李沐动手学深度学习笔记(3)---数据增强与模型优化
数据增广通过变形数据来获取多样性从而使模型泛化性能更好常见方法翻转、切割、变色等等微调通过使用在大数据集上得到的预训练好的模型来初始化模型权重来完成精度提升,相当于使用了先验知识,也相当于将模型初始化在一个距离最优解附近的一个“模型初始化”方法预训练模型质量很重要(比如一般选择 ImageNet 上预训练的 ResNet50 等)微调通常速度更快、精度更高。
1. 数据增广
数据增广就是在不增加真实数据量的情况下,通过对现有样本做随机变换来“制造”更多新样本,从而让模型见到更多变化,提高泛化能力。
对已有数据做随机变换,生成新的训练样本。
比如图像:
- 翻转
- 旋转
- 裁剪
- 加噪声
- 亮度调整
- Mixup / CutMix
这些都是在样本数量不变的情况下,创造新的“变体”。
目的:提高泛化能力、减少过拟合
数据增强(Data Augmentation)
凡是能提高数据质量、数量、信息量的方法,都叫数据增强
包括但不限于:
- 数据增广(Augmentation)
对样本随机变换增加多样性。
- 数据清洗(Cleaning)
- 去除重复样本
- 修正错误标签
- 归一化 / 标准化某些特征
- 数据合成(Data Synthesis)
- GAN 生成新样本
- Diffusion Model 生成数据
- 用模拟器(仿真环境)造数据
- 合成语音 / 合成图像 / 合成文本
- 数据标注质量提升(Label Enhancement)
- 半监督学习
- 错误标签修正
- pseudo-labeling
- active learning
- 特征工程(Feature Engineering)
- 特征提取、降维、特征组合
- 对非深度学习任务非常常见
- 对少样本类别的样本扩充(Balance Enhancement)
比如类别不平衡时用 Oversampling 技术:
- SMOTE / ADASYN
- Random Oversampling
- Class-wise augmentation
深度学习里“数据增强=数据增广”
大型数据集是成功应用深度神经网络的先决条件。 以图像增广为例,在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。 此外,应用图像增广的原因是,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
在一个已有数据集,通过数据变换,使得有更多的多样性
- 在语言里加入各种不同的背景噪音
- 改变图片的颜色、形状、位置、变形等待属性

使用增强数据训练
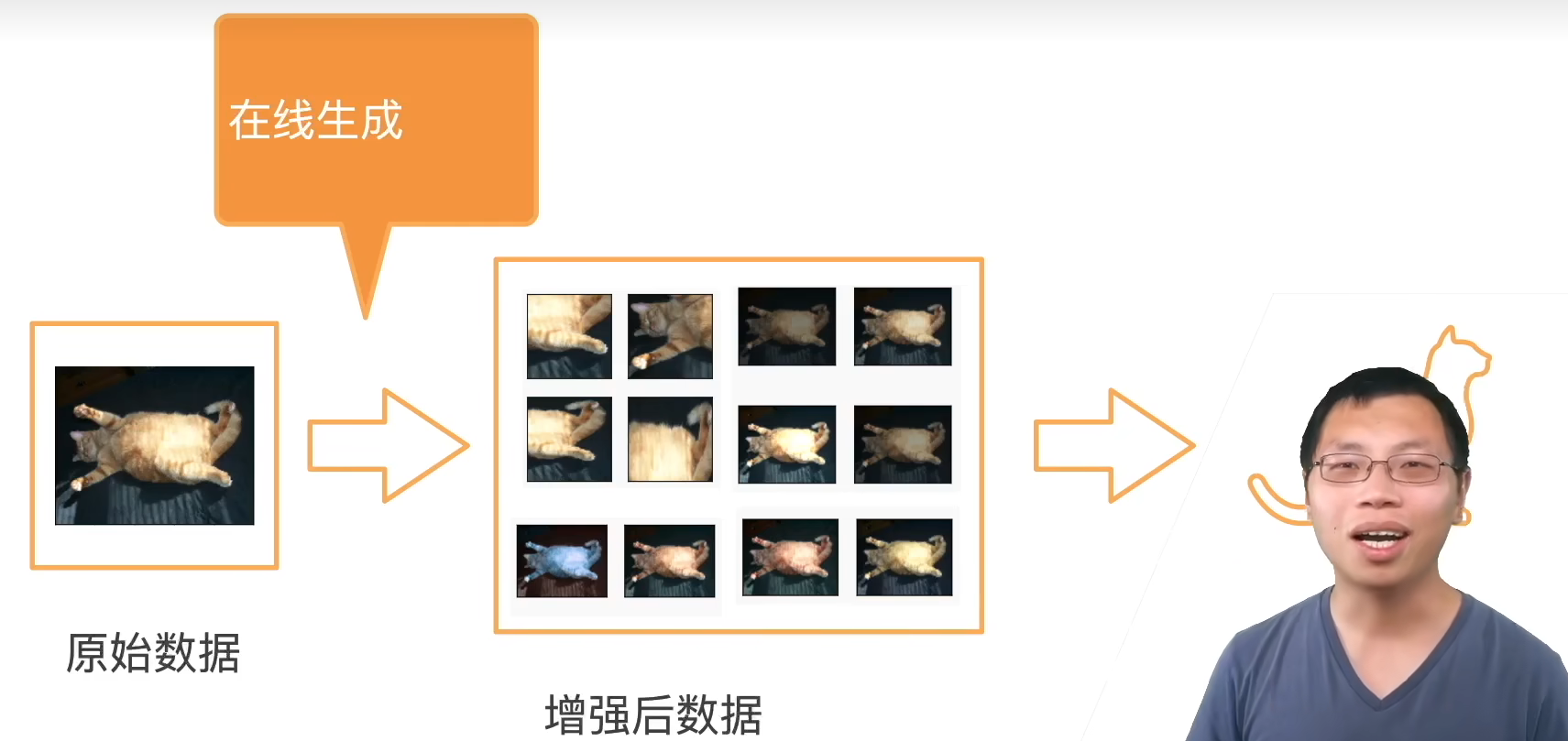

在训练中随机在线生成增强数据,在测试时不进行增强操作。
- 上下、左右翻转(Flip):
torchvision.transforms.RandomHorizontalFlip()
相应操作要符合语义解释
- 切割,从图片中切割一块,变成固定形状(由 CNN 特性决定),所以还存在拉伸等(Crop)
- 随机高宽比(e.g.[3/4,4/3])
- 随机大小(e.g.[80%,100%])
- 随机位置
- 颜色(Color)
- 色调
- 饱和度
- 明亮度(e.g.[0.5,1.5])

类似于对图片做 PS 的变换
总结
- 数据增广通过变形数据来获取多样性从而使模型泛化性能更好
- 常见方法翻转、切割、变色等等
代码实现
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open('/root/autodl-tmp/01_Data/02_cat.jpg') # 读取图片
d2l.plt.imshow(img) # 显示图片

# img: 输入PIL图像;aug: 单个增广操作;num_rows/num_cols: 展示网格行列;scale: 画布缩放
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
# 生成 num_rows * num_cols 个增广结果
Y = [aug(img) for _ in range(num_rows * num_cols)] # 每次调用 aug(img) 是独立随机操作
# 按 num_rows 行、num_cols 列显示
d2l.show_images(Y, num_rows, num_cols, scale=scale)
# 左右翻转(默认 p=0.5)
apply(img, torchvision.transforms.RandomHorizontalFlip())

apply(img, torchvision.transforms.RandomVerticalFlip()) # 上下随机翻转

- 裁剪
# 随机剪裁并缩放:输出固定 200x200
# scale=(0.1,1): 随机裁剪区域的面积占原图 10%~100%
# ratio=(0.5,2): ratio是高宽比 = 裁剪后高度/裁剪后宽度。裁剪区域高宽比在 0.5~2 之间(偏宽 到 偏高)
# 先随机选满足条件的区域裁剪,再插值缩放到 200x200
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200),
scale=(0.1, 1),
ratio=(0.5, 2)
)
# 用前面定义的 apply 函数展示 2×4 个不同随机裁剪结果
apply(img, shape_aug)

- 更改亮度
brightness、对比度contrast、饱和度saturation、色调hue
# 随机更改图像的亮度:brightness=0.5 表示亮度因子在 [0.5, 1.5] 内随机;其他参数为0表示不变化
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, # 仅调整亮度
contrast=0, # 不改对比度
saturation=0, # 不改饱和度
hue=0 # 不改色调
))
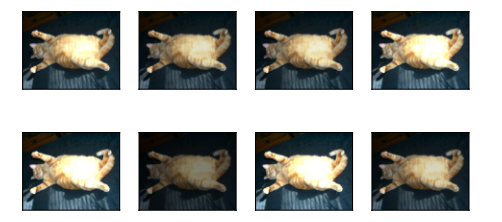
# 随机改变色调:hue=0.5 表示在 [-0.5, 0.5] 范围随机偏移色调;其他为0表示不调整
apply(img, torchvision.transforms.ColorJitter(
brightness=0, # 不改亮度
contrast=0, # 不改对比度
saturation=0, # 不改饱和度
hue=0.5 # 随机色调偏移(值域 -0.5 到 0.5)
))

# 随机更改图像的亮度(brightness)、对比度(constrast)、饱和度(saturation)和色调(hue)
color_aug = torchvision.transforms.ColorJitter(brightness=0.5,contrast=0.5,saturation=0.5,hue=0.5)
apply(img,color_aug)

- 可结合多种增广方法
torchvision.transforms.Compose([aug1, aug2, aug3, aug4])
# 组合增广:先水平翻转(随机 p=0.5),再颜色抖动(前面定义的 color_aug),再随机裁剪缩放(shape_aug)
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), # 随机左右翻转
color_aug, # 颜色增广
shape_aug # 随机裁剪+缩放到(200,200)
])
apply(img, augs)

# 下载 CIFAR-10 训练集(若未存在会自动下载)
all_images = torchvision.datasets.CIFAR10(
train=True, # 使用训练集
root='/root/autodl-tmp/01_Data/03_CIFAR10',
download=True # 如本地无数据则下载
)
# 显示前 32 张图片:4 行 × 8 列,scale 控制整体缩放
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8)

- 指定训练、测试所用增广方式
# 训练集:随机左右翻转 (p=0.5) + 转成张量
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), # 数据增广:缓解过拟合
torchvision.transforms.ToTensor() # PIL -> Tensor,像素归一化到[0,1]
])
# 测试集:不做随机操作,只做格式转换,保证评估稳定
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
- 定义加载数据集函数
# 定义一个辅助函数:读取 CIFAR-10 并应用增广
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(
root='/root/autodl-tmp/01_Data/03_CIFAR10', # 数据根目录
train=is_train, # True=训练集,False=测试集
transform=augs, # 图像增广/预处理管道
download=True # 若本地无数据则自动下载
)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size, # 每批样本数
shuffle=is_train, # 训练集打乱,测试集不打乱
num_workers=4
)
return dataloader
- 定义训练函数
# 单批训练(支持多 GPU)
def train_batch_ch13(net, X, y, loss, trainer, devices):
# 如果输入是 list(例如多输入网络),逐个搬到主设备
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train() # 切换到训练模式(启用 Dropout/BN 的训练行为)
trainer.zero_grad() # 清空上一批次的梯度
pred = net(X) # 前向传播
l = loss(pred, y) # 计算损失(reduction='none')
l.sum().backward() # 反向传播(总损失求和再回传)
trainer.step() # 更新参数
train_loss_sum = l.sum() # 当前批次总损失
train_acc_sum = d2l.accuracy(pred, y) # 当前批次准确率(样本平均)
return train_loss_sum, train_acc_sum
# 整体训练循环(含可视化与测试评估)
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter) # 计时器与每 epoch 的批次数
animator = d2l.Animator(
xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc']
)
net = nn.DataParallel(net, device_ids=devices).to(devices[0]) # 包装为多 GPU 并放到主设备
for epoch in range(num_epochs):
metric = d2l.Accumulator(4) # 累计器:[loss_sum, acc_sum, 样本数, 样本数]
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel()) # labels.shape[0] == batch_size
timer.stop()
# 每个 epoch 取 5 次点更新曲线(或最后一次)
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(
epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3], None)
)
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter) # 整个测试集评估
animator.add(epoch + 1, (None, None, test_acc))
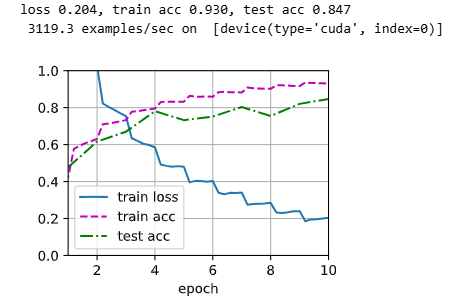
print(f'loss {metric[0] / metric[2]:.3f}, train acc'
f' {metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f' {metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f' {str(devices)}')
- 定义网络、训练
# 使用图像增广训练模型(CIFAR-10 + ResNet18)
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
# devices: 可用 GPU 列表(无 GPU 时返回 [cpu])
# net: 输出类别数=10,输入通道=3 的 ResNet18
def init_weights(m):
# 仅对 Linear 和 Conv2d 层使用 Xavier 均匀初始化(加速收敛)
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights) # 递归调用,对网络中所有子模块执行初始化
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size) # 训练数据加载器
test_iter = load_cifar10(False, test_augs, batch_size) # 测试数据加载器
loss = nn.CrossEntropyLoss(reduction='none') # 返回逐样本损失,后续自行求和
# Adam:自适应学习率优化器,对 lr 不太敏感,收敛较稳定
trainer = torch.optim.Adam(net.parameters(), lr=lr)
# 训练 10 个 epoch
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
train_with_data_aug(train_augs, test_augs, net)
2. 微调
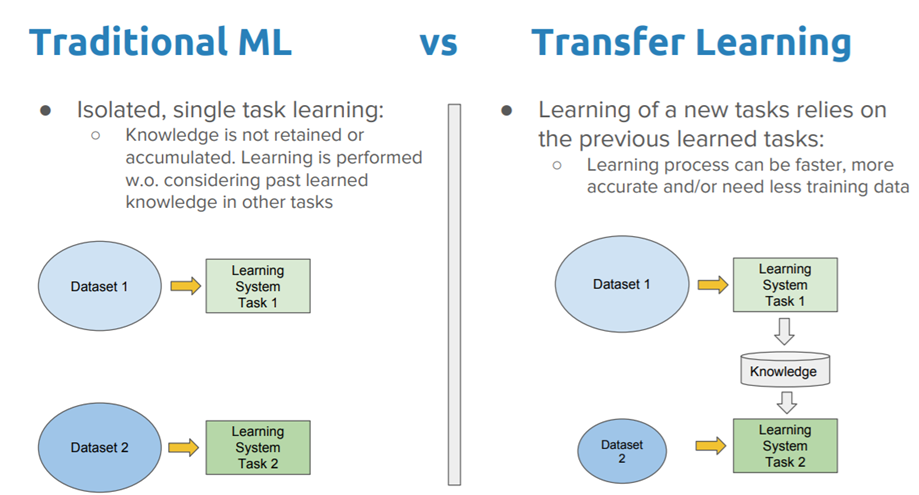
为什么需要微调/迁移学习(Fine-tuning / Transfer Learning)
在实际工程应用中,需要深度学习模型对特定的任务具有良好的泛化性,如果从头训练该模型,则需要大量该任务专用的数据集才能使模型收敛到一个可接受的结果。但是这个体量的专用数据集的标注成本也会很高。
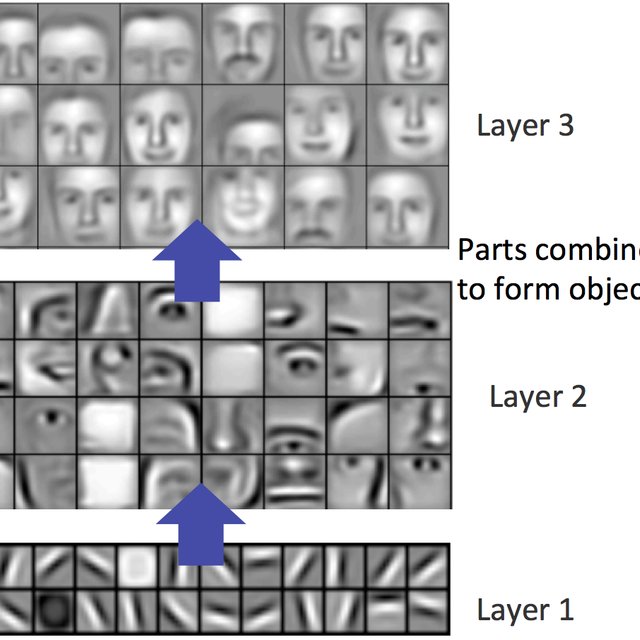
另一方面,例如在图像识别领域,已有许多在 ImageNet 等大规模数据集上训练好的模型,其靠近底层的神经元,经训练已具备基本的图像特征提取能力,这有助于识别边缘、纹理、形状和对象组合。我们可以在此模型基础上,使用相对少量的专有样本再训练,就可以得到比较好的结果。
网络架构
一个神经网络通常可以分成两块
神经网络 = 特征抽取器(Feature Extractor) + 分类器(Linear Classifier)
- 特征抽取将原始像素变成容易线性分割的特征
- 线性分类器来做分类
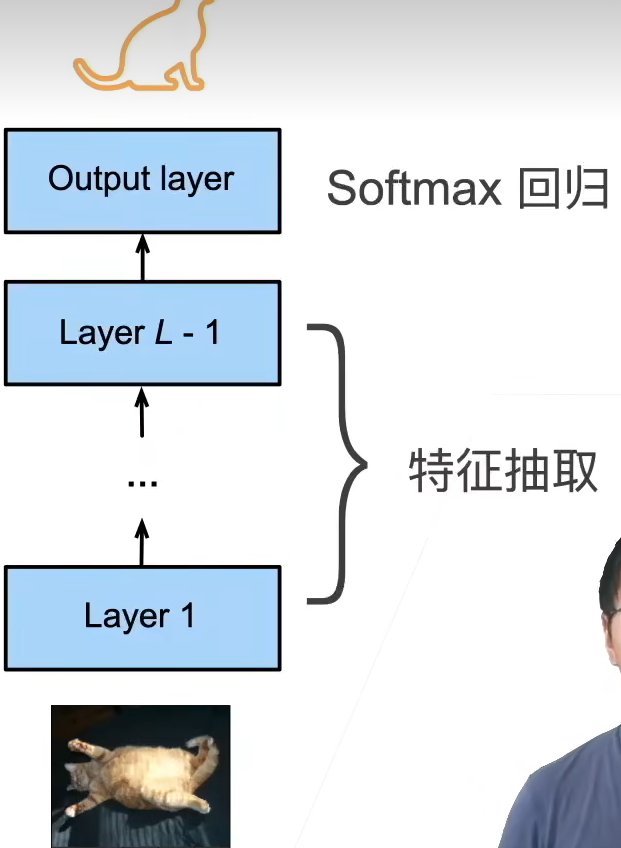
我们不会从零训练 CNN,因为:模型已经能学到通用的特征(如边缘、纹理)最后只需要换分类器(Linear)就能适配你的新任务
所以微调主要是:
- 冻结前面一大堆层(特征抽取器)
- 只训练最后一层(分类器)
这就是 迁移学习 最典型的方式
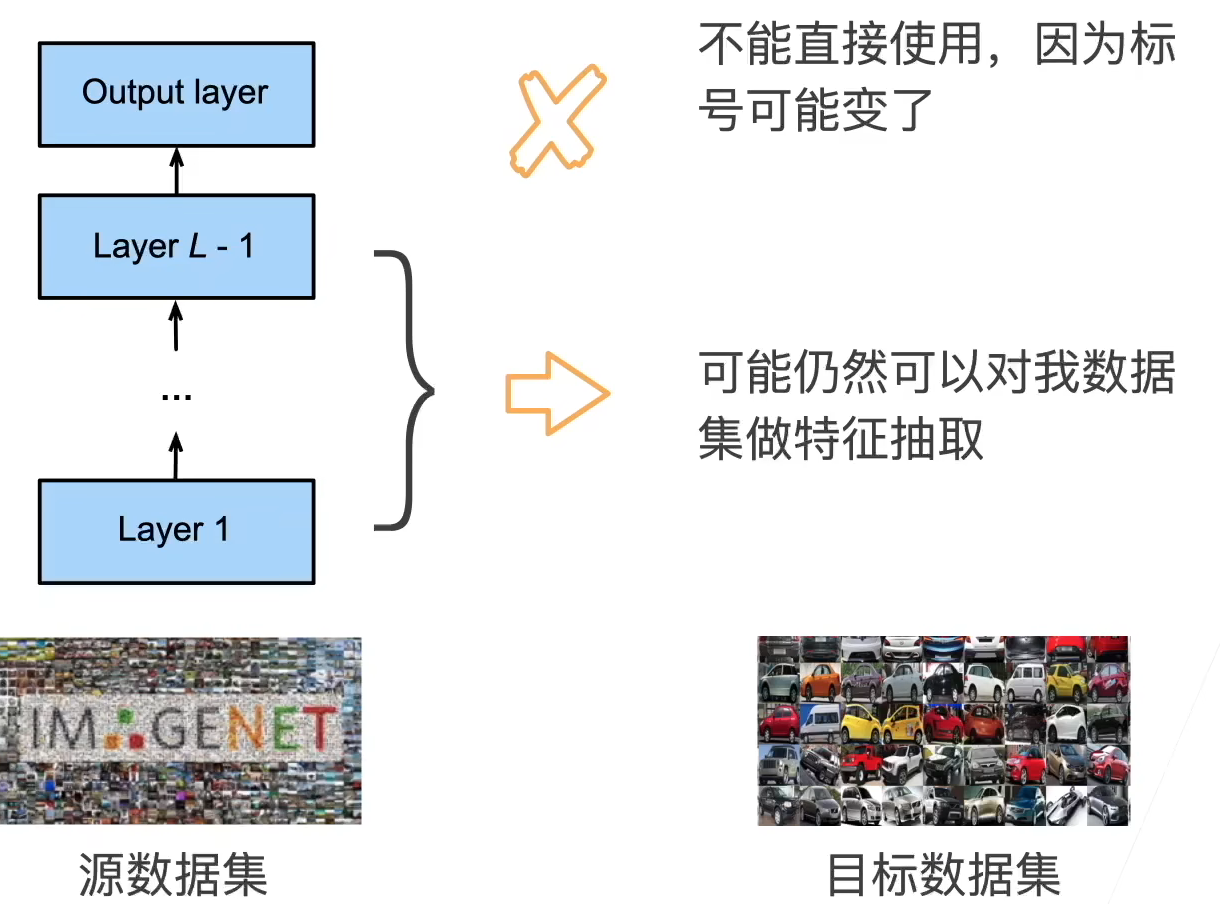
微调
训练过程
权重初始化:
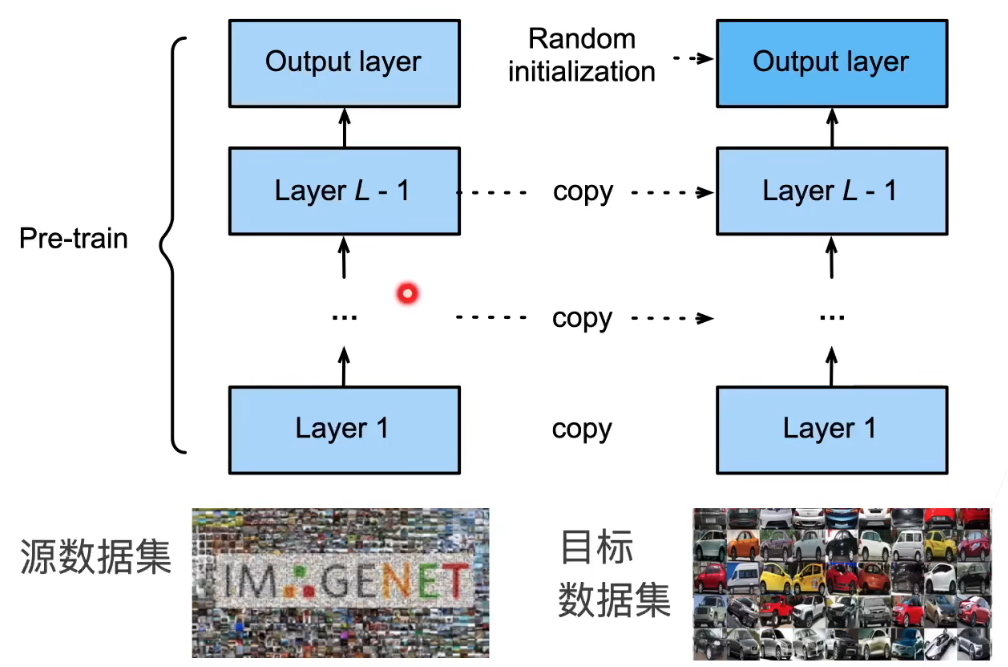
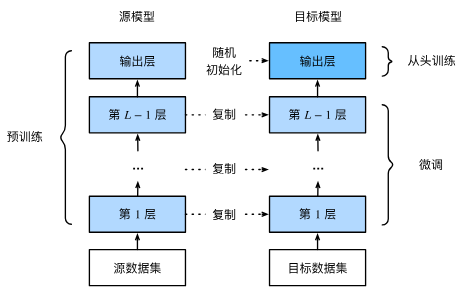
预训练 → 复制模型参数 → 替换输出层 → 微调全部或部分层 → 使用更强正则 → 小学习率训练
- 在源数据集(例如 ImageNet 数据集)上预训练神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
- 向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
- 是一个目标数据集上的正常训练任务,但使用更强的正则化
- 使用更小的学习率
- 使用更少的数据迭代
- 使用更少的 epoch
- 源数据集远复杂于目标数据(例如相差 10 倍以上),通常微调效果更好
常用技术
重用分类器权重
- 源数据集可能也有目标数据中的部分标号
- 可以使用预训练好模型分类器中对应标号对应的向量来做初始化
固定一些层
- 神经网络通常学习有层次的特征表示
- 低层次的特征更加通用
- 高层次的特征则跟数据集相关
- 可以固定底部一些层的参数,不参与更新
- 更强的正则
总结
- 微调通过使用在大数据集上得到的预训练好的模型来初始化模型权重来完成精度提升,相当于使用了先验知识,也相当于将模型初始化在一个距离最优解附近的一个“模型初始化”方法
- 预训练模型质量很重要(比如一般选择 ImageNet 上预训练的 ResNet50 等)
- 微调通常速度更快、精度更高
代码实现
- 载入数据集
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
data_dir = '/root/autodl-tmp/data/hotdog'
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir,'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir,'test'))
# 图片的大小和纵横比各有不同
hotdogs = [train_imgs[i][0] for i in range(8)]
print(train_imgs[0]) # 图片和标签,合为一个元组
print(train_imgs[0][0]) # 元组第一个元素为图片
# 逆序负索引取数据集中最后8个样本的图像张量作为“非热狗”示例
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
# 合并前8个热狗与后8个非热狗并按2行8列可视化,scale控制显示大小
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)

- 数据增广
# 数据增广
# normalize: 使用 ImageNet 的通道均值与标准差做标准化,使输入分布贴合预训练 ResNet 的假设
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], # RGB 三个通道的均值
[0.229, 0.224, 0.225]) # RGB 三个通道的标准差
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224), # 随机裁剪原图的一个区域并缩放到 224x224,增强尺度/视角变化
torchvision.transforms.RandomHorizontalFlip(), #以 50% 概率水平翻转,提升模型对方向的鲁棒性
torchvision.transforms.ToTensor(), # PIL / numpy 转为张量并把像素压到 [0,1]
normalize #按通道标准化
])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256), # 等比例缩放,使较短边达到 256(或根据实现)
torchvision.transforms.CenterCrop(224), # 中心裁剪为 224x224,和训练输入尺寸一致
torchvision.transforms.ToTensor(),
normalize
])
- 载入预训练模型
# 定义和初始化模型
# 加载在 ImageNet 上预训练的 ResNet18,后续仅替换最后一层做二分类
pretrained_net = torchvision.models.resnet18(pretrained=True) # pretrained=True 表示使用已训练好的权重
# 查看原始最后全连接层结构(输入特征数 -> 1000 类),Notebook 中直接访问属性会打印其定义
pretrained_net.fc
输出:
Linear(in_features=512, out_features=1000, bias=True)
- 载入并初始化 fine-tune 模型
finetune_net = torchvision.models.resnet18(pretrained=True) # 载入预训练权重,保留前面特征提取层
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) # 替换最后全连接层,输出改为2类
nn.init.xavier_uniform_(finetune_net.fc.weight) # 仅重新初始化新加层的权重,保持其它层的预训练参数
输出:
Parameter containing:
tensor([[ 0.0340, -0.0700, 0.0392, ..., -0.0728, -0.0040, -0.0638],
[ 0.1028, 0.0371, 0.0316, ..., 0.0643, 0.0994, 0.0082]],
requires_grad=True)
- 微调模型
定义函数 train_fine_tuning:参数
net:要微调的模型
learning_rate:基础学习率
batch_size:批大小
num_epochs:训练轮数
param_group:是否对最后一层使用单独(更大)学习率
构建 train_iter:
使用 ImageFolder 读取训练集目录 data_dir/train
应用训练时的数据增广 transform=train_augs
shuffle=True 打乱样本
构建 test_iter:
使用 ImageFolder 读取测试集目录 data_dir/test
使用确定性预处理 transform=test_augs
不打乱
devices = d2l.try_all_gpus():
返回所有可用 GPU(若无则回退到 CPU 列表)
loss = nn.CrossEntropyLoss(reduction="none"):
使用交叉熵做分类损失
reduction="none" 保留每个样本的单独损失(方便自定义统计)
分参数组(if param_group 为 True):
params_except_fc:筛掉最后一层 fc.weight 与 fc.bias,其余参数使用基础学习率
最后一层 net.fc.parameters() 使用 10 倍学习率加速适配新任务
weight_decay=0.001:L2 正则,抑制过拟合
优化器:torch.optim.SGD,两个参数组
若 param_group=False:
所有参数统一一个学习率(适用于从头训练或不区分层时)
调用 d2l.train_ch13(...):
封装好的训练循环:负责前向、反向、评估、可视化(如果有)
简要目的:
通过预训练模型的特征提取层 + 新的最后一层(更高学习率),加速适配小数据的二分类任务,同时用数据增广与正则减轻过拟合
# 微调训练函数:可选择仅对最后一层使用更大学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5, param_group=True):
# 构建带增广的训练集迭代器
train_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
# 构建测试集迭代器(仅确定性预处理)
test_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
# 选择所有可用 GPU(无则退回 CPU)
devices = d2l.try_all_gpus()
# 使用交叉熵作为分类损失;reduction="none" 便于后续自行处理样本损失
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
# 为除最后一层外的参数使用基础学习率;最后一层用 10 倍学习率加速适配新任务
params_except_fc = [
p for name, p in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]
]
trainer = torch.optim.SGD([
{'params': params_except_fc},
{'params': net.fc.parameters(), 'lr': learning_rate * 10}
], lr=learning_rate, weight_decay=0.001) # weight_decay=0.001 作为 L2 正则抑制过拟合
else:
# 所有层统一学习率(从头训练或不区分层时使用)
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.001)
# 调用 d2l 提供的通用训练例程
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
- 开始微调
# 使用较小的学习率
train_fine_tuning(finetune_net,5e-5)

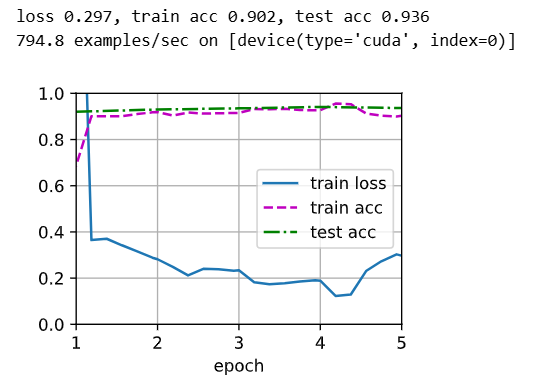
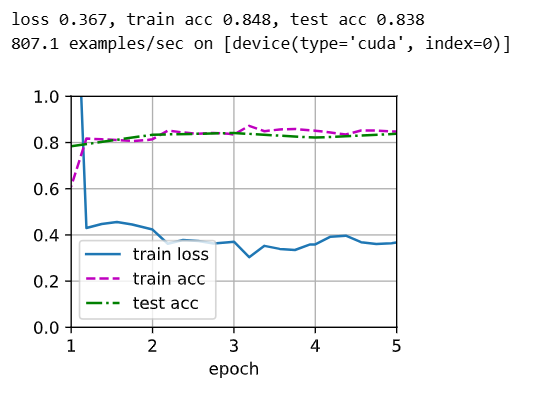
# 为了进行比较,所有模型参数初始化为随机值
scratch_net = torchvision.models.resnet18() # 这里没有pretrained=True,没有拿预训练的参数
scratch_net.fc = nn.Linear(scratch_net.fc.in_features,2)
train_fine_tuning(scratch_net,5e-4,param_group=False) # param_group=False使得所有层的参数都为默认的学习率
3. kaggle竞赛
Kaggle_CIFAR10
CIFAR-10数据集
之前几节中,我们一直在使用深度学习框架的高级 API 直接获取张量格式的图像数据集。 但是在实践中,图像数据集通常以图像文件的形式出现。 在本节中,我们将从原始图像文件开始,然后逐步组织、读取并将它们转换为张量格式。
我们将数据划分训练集、验证集和测试集。在训练集上训练模型,在验证集上评估模型,一旦找到的最佳的参数,就在测试集上最后测试一次,测试集上的误差作为泛化误差的近似。
比赛数据集分为训练集和测试集,其中训练集包含 50000 张、测试集包含 300000 张图像。 在测试集中,10000 张图像将被用于评估,而剩下的 290000 张图像将不会被进行评估,包含它们只是为了防止手动标记测试集并提交标记结果。 两个数据集中的图像都是 png 格式,高度和宽度均为 32 像素并有三个颜色通道(RGB)。 这些图片共涵盖 10 个类别:飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车
比赛的网址是:https://www.kaggle.com/c/cifar-10
代码实现
- 引入包&下载数据
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
# 我们提供包含前1000个训练图像和5个随即测试图像的数据集的小规模样本
# cifar10_tiny是cifar10中每一个类把前面一千个训练图片拿出来,测试是每一个类挑五个图片
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip',
'2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
demo = True
if demo:
# 直接使用已下载的数据,不需要再下载
data_dir = '/root/autodl-tmp/data/cifar10_tiny'
else:
data_dir = '/root/autodl-tmp/data/cifar-10'
数据集结构:
- …/data/cifar-10/train/[1-50000].png
- …/data/cifar-10/test/[1-300000].png
- …/data/cifar-10/trainLabels.csv
- …/data/cifar-10/sampleSubmission.csv
train 和 test 文件夹分别包含训练和测试图像,trainLabels.csv 含有训练图像的标签, sample_submission.csv 是提交文件的范例
- 整理数据集
# 整理数据集
def read_csv_labels(fname):
"""读取 'fname' 来给标签字典返回一个文件名。"""
with open(fname, 'r') as f:
lines = f.readlines()[1:] # 一行一行读进来,每一行为列表中一个元素
tokens = [l.rstrip().split(',') for l in lines] # 遍历列表每一个元素,切分
return dict(((name, label) for name, label in tokens))
# labels = read_csv_labels(os.path.join(data_dir,'trainLabels.csv'))
labels = read_csv_labels('/root/autodl-tmp/01_Data/04_Kaggle_CIFAR10_Tiny/trainLabels.csv')
labels

- 将验证集从原始训练集中拆分
# 将验证集从原始的训练集中拆分出来
# train文件夹下有所有train的图片,test文件夹下有所有test图片
# 把train文件夹下所有类的图片创建一个类名文件夹,然后搬到对应文件夹下
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
def reorg_train_valid(data_dir, labels, valid_ratio):
# 创建目录
for folder in ['train_valid_test/train', 'train_valid_test/valid', 'train_valid_test/train_valid']:
os.makedirs(os.path.join(data_dir, folder), exist_ok=True)
for unique_label in set(labels.values()):
os.makedirs(os.path.join(data_dir, folder, unique_label), exist_ok=True)
# 处理训练数据
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, 'train')):
if train_file == '' or not train_file.endswith('.png'):
continue
# 更安全的文件名处理
file_id = train_file.split('.')[0]
if file_id == '':
print(f"跳过无效文件名: {train_file}")
continue
if file_id not in labels:
print(f"在labels中找不到文件 {train_file} 的ID: {file_id}")
continue
label = labels[file_id]
fname = os.path.join(data_dir, 'train', train_file)
# 复制到 train_valid 目录
# copyfile(fname, os.path.join(data_dir, 'train_valid_test', 'train_valid', label, train_file))
copyfile(fname, os.path.join(data_dir, 'train_valid_test', 'train_valid', label))
# 随机分配到 train 或 valid
if label not in label_count:
label_count[label] = []
label_count[label].append(train_file)
# 为每个类别分割训练和验证集
for label, files in label_count.items():
random.shuffle(files)
n = len(files)
n_valid = max(1, int(n * valid_ratio))
for i, file in enumerate(files):
src = os.path.join(data_dir, 'train', file)
if i < n_valid:
target_dir = os.path.join(data_dir, 'train_valid_test', 'valid', label)
else:
target_dir = os.path.join(data_dir, 'train_valid_test', 'train', label)
copyfile(src, target_dir)
- 在预测期间整理测试集,方便读取
# 在预测期间整理测试集,以方便读取
def reorg_test(data_dir):
for test_file in os.listdir(os.path.join(data_dir,'test')):
copyfile(os.path.join(data_dir,'test',test_file),
os.path.join(data_dir,'train_valid_test','test','unknown')) # unknown为 test文件夹里面的一个文件夹
- 调用前面定义的函数
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)
- 图像增广
# 图像增广
transform_train = torchvision.transforms.Compose([
torchvision.transforms.Resize(40),
torchvision.transforms.RandomResizedCrop(32,scale=(0.64,1.0),ratio=(1.0,1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914,0.4822,0.4465],
[0.2023,0.1994,0.2010]) ])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914,0.4822,0.4465],
[0.2023,0.1994,0.2010]) ])
- 读取由原始图像组成的数据集
# 读取由原始图像组成的数据集
train_ds, train_valid_ds = [
torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder), # 注意这里添加了 train_valid_test
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [
torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder), # 注意这里添加了 train_valid_test
transform=transform_test) for folder in ['valid', 'test']]
- 定义数据集迭代器
# 指定上面定义的所有图像增广操作
train_iter, train_valid_iter = [
torch.utils.data.DataLoader(dataset,batch_size,shuffle=True,drop_last=True)
for dataset in (train_ds, train_valid_ds) ]
valid_iter = torch.utils.data.DataLoader(valid_ds,batch_size,shuffle=False,drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds,batch_size,shuffle=False,drop_last=False)
- 定义模型&损失函数
# 模型
def get_net():
num_classes = 10
net = d2l.resnet18(num_classes,3) # 3表示数值三通道,彩色图片
return net
loss = nn.CrossEntropyLoss(reduction="none") # reduction="none" 表示不要把loss加起来sum
- 定义训练过程
# 训练函数
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):
# 使用 SGD + Momentum + 权重衰减
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=wd)
# 每隔 lr_period 个 epoch,把学习率乘以 lr_decay
# 例如:period=5, decay=0.1 → 每 5 个 epoch lr/=10
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
# 图例内容
legend = ['train loss', 'train acc']
if valid_iter is not None:
legend.append('valid acc')
# 用于绘制实时训练曲线
animator = d2l.Animator(
xlabel='epoch', xlim=[1, num_epochs], legend=legend
)
# 多 GPU 训练(DataParallel)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
net.train() # 启用训练模式(启用 dropout/bn)
metric = d2l.Accumulator(3) # 累加器:loss_sum, acc_sum, sample_count
# 遍历每个 batch
for i, (features, labels) in enumerate(train_iter):
timer.start()
# 一次前向+反向传播,返回(loss_sum, acc_sum)
l, acc = d2l.train_batch_ch13(
net, features, labels, loss, trainer, devices
)
# 累加(loss_sum, acc_sum, 样本数)
metric.add(l, acc, labels.shape[0])
timer.stop()
# 动态更新训练曲线(每个 epoch 更新 5 次)
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(
epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2], None)
)
# 验证集评估
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
# 学习率衰减(若到周期)
scheduler.step()
measures = (
f"train loss {metric[0] / metric[2]:.3f}, "
f"train acc {metric[1] / metric[2]:.3f}"
)
if valid_iter is not None:
measures += f", valid acc {valid_acc:.3f}"
print(measures +
f"\n{metric[2] * num_epochs / timer.sum():.1f} samples/sec on {str(devices)}")
- 训练和验证模型
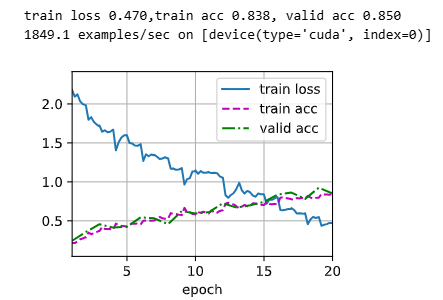
# 训练和验证模型
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)
- 在 Kaggle 上对测试集进行分类并提交结果
# 对测试集进行分类并提交结果
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period, lr_decay)
for X, _ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1,len(test_ds)+1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id':sorted_ids,'label':preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv',index=False)
狗的品种识别ImageNetDogs
比赛网址是:链接
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.DATA_HUB['dog_tiny'] = (d2l.DATA_URL + 'kaggle_dog_tiny.zip',
'0cb91d09b814ecdc07b50f31f8dcad3e816a86d')
demo = True
if demo:
data_dir = d2l.download_extract('dog_tiny')
else:
data_dir = os.path_join('..','data','dog_breed-identification')
# 整理数据集
def reorg_dog_data(data_dir, valid_ratio):
# 读取 Kaggle 提供的 labels.csv,返回 {图像id: 类别标签} 的字典
labels = d2l.read_csv_labels(os.path.join(data_dir,'labels.csv'))
# 按给定比例划分训练/验证集,并重组目录:train、valid、train_valid 等
d2l.reorg_train_valid(data_dir,labels,valid_ratio)
# 规范化测试集目录结构(将测试图片移动到指定子目录)
d2l.reorg_test(data_dir)
# 若 demo 模式则用更小 batch,更便于在 CPU/单卡上快速演示
batch_size = 32 if demo else 128
# 训练集划分为验证集的比例
valid_ratio = 0.1
reorg_dog_data(data_dir, valid_ratio)
# 图像增广
transform_train = torchvision.transforms.Compose([
# 随机裁剪并缩放到 224×224;scale 控制内容保留比例(8%~100%),ratio 控制宽高比(3/4~4/3)
torchvision.transforms.RandomResizedCrop(224,scale=(0.08,1.0),ratio=(3.0/4.0, 4.0/3.0)),
# 以 50% 概率做水平翻转,增强方向不变性
torchvision.transforms.RandomHorizontalFlip(),
# 随机调整亮度/对比度/饱和度,提升颜色多样性与鲁棒性
torchvision.transforms.ColorJitter(brightness=0.4,contrast=0.4,saturation=0.4),
# 将 PIL/ndarray 转为张量,像素从 [0,255] 映射到 [0,1]
torchvision.transforms.ToTensor(),
# 用 ImageNet 预训练常用均值/方差做标准化,便于迁移学习
torchvision.transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])])
transform_test = torchvision.transforms.Compose([
# 将较短边缩放到 256,保持纵横比
torchvision.transforms.Resize(256),
# 从中心裁剪 224×224,与训练/模型输入尺寸对齐
torchvision.transforms.CenterCrop(224),
# 转为张量
torchvision.transforms.ToTensor(),
# 与训练阶段使用相同的均值/方差标准化
torchvision.transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])])
# 使用训练增广加载 train 与 train_valid 集
train_ds, train_valid_ds = [
torchvision.datasets.ImageFolder(
os.path.join(data_dir,'train_valid_test',folder),
transform=transform_train) for folder in ['train','train_valid']]
# 使用测试增广(仅缩放裁剪)加载 valid 与 test 集
valid_ds, test_ds = [
torchvision.datasets.ImageFolder(
os.path.join(data_dir,'train_valid_test',folder),
transform=transform_test) for folder in ['valid','test']]
# 训练迭代器;打乱数据,且丢弃最后不满一个批次的数据
train_iter, train_valid_iter = [
torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
# 验证迭代器;不打乱;注意:drop_last=True 会丢弃最后不满批次的样本
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False, drop_last=True)
# 测试迭代器;不打乱;保留所有样本
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False, drop_last=False)
# 微调预训练模型
# 除了最后一层外,前面的层固定住参数不变
def get_net(device):
# 定义顺序容器(作为外壳),后面把特征提取器和新分类头挂进去
finetune_net = nn.Sequential()
# 加载预训练的 ResNet34 作为特征提取器(此处输出维度为 1000)
finetune_net.features = torchvision.models.resnet34(pretrained=True)
print("finetune_net:", finetune_net)
# 自定义新的输出层:1000 -> 256 -> 120(120 类犬种)
finetune_net.output_new = nn.Sequential(nn.Linear(1000,256),nn.ReLU(),nn.Linear(256,120)) # 在原始网络后又加了一层
print("finetune_net:", finetune_net)
# 把整个模型移动到设备上
finetune_net = finetune_net.to(devices[0]) # 注意:此处使用外部变量 devices,需要确保外部已定义
# 冻结特征提取器参数(只训练新增的输出层参数)
for param in finetune_net.features.parameters(): # 遍历features的所有参数
param.requires_grad = False
return finetune_net # 返回整个网络,这个网络中原始层的参数固定住了,保持不变
# 计算损失
loss = nn.CrossEntropyLoss(reduction='none') # 多分类交叉熵,返回逐样本(而非平均)的损失
def evaluate_loss(data_iter, net, devices):
# 累积总损失与样本总数,用于计算平均损失
l_sum, n = 0.0, 0
for features, labels in data_iter:
# 将数据与标签移动到指定设备(通常是 GPU0)
features, labels = features.to(devices[0]), labels.to(devices[0])
# 前向计算得到未归一化的 logits
outputs = net(features)
# 逐样本损失(shape 通常为 [batch])
l = loss(outputs, labels)
# 批内求和后累加到总损失
l_sum += l.sum()
# 累加样本数(分类任务下等于 batch 大小)
n += labels.numel()
# 返回平均损失标量;评估时通常搭配 net.eval() 与 torch.no_grad()
return l_sum / n
# 训练函数
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay):
# 多卡数据并行,把模型复制到多个 GPU,并把主副本放到第一个设备
net = nn.DataParallel(net,device_ids=devices).to(devices[0])
# 仅优化需要训练的参数;动量 SGD + 权重衰减
trainer = torch.optim.SGD(
(param for param in net.parameters() if param.requires_grad),
lr = lr, momentum = 0.9, weight_decay=wd)
# 学习率调度器:每 lr_period 个 epoch 乘以 lr_decay
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
# 批次数与计时器(用于吞吐量统计)
num_batches, timer = len(train_iter), d2l.Timer()
# 可视化图例
legend = ['train loss']
if valid_iter is not None:
legend.append('valid loss')
animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],legend=legend)
for epoch in range(num_epochs):
# 累计器:累计损失总和与样本数,用于计算平均损失
metric = d2l.Accumulator(2)
for i, (features, labels) in enumerate(train_iter):
timer.start()
# 数据搬到指定设备
features, labels = features.to(devices[0]), labels.to(devices[0])
# 梯度清零
trainer.zero_grad()
# 前向传播
output = net(features)
# 批损失(逐样本损失求和)
l = loss(output, labels).sum()
# 反向传播
l.backward()
# 参数更新
trainer.step()
# 记录损失总和与样本数
metric.add(l,labels.shape[0])
timer.stop()
# 每个 epoch 均匀取 5 个进度点,可视化训练损失
if (i+1) % (num_batches // 5) == 0 or i == num_batches -1:
animator.add(epoch + (i+1) / num_batches,
(metric[0] / metric[1], None))
# 本 epoch 的平均训练损失
measures = f'train loss {metric[0] / metric[1]:.3f}'
if valid_iter is not None:
# 验证集平均损失(评估函数内部不做反传)
valid_loss = evaluate_loss(valid_iter, net, devices)
# 可视化验证损失
animator.add(epoch + 1, (None, valid_loss.detach().cpu()))
# 调度学习率
scheduler.step()
# 训练结束后输出最终度量与吞吐量(样本数/总耗时)
if valid_iter is not None:
measures += f', valid loss {valid_loss:.3f}'
print(measures + f'\n{metric[1] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 10, 1e-4, 1e-4 # devices: 可用 GPU 列表(无 GPU 则为 [CPU]);num_epochs: 训练轮数;lr: 学习率;wd: 权重衰减
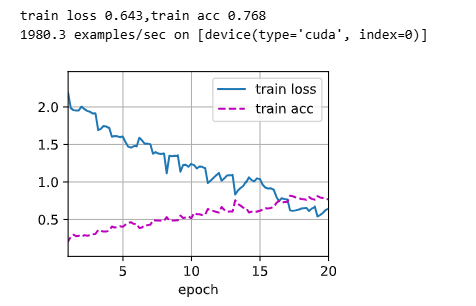
lr_period, lr_decay, net = 2, 0.9, get_net(devices) # 每 2 个 epoch 衰减一次学习率,乘以 0.9;根据设备构建微调网络
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay) # 启动训练,传入训练/验证迭代器、超参与设备
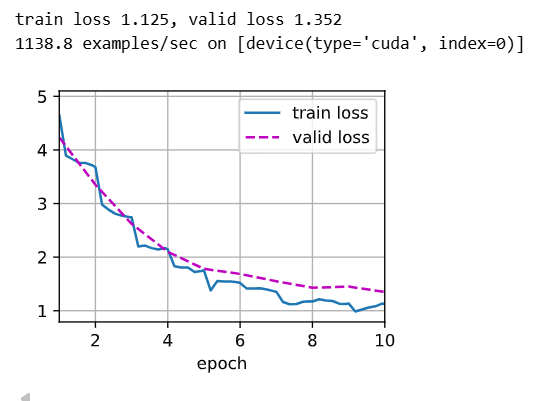
net = get_net(devices) # 构建并返回微调模型实例(内部会使用传入的设备列表)
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period, lr_decay) # 在 train_valid 上全量训练;无验证集;使用给定超参与学习率调度
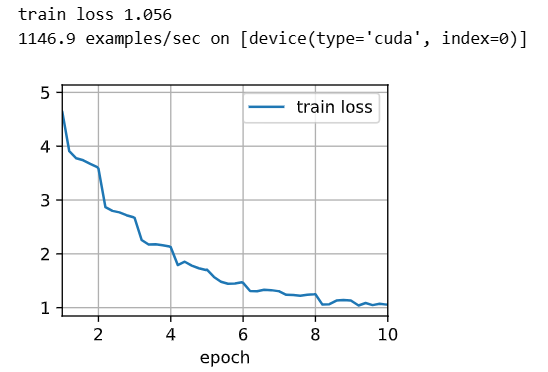
preds = [] # 收集每张测试图片对应的概率分布(按样本逐行存放)
for data, label in test_iter: # 逐批遍历测试集(label 在测试集里通常无用)
# 计算每一个样本对每一类的概率是多少
# 注意:分类通常应沿类别维做 softmax(dim=1),此处 dim=0 会按 batch 维归一化,可能不符合预期
# 推理阶段一般建议先 net.eval() 并使用 with torch.no_grad() 以关闭 Dropout/BN 的训练行为并节省显存
output = torch.nn.functional.softmax(net(data.to(devices[0])), dim=0)
# 将当前 batch 的概率矩阵(batch_size × num_classes)按行扩展到列表中
preds.extend(output.cpu().detach().numpy())
print(len(preds)) # 已累计的样本数(每次增加一个 batch 的样本数量)
# 读取并排序测试文件名,确保与 preds 的顺序一一对应
ids = sorted(os.listdir(os.path.join(data_dir, 'train_valid_test', 'test', 'unknown')))
# 写出提交文件:第一行为表头(id + 所有类别名),后续每行是 文件id + 概率向量
with open('submission.csv','w') as f:
f.write('id,' + ','.join(train_valid_ds.classes)+'\n')
for i, output in zip(ids, preds): # 将文件名与预测概率按顺序配对
f.write(i.split('.')[0] + ',' + ','.join([str(num) for num in output]) + '\n')

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)