MATLAB程序采用非支配排序遗传算法(NSGA2)求解分布式电源选址定容问题,可作为一个有用...
提供的 NSGA-II 代码严格遵循原始算法逻辑,通过模块化设计实现了“优化-可视化-决策”的完整流程,且内置配电网储能优化案例,兼具理论严谨性和工程实用性。该代码不仅可直接用于储能优化问题,还可通过修改目标函数适配各类多目标优化场景(如机械设计、路径规划、机器学习超参数调优)。开发者在使用时需重点关注决策变量定义、目标函数适配和参数调优,若涉及约束问题,建议采用“约束支配”机制替代惩罚函数,以提
MATLAB程序采用非支配排序遗传算法(NSGA2)求解分布式电源选址定容问题,可作为一个有用的参考,程序注释明确,算法原理可以自己搜。
一、引言
非支配排序遗传算法 II(NSGA-II)是多目标优化领域的经典算法,由 Kalyanmoy Deb 等人于 2002 年提出。该算法通过改进非支配排序策略、引入精英保留机制和拥挤度计算,有效解决了传统多目标进化算法计算复杂度高、缺乏精英保留、依赖人工参数等问题。本文将结合提供的 MATLAB 实现代码与原始算法文献,从代码框架、核心模块、功能特性、使用指南等方面进行全面解析,帮助开发者深入理解并灵活应用该算法。
二、代码整体框架
NSGA-II 算法的核心逻辑围绕“种群初始化-非支配排序-拥挤度计算-遗传操作-种群更新”的迭代流程展开。提供的代码严格遵循这一逻辑,采用模块化设计,各函数各司其职且协同工作。整体框架流程图如下:
graph TD
A[初始化参数] --> B[种群初始化:生成随机解]
B --> C[计算目标函数值]
C --> D[非支配排序:划分支配等级]
D --> E[计算拥挤度:维持解的多样性]
E --> F[种群排序:按等级和拥挤度排序]
F --> G[遗传操作:交叉+变异生成子代]
G --> H[合并父代与子代种群]
H --> I[重复步骤C-F:非支配排序+拥挤度计算]
I --> J[筛选种群:保留最优N个个体]
J --> K{达到最大迭代次数?}
K -- 否 --> G
K -- 是 --> L[输出非支配解(F1前沿)]代码文件结构及核心功能对应表:
| 文件名 | 核心功能 | 算法关联模块 |
|---|---|---|
nsga2.m |
主函数,控制迭代流程 | 整体框架调度 |
NonDominatedSorting.m |
非支配排序,划分支配前沿 | 快速非支配排序策略 |
CalcCrowdingDistance.m |
计算个体拥挤度 | 多样性保持机制 |
Crossover.m |
交叉操作,生成子代 | 遗传操作模块 |
Mutate.m |
变异操作,引入新基因 | 遗传操作模块 |
SortPopulation.m |
按支配等级和拥挤度排序 | 种群筛选机制 |
fun3.m |
目标函数定义(含储能优化场景) | 问题适配模块 |
Dominates.m |
判断个体间支配关系 | 非支配排序基础 |
PlotCosts.m |
可视化非支配解 | 结果展示模块 |
SQ_TOPSIS.m |
熵权 TOPSIS 决策分析 | 多目标解优选辅助 |
三、核心模块详细解析
(一)核心算法模块
1. 非支配排序模块(`NonDominatedSorting.m`)
非支配排序是 NSGA-II 的核心,用于将种群划分为不同的支配前沿(F1、F2、...),F1 为最优非支配前沿。
功能逻辑:
- 遍历种群中每对个体,判断支配关系(通过
Dominates.m函数); - 记录每个个体的“被支配计数”(
DominatedCount)和“支配集合”(DominationSet); - 被支配计数为 0 的个体进入 F1 前沿,再通过支配关系迭代生成后续前沿。
关键代码片段:
for i=1:nPop
for j=i+1:nPop
p=pop(i); q=pop(j);
if Dominates(p,q)
p.DominationSet=[p.DominationSet j]; % p支配的个体集合
q.DominatedCount=q.DominatedCount+1; % q被支配次数+1
end
if Dominates(q,p)
q.DominationSet=[q.DominationSet i];
p.DominatedCount=p.DominatedCount+1;
end
pop(i)=p; pop(j)=q;
end
if pop(i).DominatedCount==0 % 无支配个体进入F1
F{1}=[F{1} i]; pop(i).Rank=1;
end
end算法优势:计算复杂度从传统 NSGA 的 \(O(MN^3)\) 降至 \(O(MN^2)\)(M 为目标数,N 为种群规模),大幅提升效率。
2. 拥挤度计算模块(`CalcCrowdingDistance.m`)
拥挤度用于衡量同一支配前沿内个体的“拥挤程度”,值越大表示个体周围越稀疏,目的是维持解的多样性,避免解集聚集。
功能逻辑:
- 对每个支配前沿的个体,按每个目标函数值排序;
- 边界个体(目标值最大/最小)拥挤度设为无穷大(确保边界解不被淘汰);
- 中间个体的拥挤度为相邻个体在该目标上的距离归一化之和。
关键代码片段:
for j=1:nObj
[cj, so]=sort(Costs(j,:)); % 按第j个目标排序
d(so(1),j)=inf; % 边界个体拥挤度无穷大
for i=2:n-1
% 相邻个体距离归一化
d(so(i),j)=abs(cj(i+1)-cj(i-1))/abs(cj(1)-cj(end));
end
d(so(end),j)=inf;
end
pop(F{k}(i)).CrowdingDistance=sum(d(i,:)); % 总拥挤度为各目标之和核心作用:无需人工设置共享参数(如传统算法的 \(\sigma_{share}\)),实现参数无关的多样性保持。
3. 遗传操作模块
遗传操作包括交叉(Crossover.m)和变异(Mutate.m),用于生成新的子代个体,保证种群的进化能力。
- 交叉操作:采用模拟二进制交叉(SBX)变种,通过随机权重混合父代基因,生成两个子代:
matlab
function [y1, y2]=Crossover(x1,x2)
alpha=rand(size(x1)); % 随机权重
y1=alpha.x1+(1-alpha).x2;
y2=alpha.x2+(1-alpha).x1;
end - 变异操作:基于高斯变异,对部分基因添加随机扰动,避免算法陷入局部最优:
matlab
function y=Mutate(x,mu,sigma)
nVar=numel(x);
nMu=ceil(munVar); % 变异基因个数
j=randsample(nVar,nMu); % 随机选择变异基因
y=x;
y(j)=x(j)+sigma.randn(size(j)); % 高斯扰动
end
(二)问题适配与辅助模块
1. 目标函数模块(`fun3.m`)
该模块是 NSGA-II 算法的“问题接口”,用户需根据具体优化问题修改。提供的代码适配配电网储能优化场景,定义了双目标优化问题:
- 目标 1:电压偏差指数(VDI)最小化(提升电压稳定性);
- 目标 2:储能系统总成本(投资+运行维护)最小化。
核心特性:
- 包含储能运行约束(充放电功率、荷电状态 SOC 范围);
- 结合潮流计算(
runpf)模拟配电网运行状态; - 支持多储能节点接入优化。
2. 结果可视化与分析模块
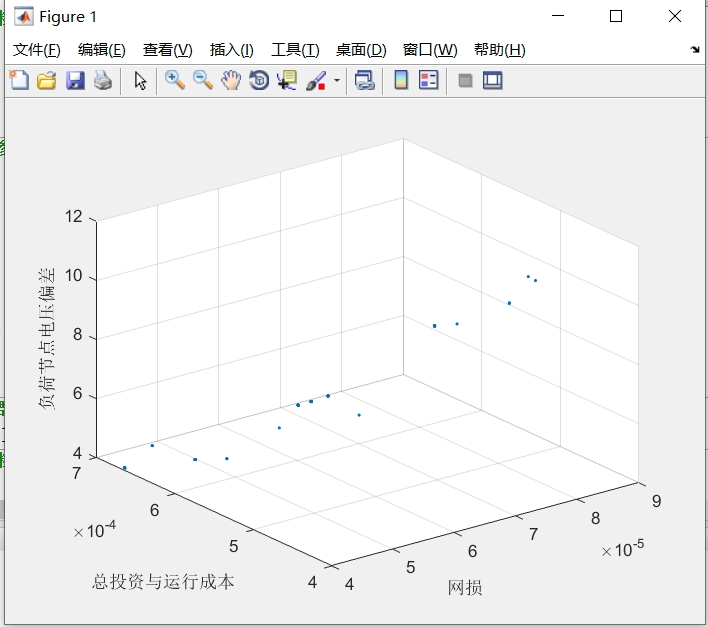
PlotCosts.m:绘制非支配前沿(F1)的目标空间分布,直观展示解的多样性和收敛性;SQ_TOPSIS.m:基于熵权 TOPSIS 方法对非支配解进行排序,辅助决策者选择最优折中解。
四、代码核心优势
(一)严格遵循 NSGA-II 原始算法设计
代码完全复现了文献中的核心创新点:
- 快速非支配排序:复杂度 \(O(MN^2)\),适配大规模种群;
- 精英保留机制:合并父代与子代种群后筛选最优个体,避免优质解丢失;
- 参数无关的多样性保持:通过拥挤度替代共享函数,无需人工调参;
- 约束处理能力:可通过修改支配关系定义(如文献中“约束支配”)适配带约束的多目标问题。
(二)模块化与可扩展性强
- 核心算法模块(排序、拥挤度计算)与问题适配模块(目标函数)分离,用户只需修改
fun3.m即可适配不同场景(如工程优化、机器学习超参数调优); - 遗传操作模块支持自定义扩展(如替换为实数编码的 SBX 交叉、多项式变异)。
(三)实用性强
- 内置配电网储能优化的完整案例,包含约束处理、潮流计算等工程细节;
- 提供结果可视化和 TOPSIS 决策分析工具,从优化到决策一站式完成;
- 代码注释清晰,结构规整,便于二次开发。
五、使用说明
(一)环境依赖
- 运行环境:MATLAB R2016b 及以上版本;
- 依赖工具箱:Power System Analysis Toolbox(用于潮流计算
runpf,适配配电网场景); - 基础依赖:MATLAB 核心工具箱(随机数生成、矩阵运算等)。
(二)参数配置
在 nsga2.m 中修改核心参数,适配具体问题:
% 问题参数
nVar=50; % 决策变量个数(储能节点+24小时充放电功率)
VarMin(1:2)=2; % 决策变量下限(储能节点编号:2-32)
VarMin(3:50)=-100; % 充放电功率下限(-100kW,放电为负)
VarMax(1:2)=32; % 决策变量上限(储能节点编号)
VarMax(3:50)=100; % 充放电功率上限(100kW,充电为正)
% 算法参数
MaxIt=10; % 最大迭代次数(建议至少设为100以保证收敛)
nPop=100; % 种群规模(越大解越优,但计算量增加)
pCrossover=0.7; % 交叉概率(建议0.7-0.9)
pMutation=0.4; % 变异概率(建议0.1-0.4)
mu=0.02; % 变异基因比例(建议0.01-0.05)
sigma=0.1*(VarMax-VarMin); % 变异步长(自适应决策变量范围)(三)运行步骤
- 下载并解压所有代码文件,确保文件在同一目录下;
- 打开 MATLAB,切换到代码所在目录;
- 运行
nsga2.m主函数; - 迭代过程中会动态绘制非支配前沿,迭代结束后输出 F1 前沿的解个数及最终可视化结果。
(四)结果解读
- 输出的
F1结构体包含非支配解的所有信息:Position(决策变量值)、Cost(目标函数值); - 可视化图中,每个红点代表一个非支配解,点的分布越均匀、覆盖范围越广,说明算法性能越好;
- 若需选择单个最优解,可运行
SQ_TOPSIS.m,输入F1.Cost得到熵权加权后的排序结果。
六、注意事项与优化建议
(一)关键注意事项
- 决策变量与目标函数适配:修改
fun3.m时,需确保决策变量的维度(nVar)与目标函数计算逻辑一致; - 约束处理:当前代码在目标函数中通过惩罚机制(如 SOC 越界时成本设为 \(10^{10}\))处理约束,也可参考文献中的“约束支配”定义修改
Dominates.m,提升约束处理效率; - 参数调优:
- 种群规模nPop建议设为 100-500,迭代次数MaxIt建议 100-500;
- 变异步长sigma需根据决策变量范围调整,过大易发散,过小易陷入局部最优; - 计算效率:若目标函数计算复杂(如大规模潮流计算),可减小种群规模或迭代次数,或采用并行计算优化。
(二)扩展优化建议
- 适配多目标问题:修改
fun3.m中的目标函数定义,支持 2 个以上目标(如添加网损最小化、环保指标等); - 改进遗传操作:将
Crossover.m替换为标准 SBX 交叉,Mutate.m替换为多项式变异,提升连续空间优化性能; - 约束支配扩展:参考文献中约束处理方法,修改
Dominates.m实现约束支配逻辑:matlab
% 约束支配判断(示例)
function b=ConstrainedDominates(x,y,constraint)
% constraint(x):x的约束违反量(0为可行)
cx=constraint(x); cy=constraint(y);
if cx==0 && cy>0
b=true; % 可行解支配不可行解
elseif cx>0 && cy>0
b=cxelse
b=all(x.Cost<=y.Cost) && any(x.Costend
end - 结果后处理:结合
SQ_TOPSIS.m与层次分析法(AHP),引入决策者偏好权重,提升决策科学性。
七、总结
提供的 NSGA-II 代码严格遵循原始算法逻辑,通过模块化设计实现了“优化-可视化-决策”的完整流程,且内置配电网储能优化案例,兼具理论严谨性和工程实用性。该代码不仅可直接用于储能优化问题,还可通过修改目标函数适配各类多目标优化场景(如机械设计、路径规划、机器学习超参数调优)。
开发者在使用时需重点关注决策变量定义、目标函数适配和参数调优,若涉及约束问题,建议采用“约束支配”机制替代惩罚函数,以提升优化效率和结果可靠性。通过合理配置参数和扩展模块,该代码可满足不同复杂度的多目标优化需求,是科研和工程应用的理想工具。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)