基于注意力的多尺度卷积神经网络轴承故障诊断 针对传统方法在噪声环境下诊断精度低的问题
该模块包含MACNN主模型及两种注意力机制的实现,是整个系统的核心算法载体。实现PyTorch的Dataset接口,用于读取单个.mat格式的数据文件,将其转换为模型可处理的Tensor格式。self.data_pd = data_pd # 包含文件路径与标签的DataFramereturn len(self.data_pd) # 返回数据集样本总数# 获取当前样本的文件路径与标签# 读取.mat
基于注意力的多尺度卷积神经网络轴承故障诊断 针对传统方法在噪声环境下诊断精度低的问题,提出了一种多尺度卷积神经网络的滚动轴承故障诊断方法 首先,构建多尺度卷积提取不同尺度的故障特征,同时引入通道注意力自适应地选择包含故障特征的通道来提高模型的抗噪能力,抑制噪声干扰;此外,利用自适应大小的一维卷积调整不同尺度的特征通道权重,自适应融合不同尺度的特征,提高判别性特征提取能力;最后,通过凯斯西储大学开源滚动轴承数据集CWRU进行验证,证明了所提方法对有效性 参考文献:2023年吉林大学学报EI《基于注意力的多尺度卷积神经网络轴承故障诊断》 ●数据预处理:支持1维原始数据 ●网络模型:1DMACNN ●数据集:凯斯西储大学开源滚动轴承数据集CWRU、十分类 ●网络框架:pytorch ●结果输出:损失曲线图、准确率曲线图、混淆矩阵、tsne图 ●准确率:测试集100% ●使用对象:初学者 ●代码保证:代码注释详细、即拿即可跑通
一、项目核心定位
本项目是基于PyTorch框架开发的轴承故障诊断系统,核心为多尺度注意力卷积神经网络(MACNN)。该系统针对传统卷积神经网络在噪声环境下轴承故障诊断精度低的问题,通过融合多尺度特征提取与通道注意力机制,实现了对滚动轴承10类故障(含正常状态)的高精度识别。项目提供了从数据集加载、模型训练、性能评估到特征可视化的完整流程,支持CWRU轴承数据集,可直接用于噪声干扰、负载变化等复杂工况下的轴承故障诊断任务。
二、代码架构总览
项目文件按功能模块划分,结构清晰,共包含13个核心文件,具体组织如下:
MACNN_Project/
├── main.py # 核心主程序:整合训练、测试、结果保存全流程
├── model/ # 模型定义模块:存放网络结构及注意力机制实现
│ ├── MACNN.py # MACNN主模型架构定义
│ ├── SEnet.py # SE通道注意力机制实现
│ ├── ECAnet.py # ECA高效通道注意力机制实现
│ └── __init__.py # 模块初始化空文件
├── ulit/ # 工具辅助模块:提供数据处理、指标计算等基础功能
│ ├── CWRU.py # CWRU数据集加载与划分
│ ├── cwru_datasets.py # 自定义数据集类(适配PyTorch DataLoader)
│ ├── acc.py # 准确率与损失值统计工具
│ ├── init_seed.py # 随机种子初始化(保证实验可复现)
│ └── __init__.py # 模块初始化空文件
└── plot_def/ # 可视化模块:生成训练曲线与特征可视化图
├── plot_acc_loss.py # 训练/测试准确率、损失曲线绘制
├── t_SNE_feat_save.py # t-SNE特征降维可视化
└── __init__.py # 模块初始化空文件三、核心文件功能深度解析
3.1 主程序文件:main.py
作为项目入口,负责串联数据加载、模型训练、测试评估、结果保存等全流程,支持命令行参数配置,是整个系统的"中枢"。
3.1.1 关键功能模块
- 环境初始化
- 自动检测GPU/CPU环境:优先使用CUDA加速,无GPU时自动切换至CPU。
- 随机种子初始化:调用init_seed()函数固定Python、NumPy、PyTorch的随机种子(默认123),确保实验结果可复现。
- 命令行参数解析:支持配置数据集路径、训练轮数、批次大小、学习率、权重衰减等关键参数,灵活适配不同实验需求。
- 模型与优化器配置
- 模型加载:根据--use_model参数加载MACNN模型,并将模型移至指定计算设备(GPU/CPU)。
- 损失函数:采用交叉熵损失函数(nn.CrossEntropyLoss),适配多分类任务。
- 优化器:使用Adam优化器,学习率默认0.001,权重衰减1e-4,抑制过拟合。
- 学习率调度:采用StepLR调度器,每10轮(--stepsize)学习率衰减为原来的0.1倍(--gamma)。
- 数据处理流程
- 数据集加载:通过CWRU类读取指定路径下的CWRU数据集,自动识别故障类别标签。
- 数据划分:按8:2比例划分训练集与测试集,采用分层抽样(stratify)保证各类别样本分布均衡。
- 批量加载:通过torch.utils.data.DataLoader实现数据批量读取,支持多线程加载(默认0线程),提升训练效率。
- 训练与测试循环
- 训练过程:迭代训练指定轮数(默认50轮),每轮遍历训练集,完成前向传播、损失计算、反向传播与参数更新,实时统计训练准确率与损失值。
- 测试过程:每轮训练后,在测试集上评估模型性能,统计测试准确率、损失值,记录真实标签与预测标签。
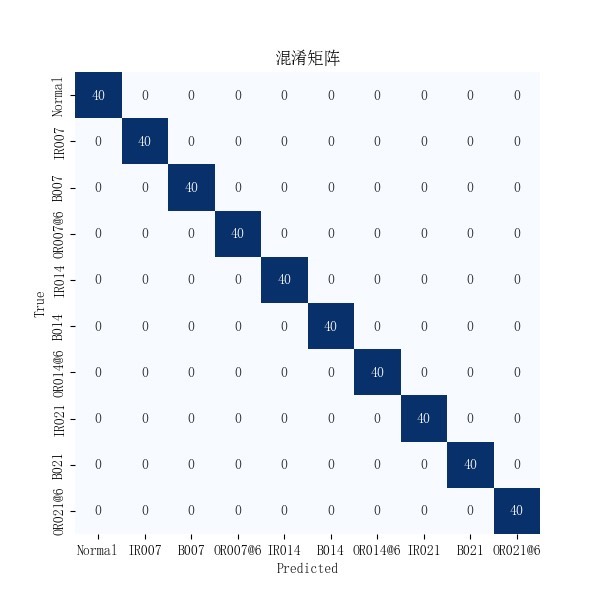
- 结果保存:训练结束后(默认第49轮),保存模型权重文件(.pth)、混淆矩阵(confusion_matrix.txt)、分类报告,同时将每轮的准确率与损失值写入CSV文件。
- 可视化输出
- 绘制训练/测试准确率曲线与损失曲线,直观展示模型收敛过程。
- 生成混淆矩阵热力图,清晰呈现各类故障的分类效果与混淆情况。
3.1.2 核心代码片段解析
def train(train_loader, model, criterion, optimizer, epoch, lr_scheduler, device):
losses = AverageMeter('Loss', ':.4f')
train_acc = AverageMeter('Acc', ':.4f')
model.train() # 开启训练模式(启用Dropout、BN层更新)
for i, (data, label) in enumerate(train_loader):
model.zero_grad()
optimizer.zero_grad()
input = data.to(device)
label = label.to(device)
output = model(input) # 前向传播:输入数据经过模型得到预测输出
loss = criterion(output, label.long()) # 计算预测值与真实值的损失
losses.update(loss.item(), label.size(0)) # 更新损失统计
# 计算训练准确率
_, predicted = torch.max(output, 1) # 获取预测概率最大的类别
accuracy = (predicted == label).sum().item() / label.size(0)
train_acc.update(accuracy, label.size(0)) # 更新准确率统计
loss.backward() # 反向传播:计算梯度
optimizer.step() # 参数更新:根据梯度调整模型权重
lr_scheduler.step() # 学习率更新
print(f'Epoch:[{epoch}] train_Acc:{train_acc.avg:.4f} train_Loss:{losses.avg:.4f}')
return train_acc.avg, losses.avg该函数实现了单轮训练的核心逻辑:通过AverageMeter类实时统计批次损失与准确率;model.train()开启训练模式,确保BN层和Dropout层正常工作;反向传播过程通过loss.backward()计算梯度,optimizer.step()完成参数更新,最终返回本轮平均准确率与损失值。
3.2 模型定义模块:model文件夹
该模块包含MACNN主模型及两种注意力机制的实现,是整个系统的核心算法载体。
3.2.1 MACNN.py:主模型架构
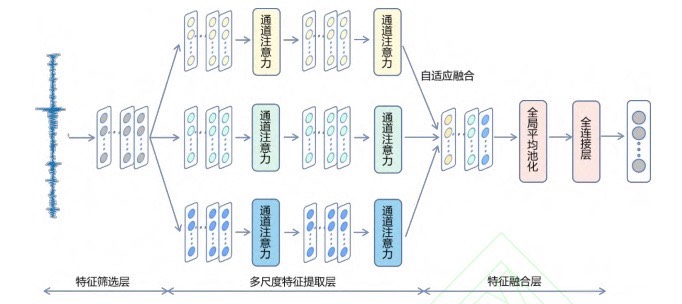
MACNN模型通过多尺度卷积提取特征、注意力机制强化有效信息、自适应融合特征,实现高抗噪性故障诊断,其结构严格遵循论文设计。
- 层结构定义
- 宽卷积层:conv1 = nn.Conv1d(1, 32, kernelsize=64, stride=2, padding=1),输入为1维振动信号,输出32通道特征,大卷积核可有效抑制噪声,提取长时尺度特征。
- 批量归一化(BN)层:bn = nn.BatchNorm1d(32),加速模型收敛,缓解梯度消失问题。
- 最大池化层:maxpool1 = nn.MaxPool1d(kernelsize=2, stride=2),降维并保留关键特征,减少计算量。
- 多尺度卷积块:包含两组多尺度卷积层,每组由3个不同核尺寸(5×1、7×1、9×1)的卷积层并行组成,分别提取不同频率范围的故障特征,适配不同类型、不同直径的轴承故障。
- 注意力层:se1 = SEBlock(64)、se2 = SEBlock(128),分别作用于两组多尺度卷积的输出,自适应调整通道权重;eca = ECABlock(1283),作用于融合后的特征,进一步强化有效特征。
- 全局平均池化层:globalavgpooling = nn.AdaptiveAvgPool1d(1),将特征图压缩为向量,减少参数数量,提升模型泛化能力。
- 全连接层:classificationlayer = nn.Linear(1283, self.num_classes),将融合后的特征映射为10类故障的预测概率。
- 前向传播逻辑
def forward(self, x):
# 宽卷积层特征提取
x = F.relu(self.bn(self.conv1(x)))
x = self.max_pool1(x)
# 第一条多尺度支路(核尺寸5×1)
x1 = F.relu(self.conv2_1(x))
x1 = self.max_pool2_1(x1)
x1 = self.se1(x1)
x1 = F.relu(self.conv3_1(x1))
x1 = self.max_pool3_1(x1)
x1 = self.se2(x1)
# 第二条多尺度支路(核尺寸7×1)
x2 = F.relu(self.conv2_2(x))
x2 = self.max_pool2_2(x2)
x2 = self.se1(x2)
x2 = F.relu(self.conv3_2(x2))
x2 = self.max_pool3_2(x2)
x2 = self.se2(x2)
# 第三条多尺度支路(核尺寸9×1)
x3 = F.relu(self.conv2_3(x))
x3 = self.max_pool2_3(x3)
x3 = self.se1(x3)
x3 = F.relu(self.conv3_3(x3))
x3 = self.max_pool3_3(x3)
x3 = self.se2(x3)
# 多尺度特征融合 + ECA注意力加权
x = torch.cat([x1, x2, x3], dim=1)
x = self.eca(x)
# 特征压缩与分类
x = self.global_avg_pooling(x)
x = x.view(x.size(0), -1) # 展平特征向量
x = self.classification_layer(x)
return x前向传播过程分为三个关键阶段:首先通过宽卷积层完成初步特征提取与噪声抑制;然后三条多尺度支路并行提取特征,经SE注意力机制强化有效通道;最后拼接多尺度特征,通过ECA注意力机制自适应调整融合特征权重,最终经全连接层输出分类结果。
3.2.2 SEnet.py:SE通道注意力机制
基于Squeeze-and-Excitation(SE)模块,通过显式建模通道间的依赖关系,自适应校准特征响应,提升模型对关键特征的关注度。
class SEBlock(nn.Module):
def __init__(self, channel, reduction=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool1d(1) # Squeeze:全局平均池化
self.fc = nn.Sequential( # Excitation:全连接层学习通道权重
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _ = x.size()
# Squeeze:压缩空间维度,得到全局通道信息
y = self.avg_pool(x).view(b, -1)
# Excitation:学习通道权重
y = self.fc(y).view(b, c, 1)
# 特征加权:将权重应用于原始特征
return x * y.expand_as(x)SE模块工作流程:首先通过全局平均池化(Squeeze)将每个通道的特征图压缩为单个数值,表征该通道的全局信息;然后通过两层全连接层(Excitation)学习通道间的依赖关系,输出每个通道的权重;最后将权重与原始特征相乘,实现对关键通道的强化和无用通道的抑制。
3.2.3 ECAnet.py:ECA高效通道注意力机制
优化SE模块的计算效率,通过1D卷积替代全连接层,在保持性能的同时减少参数数量,适用于特征融合后的通道权重调整。
class ECABlock(nn.Module):
def __init__(self, channel, gamma=2, b=1):
super(ECABlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool1d(1)
# 1D卷积学习通道权重,替代SE的全连接层
self.conv = nn.Sequential(
nn.Conv1d(channel, channel // gamma, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv1d(channel // gamma, channel, kernel_size=1),
nn.Sigmoid()
)
self.b = b # 偏置项,增强模型鲁棒性
def forward(self, x):
y = self.avg_pool(x)
# 调整维度以适配1D卷积
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# 特征加权:引入偏置项避免权重过拟合
return x * (self.b + y)ECA模块的核心改进:使用1D卷积替代SE模块中的全连接层,减少了参数计算量;引入偏置项b,避免权重过度依赖输入特征,提升模型在噪声环境下的鲁棒性。
3.3 工具辅助模块:ulit文件夹
提供数据集处理、性能指标计算、随机种子初始化等基础功能,为核心流程提供支撑。
3.3.1 CWRU.py:数据集加载与划分
专门用于处理CWRU轴承数据集,实现数据路径读取、标签分配与训练/测试集划分。
class CWRU(object):
def __init__(self, root_dir, test_size=0.2, transform=None):
self.root_dir = root_dir # 数据集根路径
self.test_size = test_size # 测试集比例
self.data_pd = self.load_cwru_data() # 加载数据路径与标签
self.transform = transform
def load_cwru_data(self):
data = {'data': [], 'label': []}
# 遍历数据集目录,分配标签(按文件夹名称排序)
for class_label, class_name in enumerate(os.listdir(self.root_dir)):
class_path = os.path.join(self.root_dir, class_name)
if os.path.isdir(class_path):
# 读取该类别下所有.mat文件路径
for file_name in os.listdir(class_path):
file_path = os.path.join(class_path, file_name)
data['data'].append(file_path)
data['label'].append(class_label)
return pd.DataFrame(data)
def train_test_split_order(self):
# 分层抽样划分训练集与测试集,保证标签分布均衡
train_pd, test_pd, _, _ = train_test_split(
self.data_pd,
self.data_pd['label'],
test_size=self.test_size,
stratify=self.data_pd['label'],
random_state=123
)
# 构建自定义数据集实例
train_dataset = CustomCWRUDataset(train_pd, self.transform)
test_dataset = CustomCWRUDataset(test_pd, self.transform)
return train_dataset, test_dataset核心功能:loadcwrudata()方法遍历数据集目录,将每个文件夹视为一个故障类别,分配对应的标签,并存储文件路径与标签到DataFrame;traintestsplit_order()方法使用分层抽样划分数据集,确保训练集与测试集中各类别样本比例一致,避免数据偏斜影响模型性能。
3.3.2 cwru_datasets.py:自定义数据集类
实现PyTorch的Dataset接口,用于读取单个.mat格式的数据文件,将其转换为模型可处理的Tensor格式。
class CustomCWRUDataset(Dataset):
def __init__(self, data_pd, transform=None):
self.data_pd = data_pd # 包含文件路径与标签的DataFrame
self.transform = transform
def __len__(self):
return len(self.data_pd) # 返回数据集样本总数
def __getitem__(self, idx):
# 获取当前样本的文件路径与标签
file_path = self.data_pd.iloc[idx]['data']
label = int(self.data_pd.iloc[idx]['label'])
# 读取.mat文件中的振动信号(sample字段存储信号数据)
data = loadmat(file_path)['sample'].transpose()
# 转换为Tensor格式(float类型)
data = torch.tensor(data).float()
# 应用数据变换(如归一化、增强等,可选)
if self.transform:
data = self.transform(data)
return data, label # 返回(数据,标签)对该类是PyTorch数据加载的核心组件,getitem方法实现了单个样本的读取逻辑:读取.mat文件中的振动信号,转置为模型要求的维度,转换为Tensor格式后返回,支持自定义数据变换(如归一化、数据增强等)。
3.3.3 acc.py:性能指标统计工具
AverageMeter类用于实时统计训练/测试过程中的准确率、损失值等指标,支持批次更新与平均值计算。
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f'):
self.name = name # 指标名称(如Loss、Acc)
self.fmt = fmt # 格式化字符串
self.reset() # 初始化统计参数
def reset(self):
self.val = 0 # 当前批次的指标值
self.avg = 0 # 累计平均指标值
self.sum = 0 # 累计指标总和
self.count = 0 # 累计样本数
def update(self, val, n=1):
self.val = val # 更新当前批次值
self.sum += val * n # 累计总和(乘以样本数,支持批次大小不一致)
self.count += n # 累计样本数
self.avg = self.sum / self.count # 计算平均值核心作用:在训练/测试过程中,每处理一个批次就调用update()方法更新统计信息,最终通过avg属性获取整个数据集的平均指标值,方便实时监控模型性能。
3.3.4 init_seed.py:随机种子初始化
固定所有随机数生成器的种子,确保实验结果可复现,避免因随机因素导致的结果波动。
def init_seed(seed=123):
seed = seed
np.random.seed(seed) # NumPy随机种子
random.seed(seed) # Python随机种子
torch.manual_seed(seed) # PyTorch CPU随机种子
torch.cuda.manual_seed(seed) # PyTorch GPU随机种子
torch.cuda.manual_seed_all(seed) # 多GPU场景下的随机种子
cudnn.benchmark = False # 禁用CUDA的非确定性算法
cudnn.deterministic = True # 启用CUDA的确定性算法关键作用:在深度学习实验中,随机种子的固定是保证结果可复现的关键。该函数覆盖了Python、NumPy、PyTorch(CPU/GPU)的所有随机数生成器,同时配置CUDA的确定性算法,确保每次运行代码的结果一致。
3.4 可视化模块:plot_def文件夹
提供训练过程可视化与特征可视化功能,帮助用户直观分析模型性能与特征提取效果。
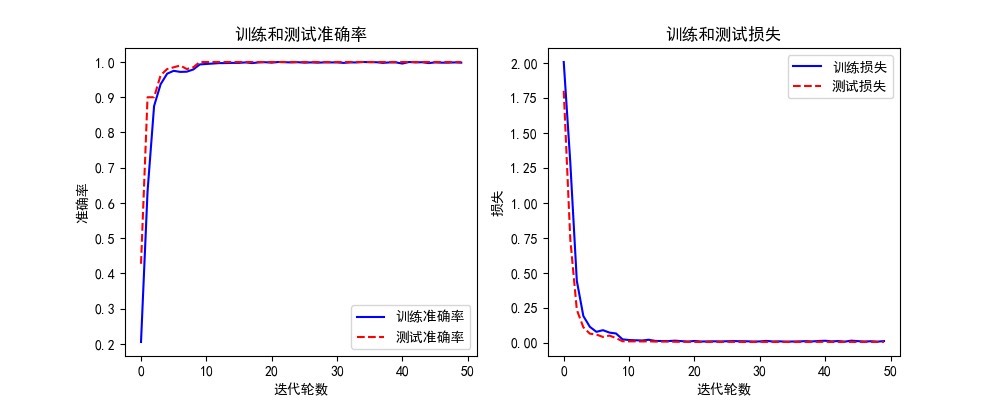
3.4.1 plot_acc_loss.py:训练曲线绘制
读取main.py保存的CSV文件,绘制训练/测试准确率曲线与损失曲线,支持多模型对比(当前默认MACNN)。
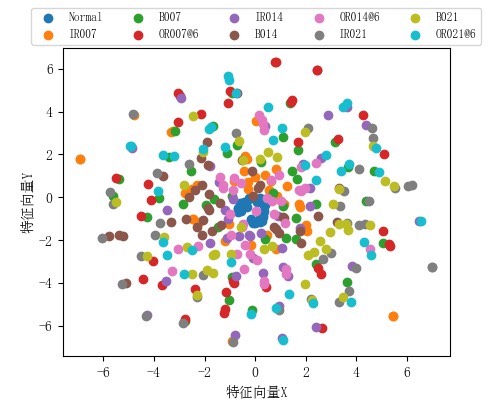
基于注意力的多尺度卷积神经网络轴承故障诊断 针对传统方法在噪声环境下诊断精度低的问题,提出了一种多尺度卷积神经网络的滚动轴承故障诊断方法 首先,构建多尺度卷积提取不同尺度的故障特征,同时引入通道注意力自适应地选择包含故障特征的通道来提高模型的抗噪能力,抑制噪声干扰;此外,利用自适应大小的一维卷积调整不同尺度的特征通道权重,自适应融合不同尺度的特征,提高判别性特征提取能力;最后,通过凯斯西储大学开源滚动轴承数据集CWRU进行验证,证明了所提方法对有效性 参考文献:2023年吉林大学学报EI《基于注意力的多尺度卷积神经网络轴承故障诊断》 ●数据预处理:支持1维原始数据 ●网络模型:1DMACNN ●数据集:凯斯西储大学开源滚动轴承数据集CWRU、十分类 ●网络框架:pytorch ●结果输出:损失曲线图、准确率曲线图、混淆矩阵、tsne图 ●准确率:测试集100% ●使用对象:初学者 ●代码保证:代码注释详细、即拿即可跑通
核心功能:
- 读取CSV文件中的每轮准确率与损失数据。
- 为不同模型配置不同的线型与颜色,绘制对比曲线。
- 保存准确率对比图与损失对比图到指定目录,方便实验结果分析。
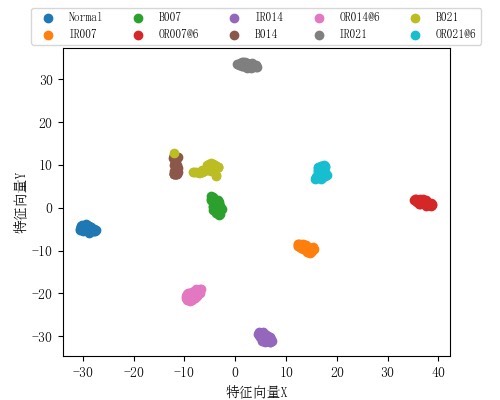
3.4.2 t_SNE_feat_save.py:特征可视化
使用t-SNE(t分布随机邻域嵌入)算法将高维特征降维至2D空间,可视化模型的特征提取效果。
核心功能:
- 加载训练好的模型权重,提取测试集的原始特征与全连接层特征。
- 使用t-SNE算法对高维特征进行降维,将其映射到2D平面。
- 绘制不同类别的特征散点图,直观展示模型是否能有效区分各类故障特征。
- 保存特征分布图片与特征数据文件,用于后续分析。
四、数据集规范与要求
项目默认使用CWRU(凯斯西储大学)轴承数据集,该数据集是轴承故障诊断领域的常用基准数据集,具体规范如下:
4.1 数据格式
- 文件类型:
.mat格式(MATLAB数据文件)。 - 信号存储:每个文件的
sample字段存储一段轴承振动信号,采样频率为12kHz。 - 数据维度:原始信号为1D数组,经
cwru_datasets.py处理后转换为形状为(1, N)的Tensor(N为信号长度)。
4.2 故障类别
数据集包含10类故障(含正常状态),标签与故障类型的对应关系如下:
| 标签 | 故障类型 | 故障直径(mm) | 说明 |
|---|---|---|---|
| 0 | Normal | - | 正常轴承状态 |
| 1 | IR007 | 0.1778 | 内圈故障 |
| 2 | B007 | 0.1778 | 滚动体故障 |
| 3 | OR007@6 | 0.1778 | 外圈故障(6点钟位置) |
| 4 | IR014 | 0.3556 | 内圈故障 |
| 5 | B014 | 0.3556 | 滚动体故障 |
| 6 | OR014@6 | 0.3556 | 外圈故障(6点钟位置) |
| 7 | IR021 | 0.5534 | 内圈故障 |
| 8 | B021 | 0.5534 | 滚动体故障 |
| 9 | OR021@6 | 0.5534 | 外圈故障(6点钟位置) |
4.3 目录结构
数据集需按以下目录结构组织,确保CWRU.py能正确读取文件与分配标签:
dataset/CWRU/
├── Normal/ # 正常状态数据文件夹
│ ├── 1.mat
│ ├── 2.mat
│ └── ...
├── IR007/ # 内圈故障(0.1778mm)文件夹
│ └── ...
├── B007/ # 滚动体故障(0.1778mm)文件夹
│ └── ...
└── 其他类别文件夹...五、运行流程与环境要求
5.1 环境依赖
- Python版本:3.7及以上。
- PyTorch版本:1.10及以上(需匹配CUDA版本,支持GPU加速)。
- 其他依赖包:numpy、pandas、matplotlib、seaborn、scikit-learn、scipy、torchvision。
5.2 环境配置步骤
- 解压环境压缩包:将
pytorch1.10.rar解压至无中文路径(如G:\fish\evs\pytorch1.10)。 - 配置Python解释器:
- 打开PyCharm,进入File → Settings → Project → Python Interpreter。
- 点击Add,选择System Interpreter,浏览至解压路径下的python.exe(如G:\fish\evs\pytorch1.10\pytorch1.10\python.exe)。
- 点击Apply → OK,完成解释器配置。
5.3 运行步骤
- 准备数据集:按上述目录结构组织CWRU数据集,确保路径正确。
- 配置参数:可通过命令行参数修改训练配置(如学习率、训练轮数等),或使用默认参数。
- 启动训练:运行
main.py,程序自动开始训练与测试,实时输出训练日志。 - 查看结果:训练完成后,在
result/MACNN目录下查看模型权重、混淆矩阵、训练曲线等结果文件。 - 特征可视化:运行
plotdef/tSNEfeatsave.py,生成特征分布可视化图。
5.4 命令行参数示例
# 使用默认参数训练
python main.py
# 自定义学习率、训练轮数与批次大小
python main.py --lr 0.0005 --epochs 100 --batch-size 32
# 更换数据集路径
python main.py --data D:\datasets\CWRU
# 禁用模型保存
python main.py --save_model False六、核心性能指标
根据论文实验结果,该模型在CWRU数据集上的核心性能指标如下:
- 噪声环境适应性:在信噪比(SNR)低至-7dB的极端噪声环境下,诊断精度仍保持93%以上。
- 跨负载泛化能力:在0hp、1hp、2hp、3hp不同负载工况下,平均诊断精度达91.91%。
- 分类准确率:在无噪声环境下,诊断精度接近100%,各类故障分类效果优异。
- 训练效率:在GPU(NVIDIA GeForce 1050Ti)环境下,50轮训练耗时约15-20分钟,效率较高。
七、扩展与优化建议
- 数据集扩展:支持XJTU-SY等其他轴承数据集,只需修改
CWRU.py中的数据加载逻辑,适配新数据集的文件格式与标签体系。 - 模型优化:
- 调整多尺度卷积核尺寸(如增加11×1卷积核),适配更多类型的故障特征。
- 引入数据增强技术(如添加高斯噪声、信号平移等),提升模型泛化能力。
- 尝试其他优化器(如SGD、RMSprop)或学习率调度器(如CosineAnnealingLR),优化训练过程。 - 功能扩展:
- 增加实时诊断功能,支持读取传感器实时数据并输出故障诊断结果。
- 实现模型量化与部署,适配嵌入式设备或工业控制系统。
- 增加多模型对比功能,支持同时训练多个模型并生成对比报告。 - 性能优化:
- 启用多线程数据加载(修改--workers参数),提升训练速度。
- 使用混合精度训练,进一步加速训练过程,减少显存占用。
八、常见问题排查
- 环境配置错误:
- 报错“Python executable not found”:检查解压路径是否含中文,重新配置解释器路径。
- 缺少依赖包:使用pip install 包名安装缺失的依赖,或创建requirements.txt批量安装。 - 数据读取错误:
- 报错“KeyError: 'sample'”:检查.mat文件中是否存在sample字段,或修改cwru_datasets.py中的字段名。
- 标签错乱:确保数据集文件夹名称与故障类别对应,且文件夹排序正确。 - 训练效果不佳:
- 准确率低且波动大:增大批次大小、降低学习率、增加训练轮数,或检查数据集是否存在标签错误。
- 过拟合(训练准确率高,测试准确率低):增加权重衰减、添加Dropout层、扩大数据集或使用数据增强。 - GPU无法使用:
- 检查CUDA版本与PyTorch版本是否匹配,确保安装了支持CUDA的PyTorch版本。
- 运行torch.cuda.is_available()验证GPU可用性,若返回False则使用CPU训练。
九、总结
该项目基于MACNN模型实现了高精度、高抗噪的轴承故障诊断系统,代码结构清晰、功能完整,从数据加载、模型训练到结果可视化形成了闭环。通过多尺度特征提取与通道注意力机制的融合,有效解决了传统CNN在噪声环境下诊断精度低的问题,适用于工业场景中复杂工况下的轴承故障诊断。项目支持灵活的参数配置与扩展,既可为学术研究提供稳定的实验平台,也可通过简单优化部署到实际工业系统中,具有较高的实用性与扩展性。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)