机器学习——贝叶斯算法
优点:理论基础坚实:贝叶斯算法基于贝叶斯定理,它为概率模型的学习和推理提供了明确的理论框架。易于实现:贝叶斯算法的逻辑简单,只要使用贝叶斯公式转化即可,因此易于实现。分类过程中时空开销小:贝叶斯算法假设特征之间相互独立,因此在分类过程中,只会涉及到二维存储,大大降低了时空开销。易于并行化:贝叶斯算法可以很方便地进行并行化处理,提高计算效率。缺点:假设前提:贝叶斯算法假设样本特征彼此独立,这个假设在
一、原理解析
贝叶斯算法的核心思想是通过不断更新先验概率,结合新的数据,得到更准确的后验概率。这一特性使其在处理不确定性和噪声数据时表现出色。
1.贝叶斯公式
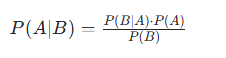
P(A|B):在事件B发生的条件下事件A发生的概率,称为后验概率
P(B|A):是在事件A发生的条件下事件B发生的概率,称为似然
P(A):事件A发生的先验概率
P(B):事件B发生的边际概率
2.计算步骤:
1.计算先验概率:基于训练数据,计算每个类别的先验概率 P(A)。
2.计算似然:对于每个特征,计算在给定类别下的条件概率 P(xi∣A)。
3.计算后验概率:对于新的输入样本,利用贝叶斯定理计算每个类别的后验概率。
4.选择最大概率类别:将后验概率最大的类别作为预测结果。
3.示例:
一个二分类问题,数据集如下:
| 特征a | 特征b | 特征c | 类别d |
| 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
使用朴素贝叶斯分类器来预测一个新的样本(特征a=1,特征b=0,特征c=0)的类别是
1.计算类别的先验概率:
P(d=0)=3/6=0.5
P(d=1)=3/6=0.5
2.计算每个特征在每个类别下的条件概率:
P(a=1|d=0) = 2/3 = 0.667
P(a=0|d=0) = 1/3 = 0.333
P(b=1|d=0) = 1/3 = 0.333
P(b=0|d=0) = 2/3 = 0.667
P(c=1|d=0) = 2/3 = 0.667
P(c=0|d=0) = 2/3 = 0.667
P(a=1|d=1) = 1/3 = 0.333
P(a=0|d=1) = 2/3 = 0.667
P(b=1|d=1) = 2/3 = 0.667
P(b=0|d=1) = 1/3 = 0.333
P(c=1|d=1) = 2/3 = 0.667
P(c=0|d=1) = 1/3 = 0.333
3.计算后验概率
朴素贝叶斯认为特征之间相互独立,因此联合条件概率可拆分
p(a=1,b=0,c=0)=p(a=1,b=0,c=0|d=0)*p(d=0) + p(a=1,b=0,c=0|d=1)*p(d=1)=1/6
p(d=0|a=1,b=0,c=0)=p(a=1,b=0,c=0|d=0)*p(d=0)/p(a=1,b=0,c=0)=p(a=1|d=0)*p(b=0|d=0)*p(c=0|d=0)*p(d=0)*p(d=0)/p(a=1,b=0,c=0)=0.889
p(d=1|a=1,b=0,c=0)=p(a=1,b=0,c=0|d=1)*p(d=1)/p(a=1,b=0,c=0) = p(a=1|d=1)*p(b=0|d=1)*p(c=0|d=1)*p(d=0)*p(d=1)/p(a=1,b=0,c=0)=0.111
根据后验概率,我们选择后验概率较大的类别作为预测结果,因此预测该样本的类别为D=0。
二、API接口
class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)参数:
alpha: 控制模型拟合时的平滑度.
定义:alpha是一个浮点数,表示添加剂(拉普拉斯/Lidstone)平滑参数。它控制了模型估计概率中的平滑程度。
作用:平滑是一种防止过拟合的技术,特别是在处理稀疏数据集或未出现在训练集中的特征时。当alpha设置为0时,表示不进行平滑;alpha设置为1时,称为Laplace平滑;当0<alpha<1时,称为Lidstone平滑。
影响:alpha值的大小会影响模型的复杂度。如果alpha值过大,模型估计出来的概率会减少,可能导致分类器更加稳定但准确率降低;反之,如果alpha值被设置的过低,会导致准确率提升,但可能会引起模型的过拟合问题。
fit_prior: 是否去学习类的先验概率。当fit_prior设置为True时,模型会根据训练数据集计算出每个类的先验概率。如果训练数据集中某个类的样本数量较少,计算出的先验概率可能非常小,这可能导致该类样本在分类时被忽略,从而影响模型的分类效果。
class_prior: 各个类别的先验概率,如果没有指定,则模型会根据数据自动学习, 每个类别的先验概率相同,等于类标记总个数N分之一。
作用:通过手动设置类的先验概率,可以调整模型对于不同类别的偏好。这在处理不平衡数据集时特别有用,可以通过提高少数类的先验概率来改进分类效果。
import pandas as pd
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x),
horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data = pd.read_csv("iris.csv", header=None)
data = data.drop(0, axis=1)
X_whole = data.drop(5, axis=1)
y_whole = data[5]
from sklearn.model_selection import train_test_split
x_train_w, x_test_w, y_train_w, y_test_w = \
train_test_split(X_whole, y_whole, test_size=0.2, random_state=0)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB(alpha=1)
classifier.fit(x_train_w, y_train_w)
train_pred = classifier.predict(x_train_w)
cm_plot(y_train_w, train_pred).show()
test_pred = classifier.predict(x_test_w)
cm_plot(y_test_w, test_pred).show()
三、总结
优点:
理论基础坚实:贝叶斯算法基于贝叶斯定理,它为概率模型的学习和推理提供了明确的理论框架。
易于实现:贝叶斯算法的逻辑简单,只要使用贝叶斯公式转化即可,因此易于实现。
分类过程中时空开销小:贝叶斯算法假设特征之间相互独立,因此在分类过程中,只会涉及到二维存储,大大降低了时空开销。
易于并行化:贝叶斯算法可以很方便地进行并行化处理,提高计算效率。
缺点:
假设前提:贝叶斯算法假设样本特征彼此独立,这个假设在实际应用中往往是不成立的,尤其在属性个数比较多或者属性之间相关性较大时,分类效果不好。
对噪声敏感:如果数据中存在大量噪声,贝叶斯算法可能会表现不佳。
模型选择:贝叶斯算法需要对模型进行正确的选择,如果模型选择不当,可能会导致算法性能下降。
高维特征空间的应用限制:贝叶斯算法在处理高维特征空间时可能会遇到困难,因为高维空间中的数据通常具有稀疏性,这会导致贝叶斯网络的学习和推理变得非常困难。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)