人工智能应用- 预测化学反应:06. BERT 模型简介
BERT是一种基于Transformer的双向预训练语言模型,通过同时考虑上下文信息提升语义理解能力。其核心是层次性编码结构,利用CLS符号表示整体语义,SEP符号分隔相关文本段。训练后的CLS输出向量可用于构建分类器,实现文本分类任务。该模型通过双向编码有效聚合上下文,显著提升了自然语言处理性能。
·
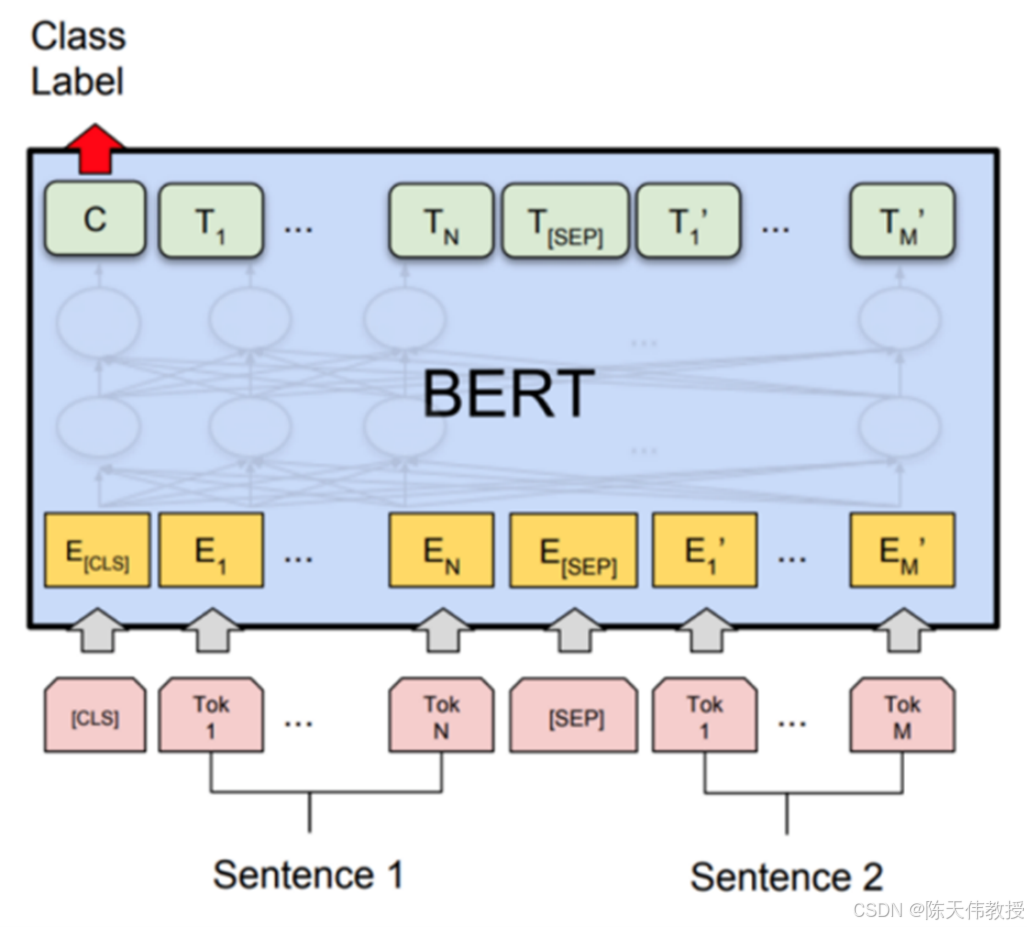
图 : 自然语言处理领域中的 BERT 模型
BERT(Bidirectional Encoder Representations from Transformers)是一种深度学习模型,最初应用于自然语言处理领域。该模型的核心思想是对输入文本进行双向编码,从而提高对上下文语义的理解能力。
具体而言,BERT 是一个基于 Transformer 结构的预训练模型,能够对输入序列进行层次性编码。在每一层编码时,序列中的每个元素都可以参考序列中其他元素的信息,从而有效聚合上下文信息。BERT 的独特之处在于,它能够同时考虑序列的前后文,使模型对序列的理解更加完整和准确。
在 BERT 模型中,CLS 符号用于表示整个序列的语义。SEP 符号用于分隔两段具有相关性的文本,例如问答系统中的问题和答案,帮助模型判断它们的语义关联。经过训练后,CLS 符号对应的输出向量可以用来表示整个序列的含义。基于这一向量,可以训练一个分类器(如线性分类器或神经网络分类器),实现序列数据的自动分类。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)