基础上加入了权重衰减,能更好地防止过拟合,训练效果往往更稳定。
Adam(上) Adamw(下)
半监督
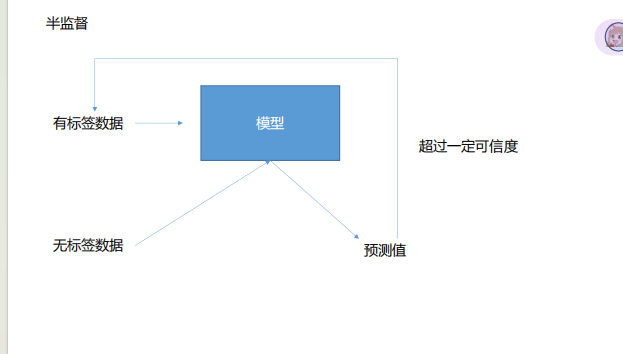
通用半监督(伪标签法)流程
- 初始训练:用少量有标签数据训练一个基础模型(先让模型具备初步分类能力)。
- 生成伪标签:用训练好的模型对无标签数据做预测,筛选高置信度的预测结果作为 “伪标签”(比如你代码里的
thres=0.99,只保留预测概率 > 0.99 的样本)。 - 合并训练:把 “有标签数据 + 高置信度伪标签数据” 合并,作为新的训练集,继续训练模型。
- 迭代优化(可选):重复步骤 2-3,用更新后的模型重新生成更精准的伪标签,逐步提升模型性能。
-
第一步:加载数据
- 有标签数据:
train_set(训练集)、val_set(验证集) - 无标签数据:
no_label_set(无标签训练集)
- 有标签数据:
-
第二步:先训练基础模型
- 用
train_loader(有标签数据)训练模型,直到验证准确率达到一定阈值(你代码里是plt_val_acc[-1] > 0.6)。
- 用
-
第三步:生成伪标签
- 每 3 个 epoch(
epoch % 3 == 0),调用get_semi_loader:- 用当前模型预测
no_label_loader(无标签数据); - 用
Softmax转概率,筛选prob > thres的样本,生成semiset(伪标签数据集)。
- 用当前模型预测
- 每 3 个 epoch(
-
第四步:合并训练
- 把
semiset对应的sem_loader加入训练,和有标签数据一起更新模型参数。
- 把
-
循环迭代:重复 “训练→生成伪标签→合并训练”,直到训练结束。
伪标签法的关键注意点
- 置信度阈值要高:避免低置信度的伪标签 “污染” 训练;
- 模型先有基础性能:必须等模型在有标签数据上训练到一定准确率(比如 > 60%),再生成伪标签,否则伪标签错误率太高;
- 避免数据泄露:无标签数据不能和验证集重叠,否则模型会 “作弊”。
import random
import numpy as np
import os
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
import torch # PyTorch核心库,用于张量计算和模型构建
import torch.nn as nn
from PIL import Image # 用于读取和处理图片数据
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm # 进度条显示
from torchvision import transforms # 图片预处理工具(裁剪、旋转、转张量等)
import time # 用于计算训练耗时
import matplotlib.pyplot as plt
from model_utils.model import initialize_model # 导入预训练模型初始化函数(resnet18)
def seed_everything(seed):
# PyTorch CPU随机种子
torch.manual_seed(seed)
# PyTorch单个GPU随机种子
torch.cuda.manual_seed(seed)
# PyTorch多个GPU随机种子
torch.cuda.manual_seed_all(seed)
# 禁用cudnn的benchmark模式(避免自动优化导致结果不一致)
torch.backends.cudnn.benchmark = False
# 启用cudnn的确定性模式(保证相同输入得到相同输出)
torch.backends.cudnn.deterministic = True
# Python原生随机种子
random.seed(seed)
# NumPy随机种子
np.random.seed(seed)
# Python哈希种子(影响字典等结构的随机性)
os.environ['PYTHONHASHSEED'] = str(seed)
# 固定随机种子为0,后续每次运行代码结果都一致
seed_everything(0)
HW = 224
# 训练集图片预处理(数据增强:提升模型泛化能力,避免过拟合)
train_transform = transforms.Compose(
[
transforms.ToPILImage(), # 将NumPy数组转为PIL图片(后续预处理需要PIL格式)
transforms.RandomResizedCrop(224), # 随机裁剪后缩放为224x224(模拟不同拍摄角度)
transforms.RandomRotation(50), # 随机旋转(-50°到50°之间)
transforms.ToTensor() # 转为PyTorch张量(格式:[C, H, W],值从0-255归一化到0-1)
]
)
# 验证集图片预处理(无数据增强,仅做必要转换,保证评估真实)
val_transform = transforms.Compose(
[
transforms.ToPILImage(), # NumPy数组转PIL图片
transforms.ToTensor() # 转张量(无裁剪/旋转,保持原始缩放后的尺寸)
]
)
class food_Dataset(Dataset):
"""
自定义数据集类(继承PyTorch的Dataset),用于读取食物分类数据集
支持三种模式:train(有标签训练集)、val(有标签验证集)、semi(无标签数据集)
"""
def __init__(self, path, mode="train"):
"""
初始化数据集
path: 数据集文件夹路径
mode: 模式(train/val/semi)
"""
self.mode = mode # 保存模式
if mode == "semi":
# 无标签模式:只读取图片,不读取标签
self.X = self.read_file(path)
else:
# 有标签模式:读取图片(X)和对应标签(Y)
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) # 标签转为长整数型(PyTorch分类任务要求)
# 根据模式选择预处理方式
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path):
"""
读取文件夹中的图片数据和标签(核心读取逻辑)
return: 图片数组(X)和标签数组(Y,semi模式仅返回X)
"""
if self.mode == "semi":
# 无标签模式:文件夹下直接是图片文件(无子文件夹)
file_list = os.listdir(path) # 获取所有图片文件名
# 初始化存储图片的数组:[样本数, 高度, 宽度, 通道数](uint8:0-255像素值)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
# 遍历所有图片,读取并缩放
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name) # 拼接图片完整路径
img = Image.open(img_path) # 打开图片
img = img.resize((HW, HW)) # 缩放为224x224
xi[j, ...] = img # 存入数组(...表示其余维度全选)
print("读到了%d个无标签数据" % len(xi))
return xi
else:
# 有标签模式:文件夹下有子文件夹(子文件夹名是类别编号:00-10,共11类)
# tqdm用于显示读取进度条
for i in tqdm(range(11), desc="读取有标签数据"):
file_dir = path + "/%02d" % i # 子文件夹路径(00, 01, ..., 10)
file_list = os.listdir(file_dir) # 获取当前类别下所有图片名
# 初始化当前类别的图片和标签数组
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
yi = np.zeros(len(file_list), dtype=np.uint8) # 标签全为当前类别i
# 读取当前类别的所有图片
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name) # 图片完整路径
img = Image.open(img_path) # 打开图片
img = img.resize((HW, HW)) # 缩放为224x224
xi[j, ...] = img # 存入图片数组
yi[j] = i # 存入标签(当前类别i)
# 合并所有类别的数据(i=0时初始化,i>0时拼接)
if i == 0:
X = xi # 首次初始化总图片数组
Y = yi # 首次初始化总标签数组
else:
X = np.concatenate((X, xi), axis=0) # 纵向拼接图片(增加样本数)
Y = np.concatenate((Y, yi), axis=0) # 纵向拼接标签
print("读到了%d个有标签数据" % len(Y))
return X, Y
def __getitem__(self, item):
"""
按索引获取单个样本(DataLoader会调用此方法批量取数据)
item: 样本索引
return: 预处理后的图片张量 + 标签(semi模式返回原始图片用于后续标注)
"""
if self.mode == "semi":
# 无标签模式:返回预处理后的图片 + 原始图片(后续半监督时用原始图重新预处理)
return self.transform(self.X[item]), self.X[item]
else:
# 有标签模式:返回预处理后的图片 + 对应标签
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
"""返回数据集总样本数(DataLoader需要此方法确定批次数量)"""
return len(self.X)
class semiDataset(Dataset):
"""
半监督数据集类:用训练好的模型给无标签数据打"伪标签",筛选高置信度样本
高置信度样本(概率>阈值)会被当作有标签数据加入训练
"""
def __init__(self, no_label_loder, model, device, thres=0.99):
"""
初始化:给无标签数据打伪标签并筛选
thres: 置信度阈值(默认0.99,只有预测概率>0.99才保留)
"""
# 调用get_label方法,获取高置信度的伪标签数据
x, y = self.get_label(no_label_loder, model, device, thres)
if x == []:
# 没有符合阈值的样本,标记为无效
self.flag = False
else:
# 有有效样本,初始化数据集
self.flag = True
self.X = np.array(x) # 伪标签图片数组
self.Y = torch.LongTensor(y) # 伪标签(长整数型)
self.transform = train_transform # 用训练集的预处理(数据增强)
def get_label(self, no_label_loder, model, device, thres):
"""
核心方法:用模型预测无标签数据,筛选高置信度样本
:return: 高置信度样本的图片(x)和伪标签(y)
"""
model = model.to(device) # 把模型移到指定设备
pred_prob = [] # 存储每个样本的最大预测概率
labels = [] # 存储每个样本的预测类别(伪标签)
x = [] # 存储高置信度样本的图片
y = [] # 存储高置信度样本的伪标签
soft = nn.Softmax(dim=1) # Softmax函数(将模型输出转为概率,dim=1表示按类别维度)
# 禁用梯度计算(仅预测,不训练,节省内存和时间)
with torch.no_grad():
# 遍历无标签数据
for bat_x, _ in no_label_loder:
bat_x = bat_x.to(device) # 数据移到设备
pred = model(bat_x) # 模型预测(输出11个类别的得分)
pred_soft = soft(pred) # 得分转为概率(总和=1)
# 获取每个样本的最大概率和对应类别
pred_max, pred_value = pred_soft.max(1) # max(1)按行取最大(每个样本)
# 存入列表(需转回CPU和NumPy格式,避免GPU内存占用)
pred_prob.extend(pred_max.cpu().numpy().tolist())
labels.extend(pred_value.cpu().numpy().tolist())
# 筛选高置信度样本(概率>阈值)
for index, prob in enumerate(pred_prob):
if prob > thres:
# 取出原始无标签数据的图片(_对应的是原始图片,见food_Dataset的__getitem__)
x.append(no_label_loder.dataset[index][1])
y.append(labels[index]) # 存入对应的伪标签
print(f"筛选出{len(x)}个高置信度伪标签样本(置信度>={thres})")
return x, y
def __getitem__(self, item):
"""按索引获取伪标签样本(预处理后图片+伪标签)"""
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
"""返回伪标签数据集样本数"""
return len(self.X)
def get_semi_loader(no_label_loder, model, device, thres):
"""
生成伪标签数据的DataLoader(批量加载伪标签数据)
:return: 伪标签数据的DataLoader(无有效样本则返回None)
"""
semiset = semiDataset(no_label_loder, model, device, thres)
if semiset.flag == False:
print("没有符合条件的伪标签样本,不使用半监督数据")
return None
else:
# 批量大小16,不打乱(伪标签数据已筛选,打乱意义不大)
semi_loader = DataLoader(semiset, batch_size=16, shuffle=False)
return semi_loader
class myModel(nn.Module):
"""
结构:卷积层+批归一化+ReLU+池化层 → 全连接层 → 分类
输入:3x224x224(RGB图片),输出:11类得分
"""
def __init__(self, num_class):
super(myModel, self).__init__() # 调用父类构造函数
#两种写法 第一种:
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) # 64x224x224
self.bn1 = nn.BatchNorm2d(64) # 批归一化(加速训练,缓解梯度消失)
self.relu = nn.ReLU() # ReLU激活函数(引入非线性)
self.pool1 = nn.MaxPool2d(2) # 64x112x112
#第二种
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), #128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) #128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1), #256*56*56
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) #256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1), #512*28*28
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) #512*14*14
)
self.pool2 = nn.MaxPool2d(2) # 512x7x7
# 全连接层1:512*7*7=25088 → 1000维
self.fc1 = nn.Linear(25088, 1000)
self.relu2 = nn.ReLU()
# 全连接层2:1000 → 11类(输出最终分类得分)
self.fc2 = nn.Linear(1000, num_class)
def forward(self, x):
"""
前向传播(模型推理逻辑):定义数据如何通过网络层
"""
#第一种
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
#第二种
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
# 展平张量:从(batch_size, 512, 7, 7)转为(batch_size, 512*7*7)
x = x.view(x.size()[0], -1) # -1表示自动计算剩余维度
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss_func, thres, save_path):
"""
核心训练+验证函数:包含有监督训练、半监督训练、模型评估、结果可视化
thres: 伪标签置信度阈值
"""
model = model.to(device)
semi_loader = None # 伪标签数据加载器(初始为None,后续动态生成)
# 记录训练/验证的损失和准确率(用于绘图)
plt_train_loss = [] # 训练损失
plt_val_loss = [] # 验证损失
plt_train_acc = [] # 训练准确率
plt_val_acc = [] # 验证准确率
max_acc = 0.0 # 记录最佳验证准确率(用于保存最优模型)
# 遍历每个训练轮次
for epoch in range(epochs):
# 初始化本轮的损失和准确率(累加用)
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0
start_time = time.time() # 记录本轮训练开始时间
# ---------------------- 有监督训练阶段 ----------------------
model.train() # 模型设为训练模式(启用Dropout、BatchNorm更新)
# 遍历有标签训练集
for batch_x, batch_y in train_loader:
# 数据移到设备(GPU/CPU)
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 模型预测
train_bat_loss = loss_func(pred, target) # 计算批次损失
train_bat_loss.backward() # 反向传播(计算梯度)
optimizer.step() # 优化器更新模型参数
optimizer.zero_grad() # 梯度清零(避免累积,否则影响下一批次)
# 累加损失和准确率
train_loss += train_bat_loss.cpu().item() # 损失值转回CPU并累加
# 预测类别:取概率最大的索引;对比真实标签,统计正确个数
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
# 计算本轮平均训练损失和准确率(除以批次数量/样本总数)
plt_train_loss.append(train_loss / len(train_loader)) # 损失:总损失/批次数
plt_train_acc.append(train_acc / len(train_loader.dataset)) # 准确率:正确数/总样本数
# ---------------------- 半监督训练阶段(如果有伪标签数据) ----------------------
if semi_loader is not None:
# 遍历伪标签数据集
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss_func(pred, target) # 用伪标签计算损失
semi_bat_loss.backward()
optimizer.step()
optimizer.zero_grad()
# 累加伪标签数据的损失和准确率
semi_loss += semi_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
# 打印伪标签训练准确率(注意:分母是有标签训练集样本数,仅作参考)
print(f"半监督数据集训练准确率:{semi_acc / len(train_loader.dataset):.4f}")
# ---------------------- 验证阶段 ----------------------
model.eval() # 模型设为评估模式(禁用Dropout、固定BatchNorm)
with torch.no_grad(): # 禁用梯度计算(节省内存,加速推理)
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss_func(pred, target) # 计算验证损失
val_loss += val_bat_loss.cpu().item()
# 累加验证正确个数
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
# 计算本轮平均验证损失和准确率
plt_val_loss.append(val_loss / len(val_loader.dataset)) # 验证损失:总损失/验证样本数
plt_val_acc.append(val_acc / len(val_loader.dataset)) # 验证准确率:正确数/验证样本数
# ---------------------- 动态生成伪标签数据 ----------------------
# 每3个epoch,且验证准确率>0.6(模型有一定性能后),才生成伪标签
if epoch % 3 == 0 and plt_val_acc[-1] > 0.6:
print(f"\n第{epoch}轮:开始生成伪标签数据...")
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
# ---------------------- 保存最佳模型 ----------------------
if val_acc > max_acc: # 若当前验证准确率高于历史最佳
torch.save(model, save_path) # 保存整个模型
max_acc = val_acc # 更新最佳准确率
print(f"最佳模型已保存!当前最佳验证准确率:{val_acc / len(val_loader.dataset):.4f}")
# ---------------------- 打印本轮训练信息 ----------------------
print(
'[%03d/%03d] %.2f秒 | 训练损失: %.6f | 验证损失: %.6f | 训练准确率: %.6f | 验证准确率: %.6f'
% (epoch + 1, epochs, time.time() - start_time, # epoch从1开始显示
plt_train_loss[-1], plt_val_loss[-1],
plt_train_acc[-1], plt_val_acc[-1])
)
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号乱码
plt.figure(figsize=(8, 4))
plt.plot(plt_train_loss, label='训练损失')
plt.plot(plt_val_loss, label='验证损失')
plt.title("损失变化曲线")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("损失值")
plt.legend() # 显示图例
plt.show()
# 绘制准确率曲线
plt.figure(figsize=(8, 4))
plt.plot(plt_train_acc, label='训练准确率')
plt.plot(plt_val_acc, label='验证准确率')
plt.title("准确率变化曲线")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("准确率(0-1)")
plt.legend()
plt.show()
# ---------------------- 主程序:数据加载 + 模型初始化 + 训练 ----------------------
train_path = r"E:\PyCharm\ligekaoyan\深度学习基础类\Classification1\food_classification\food-11\training\labeled" # 有标签训练集
val_path = r"E:\PyCharm\ligekaoyan\深度学习基础类\Classification1\food_classification\food-11\validation" # 验证集
no_label_path = r"E:\PyCharm\ligekaoyan\深度学习基础类\Classification1\food_classification\food-11\training\unlabeled\00" # 无标签数据集
# train_path = r"E:\PyCharm\ligekaoyan\深度学习基础类\Classification1\food_classification\food-11_sample\training\labeled" # 有标签训练集
# val_path = r"E:\PyCharm\ligekaoyan\深度学习基础类\Classification1\food_classification\food-11_sample\validation" # 验证集
# no_label_path = r"E:\PyCharm\ligekaoyan\深度学习基础类\Classification1\food_classification\food-11_sample\training\unlabeled\00" # 无标签数据集
train_set = food_Dataset(train_path, "train")
val_set = food_Dataset(val_path, "val")
no_label_set = food_Dataset(no_label_path, "semi")
# 创建DataLoader(批量加载数据,支持多线程)
train_loader = DataLoader(train_set, batch_size=16, shuffle=True) #打乱数据
val_loader = DataLoader(val_set, batch_size=16, shuffle=True)
no_label_loader = DataLoader(no_label_set, batch_size=16, shuffle=False) # 无标签数据不打乱
# 初始化模型(使用ResNet18预训练模型,分类数11)
# model = myModel(11) # 若要使用自定义CNN,取消注释此行,注释下一行
model, _ = initialize_model("resnet18", 11, use_pretrained=True)
lr = 0.0001
loss_func = nn.CrossEntropyLoss() # 交叉熵损失(分类任务常用)
# 优化器:AdamW(Adam的改进版,带权重衰减,泛化性更好)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
device = "cuda" if torch.cuda.is_available() else "cpu" # 自动判断使用GPU还是CPU
save_path = "model_save/best_model.pth"
epochs = 15
thres = 0.99 # 伪标签置信度阈值
if not os.path.exists("model_save"):
os.makedirs("model_save")
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss_func, thres, save_path)半监督作用:
1. 解决 “标注成本高” 的问题
现实中,有标签数据往往很少 / 很贵(比如医疗影像、工业质检的标注需要专家),而无标签数据很容易获取(比如随便爬取的图片、日志数据)。半监督能利用这些 “免费的无标签数据”,在不增加标注成本的前提下,让模型学到更多数据的特征,性能比只用有标签数据更好。
2. 提升模型的泛化能力
有标签数据通常是 “小而局限” 的(比如只标注了某几种场景的图片),而无标签数据涵盖的场景更丰富。半监督通过学习无标签数据的 “全局分布信息”,能让模型对没见过的新样本适应能力更强(减少过拟合)。
3. 填补 “数据分布 gap”
比如你的任务是 “食物分类”:
- 有标签数据可能只有 “实验室拍摄的干净食物图”;
- 无标签数据可以是 “用户随手拍的模糊 / 光线差的食物图”。半监督能让模型学习到 “不同场景下的食物特征”,填补有标签数据和真实场景之间的分布差异。
4. 对 “弱监督任务” 的补充
比如某些任务只有 “部分标签”(比如只知道图片里有食物,但不知道具体类别),半监督可以结合无标签数据,把 “弱标签” 补全 / 优化,提升任务效果。
举个你代码的例子:如果只用有标签数据训练,模型可能只能到 70% 准确率;加上无标签数据的伪标签后,准确率能提到 80%—— 这就是半监督 “用无标签数据换性能提升” 的直接作用。
半监督学习适用于 “标签稀缺但无标签数据丰富、且数据分布一致” 的任务;
不适用于 “数据分布不一致、噪声大、任务简单或伪标签不可靠” 的场景。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)