神经网络优化:BP、RBF 与智能算法的碰撞
BP、RBF神经网络的数据预测和分类,可用粒子群PSO、遗传算法GA、萤火虫算法、模拟退火算法对BP进行优化,。在数据预测和分类领域,神经网络是绝对的明星。今天咱们就来唠唠 BP 和 RBF 神经网络,以及如何用粒子群 PSO、遗传算法 GA、萤火虫算法、模拟退火算法这些智能算法来优化 BP 神经网络。
BP、RBF神经网络的数据预测和分类,可用粒子群PSO、遗传算法GA、萤火虫算法、模拟退火算法对BP进行优化,。
在数据预测和分类领域,神经网络是绝对的明星。今天咱们就来唠唠 BP 和 RBF 神经网络,以及如何用粒子群 PSO、遗传算法 GA、萤火虫算法、模拟退火算法这些智能算法来优化 BP 神经网络。
BP 神经网络
BP(Back Propagation)神经网络,也就是反向传播神经网络,是一种按照误差逆向传播算法训练的多层前馈神经网络。它就像一个黑盒子,输入数据,经过层层神经元处理,最后输出结果。
下面是一段简单的 Python 实现 BP 神经网络的代码片段(使用 Keras 库):
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 生成一些随机数据作为示例
X = np.random.rand(100, 5)
y = np.random.randint(0, 2, size=(100, 1))
model = Sequential()
model.add(Dense(10, input_dim=5, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, epochs=100, batch_size=10)这段代码里,首先导入了必要的库。然后创建了一些随机的输入数据 X 和标签 y。接着,使用 Sequential 模型搭建了一个简单的 BP 神经网络,有一个包含 10 个神经元的隐藏层,激活函数是 relu,输出层是一个神经元,激活函数为 sigmoid,适合二分类问题。之后,用 binary_crossentropy 作为损失函数,adam 优化器来编译模型,并通过 fit 方法进行训练。
RBF 神经网络
RBF(Radial Basis Function)神经网络则是一种局部逼近网络。它的神经元激活函数是径向基函数,最常用的是高斯函数。相比 BP 神经网络,RBF 神经网络的学习速度更快,而且具有较好的泛化能力。
这里简单写个 RBF 神经网络的 Python 实现思路代码(假设使用自定义函数实现,非特定库):
import numpy as np
def gaussian(x, c, sigma):
return np.exp(-np.linalg.norm(x - c) ** 2 / (2 * sigma ** 2))
# 假设输入数据 X 和中心 c 以及宽度 sigma 都已定义
X = np.random.rand(10, 3)
c = np.random.rand(5, 3)
sigma = np.ones(5)
hidden_layer_output = np.zeros((X.shape[0], c.shape[0]))
for i in range(X.shape[0]):
for j in range(c.shape[0]):
hidden_layer_output[i, j] = gaussian(X[i], c[j], sigma[j])
# 假设权重 w 已定义
w = np.random.rand(c.shape[0], 1)
output = np.dot(hidden_layer_output, w)上述代码中,首先定义了高斯函数 gaussian,这是 RBF 神经网络的核心。接着假设有输入数据 X,中心 c 和宽度 sigma,计算隐藏层的输出。最后通过与权重 w 相乘得到最终输出。
智能算法优化 BP 神经网络
粒子群算法(PSO)
PSO 是一种基于群体智能的优化算法,模拟鸟群觅食行为。粒子在解空间中飞行,通过不断调整自己的速度和位置来寻找最优解。
BP、RBF神经网络的数据预测和分类,可用粒子群PSO、遗传算法GA、萤火虫算法、模拟退火算法对BP进行优化,。
优化 BP 神经网络时,PSO 可以用来调整神经网络的权重。大致思路是将每个粒子的位置表示为 BP 神经网络的一组权重,通过计算粒子位置对应的神经网络的误差来确定粒子的适应度。
下面是一个简化的 PSO 优化 BP 神经网络权重的代码框架:
import numpy as np
# BP 神经网络的误差计算函数
def bp_error(weights, X, y):
# 这里省略实际的 BP 网络搭建和前向传播计算,仅示意返回误差
return np.random.rand()
# PSO 参数
n_particles = 50
n_dimensions = 10 # 假设 BP 网络权重数量为 10
c1 = 1.5
c2 = 1.5
w = 0.7
max_iter = 100
# 初始化粒子位置和速度
particles = np.random.rand(n_particles, n_dimensions)
velocities = np.random.rand(n_particles, n_dimensions)
for _ in range(max_iter):
for i in range(n_particles):
fitness = bp_error(particles[i], X, y)
if fitness < best_fitness[i]:
best_fitness[i] = fitness
best_position[i] = particles[i]
global_best_index = np.argmin(best_fitness)
global_best = best_position[global_best_index]
for i in range(n_particles):
r1 = np.random.rand(n_dimensions)
r2 = np.random.rand(n_dimensions)
velocities[i] = w * velocities[i] + c1 * r1 * (best_position[i] - particles[i]) + c2 * r2 * (
global_best - particles[i])
particles[i] = particles[i] + velocities[i]这段代码里,先定义了一个 bp_error 函数来计算 BP 神经网络基于当前权重的误差。然后初始化粒子群的位置和速度,在每次迭代中,计算每个粒子的适应度(误差),更新个体最优和全局最优位置,再根据 PSO 公式更新粒子的速度和位置。
遗传算法(GA)
GA 则是借鉴生物进化过程中的遗传、变异、选择等机制。在优化 BP 神经网络时,将 BP 神经网络的权重编码成染色体,通过遗传操作(交叉、变异)来生成新的权重组合,选择适应度高(误差小)的染色体保留下来。
以下是 GA 优化 BP 神经网络权重的代码框架:
import numpy as np
# BP 神经网络的误差计算函数
def bp_error(weights, X, y):
# 这里省略实际的 BP 网络搭建和前向传播计算,仅示意返回误差
return np.random.rand()
# GA 参数
population_size = 50
chromosome_length = 10 # 假设 BP 网络权重数量为 10
mutation_rate = 0.01
max_generations = 100
# 初始化种群
population = np.random.rand(population_size, chromosome_length)
for generation in range(max_generations):
fitness = np.array([bp_error(chromosome, X, y) for chromosome in population])
selection_prob = 1 / fitness
selection_prob = selection_prob / np.sum(selection_prob)
new_population = np.zeros((population_size, chromosome_length))
for i in range(population_size):
parent1_index = np.random.choice(population_size, p=selection_prob)
parent2_index = np.random.choice(population_size, p=selection_prob)
crossover_point = np.random.randint(1, chromosome_length - 1)
new_population[i, :crossover_point] = population[parent1_index, :crossover_point]
new_population[i, crossover_point:] = population[parent2_index, crossover_point:]
if np.random.rand() < mutation_rate:
mutation_index = np.random.randint(chromosome_length)
new_population[i, mutation_index] = np.random.rand()
population = new_population这段代码先定义了 bp_error 函数计算误差。初始化种群后,在每一代中,计算每个染色体(权重组合)的适应度,根据适应度计算选择概率进行选择操作,通过交叉和变异生成新的种群。
萤火虫算法和模拟退火算法
萤火虫算法模拟萤火虫的发光和吸引行为,发光强度与目标函数值相关,通过萤火虫之间的相互吸引来寻找最优解。模拟退火算法则是基于物理中固体退火的原理,在搜索最优解时,以一定概率接受较差的解,随着温度降低,接受较差解的概率逐渐减小,最终收敛到全局最优解。这两种算法同样可以用于优化 BP 神经网络的权重,思路与 PSO 和 GA 类似,都是通过不断搜索权重空间来找到使误差最小的权重组合。
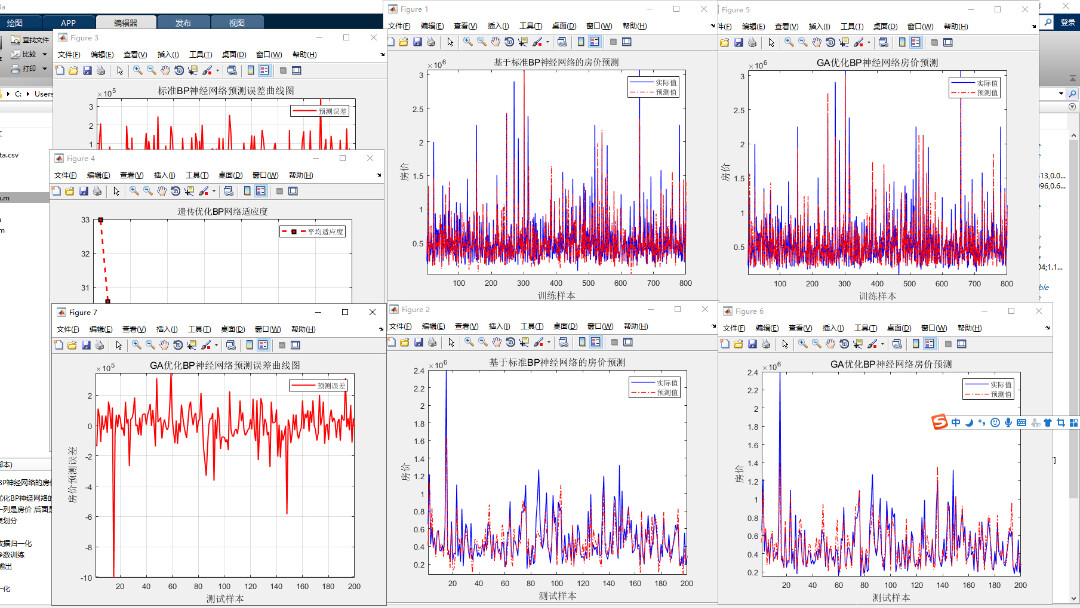
总之,BP 和 RBF 神经网络在数据预测和分类上各有优势,而 PSO、GA 等智能算法为优化 BP 神经网络提供了强大的工具,通过不断尝试和调整,能够在实际应用中取得更好的效果。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)