基于麻雀搜索算法优化BP神经网络(SSA - BP)的数据回归预测及Matlab代码实现
麻雀搜索算法模拟了麻雀觅食和反捕食行为。在这个算法中,麻雀群体分为发现者(探索者)和加入者(追随者),发现者负责寻找食物并为整个群体提供觅食方向,加入者则跟随发现者获取食物。同时,麻雀还有反捕食行为,当危险来临,一部分麻雀会迅速做出反应以避免被捕食。BP神经网络是一种多层前馈神经网络,通过误差反向传播算法来调整网络的权值和阈值。它由输入层、隐藏层和输出层组成,信息从前向后传递,误差从后向前传播并不
基于麻雀搜索算法优化BP神经网络(SSA-BP)的数据回归预测 SSA-BP回归 matlab代码 注:暂无Matlab版本要求 -- 推荐 2018B 版本及以上
在数据预测领域,BP神经网络(Back Propagation Neural Network)是一种经典且应用广泛的算法。然而,传统BP神经网络容易陷入局部最优解,导致预测精度受限。为了克服这一问题,将麻雀搜索算法(Sparrow Search Algorithm,SSA)与BP神经网络相结合,形成SSA - BP模型,能有效提升预测性能。本文将介绍如何基于SSA - BP进行数据回归预测,并附上Matlab代码及相应分析。
一、麻雀搜索算法(SSA)原理简介
麻雀搜索算法模拟了麻雀觅食和反捕食行为。在这个算法中,麻雀群体分为发现者(探索者)和加入者(追随者),发现者负责寻找食物并为整个群体提供觅食方向,加入者则跟随发现者获取食物。同时,麻雀还有反捕食行为,当危险来临,一部分麻雀会迅速做出反应以避免被捕食。
二、BP神经网络原理简介
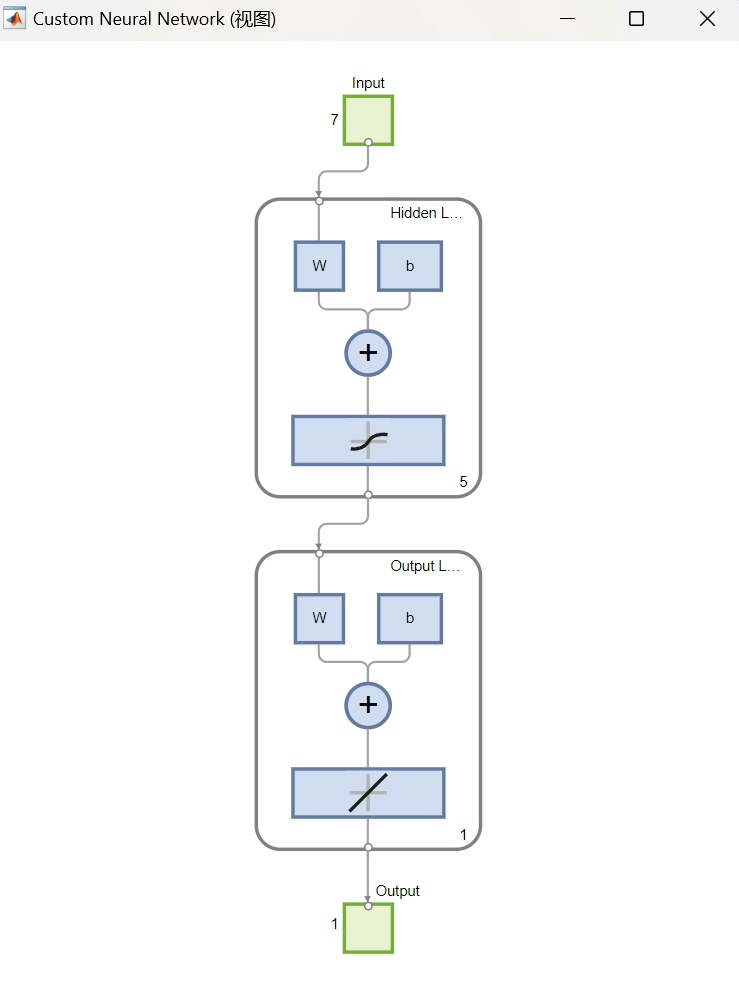
BP神经网络是一种多层前馈神经网络,通过误差反向传播算法来调整网络的权值和阈值。它由输入层、隐藏层和输出层组成,信息从前向后传递,误差从后向前传播并不断调整参数,以最小化预测值与实际值之间的误差。
三、SSA优化BP神经网络的思路
SSA算法利用其全局搜索能力,在BP神经网络的权值和阈值空间中进行搜索,寻找最优的权值和阈值组合,从而避免BP神经网络陷入局部最优解,提升预测的准确性。
四、Matlab代码实现
1. 数据准备
假设我们有一组输入数据 inputData 和对应的输出数据 outputData,将数据分为训练集和测试集。
% 加载数据
load data.mat; % 假设数据存储在data.mat文件中
inputData = data(:, 1:end - 1);
outputData = data(:, end);
% 划分训练集和测试集
trainRatio = 0.7;
trainIndex = 1:round(size(inputData, 1) * trainRatio);
testIndex = setdiff(1:size(inputData, 1), trainIndex);
inputTrain = inputData(trainIndex, :);
outputTrain = outputData(trainIndex, :);
inputTest = inputData(testIndex, :);
outputTest = outputData(testIndex, :);在这段代码中,我们首先从 data.mat 文件中加载数据,将前几列作为输入数据,最后一列作为输出数据。然后按照70%的数据作为训练集,30%作为测试集的比例进行划分。
2. 初始化BP神经网络
% 初始化BP神经网络
hiddenLayerSize = 10; % 隐藏层神经元个数
net = feedforwardnet(hiddenLayerSize);
net.trainFcn = 'trainlm'; % 训练函数,这里使用Levenberg - Marquardt算法这里我们创建了一个前馈神经网络 net,设置隐藏层神经元个数为10,并选择 trainlm 作为训练函数,trainlm 是一种收敛速度较快的训练算法。
3. 麻雀搜索算法优化BP神经网络
% 麻雀搜索算法参数设置
popSize = 30; % 种群规模
maxIter = 100; % 最大迭代次数
dim = (size(inputTrain, 2) + 1) * hiddenLayerSize + (hiddenLayerSize + 1) * size(outputTrain, 2); % 优化参数维度
lb = -1; % 下限
ub = 1; % 上限
% 初始化麻雀位置
X = lb + (ub - lb) * rand(popSize, dim);在这部分代码中,我们设置了麻雀搜索算法的参数,包括种群规模 popSize、最大迭代次数 maxIter。通过计算得到需要优化的参数维度 dim,这里的维度计算是根据输入层、隐藏层和输出层之间的连接权重以及阈值的数量得出。然后初始化麻雀的位置 X,位置在 lb 和 ub 之间随机生成。
4. 适应度函数计算
function fitness = calFitness(X, inputTrain, outputTrain, hiddenLayerSize)
[inputNum, ~] = size(inputTrain);
[outputNum, ~] = size(outputTrain);
% 提取权重和阈值
w1 = reshape(X(1:inputNum * hiddenLayerSize), inputNum, hiddenLayerSize);
b1 = X(inputNum * hiddenLayerSize + 1:inputNum * hiddenLayerSize + hiddenLayerSize);
w2 = reshape(X(inputNum * hiddenLayerSize + hiddenLayerSize + 1:inputNum * hiddenLayerSize + hiddenLayerSize + hiddenLayerSize * outputNum), hiddenLayerSize, outputNum);
b2 = X(inputNum * hiddenLayerSize + hiddenLayerSize + hiddenLayerSize * outputNum + 1:end);
% 前向传播
a1 = logsig(inputTrain * w1 + repmat(b1, inputNum, 1));
a2 = purelin(a1 * w2 + repmat(b2, inputNum, 1));
% 计算均方误差
fitness = mean((a2 - outputTrain).^2);
end上述函数 calFitness 用于计算每个麻雀位置对应的适应度值。它首先从麻雀位置 X 中提取出BP神经网络的权重 w1、w2 和阈值 b1、b2。然后进行前向传播计算得到预测值 a2,最后通过计算预测值与实际输出值 outputTrain 的均方误差作为适应度值。
5. 麻雀搜索算法主体
for t = 1:maxIter
% 计算适应度值
fitness = zeros(popSize, 1);
for i = 1:popSize
fitness(i) = calFitness(X(i, :), inputTrain, outputTrain, hiddenLayerSize);
end
% 找出当前最优解
[bestFitness, bestIndex] = min(fitness);
bestX = X(bestIndex, :);
% 发现者位置更新
r2 = rand;
if r2 < 0.8
X(1:ceil(popSize * 0.2), :) = X(1:ceil(popSize * 0.2), :) + exp(-(t + 1) / maxIter) * randn(ceil(popSize * 0.2), dim);
else
X(1:ceil(popSize * 0.2), :) = X(1:ceil(popSize * 0.2), :) + randn(ceil(popSize * 0.2), dim);
end
% 加入者位置更新
for i = ceil(popSize * 0.2) + 1:popSize
if i > popSize / 2
X(i, :) = randn * exp((bestX - X(i, :)) / i^2);
else
X(i, :) = bestX + randn * abs(X(i, :) - bestX);
end
end
% 危险预警机制
c = rand;
if c < 0.5
worstIndex = find(fitness == max(fitness));
X(worstIndex, :) = bestX + randn(size(X(worstIndex, :)));
end
end这部分是麻雀搜索算法的主体循环。每次迭代中,先计算每个麻雀位置的适应度值,找出当前最优解。然后根据发现者、加入者的不同规则更新它们的位置,并且加入危险预警机制,对适应度最差的麻雀位置进行更新,以避免算法陷入局部最优。
6. 应用优化后的参数到BP神经网络并进行预测
% 应用最优参数到BP神经网络
w1 = reshape(bestX(1:inputNum * hiddenLayerSize), inputNum, hiddenLayerSize);
b1 = bestX(inputNum * hiddenLayerSize + 1:inputNum * hiddenLayerSize + hiddenLayerSize);
w2 = reshape(bestX(inputNum * hiddenLayerSize + hiddenLayerSize + 1:inputNum * hiddenLayerSize + hiddenLayerSize + hiddenLayerSize * outputNum), hiddenLayerSize, outputNum);
b2 = bestX(inputNum * hiddenLayerSize + hiddenLayerSize + hiddenLayerSize * outputNum + 1:end);
net.IW{1, 1} = w1;
net.b{1} = b1;
net.LW{2, 1} = w2;
net.b{2} = b2;
% 训练和预测
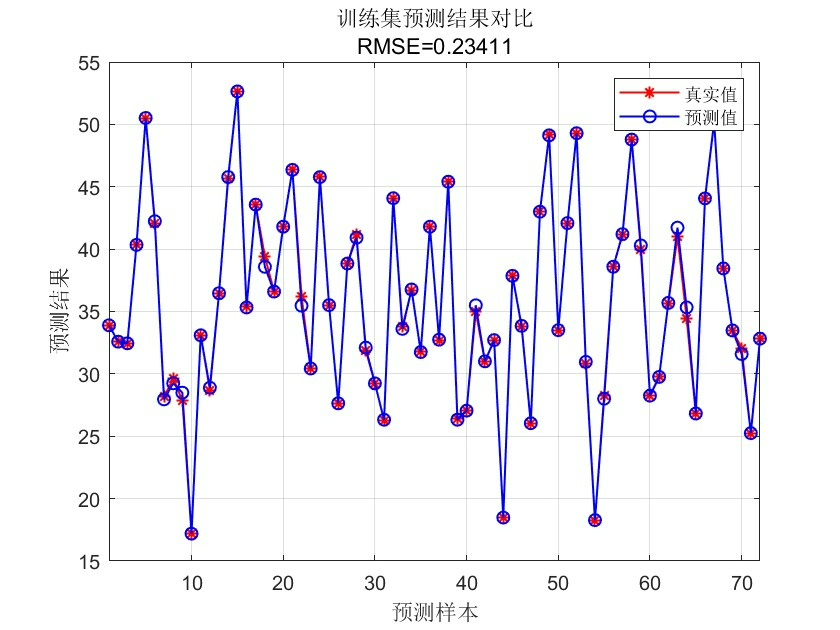
[net, ~] = train(net, inputTrain', outputTrain');
outputPredict = net(inputTest');
% 计算预测误差
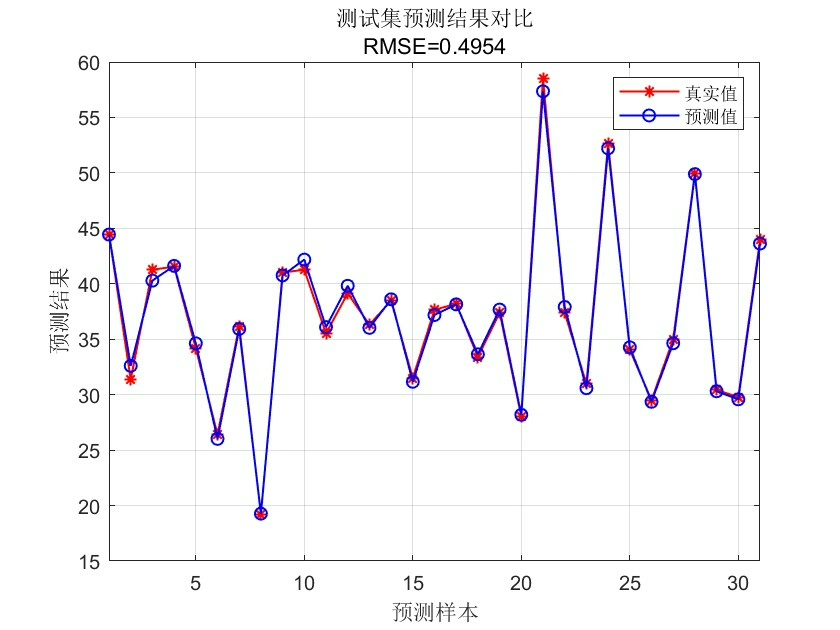
mseError = mean((outputPredict - outputTest').^2);最后,我们将通过麻雀搜索算法得到的最优权重和阈值应用到BP神经网络中,对训练集进行训练,然后对测试集进行预测,并计算预测的均方误差 mseError 来评估模型的性能。
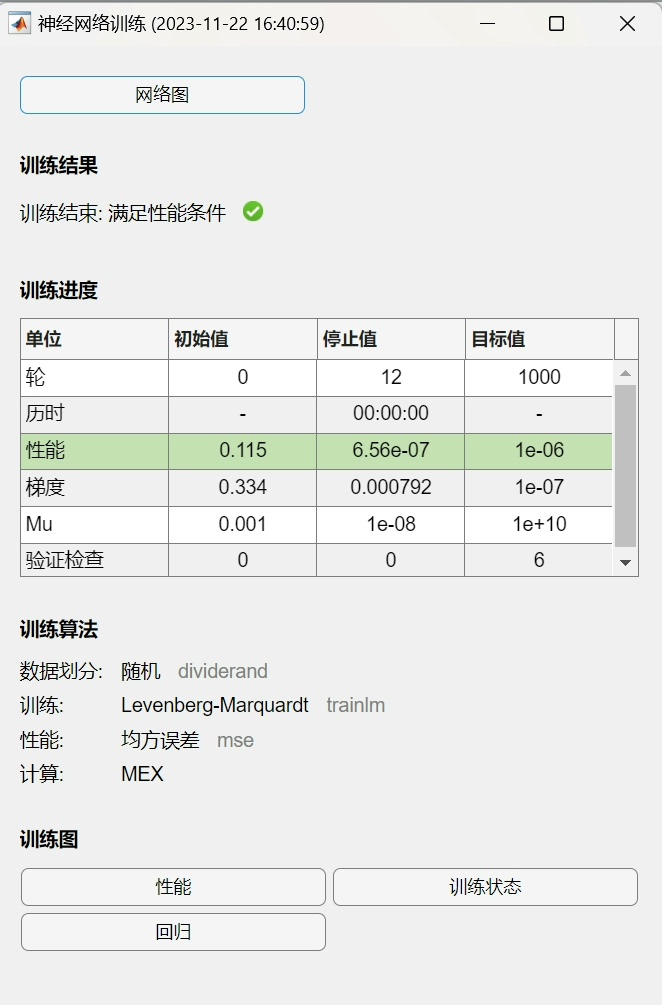
基于麻雀搜索算法优化BP神经网络(SSA-BP)的数据回归预测 SSA-BP回归 matlab代码 注:暂无Matlab版本要求 -- 推荐 2018B 版本及以上
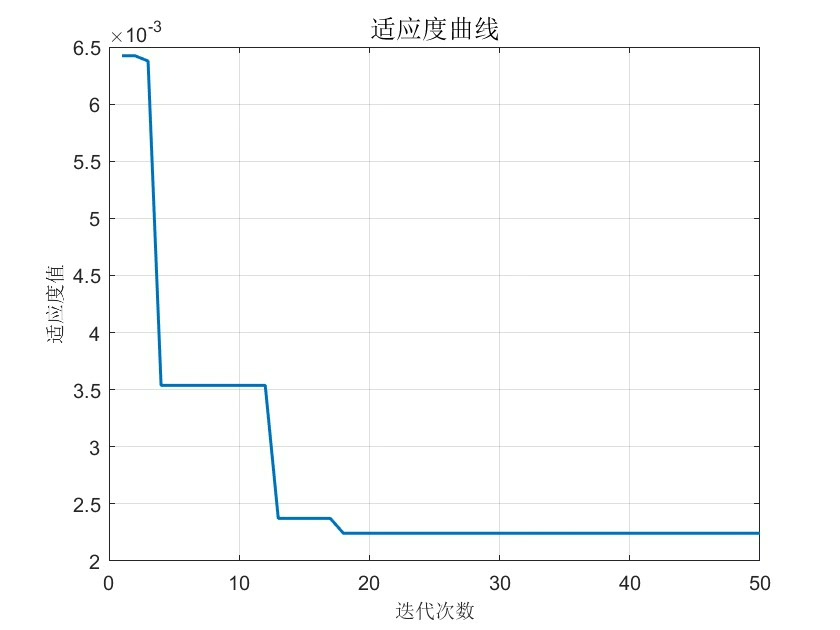
通过上述步骤和Matlab代码,我们实现了基于麻雀搜索算法优化BP神经网络的数据回归预测。这种结合的方法能够在许多实际数据预测场景中发挥出色的性能,为数据分析和预测提供了更强大的工具。
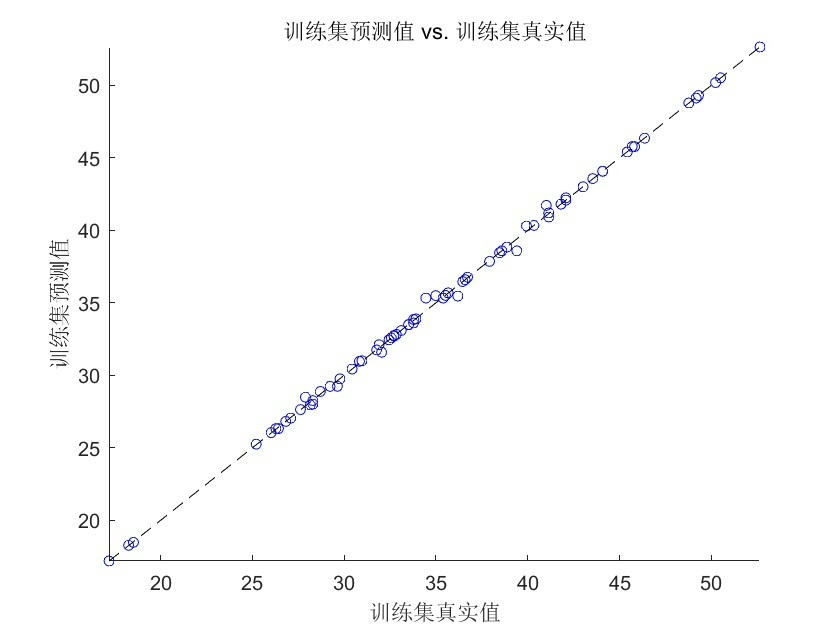
希望本文的介绍和代码示例能帮助你理解和应用SSA - BP模型进行数据回归预测。如果你在实践中有任何问题,欢迎在评论区留言交流。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)