【人工智能算法】超详细图解决策树回归算法的应用实例
本文详细介绍了基于CART算法的决策树回归模型在高尔夫打球人数预测中的应用。主要内容包括:数据预处理(独热编码、布尔值转换及数据集拆分)、CART算法原理(通过最小化MSE递归构建二叉树)、模型训练与预测流程、评估指标(RMSE)以及剪枝优化方法(预剪枝和后剪枝)。通过设置复杂度参数α平衡模型精度与泛化能力,最终实现可复现的预测模型。该方案采用Python3.7和scikit-learn1.5实现
·
文章围绕决策树回归模型实现高尔夫打球人数预测,完整流程涵盖数据处理、模型构建、训练、预测、评估及剪枝优化,具体步骤如下:
一、数据准备与预处理
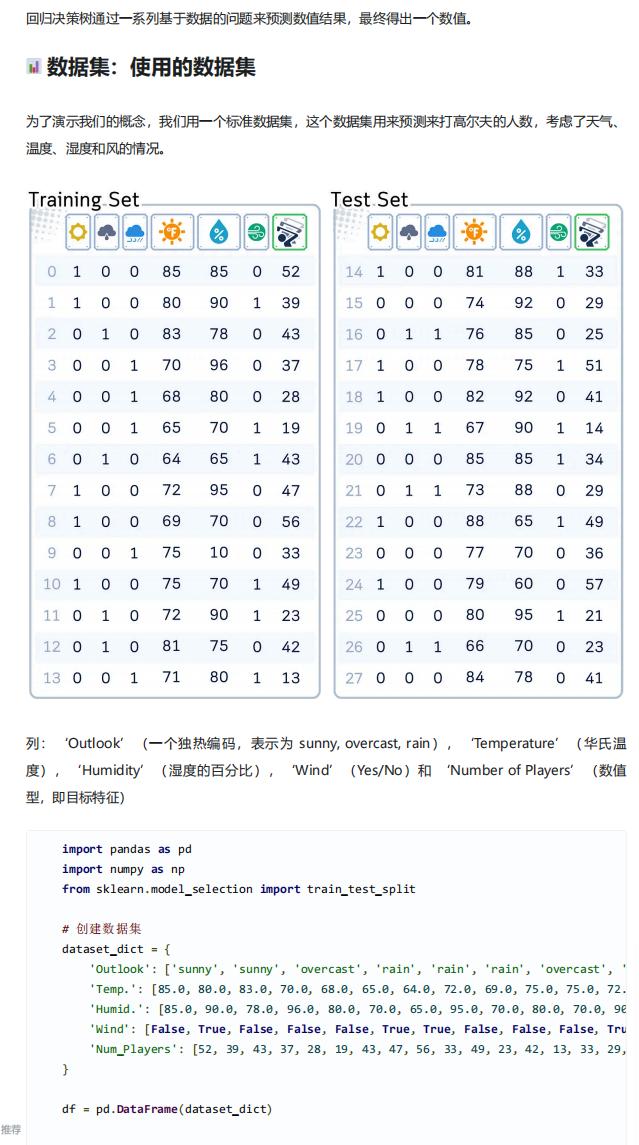
- 数据集定义:创建包含 5 个字段的数据集,特征变量包括 “Outlook”(天气,含 sunny、overcast、rain 三类)、“Temperature”(华氏温度)、“Humidity”(湿度百分比)、“Wind”(是否有风,Yes/No),目标变量为 “Num_Players”(打球人数,数值型)。
- 数据编码与转换:
- 对分类特征 “Outlook” 进行独热编码,将其拆解为对应类别的二进制列,便于模型处理;
- 将布尔型特征 “Wind” 转换为整数型(0 表示无风,1 表示有风),统一数据格式。
- 数据集拆分:使用
train_test_split函数将预处理后的数据划分为特征矩阵(X)和目标向量(y),再按 5:5 的比例拆分训练集(X_train、y_train)和测试集(X_test、y_test),且不打乱数据顺序(shuffle=False)。
二、模型核心机制与训练流程(基于 CART 算法)
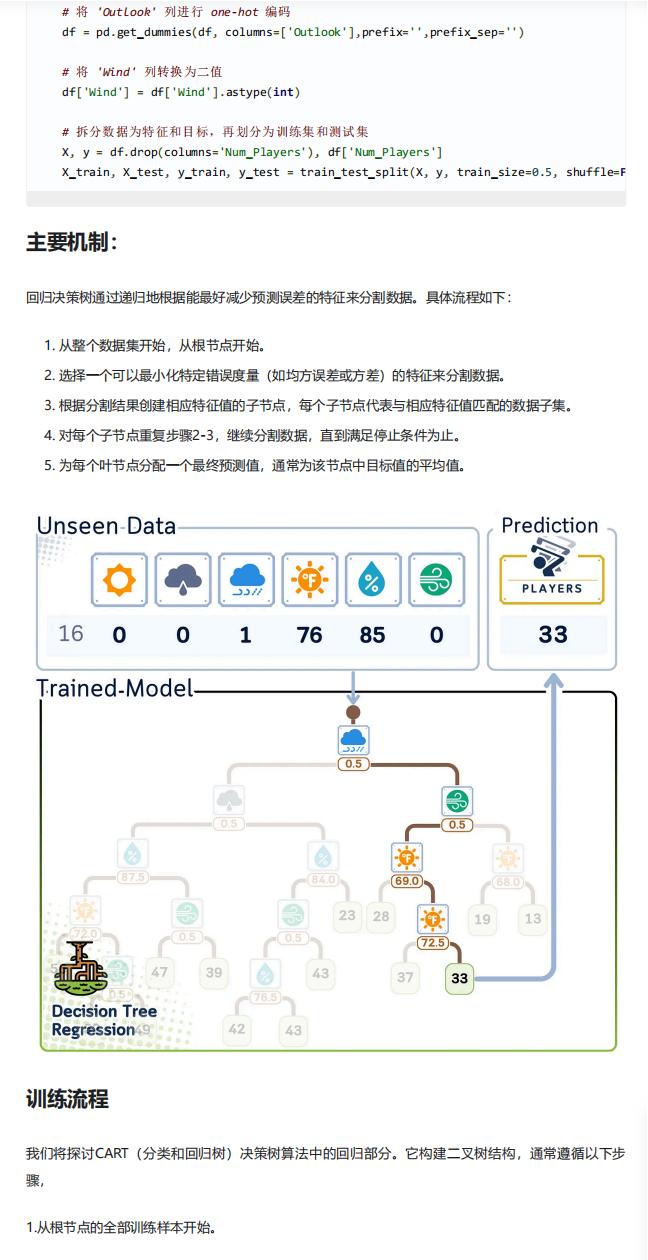
- 核心原理:通过递归分割数据构建二叉树,以最小化预测误差(均方误差 MSE 或方差)为目标,最终叶节点以该节点内目标值的平均值作为预测结果。
- 具体训练步骤:
- 初始化:从根节点开始,包含全部训练样本;
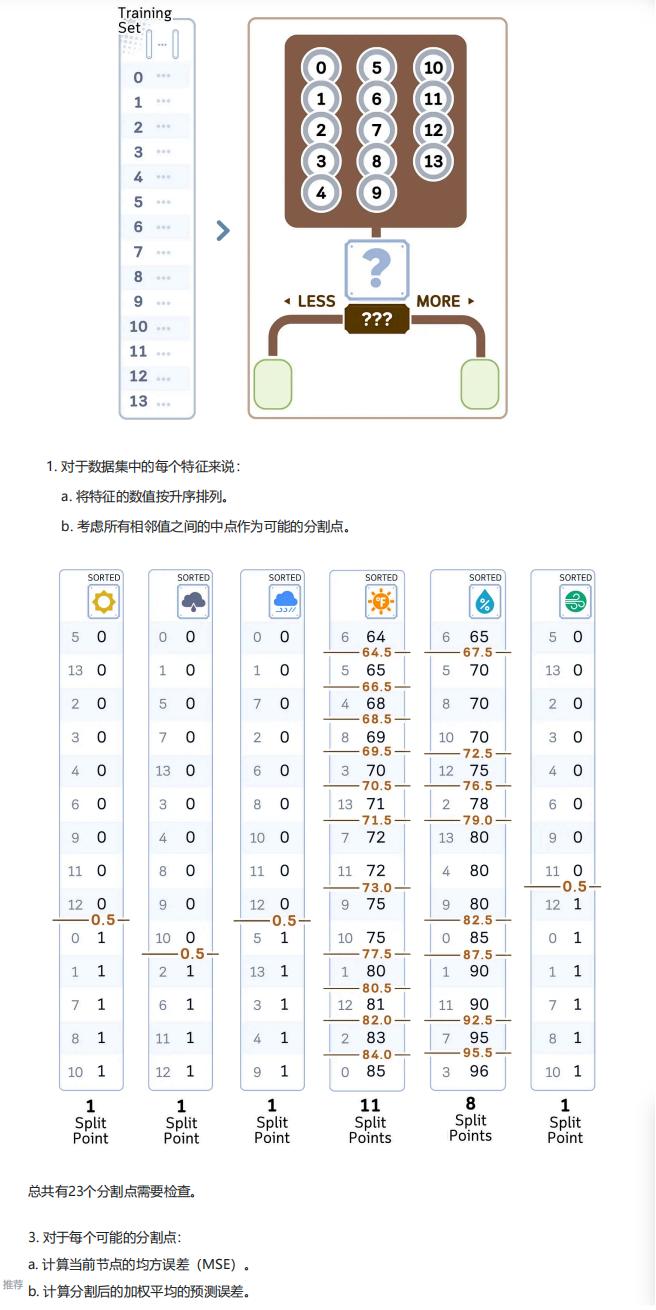
- 特征与分割点筛选:
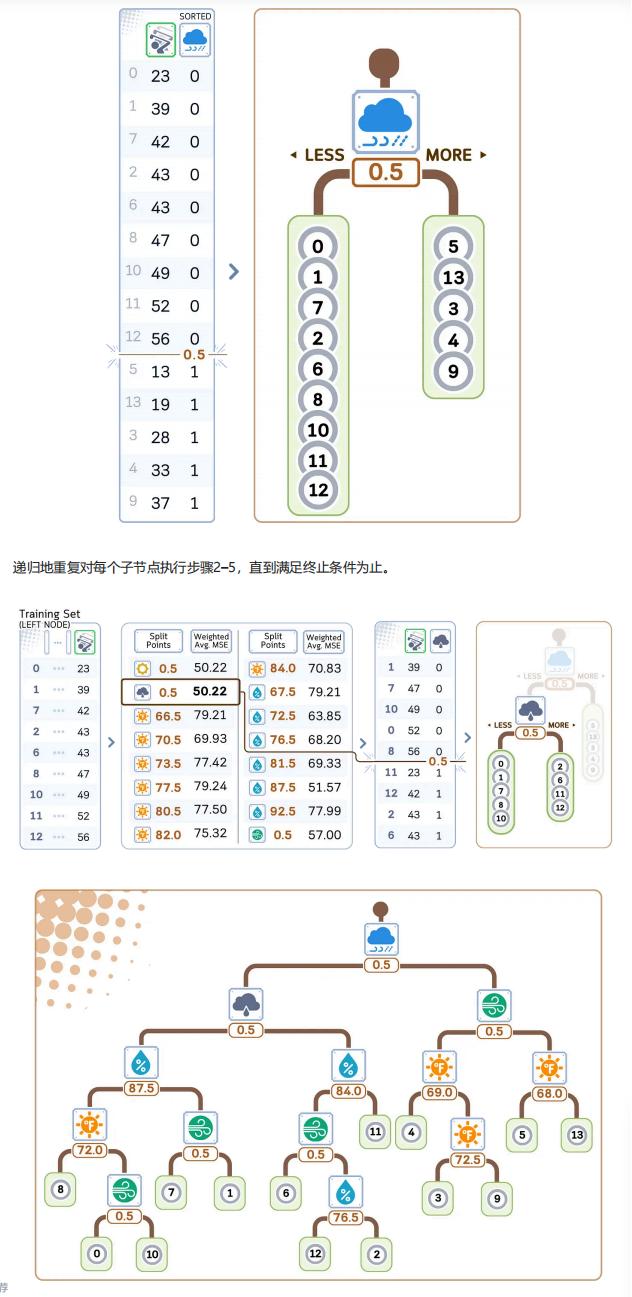
- 对每个数值型特征,按升序排列其取值,取所有相邻值的中点作为候选分割点(文中共生成 23 个分割点);
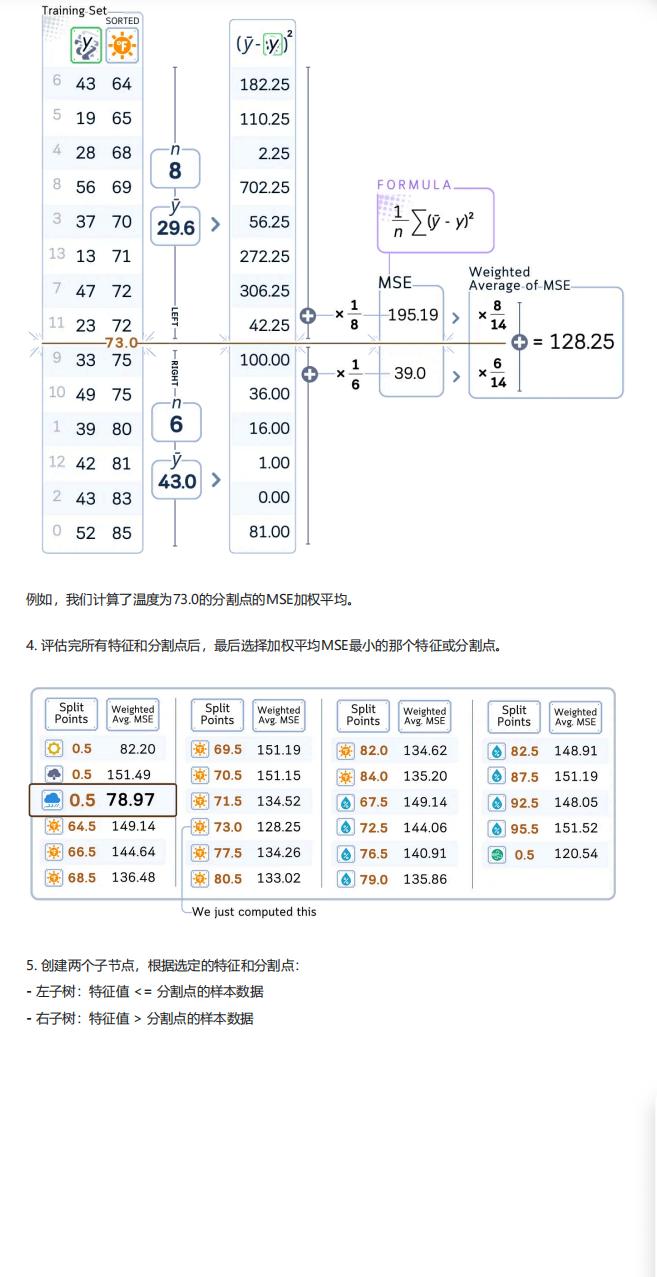
- 对每个候选分割点,计算分割前节点的 MSE,再计算分割后左右子树的加权平均 MSE(权重为子树样本数占比);
- 选择加权平均 MSE 最小的特征及对应分割点作为当前节点的分裂依据;
- 子节点创建:根据选定的特征和分割点,将当前节点样本划分为两部分,特征值≤分割点的样本归入左子树,>分割点的归入右子树,形成两个子节点;
- 递归分裂:对每个子节点重复上述 “筛选分割点 - 创建子节点” 的过程,直至满足停止条件(如达到预设深度、节点样本数不足等);
- 叶节点赋值:对最终无法继续分裂的叶节点,赋予该节点内所有样本目标变量(Num_Players)的平均值,作为该节点的预测值。
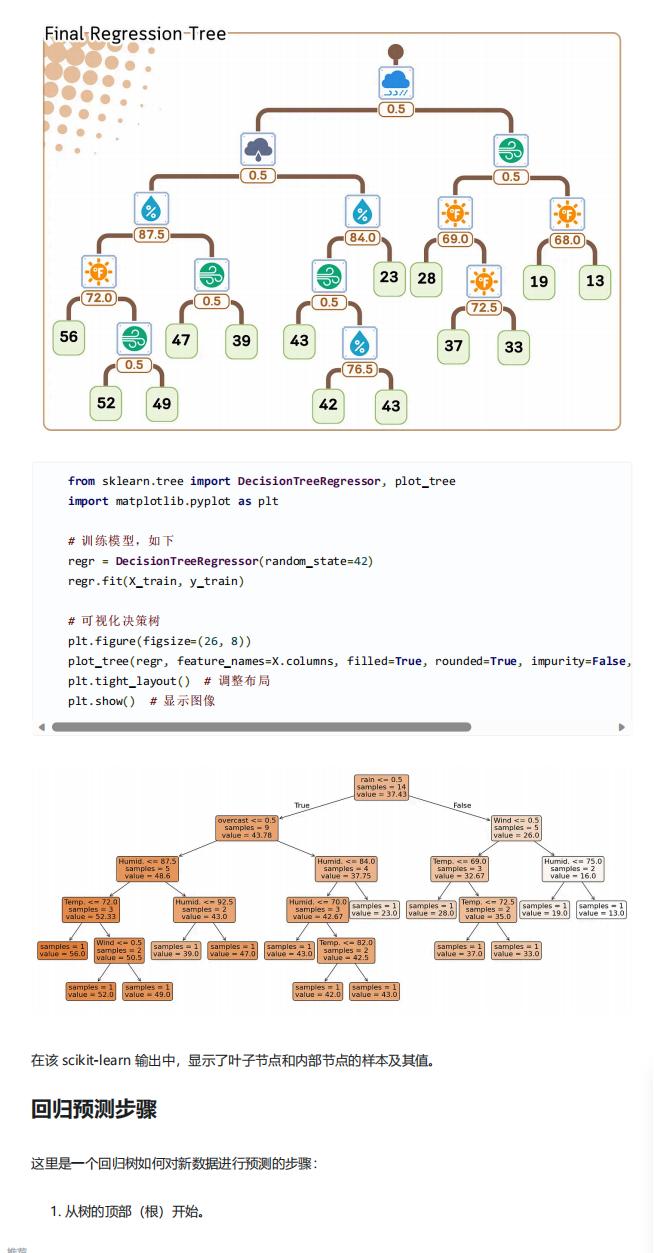
- 模型训练代码实现:调用
sklearn.tree.DecisionTreeRegressor初始化模型(设置 random_state=42 保证结果可复现),通过fit方法传入训练集(X_train、y_train)完成模型训练,同时可使用plot_tree函数可视化决策树结构,展示节点分裂逻辑与叶节点信息。
三、新数据预测步骤
- 从训练好的决策树根节点开始遍历;
- 在每个内部节点(决策点),查看当前节点的分裂特征和分割值:
- 若新数据的该特征值≤分割值,进入左子树;
- 若特征值>分割值,进入右子树;
- 重复上述判断,直至遍历到叶节点;
- 叶节点存储的平均值即为新数据的预测结果(如预测某天气下的高尔夫打球人数)。
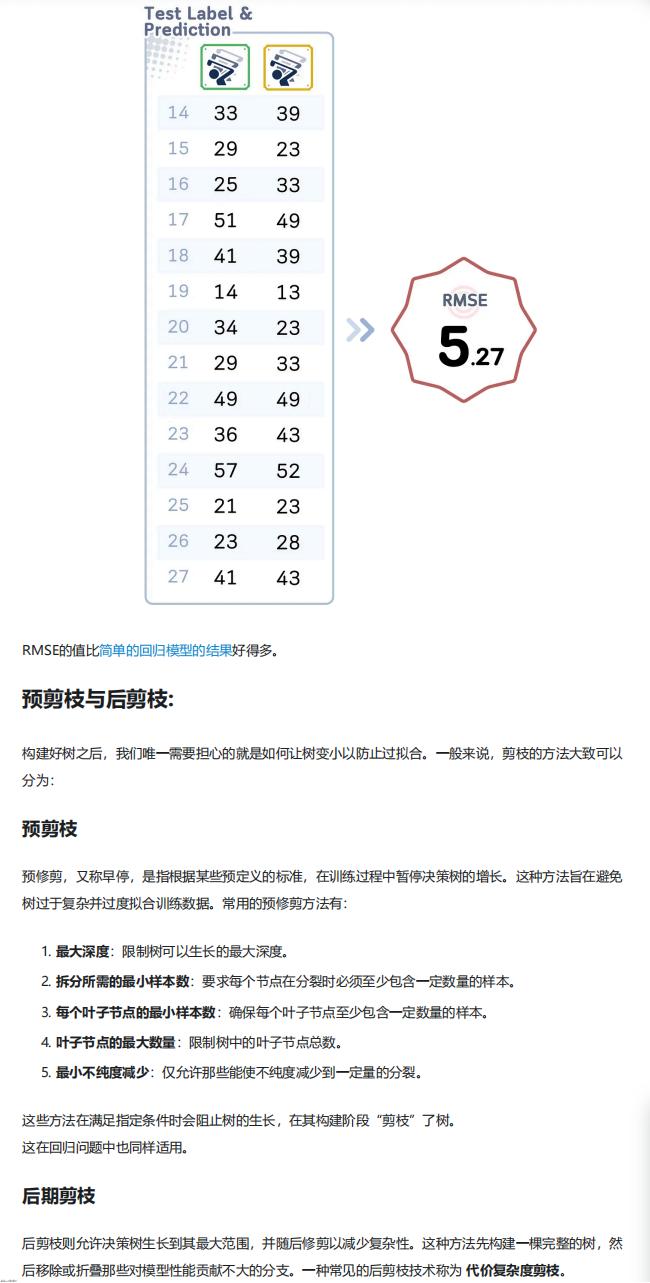
四、模型评估
使用测试集验证模型性能,通过计算均方根误差(RMSE)衡量预测值与真实值的偏差,文中结果显示该模型的 RMSE 优于简单回归模型,说明预测效果较好。
五、剪枝优化(防止过拟合)
由于决策树易生长过深导致过拟合,采用预剪枝和后剪枝两种方法优化:
- 预剪枝(早停):在模型训练过程中设置限制条件,阻止树过度生长,常用方法包括:
- 限制树的最大深度;
- 要求节点分裂时至少包含最小样本数;
- 限制每个叶节点的最小样本数;
- 设定叶节点的最大数量;
- 仅允许分裂后不纯度(MSE)减少量达到阈值的分裂操作。
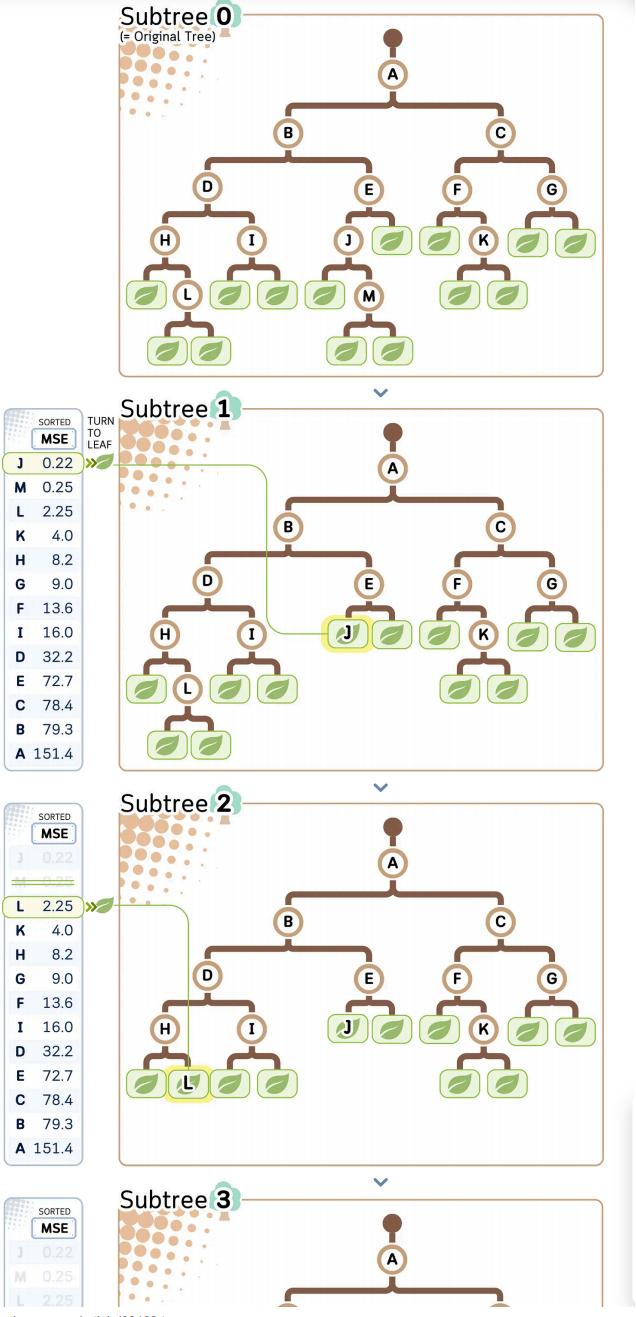
- 后剪枝(代价复杂度剪枝):先构建完整决策树,再移除无效分支,步骤如下:
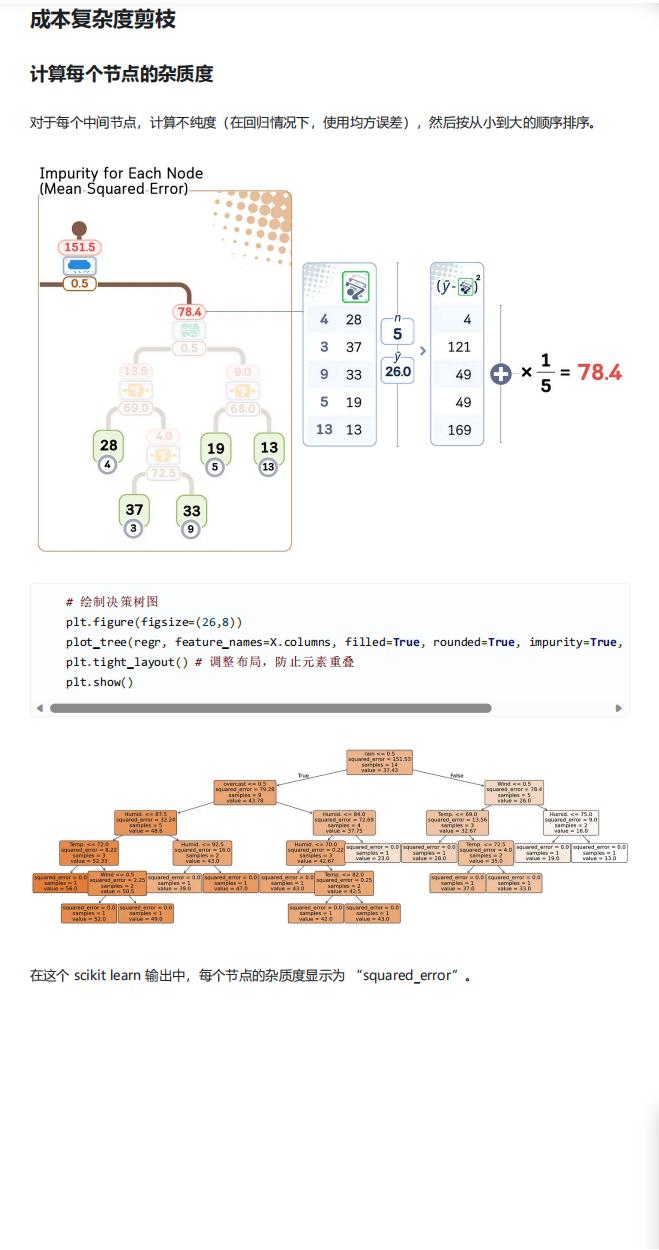
- 计算所有中间节点的不纯度(MSE),并按从小到大排序;
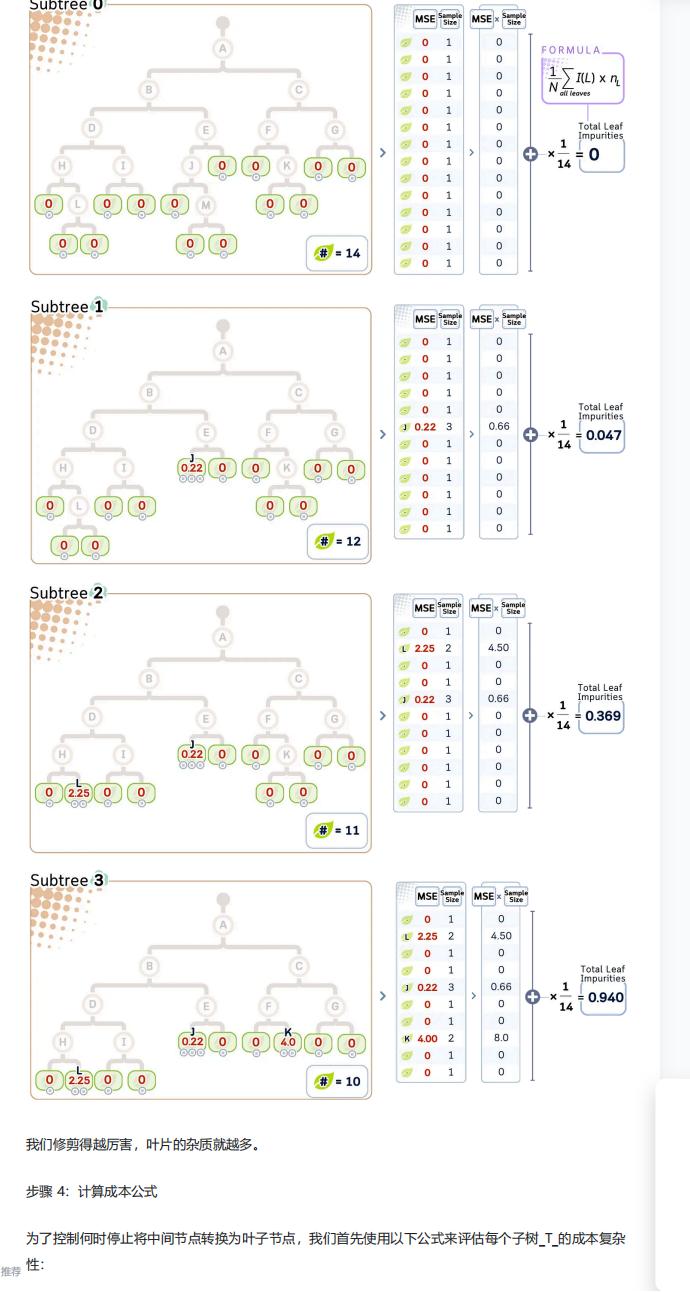
- 逐步将 MSE 最小的中间节点转化为叶节点(即移除该节点的子树),生成一系列不同复杂度的子树;
- 计算每个子树的总叶杂质 R (T):通过公式
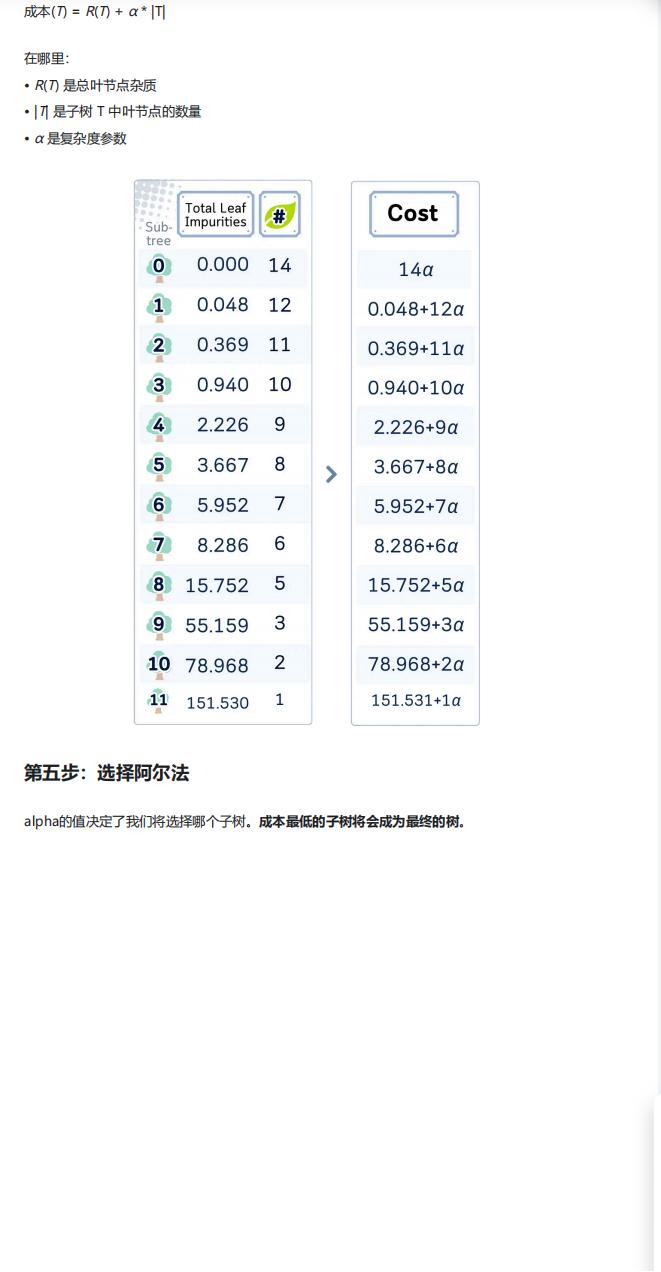
R(T) = (1/N)×Σ[I(L)×n_L]计算(N 为树总样本数,L 为叶节点,I (L) 为叶节点 MSE,n_L 为叶节点样本数); - 计算子树的成本复杂度:
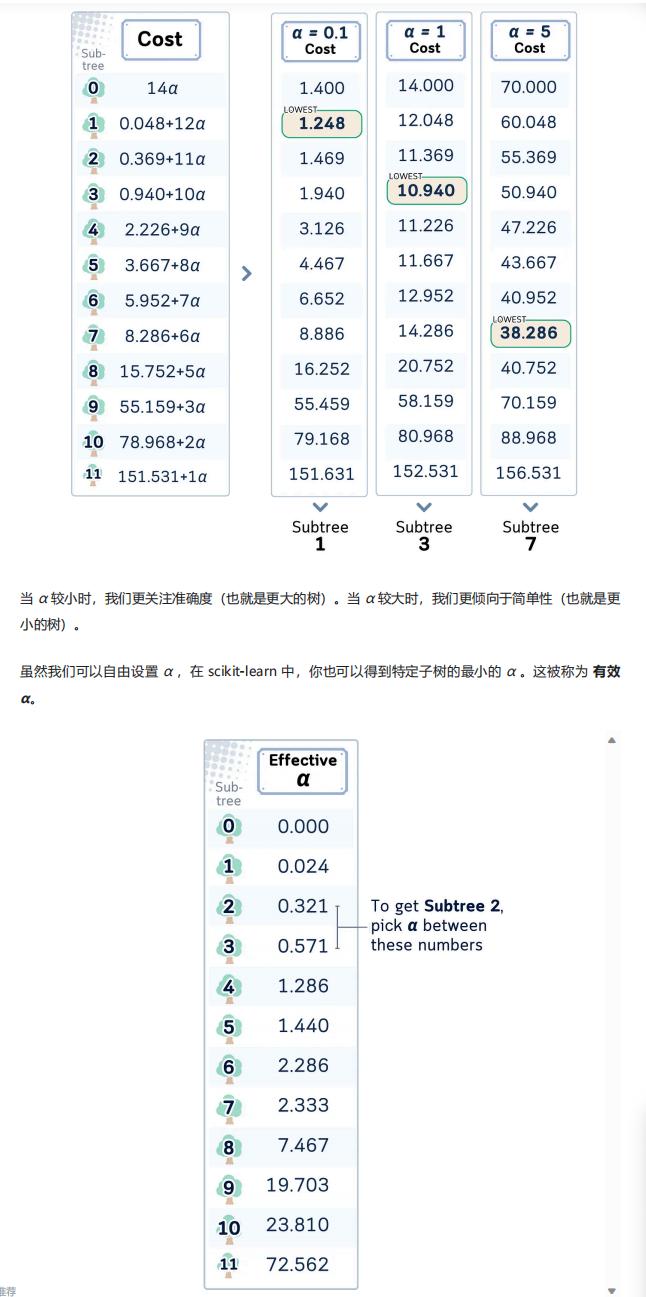
Cost = R(T) + α×|T|(α 为复杂度参数,|T | 为叶节点数量); - 选择成本最低的子树作为最终模型:α 越小越倾向于复杂树(追求准确度),α 越大越倾向于简单树(追求泛化性),可通过
cost_complexity_pruning_path函数获取有效 α 值及对应子树,文中选定 α=0.1 训练最终模型。
六、完整代码落地
- 导入依赖库(pandas、numpy、sklearn 中的数据集拆分、模型、评估指标等);
- 执行上述数据预处理、模型训练、剪枝、预测步骤;
- 输出测试集预测结果的 RMSE,完成模型效果验证。
技术环境依赖 Python 3.7 和 scikit-learn 1.5,所有步骤均通过代码实现,可复现性强,且通过剪枝平衡了模型复杂度与泛化能力。






脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)