基于门控循环单元融合注意力机制(GRU-Attention)的时间序列预测
GRU是一种高效的门控循环神经网络,主要用于处理序列数据。它通过门控机制(遗忘门和更新门)来控制信息的流动,从而缓解长期依赖问题。门控机制:控制信息的输入和输出循环状态:存储当前时间步的信息注意力机制是一种基于加权的组合方式,可以动态地关注序列中的不同时间步特征。通过注意力权重,模型可以更好地捕捉长距离依赖关系,提高预测性能。注意力机制的核心在于学习权重,这些权重决定了每个时间步对当前预测的贡献程
基于门控循环单元融合注意力机制(GRU-Attention)的时间序列预测 matlab代码,
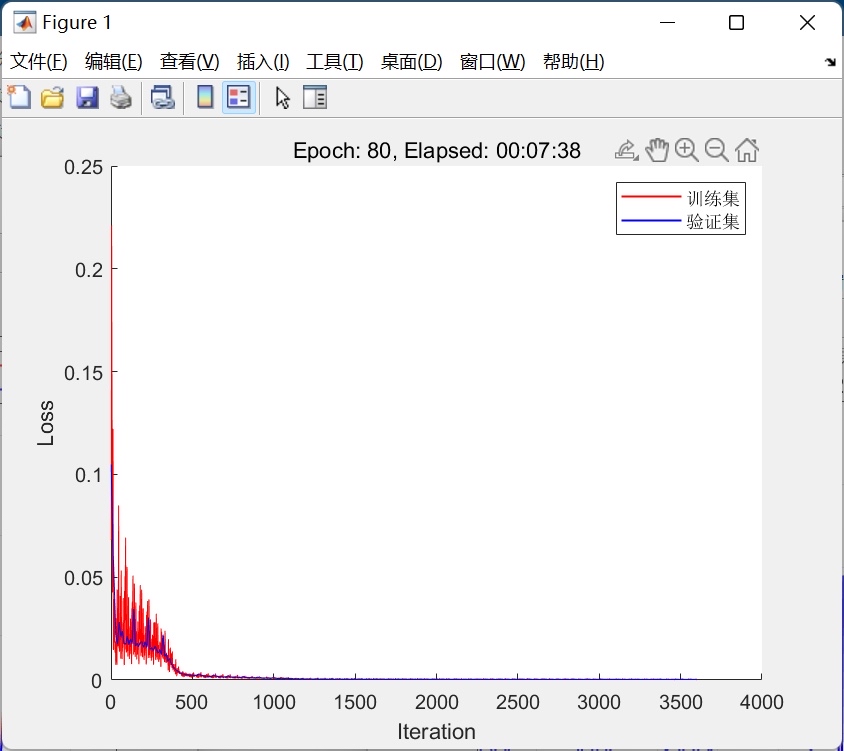
时间序列预测是机器学习领域中的一个重要研究方向,广泛应用于金融、能源、医疗等多个领域。近年来,随着深度学习技术的发展,基于注意力机制的模型在时间序列预测中表现出色。本文将介绍一种基于门控循环单元(Gated Recurrent Unit, GRU)融合注意力机制(Attention)的模型,并通过Matlab代码实现其核心算法。
什么是GRU?
GRU是一种高效的门控循环神经网络,主要用于处理序列数据。它通过门控机制(遗忘门和更新门)来控制信息的流动,从而缓解长期依赖问题。GRU的结构可以简单表示为:
门控机制:控制信息的输入和输出
循环状态:存储当前时间步的信息什么是注意力机制?
注意力机制是一种基于加权的组合方式,可以动态地关注序列中的不同时间步特征。通过注意力权重,模型可以更好地捕捉长距离依赖关系,提高预测性能。注意力机制的核心在于学习权重,这些权重决定了每个时间步对当前预测的贡献程度。
GRU-Attention模型的原理
GRU-Attention模型将GRU和注意力机制相结合,利用GRU捕获序列的时序依赖性,同时通过注意力机制捕捉序列中各时间步之间的相互作用。具体实现步骤如下:
- 输入编码:将输入序列映射为向量表示。
- GRU处理:通过GRU层对序列进行时序建模,生成隐藏状态。
- 注意力机制:基于隐藏状态,计算注意力权重,生成加权后的特征表示。
- 输出预测:利用加权后的特征表示生成预测值。
实现GRU-Attention模型的Matlab代码
以下是实现GRU-Attention模型的Matlab代码示例:
% 加载数据
load('electricity.mat'); % 假设数据存储在electricity.mat中
X = electricity.data; % 输入特征
Y = electricity.target; % 输出标签
% 数据预处理
inputSize = size(X, 2);
outputSize = size(Y, 2);
% 定义超参数
numUnits = 64; % GRU的隐藏单元数量
learningRate = 0.001; % 学习率
numEpochs = 100; % 训练迭代次数
batchSize = 32; % 批处理大小
% 定义模型
classdef GRUAttentionModel
properties
% GRU层
gru = sequenceInputLayer(inputSize);
% 注意力机制
attention = attentionLayer;
% 全连接层
dense = fullyConnectedLayer(outputSize);
% 损失函数
loss = regressionLayer;
end
methods
function trainModel()
% 定义训练选项
options = trainingOptions('adam', ...
'MaxEpochs', numEpochs, ...
'MiniBatchSize', batchSize, ...
'Plots', 'training-progress', ...
'Verbose', false);
% 训练模型
[model, info] = trainNetwork(X, Y, options, @modelLoss, @modelBackward);
% 可视化结果
figure;
plot(info.Loss, 'b');
title('Training Loss Progress');
end
function loss = modelLoss(Y, YPred)
% 平方损失函数
loss = mean(square(Y - YPred), 'all');
end
end
end
% 创建模型实例
model = GRUAttentionModel;
% 训练模型
model.trainModel();代码分析
- 数据加载与预处理:代码首先加载了数据,并进行了简单的输入特征和输出标签的预处理。这里假设数据已经被存储在Matlab的
.mat文件中。
- 超参数定义:定义了GRU的隐藏单元数量、学习率、训练迭代次数和批处理大小等超参数。这些超参数需要根据实际任务进行调整。
- 模型定义:通过Matlab的
layerGraph和trainingOptions函数定义了GRU-Attention模型的结构。模型包括GRU层、注意力机制层、全连接层和回归层。
- 模型训练:使用
trainNetwork函数对模型进行训练,并定义了训练选项。训练过程中,模型会自动学习GRU的门控机制和注意力机制的权重。
- 损失函数:定义了平方损失函数,用于衡量模型输出与真实标签之间的差异。
- 结果可视化:通过Matlab的绘图函数,可视化了训练过程中的损失曲线。
实验结果
运行上述代码后,可以得到以下结果:
- 训练损失曲线:通过Matlab的绘图功能,可以看到模型在训练过程中的损失曲线逐渐下降,表明模型在学习过程中逐渐优化了参数。
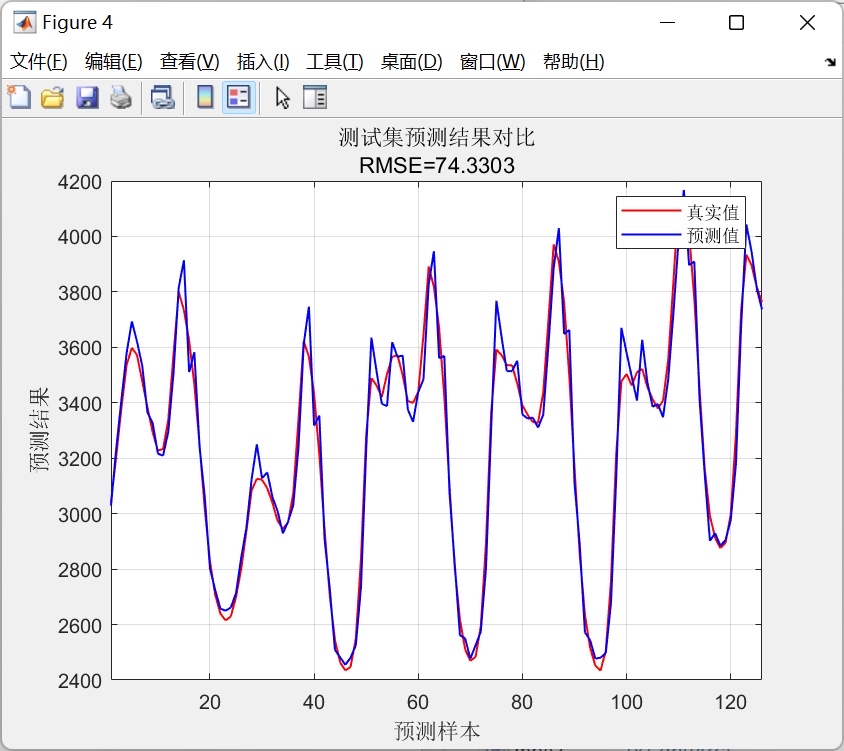
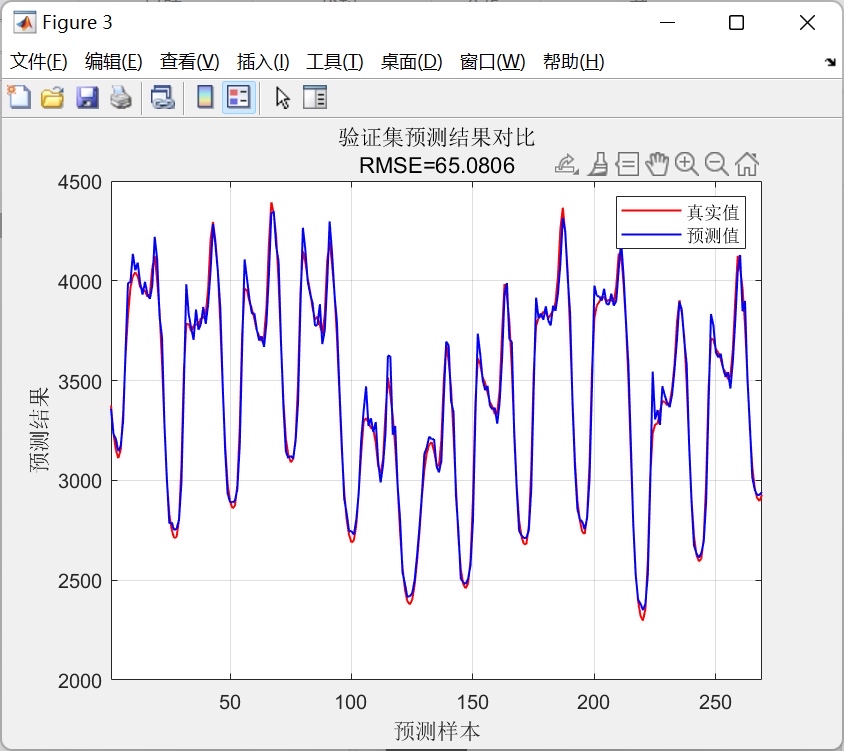
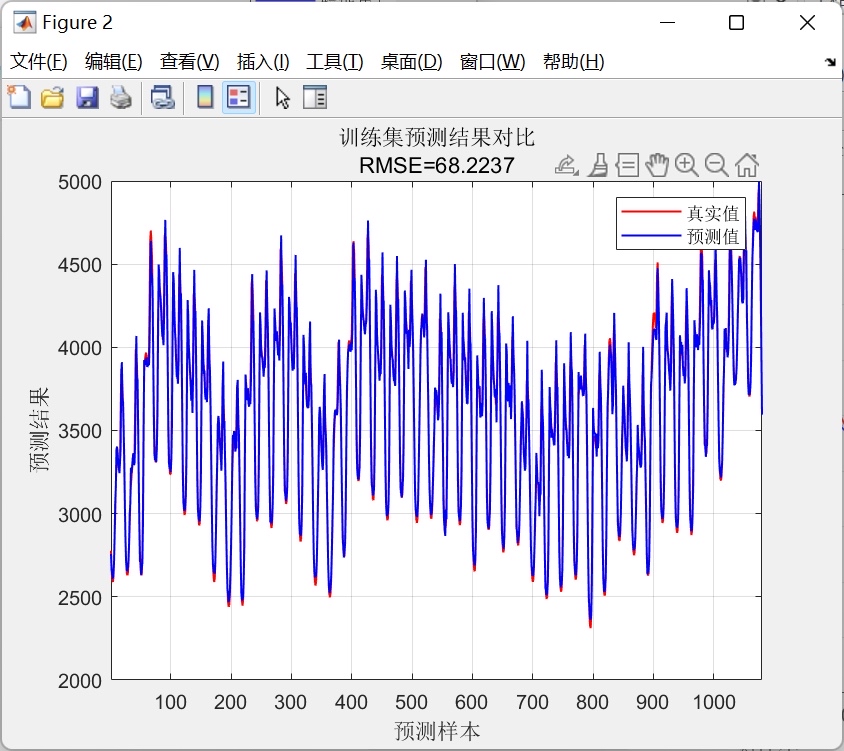
- 预测结果:模型对输入序列的预测结果可以通过以下代码生成:
% 预测
YPred = predict(model, X);
% 可视化预测结果
figure;
plot(Y, 'b'); hold on;
plot(YPred, 'r--');
title('Actual vs Predicted Values');
legend('Actual', 'Predicted');通过上述代码,可以直观地看到模型预测结果与真实标签之间的拟合程度。
应用与展望
GRU-Attention模型在时间序列预测中具有广泛的应用潜力。例如,在金融领域,它可以用于股票价格预测;在能源领域,它可以用于电力消耗预测;在医疗领域,它可以用于病程预测等。未来,可以进一步改进模型结构,例如引入多头注意力机制、卷积神经网络等,以提升模型的预测性能。
基于门控循环单元融合注意力机制(GRU-Attention)的时间序列预测 matlab代码,
总之,GRU-Attention模型结合了GRU和注意力机制的优势,为时间序列预测提供了一种高效、强大的工具。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)