鲁鹏教授《计算机视觉与深度学习》课程笔记与思考 ——08. 纹理表示 & 卷积神经网络:从 “人工特征” 到 “网络化提取”
本文系统梳理了从传统卷积方法到卷积神经网络(CNN)的演进过程。首先回顾了卷积的基础应用(去噪、边缘检测),指出人工设计卷积核只能提取低级特征。重点阐述了纹理表示方法,通过多类型卷积核组提取高级特征,并对比了两种统计表示方式。随后分析了全连接网络的瓶颈(参数量爆炸、空间信息丢失),引出CNN的三大核心优势:自动学习3D卷积核、参数共享机制和层次化特征提取。详细解析了CNN四层结构(卷积、激活、池化
在上一篇笔记中,我们聚焦卷积的 “基础应用”—— 通过平均滤波、高斯滤波解决图像去噪,通过 Canny 检测器实现边缘提取,这些内容本质是 “用人工设计的卷积核处理图像局部特征”。而本节课则是从 “单一特征(边缘)” 升级到 “高级特征(纹理)”,再从 “人工特征设计” 过渡到 “网络自动学习”,最终引出卷积神经网络(CNN)的核心逻辑。
本文将严格遵循视频 “回顾→纹理表示→全连接瓶颈→CNN 基础” 的讲解脉络,提炼 “易记步骤 + 直观对比 + 关键衔接”,帮你打通 “卷积→纹理→CNN” 的知识点链条,理解 “为什么 CNN 能高效处理图像”。
目录
四、卷积神经网络(CNN)基础:从 “人工核组” 到 “网络化提取”
2. 关键层解析(重点:3D 卷积核、ReLU 激活、池化作用)
六、学习感悟:“人工→自动” 的递进,才是 CNN 的核心逻辑
一、上节课核心回顾:卷积应用的 “关键承上”
本节课开篇先回顾上节课的核心知识点,这些是理解 “纹理表示” 和 “CNN” 的基础 —— 本质是 “人工卷积核的功能延伸”:
| 核心模块 | 核心目标 | 关键结论(视频重点强调) |
|---|---|---|
| 卷积基础 | 局部特征提取 | 1. 卷积 =“核与图像局部相乘累加”,工程中可忽略核翻转(对称核居多);2. 零填充是保持尺寸的核心方法 |
| 高斯滤波 | 去噪 + 避免振铃 | 1. 高斯核参数:σ 控制平滑强度,尺寸 = 2×3σ+1(经验法则);2. 可分离性(2D→2 个 1D)降低计算量 |
| Canny 边缘检测 | 精准提取连续边缘 | 四步流程:高斯一阶偏导卷积→计算梯度幅值 / 方向→非极大值抑制(边缘细化)→双阈值连接(避免断裂) |
| 卷积核的本质 | 特征模板 | 不同核提取不同特征:平均核→平滑、高斯偏导核→边缘、中值滤波→椒盐噪声 |
关键衔接:上节课的卷积核仅能提取 “边缘、平滑区域” 等低级特征,无法描述 “斑马纹、豹纹” 这类 “重复子结构组成的纹理”;而纹理表示正是 “用多类卷积核组合提取高级特征”,这一思路直接铺垫了 CNN——CNN 本质是 “让网络自动学习‘更复杂的卷积核组’”。
二、纹理表示:从 “边缘提取” 到 “高级特征描述”
纹理的本质是 “图像中重复出现的子结构(纹理基元)”,比如斑马的黑白条纹、树皮的纹路。视频中明确指出:边缘提取只能得到杂乱的线条,无法区分不同纹理,必须用 “卷积核组 + 统计信息” 实现纹理表示。
1. 边缘提取的局限:为什么需要纹理表示?
以 “斑马纹” 和 “豹纹” 为例:

- 边缘提取后,两者都会得到大量 “黑白交界的边缘”,仅看边缘图无法区分 “条纹” 和 “斑点”;
- 核心问题:边缘是 “单一局部特征”,而纹理是 “多个基元的组合规律”,需要 “多特征 + 统计规律” 描述。
2. 基于卷积核组的纹理表示(三步法,必记)
视频中提炼的核心流程,本质是 “用多类卷积核覆盖纹理基元,再用统计信息总结规律”:
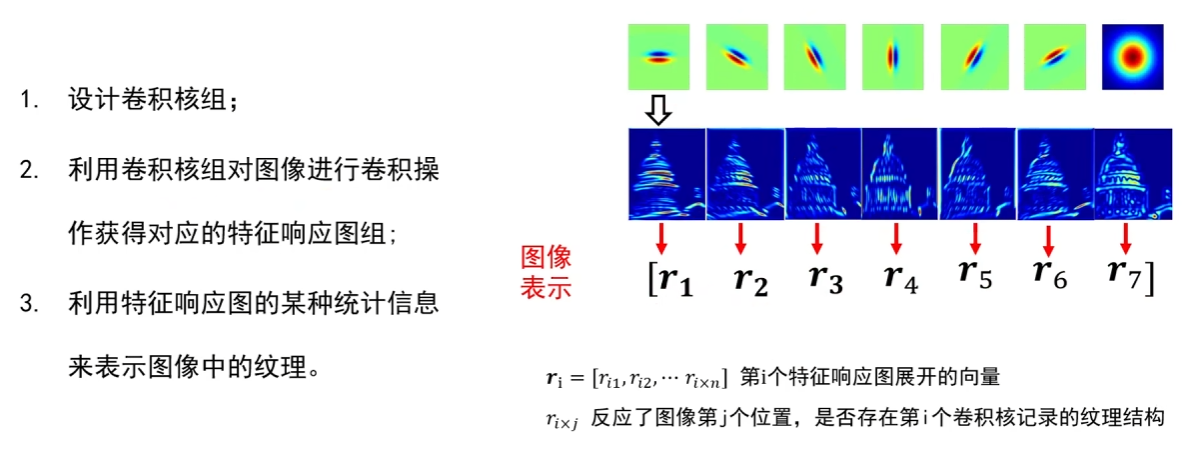
- 设计卷积核组:选择多类卷积核(如边缘核、条状核、点状核),覆盖纹理可能包含的基元(比如斑马纹需要 “水平条纹核”,豹纹需要 “斑点核”);
- 生成特征响应图:用核组中的每个核与图像卷积,得到对应 “特征响应图”—— 响应图中 “越亮的区域” 表示图像此处存在该核描述的基元(如 “水平条纹核” 的响应图亮区 = 斑马的白条纹);
- 统计信息表示纹理:对所有特征响应图做统计(如均值、展开),将高维响应图压缩为低维向量,作为纹理的最终表示(用于后续分类)。
3. 卷积核组的设计维度(4 个核心参数)
卷积核组的设计直接决定纹理表示效果,需围绕 “覆盖更多纹理基元” 展开,核心有 4 个维度:
| 设计维度 | 具体选择 | 作用说明 |
|---|---|---|
| 核类型 | 边缘核、条状核、点状核 | 边缘核(高斯偏导核)→ 检测纹理中的线条;条状核→检测条纹;点状核→检测斑点 |
| 核尺寸 | 3×3(细粒度)、7×7(粗粒度) | 尺寸小→提取细节基元(如细条纹);尺寸大→提取粗犷基元(如宽条纹) |
| 核方向 | 0°、30°、60°、90° 等 | 覆盖不同方向的基元(如斑马纹需水平核,木纹需 45° 核) |
| σ(标准差) | 1(细节)、3(粗犷) | 控制核的 “覆盖范围”:σ 小→仅关注中心像素(细节);σ 大→关注周边像素(粗犷) |
“用卷积核组表示图像” 的实例:
- 先准备一个卷积核组(图里是包含边缘、斑点等不同类型的 48 个核);
- 把输入图像和这个核组里的每个核做卷积,得到48 个特征响应图(每个图对应一种核提取的特征);
- 计算每个响应图的均值,把这 48 个均值拼成一个48 维向量—— 这个向量就可以用来代表原图像(后续能用于分类等任务)。

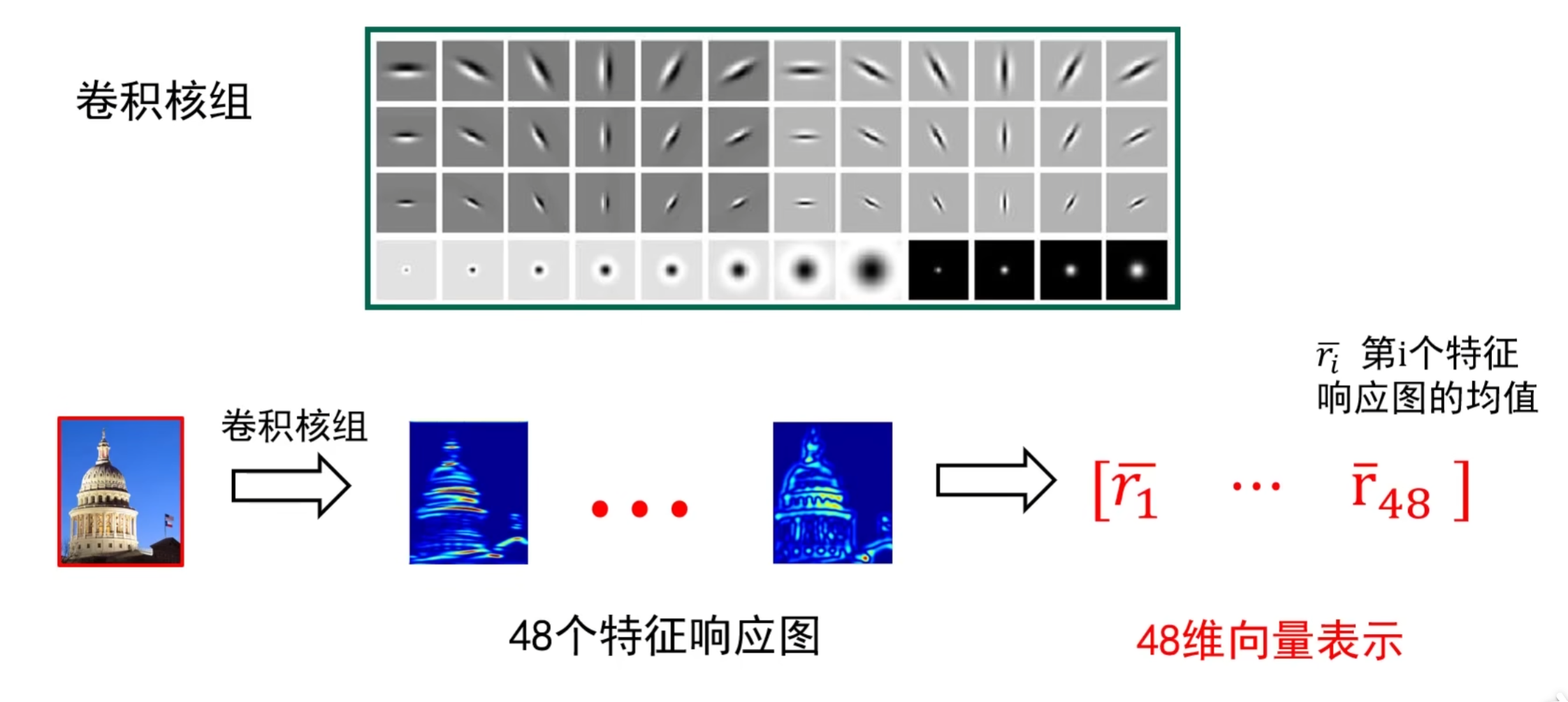
这张图里的 48 维向量是用来表示整张图像的,不是单个像素块。其中,48 维向量的每一维,对应的是 “某一个卷积核” 在整张图像上做卷积后,得到的 “特征响应图” 的均值 —— 这个均值代表 “该卷积核对应的特征,在整张图里的整体强弱程度”。
比如其中一维对应 “水平边缘核” 的响应图均值,这一维的数值大,就说明这张图里水平边缘特征比较明显。
4. 特征响应图的两种统计表示(对比记忆)
下面介绍两种主流统计方式,核心区别是 “是否保留位置信息”,适用于不同场景:
| 统计方式 | 操作逻辑 | 维度大小 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 直接展开 | 将所有响应图按行 / 列拉成 1D 向量 | 核数量 × 图像像素数(如 7×200×100=14 万维) | 保留基元位置信息 | 维度爆炸,参数冗余 | 需精准定位基元的场景 |
| 均值统计 | 计算每个响应图的像素均值 | 核数量(如 7 核→7 维) | 维度极低,计算高效 | 丢失位置信息 | 纹理分类(忽略位置) |
关键提醒: 单个像素的特征响应向量(如 48 核→48 维)是稀疏向量(大部分值为 0),因为一个像素不可能同时包含 “条纹、斑点、多方向边缘” 等多种基元,这一特性后续会用于 CNN 的参数压缩。
三、全连接神经网络的 “瓶颈”:CNN 的 “诞生必要性”
为什么要从 “纹理表示” 过渡到 CNN?视频中通过 “全连接网络的缺陷” 给出答案:全连接无法高效处理 “图像→纹理表示” 的端到端任务,存在两大致命问题。
1. 参数量爆炸:全连接的致命问题(实例计算)
全连接网络的每个神经元都与前一层所有神经元相连,参数量随输入维度呈 “指数级增长”,视频中用具体例子说明:
- 小图像(32×32×3 的 CIFAR10 图)拉成一维后是 3072 维,隐层每个神经元要配 3072 个权值;
- 稍大的图像(200×200×3)拉成一维后是 120000 维,隐层每个神经元的权值直接涨到 12 万个。
全连接网络的权值数量会随图像尺寸暴涨,因此仅适合处理小图像,处理大图像时参数量会失控—— 这就是它的瓶颈。
2. 全连接的两大缺陷(空间丢失 + 参数冗余)
- 空间信息丢失:将 2D 图像拉成 1D 向量,破坏了 “像素的邻域关系”(如 “猫耳朵” 的上下像素被拉成不相邻的向量元素),而纹理的基元组合依赖空间关系;
- 参数冗余:全连接的权重不共享,每个位置的像素都需要独立权重,但图像中 “相同基元(如条纹)” 在不同位置的特征提取逻辑一致(无需重复学习权重)。
结论:全连接仅适合 “低维、无空间关系的向量输入”(如纹理的均值表示),无法直接处理高维图像 —— 这就需要 CNN 来解决 “空间保留 + 参数共享” 的问题。
四、卷积神经网络(CNN)基础:从 “人工核组” 到 “网络化提取”
核心观点:CNN 本质是 “卷积核组的网络化升级” —— 将 “人工设计核组” 改为 “网络自动学习核组”,同时加入 “激活层、池化层” 优化特征提取,最终实现 “端到端的图像分类”。
1. CNN 的核心结构(4 层组合,对应视频内容)
CNN 的结构围绕 “高效提取特征” 设计,从输入到输出依次为:
图像输入 → 卷积层(提取特征)→ 激活层(引入非线性)→ 池化层(压缩维度)→ 全连接层(分类)

- 前三层(卷积 + 激活 + 池化):负责 “从图像中提取特征”,对应 “纹理表示的核组 + 响应图处理”;
- 全连接层:负责 “将提取的特征向量分类”,与上节课的全连接逻辑一致。
2. 关键层解析(重点:3D 卷积核、ReLU 激活、池化作用)
视频中对 CNN 各层的讲解聚焦 “与纹理表示的区别”,核心细节如下:
(1)卷积层:CNN 的 “核心”,自动学习 3D 卷积核
- 与纹理表示的核区别:纹理表示的核是 2D(单通道),CNN 的核是 3D(深度 = 输入图像的通道数,如 RGB 输入→核深度 = 3);
- 操作逻辑:每个 3D 核(如 5×5×3)与图像的局部 3D 区域(5×5×3)“逐元素相乘累加”,输出 1 个 2D 特征响应图;若有 N 个 3D 核,则输出 N 个特征响应图(对应 N 类特征);
- 核心优势:核的权重由网络 “从数据中学习”,无需人工设计 —— 比如训练 “猫分类” 时,网络会自动学习 “猫耳朵边缘核”“猫毛纹理核”,比人工核更贴合任务。

卷积网络中的卷积核 
卷积网络中的卷积操作
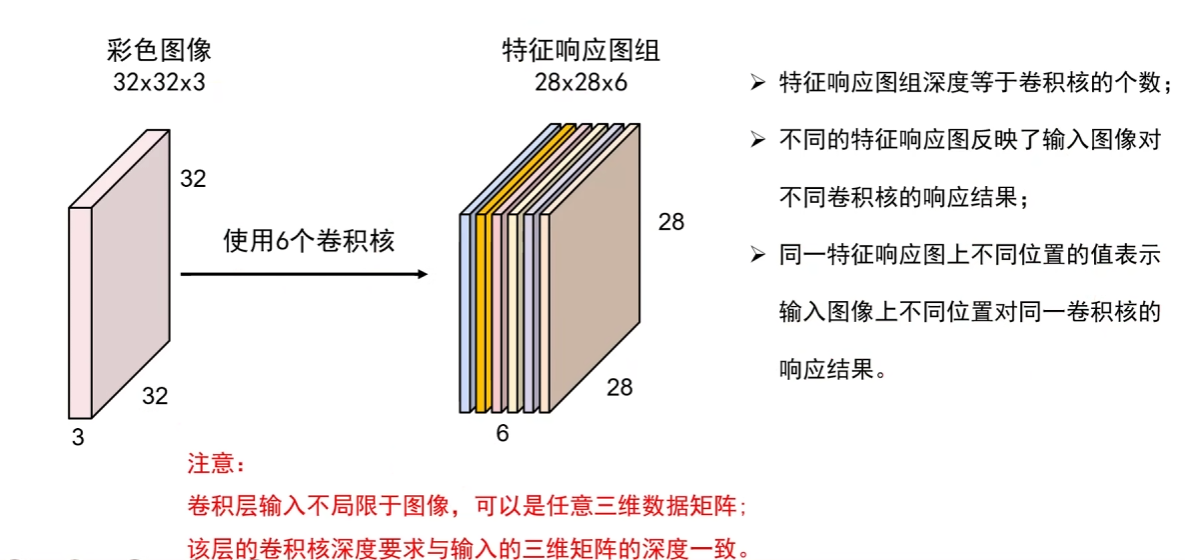
特征响应图组是卷积神经网络中卷积操作的输出结果:
- 维度逻辑:以图中为例,它是从 32×32×3 的彩色图像(宽 × 高 × 通道数),经 6 个卷积核处理后得到的 28×28×6 的结果(宽 × 高 × 卷积核数);宽高缩小是卷积核滑动计算的自然结果(比如用 5×5 卷积核时,32-5+1=28)。
- 核心含义:其深度(这里的 “6”)等于所用卷积核的个数,每个响应图对应一个卷积核,反映输入图像在该卷积核所提取特征维度上的响应(不同卷积核会捕捉图像的不同特征,比如边缘、纹理等)。
输入数据→卷积核处理→输出特征响应图组

卷积层中,输入数据经过卷积操作后,输出特征图的尺寸是如何确定的:

左侧:影响输出尺寸的 4 个因素
决定输出特征图组(W2×H2×D2)大小的关键是这 4 点:
- 卷积核自身的宽、高(对应参数 F);
- 是否做边界填充(对应参数 P,填充则 P>0);
- 卷积操作的步长(对应参数 S,即每次卷积滑动的距离);
- 这一层用了多少个卷积核(对应参数 K)。
右侧:尺寸计算公式 + 参数说明
- 输入数据的维度:
W1×H1×D1(W = 宽、H = 高、D = 深度 / 通道数); - 输出特征图的维度:
W2×H2×D2; - 具体计算:
- 输出宽度
W2 = (W1 - F + 2P) / S + 1 - 输出高度
H2 = (H1 - F + 2P) / S + 1(图里写的 “H2=(H2-F+2P)/S+1” 是笔误,应该是 H1) - 输出深度
D2 = K(输出深度 = 该层卷积核的个数);
- 输出宽度
- 4 个超参数定义:F = 卷积核尺寸、S = 卷积步长、P = 零填充数量、K = 卷积核个数(刚好对应左侧的 4 个影响因素)。
(2)激活层:引入非线性,解决 “线性分类局限”
- 视频中默认用 ReLU 激活函数:f (x) = max (0, x)(输入>0 则输出 x,否则输出 0);
- 作用:卷积层的输出是 “线性组合”,无法拟合复杂纹理的非线性关系(如 “条纹 + 斑点” 的组合),ReLU 通过 “抑制负响应” 引入非线性,让网络能学习更复杂的特征。
(3)池化层:压缩维度,减少参数冗余,控制过拟合
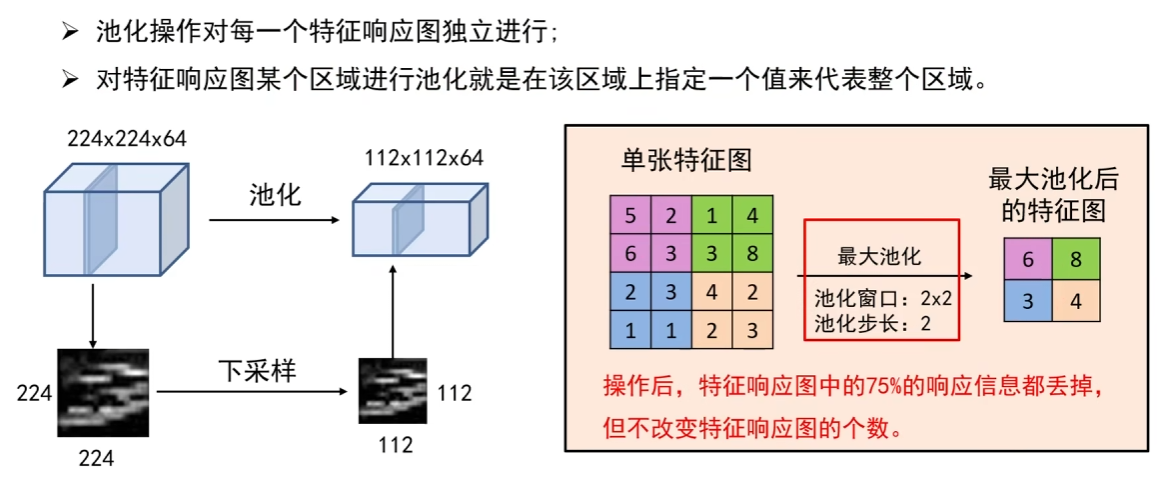
1. 池化的作用
对每个特征响应图独立执行操作,通过降低特征响应图的宽度和高度,减少后续卷积层的参数数量,节省计算资源,进而控制过拟合。
2. 池化操作的定义
对特征响应图的某个区域,选取一个值来代表整个区域。
3. 常见池化操作
- 最大池化:使用区域内的最大值代表该区域;
- 平均池化:采用区域内所有值的均值代表该区域。
4. 池化层的超参数
池化窗口、池化步长
(4)全连接层:分类收尾
- 操作:将池化后的所有特征图拉成 1D 向量,输入全连接网络;
- 作用:将 “高维特征向量” 映射到 “类别数”(如 10 类分类→输出 10 维向量,对应每类的概率)。
3. CNN 与卷积核组的核心区别(表格对比)
理解两者的区别,就能懂 “CNN 为什么更优”:
| 对比维度 | 基于卷积核组的纹理表示 | 卷积神经网络(CNN) |
|---|---|---|
| 核的来源 | 人工设计(固定) | 数据驱动学习(动态适配任务) |
| 核的复杂度 | 简单核(如 3×3 边缘核) | 复杂核(如 5×5×3 的 3D 核) |
| 特征提取层次 | 单层次(仅提取基元) | 多层次(低级→高级:边缘→纹理→物体部件) |
| 非线性能力 | 无(仅线性卷积) | 有(ReLU 激活层引入非线性) |
| 维度压缩方式 | 人工统计(如均值) | 自动池化(最大池化) |
| 适用场景 | 简单纹理分类 | 复杂图像分类(如物体、人脸) |
五、样本增强
当训练图像模型时,“过拟合” 是高频痛点 ——样本数量太少会让模型 “学窄”,只能适配训练数据,遇到新数据就 “水土不服”(这正是样本不足导致的 “泛化能力差”)。
而 样本增强 就是破解这个问题的 “低成本魔法”:从已有训练样本出发,用 “不改变核心信息的随机变换” 生成新样本,让模型训练时不会重复看到同一图像,从而学会更通用的特征,提升泛化能力。
1. 入门级几何变换:翻转增强
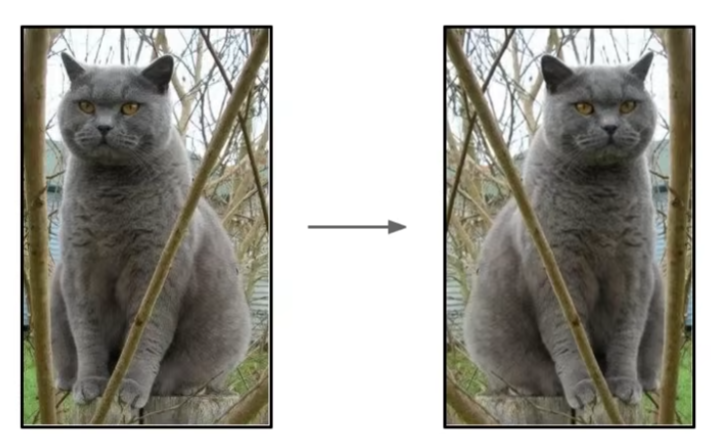
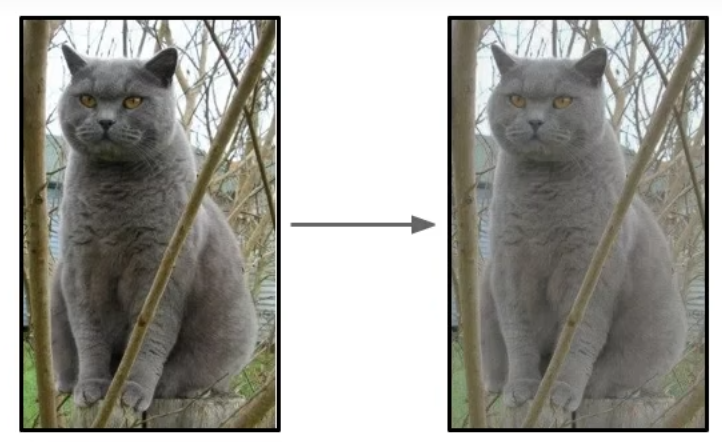
翻转是最基础的样本增强手段,通过水平 / 垂直翻转图像,在保留主体特征的前提下制造 “新样本”。
比如下图中猫咪的图像,水平翻转后,猫咪的外形、神态等核心信息未变,但对模型而言已是 “全新训练素材”,轻松扩充了样本量。
2. 空间维度的灵活变换:随机缩放 & 抠图
若想强化样本的 “空间多样性”,可以参考残差网络的随机缩放 + 抠图法,操作分训练、测试两个阶段:
-
训练阶段(随机化):
- 在 [256, 480] 中随机选一个尺寸 L;
- 将原图像缩放到 “短边 = L” 的大小;
- 从缩放后的图里随机抠取 224×224 的区域 —— 通过 “随机尺寸 + 随机区域” 组合,最大化训练样本的多样性。
-
测试阶段(稳定化):
- 将图像缩放到 5 种固定尺寸(224/256/384/480/640);
- 对每个尺寸的图及其镜像图,分别抠取 “四个角 + 中间” 的 224×224 区域,得到 10 个测试样本 —— 多区域结果取平均,能提升测试稳定性。

3. 色彩维度的多样性:色彩抖动
除了空间变换,还能在 “色彩” 维度做文章 ——色彩抖动通过微调像素色彩增加样本多样性,步骤如下:
- 用主成分分析(PCA)提取图像 RGB 通道的 “色彩主轴”(核心色彩特征方向);
- 沿主轴随机采样一个小偏移量;
- 将偏移量加到每个像素上 —— 既改变了图像色调 / 光线,又保留了主体内容,让模型 “见过同一内容的不同色彩形态”。
样本增强的形式还有许多这里就不一一列举了,其核心逻辑是:在不破坏图像核心信息的前提下,给模型展示 “同一内容的不同形态”,既解决了样本不足的问题,又帮模型练出了更强的 “泛化能力”。
六、学习感悟:“人工→自动” 的递进,才是 CNN 的核心逻辑
- 纹理表示是 CNN 的 “入门钥匙”:视频中反复强调 “先懂纹理表示,再学 CNN”—— 因为纹理表示的 “核组提取基元 + 统计表示”,与 CNN 的 “卷积层提取特征 + 池化层压缩” 逻辑完全一致,只是 CNN 把 “人工步骤” 改成了 “网络自动完成”;
- 参数共享是 CNN 的 “效率密码”:全连接的参数量爆炸,根源是 “每个像素独立权重”,而 CNN 的 “同一卷积核在全图滑动(权重共享)”,让参数量从 “千万级” 降到 “百万级”,这是 CNN 能处理大图像的核心;
- 特征层次化是 CNN 的 “识别关键”:纹理表示仅提取 “单一基元”,而 CNN 通过 “多卷积层堆叠”,能实现 “低级特征(边缘)→中级特征(纹理)→高级特征(猫耳朵)” 的递进,最终让网络 “看懂” 物体,这也是人类识别图像的逻辑。
七、结语
本节课从 “纹理表示” 切入,本质是完成了 “从人工特征设计到网络自动学习” 的过渡 —— 纹理表示证明 “多核组合能提取高级特征”,全连接的瓶颈证明 “需要新网络结构”,而 CNN 正是这两者的结合体。
下一篇笔记将深入 CNN 的 “经典架构(如 LeNet、AlexNet)”,拆解 “如何通过层堆叠实现更优的特征提取”,同时讲解 “CNN 的训练细节(如权重初始化、正则化)”。如果对 “3D 卷积核的操作逻辑”“池化层的参数选择” 有疑问,欢迎在评论区交流 —— 理解 CNN 的层间协作,才能真正掌握其核心能力。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)