Pytorch可视化(四)之训练过程可视化TensorBoard
当我们的实验变得复杂(对比不同超参数、观察深层梯度)时,Matplotlib 的静态绘图就显得捉襟见肘。TensorBoard 作为深度学习领域事实上的标准可视化工具,能为我们提供动态、交互式的实验追踪。
当我们的实验变得复杂(对比不同超参数、观察深层梯度)时,Matplotlib 的静态绘图就显得捉襟见肘。TensorBoard 作为深度学习领域事实上的标准可视化工具,能为我们提供动态、交互式的实验追踪。
TensorBoard 可视化(进阶方案)
1.TensorBoard安装
tensorboardX 更偏向于早期 PyTorch 版本或非 PyTorch 框架使用;
在当前 PyTorch 生态中,推荐优先使用 torch.utils.tensorboard
from torch.utils.tensorboard import SummaryWriter
2.TensorBoard可视化的基本逻辑
从概念上看,TensorBoard 可以理解为一个 “训练过程的记录员 + 可视化前端”。
其基本工作流程可以抽象为三步:
1.记录员(SummaryWriter):训练代码中记录数据(如 loss、图像、模型结构等)
2.日志文件(logdir):将记录内容写入
3.Web UI:一个独立的后台进程,通过读取日志文件,在浏览器中实时渲染图表
👉TensorBoard 不参与训练本身,它只负责“记录”和“展示”
这也带来一个重要特性:只要有日志文件和 TensorBoard 环境,就可以复现实验过程中的可视化结果
- 日志文件可以被拷贝、共享
- 训练和可视化可以在 不同机器 上完成
3.TensorBoard配置与启动
创建SummaryWriter
在使用 TensorBoard 前,首先需要指定一个目录,用于保存所有记录数据(通常为logdir)
from tensorboardX import SummaryWriter
writer = SummaryWriter('./runs')
上述代码完成了两件事:实例化一个 SummaryWriter,指定日志输出目录为当前路径下的 runs/,之后所有通过 writer.add_xxx() 记录的内容,都会写入该目录。
👉 一个实验对应一个子目录是常见做法(如runs/exp1、runs/exp2),这也是TensorBoard 支持多实验对比(Runs)的基础
启动TensorBoard
在命令行中输入
tensorboard --logdir=/path/to/logs/ --port=xxxx
参数说明:
--logdir:日志目录路径--port:Web 服务端口(默认 6006)
启动后,在浏览器中访问:
http://localhost:6006
即可看到 TensorBoard 界面。
在服务器或远程环境中,也可以结合 nohup、tmux 等方式让 TensorBoard 后台运行,这里不再展开。
4.模型结构可视化
首先定义模型,给定一个示例输入,TensorBoard 会根据前向传播过程追踪并记录模型的计算图,再通过TensorBoard进行可视化,使用add_graph:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('./runs')
model = models.resnet18(pretrained=True)
writer.add_graph(model, input_to_model = torch.rand(64, 3, 224, 224))
writer.close()
tensorboard --logdir=./runs
即可在 Graphs 标签页中看到模型结构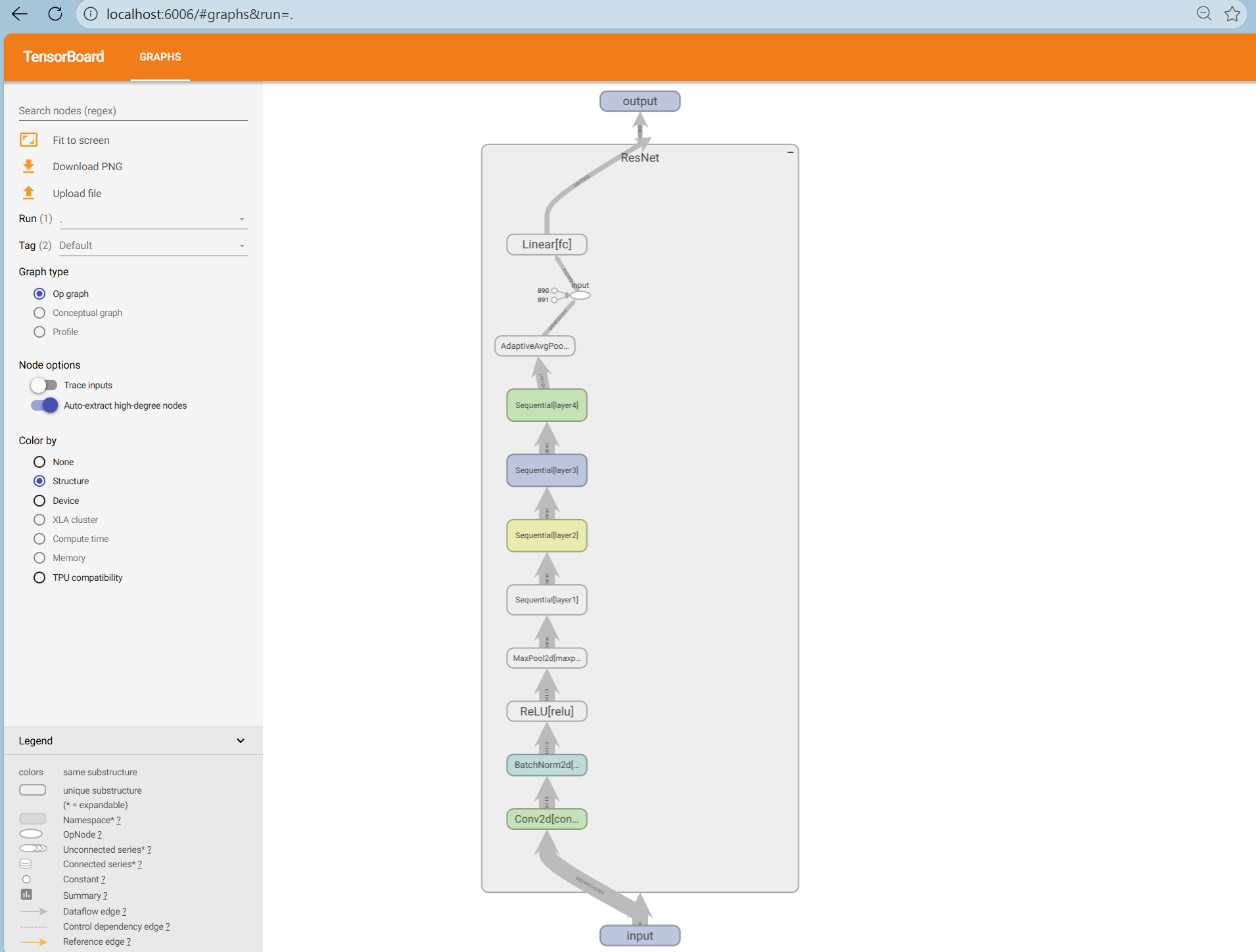
5.图像数据可视化
TensorBoard 提供了多种图像写入接口:
add_image:单张图像add_images:多张图像(batch)torchvision.utils.make_grid:将多张图像拼成网格后再显示
下面以 CIFAR-10 数据集 为例说明
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform_train = transforms.Compose(
[transforms.ToTensor()])
transform_test = transforms.Compose(
[transforms.ToTensor()])
train_data = datasets.CIFAR10(".", train=True, download=True, transform=transform_train)
test_data = datasets.CIFAR10(".", train=False, download=True, transform=transform_test)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64)
images, labels = next(iter(train_loader))
# 单张图像可视化
writer = SummaryWriter('./pytorch_tb')
writer.add_image('images[0]', images[0])
writer.close()
# 将多张图片拼接成一张图片,中间用黑色网格分割
# 多张图像拼接展示(Grid)
writer = SummaryWriter('./pytorch_tb')
img_grid = torchvision.utils.make_grid(images)
writer.add_image('image_grid', img_grid)
writer.close()
# 多张图像批量写入
writer = SummaryWriter('./pytorch_tb')
writer.add_images("images",images,global_step = 0)
writer.close()
依次运行上面三组可视化(注意不要同时在notebook的一个单元格内运行),得到的可视化结果如下(最后运行的结果在最上面):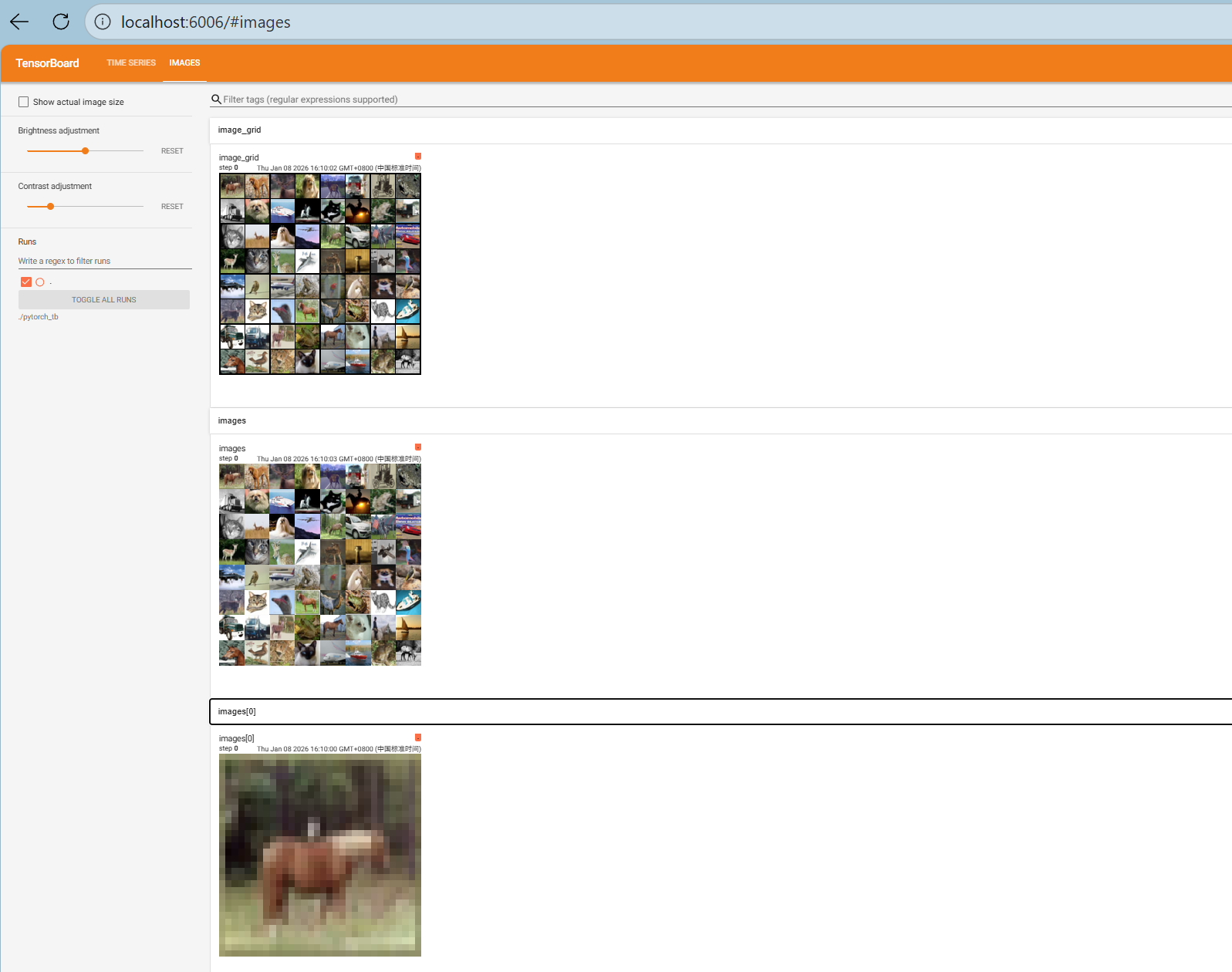
TensorBoard训练可视化
1.TensorBoard连续变量可视化
在模型训练过程中,损失函数、准确率、学习率等量随训练轮次(epoch / step)变化的数值,都属于典型的连续变量或时序变量。TensorBoard 提供的 add_scalar 接口正是为这类数据设计的。
记录单条标量曲线
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
"""
tag:曲线名称(决定 TensorBoard 中的分组与显示标签)
scalar_value:要记录的数值
global_step:横轴坐标(通常使用 epoch 或 iteration)
"""
from torch.utils.tensorboard import SummaryWriter
# 初始化 TensorBoard 的 SummaryWriter
writer = SummaryWriter('./pytorch_tb')
# 这部分与树叶分类那一部分基本一样,只是add_scalar了
# 在训练循环中记录损失和准确率
best_acc = 0
for epoch in range(EPOCHS):
print(f'\nEpoch {epoch+1}/{EPOCHS}')
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer)
val_loss, val_acc = validate(model, val_loader, criterion)
# 记录训练和验证的损失和准确率到 TensorBoard
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Accuracy/train', train_acc, epoch)
writer.add_scalar('Loss/validation', val_loss, epoch)
writer.add_scalar('Accuracy/validation', val_acc, epoch)
scheduler.step()
print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_model.pth')
print(f'Model saved with acc: {val_acc:.2f}%')
# 关闭 TensorBoard 的 SummaryWriter
writer.close()
此时在 TensorBoard 的 Scalars 页面中,可以清晰地看到训练集与验证集的损失、准确率随 epoch 的变化曲线。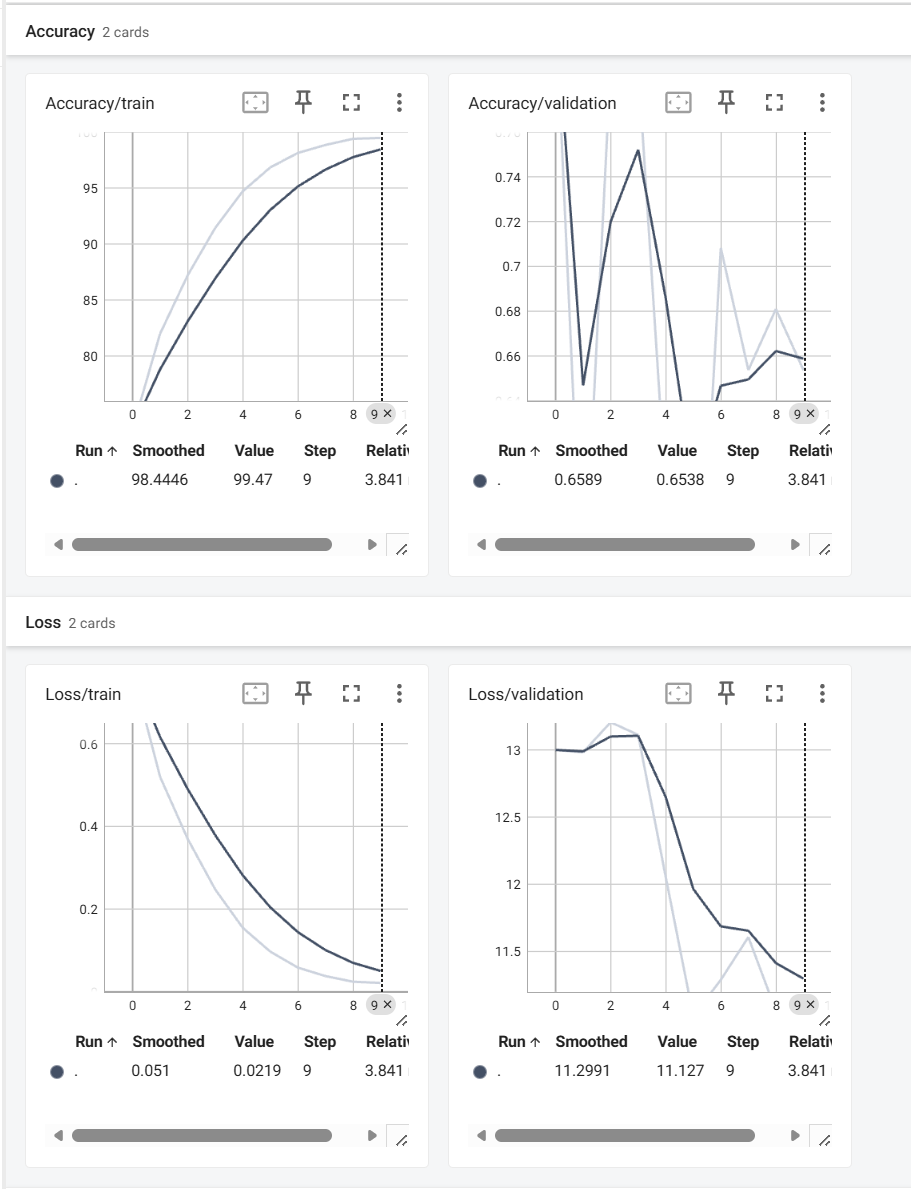
多条曲线对比的两种常见方式
在实际实验中,经常需要在 同一张图中对比多条曲线(例如 train vs val)。TensorBoard 中有两种常见做法。
- 1.使用不同子目录(多实验 / 多运行对比)
from torch.utils.tensorboard import SummaryWriter
# 初始化两个 SummaryWriter,分别用于训练和验证
train_writer = SummaryWriter('./pytorch_tb/train')
val_writer = SummaryWriter('./pytorch_tb/val')
# 在训练循环中记录损失和准确率
best_acc = 0
for epoch in range(EPOCHS):
print(f'\nEpoch {epoch+1}/{EPOCHS}')
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer)
val_loss, val_acc = validate(model, val_loader, criterion)
# 记录训练和验证的损失到 TensorBoard
train_writer.add_scalar('Loss', train_loss, epoch) # 使用相同的标签 "Loss"
val_writer.add_scalar('Loss', val_loss, epoch) # 使用相同的标签 "Loss"
scheduler.step()
print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_model.pth')
print(f'Model saved with acc: {val_acc:.2f}%')
# 关闭 TensorBoard 的 SummaryWriter
train_writer.close()
val_writer.close()
- 2.使用同一 logdir,不同 tag(推荐)
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Loss/validation', val_loss, epoch)
使用同一 logdir、不同 tag 的方式,更适合 同一实验内部的指标对比(如 train vs val),而多子目录方式更适合 不同实验配置之间的整体对比
2.参数分布可视化
当我们不仅关心“指标是否变好”,而是进一步希望了解 模型内部发生了什么变化 时,参数分布可视化就变得非常有价值。
TensorBoard 提供的 add_histogram 接口,可用于记录:
- 模型权重的分布变化
- 梯度分布是否异常
- 是否存在梯度消失 / 梯度爆炸
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None)
"""
values:通常是参数张量或梯度张量
tag:用于区分不同参数或不同类型(weight / grad)
"""
在训练过程中记录参数与梯度分布
from torch.utils.tensorboard import SummaryWriter
# 初始化 TensorBoard 的 SummaryWriter
writer = SummaryWriter('./pytorch_tb')
# 在训练循环中记录损失、准确率和模型参数的分布
best_acc = 0
for epoch in range(EPOCHS):
print(f'\nEpoch {epoch+1}/{EPOCHS}')
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer)
val_loss, val_acc = validate(model, val_loader, criterion)
# 记录训练和验证的损失和准确率到 TensorBoard
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Accuracy/train', train_acc, epoch)
writer.add_scalar('Loss/validation', val_loss, epoch)
writer.add_scalar('Accuracy/validation', val_acc, epoch)
# 记录模型参数的分布
for name, param in model.named_parameters():
writer.add_histogram(name, param, epoch)
writer.add_histogram(f'{name}.grad', param.grad, epoch)
scheduler.step()
print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_model.pth')
print(f'Model saved with acc: {val_acc:.2f}%')
# 关闭 TensorBoard 的 SummaryWriter
writer.close()
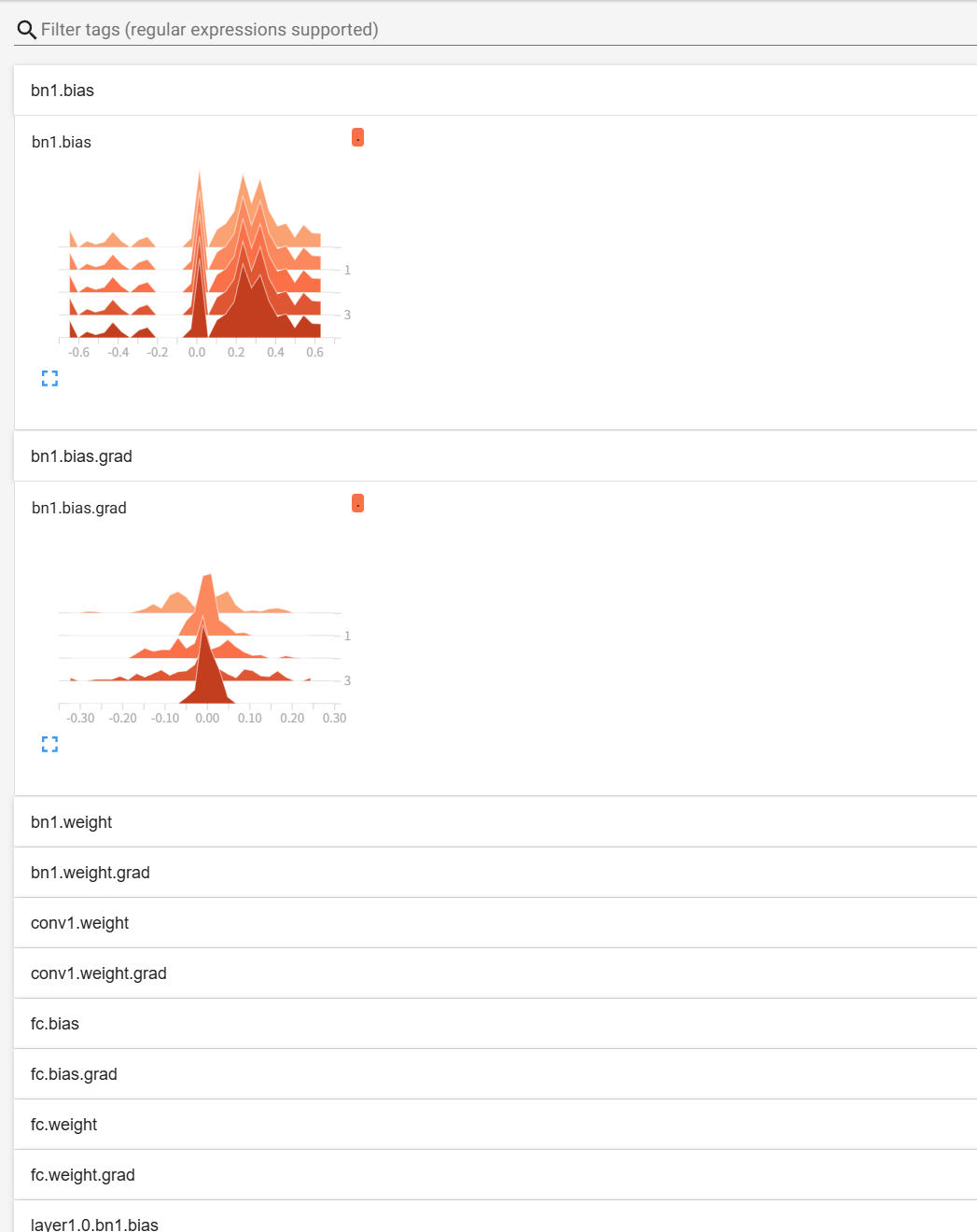
实践中的常见解读经验
- 权重分布逐渐收敛:通常意味着模型训练稳定
- 梯度长期接近 0:可能存在梯度消失
- 梯度分布剧烈波动:可能学习率过大或训练不稳定
因此,参数分布可视化通常作为:
- 模型训练异常排查工具
- 超参数(如学习率、初始化方式)调试依据

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 60
60 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)