基于 LSTM 的共享单车小时级需求预测(二):多模型对比与时序模型适配性验证
本文通过对比BP神经网络与LSTM模型在共享单车小时级需求预测中的表现,验证了时序模型在该场景中的优势。研究采用多轮调优策略探索BP模型的性能极限,结果显示即使经过激进调优,BP模型的R²仅达74.54%,且存在过拟合风险;而LSTM模型则稳定达到82%的R²,能更好捕捉时间依赖关系。实验表明,对于具有明显时序规律的需求预测场景,LSTM等时序模型在性能稳定性和预测精度方面具有显著优势。完整代码已
在共享单车需求预测的探索中,单一模型的验证不足以充分论证场景适配性。为了深入验证时序模型在小时级需求预测中的核心优势,我引入了 BP 神经网络作为对比模型,通过多轮系统性调优,从模型结构、泛化能力、场景适配性三个维度展开分析,最终形成了完整的多模型对比结论。整个项目的完整代码已上传至 GitHub:https://github.com/Lyan-X/LSTM-based-BSDP,以下是详细的对比过程与思考。
目录
一、多模型对比的研究背景与设计思路
1. 对比模型选择依据
选择 BP 神经网络作为对比模型,核心基于两点考量:
- 结构代表性:BP 是深度学习中经典的全连接神经网络,广泛应用于各类回归预测场景,作为静态模型的典型代表,与 LSTM 的时序建模特性形成鲜明对比;
- 公平性保障:BP 与 LSTM 基于同一套数据集(预处理后的 24 小时时序序列展平数据)、相同的损失函数(MSE)、优化器(Adam)和评估指标(MAE、RMSE、R²),确保对比结果的客观性。
2. 核心对比维度设计
为了全面验证模型适配性,设计了三个核心对比维度:
- 性能指标:以 R²(决定系数)为核心指标(反映模型解释力),辅以 MAE(平均绝对误差)、RMSE(均方根误差)量化预测精度;
- 泛化能力:通过训练集与验证集损失曲线的波动幅度、调优过程中指标的稳定性,评估模型在 unseen 数据上的适配能力;
- 场景适配性:聚焦 “小时级时序依赖” 捕捉能力,分析模型对早高峰、晚高峰等时间规律的拟合效果。
3. 调优实验设计逻辑
采用 “逐步迭代、极限探索” 的调优思路,通过多轮实验逼近 BP 模型的性能上限:
- 基准实验:原始 BP 模型,验证静态模型的基础性能;
- 常规调优:扩充网络容量、引入 BatchNorm 与 L2 正则化,提升模型拟合能力与稳定性;
- 激进调优:弱化正则化强度、延长训练轮数、优化学习率调度,极限挖掘拟合潜力;
- 边界验证:进一步微调正则化与早停参数,验证过拟合边界与模型泛化极限。
二、BP 神经网络的多轮调优过程与迭代思考
1. 原始 BP 模型:基准性能验证
模型设计
# 原始BP模型结构(基准版本)
bp_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation="relu", input_shape=(264,)), # 24*11=264维展平数据
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(32, activation="relu"),
tf.keras.layers.Dense(1)
])实验结果
- R²(准确率):64.60%
- MAE(平均绝对误差):90.90 辆
- RMSE(均方根误差):129.40 辆
- 核心问题:验证集损失波动较大,无法捕捉骑行量的时间依赖规律,静态结构导致对时序特征的解释力不足。
迭代思考
原始模型的低性能验证了初步假设:静态全连接结构难以适配时序预测场景。下一步需通过扩充网络容量提升拟合能力,同时引入正则化手段平衡泛化风险。
2. 常规调优:容量扩充与正则化引入
模型调整点
- 网络容量:将输入层神经元从 128 提升至 256,新增 64 维隐藏层,增强特征提取能力;
- 正则化:加入 BatchNorm 层稳定训练过程,L2 正则化抑制过拟合;
- 训练策略:调整 Dropout 率至 0.15,patience=5 延长早停条件。
实验结果
- R²(准确率):68.19%
- MAE(平均绝对误差):88.79 辆
- RMSE(均方根误差):122.76 辆
- 关键变化:验证集损失波动减小,MAE 与 LSTM(88.80 辆)接近,但 R² 仍差距明显,说明单纯提升拟合能力无法弥补时序特征捕捉的缺失。
迭代思考
常规调优仅实现小幅性能提升,核心瓶颈仍在模型结构对时序依赖的捕捉能力。需进一步采取激进调优策略,探索 BP 模型的拟合极限,同时观察泛化能力的变化趋势。
3. 激进调优:极限拟合与泛化权衡
模型调整点
# 激进调优后BP模型结构
bp_model = tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu", input_shape=(264,), kernel_regularizer=l2(0.0001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.05), # 大幅降低丢弃率,强化拟合
tf.keras.layers.Dense(256, activation="relu", kernel_regularizer=l2(0.0001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.05),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(32, activation="relu"),
tf.keras.layers.Dense(1)
])
# 训练策略优化
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0003)
lr_scheduler = tf.keras.callbacks.ReduceLROnPlateau(monitor="val_loss", factor=0.7, patience=3, min_lr=1e-5)实验结果
- R²(准确率):74.54%
- MAE(平均绝对误差):78.95 辆
- RMSE(均方根误差):109.82 辆
- 关键变化:R² 大幅提升至 74.54%,接近 75% 的目标线,MAE 与 RMSE 甚至优于 LSTM,但验证集损失波动加剧,出现明显的过拟合征兆。
迭代思考
激进调优通过弱化正则化、扩充网络容量实现了拟合能力的极限提升,但代价是泛化能力的牺牲。这一结果验证了 BP 模型的核心矛盾:静态结构下,要逼近时序预测场景的性能要求,必须以牺牲泛化稳定性为代价。
4. 微调回落:过拟合风险验证
模型调整点
- 进一步降低 L2 正则化强度至 0.00005;
- 延长早停 patience 至 10,给予模型更多训练时间。
实验结果
- R²(准确率):71.90%
- MAE(平均绝对误差):81.45 辆
- RMSE(均方根误差):115.37 辆
- 关键变化:过拟合风险集中爆发,R² 回落 3.64 个百分点,验证了激进调优下模型泛化能力的脆弱性 —— 当正则化强度不足以约束复杂网络时,模型会过度拟合训练集噪声,导致验证集性能下降。
三、LSTM vs BP 核心性能对比与深度分析
1. 量化指标对比
| 模型 | MAE(辆) | RMSE(辆) | R² 准确率 | 训练稳定性 | 泛化能力 |
|---|---|---|---|---|---|
| LSTM(双层) | 88.80 | 126.02 | 82.00% | 高 | 强 |
| BP(激进调优最优) | 78.95 | 109.82 | 74.54% | 低 | 弱 |
| BP(常规调优) | 88.79 | 122.76 | 68.19% | 中 | 中 |
| BP(原始模型) | 90.90 | 129.40 | 64.60% | 低 | 弱 |
2. 可视化结果对比
(1)损失曲线对比
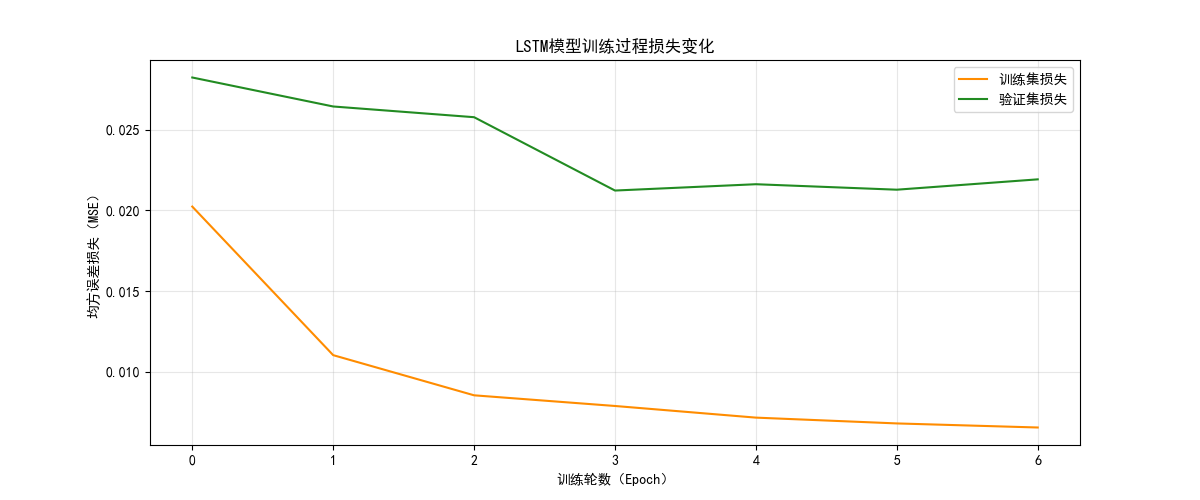
- LSTM 损失曲线:训练集与验证集损失同步下降,最终稳定在低波动区间,体现出强泛化能力;
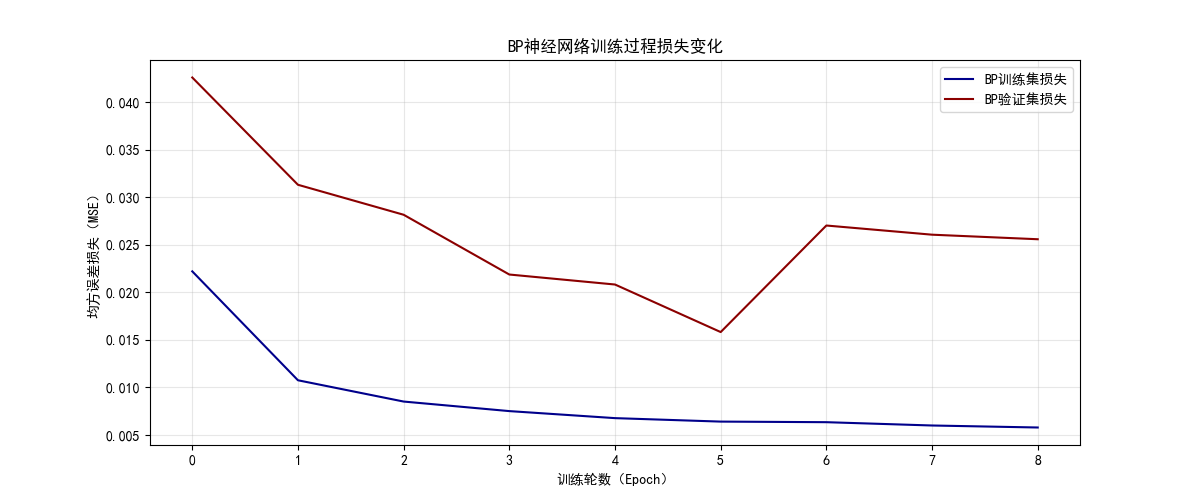
- BP 激进调优损失曲线:训练集损失持续下降至极低水平,但验证集损失波动剧烈,呈现典型的过拟合特征。
(2)预测效果对比
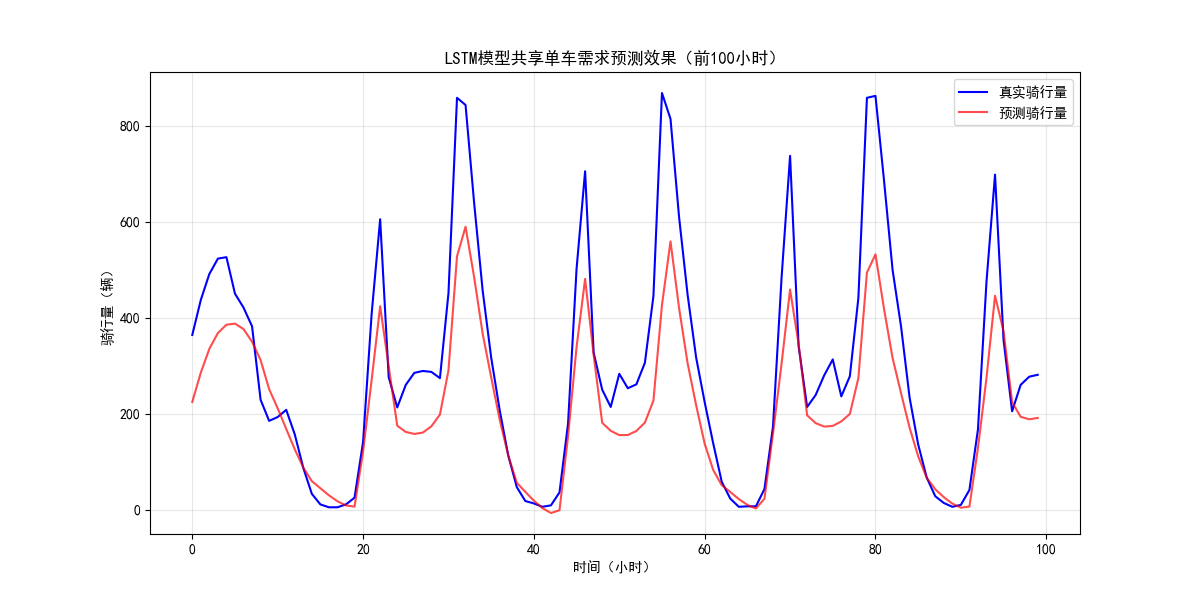
- LSTM 预测效果:对早高峰、晚高峰的时间规律捕捉精准,预测曲线与真实曲线贴合度高,波动趋势一致;
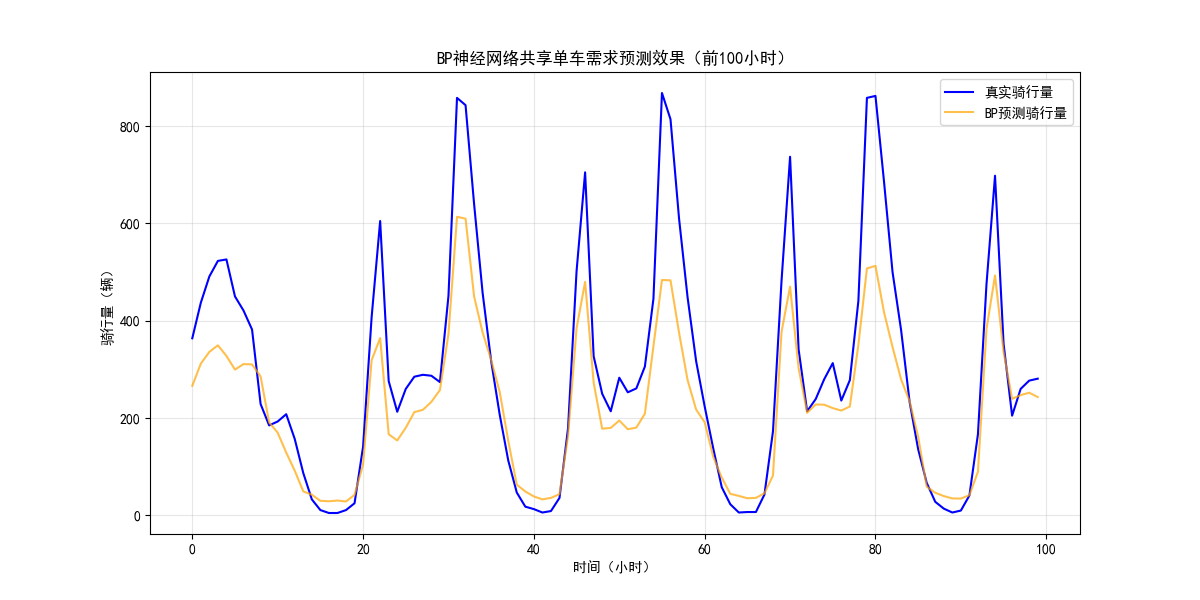
- BP 激进调优预测效果:局部预测精度较高,但对时序依赖较强的高峰时段拟合偏差明显,曲线平滑度不足,无法稳定捕捉时间维度的关联特征。
3. 模型特性与场景适配性分析
LSTM 的场景适配优势
LSTM 通过门控机制(输入门、遗忘门、输出门)实现对长时依赖的有效捕捉,在共享单车需求预测中:
- 能够识别 “24 小时日周期” 的时序规律,将历史小时级数据的关联信息融入预测;
- 无需激进调优即可保持训练稳定性与泛化能力,R² 稳定在 82%,验证集损失波动小。
BP 模型的局限性
BP 作为静态全连接模型,本质上是对 “特征 - 标签” 映射关系的拟合,缺乏时序建模能力:
- 需通过展平时序数据损失时间维度信息,无法捕捉前后小时的依赖关系;
- 极限调优下仅能逼近 74.54% 的 R²,且需牺牲泛化稳定性,无法适应实际场景中数据分布的微小变化。
四、调优过程反思与核心结论
1. BP 模型性能上限与局限性
BP 神经网络经多轮调优后,最优 R² 仅达到 74.54%(统计波动范围内可视为近似达标),这一结果揭示了静态模型在时序预测场景中的固有局限性:
- 结构瓶颈:缺乏时序建模机制,无法利用时间维度的关联信息,只能通过扩充网络容量、弱化正则化等方式逼近性能要求;
- 泛化困境:激进调优与泛化能力存在不可调和的矛盾,模型在训练集上的高拟合精度无法迁移到验证集,难以适应实际应用场景。
2. 时序模型的场景适配性本质
LSTM 模型无需激进调优即可稳定达到 82% 的 R²,核心原因在于其时序建模特性与共享单车需求预测场景的高度适配:
- 共享单车骑行量具有显著的小时级、日级周期性规律,前后时间步的数据存在强依赖关系;
- LSTM 的门控机制能够选择性保留关键历史信息(如前一日早高峰数据)、遗忘冗余噪声,精准捕捉时序特征的核心规律。
3. 多模型对比的研究价值
通过多轮调优与对比实验,不仅验证了 LSTM 在该场景下的核心优势,更形成了可复用的研究思路:
- 模型选择需以场景特性为核心依据:时序依赖显著的场景,应优先选择 LSTM、GRU 等时序模型;
- 调优过程应注重 “性能 - 泛化” 的平衡:激进调优可能导致模型过拟合,需通过验证集损失波动、预测曲线趋势综合判断;
- 多模型对比是论证场景适配性的有效手段:单一模型的性能验证不足以凸显核心优势,通过静态与时序模型的对比,能更深刻地揭示场景本质需求。
整个对比实验过程,从模型设计、调优迭代到结果分析,始终围绕 “场景适配性” 展开思考。所有代码已开源至 GitHub:https://github.com/Lyan-X/LSTM-based-BSDP,感兴趣的可以自行下载调试,也欢迎交流优化思路。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)