深度学习篇---Batch Normalization(批归一化)实现
BatchNormalization(批归一化)是深度学习中革命性的技术,通过标准化网络各层的输入分布,有效解决了内部协变量偏移问题。其核心原理包括计算批次均值方差、归一化处理,并引入可学习的缩放参数γ和偏移参数β。BN显著提升了训练速度(3-10倍)、允许使用更大学习率,并增强了网络对初始化的鲁棒性。在实现时需注意通道数匹配、训练/推理模式切换等细节,小批量场景可用GroupNorm替代。BN已
Batch Normalization(批归一化)实现
如果说神经网络是一座大厦,那么BatchNorm就是钢筋水泥——让整个结构更加稳固,经得起各种考验。它可以说是深度学习史上最实用的技术之一,没有它,很多现代网络根本无法训练。
一、BatchNorm解决了什么问题?
在深度网络中,有一个叫 "Internal Covariate Shift"(内部协变量偏移) 的问题:
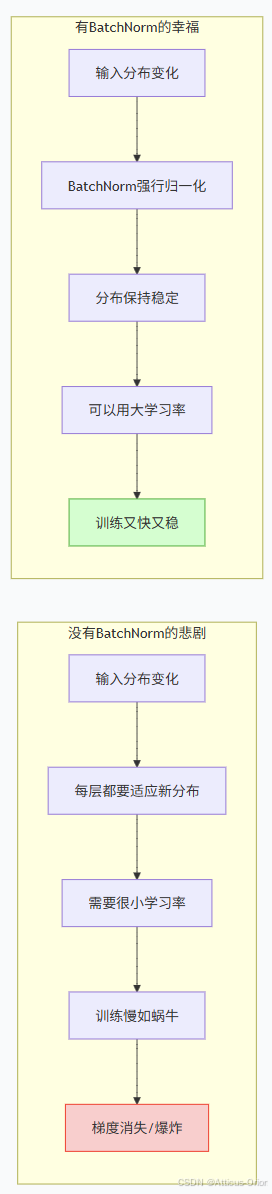
直观理解:
-
没BatchNorm:每一层的输入分布都在变,模型要不断适应新分布
-
有BatchNorm:把输入强行拉回标准分布,模型只要专注学习特征
二、BatchNorm的本质
2.1 数学原理
对于输入x,BatchNorm做三件事: 1. 算均值:μ_B = 1/m × Σ(x_i) # 当前批次的均值 2. 算方差:σ_B² = 1/m × Σ(x_i - μ_B)² # 当前批次的方差 3. 归一化:x̂_i = (x_i - μ_B) / √(σ_B² + ε) # 变成N(0,1)分布 4. 再缩放:y_i = γ × x̂_i + β # 学习最适合的分布 其中: - γ:可学习的缩放参数(初始为1) - β:可学习的偏移参数(初始为0) - ε:小常数,防止除零(1e-5)
2.2 训练 vs 推理的不同行为
import torch
import torch.nn as nn
class BatchNormDemo:
def __init__(self):
self.bn = nn.BatchNorm2d(64) # 64个通道
def train_mode(self):
"""训练模式"""
self.bn.train()
# 使用当前batch的均值和方差
# 同时更新running_mean和running_var
def eval_mode(self):
"""推理模式"""
self.bn.eval()
# 使用训练集累积的running_mean和running_var
# 不再更新统计量三、BatchNorm添加到网络
3.1 在不同层的添加位置
import torch.nn as nn
import torch.nn.functional as F
class CNNWithBN(nn.Module):
def __init__(self):
super().__init__()
# 1. 卷积层 + BN + 激活(标准写法)
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.bn1 = nn.BatchNorm2d(64) # 注意:通道数要匹配
self.conv2 = nn.Conv2d(64, 128, 3, padding=1)
self.bn2 = nn.BatchNorm2d(128)
# 2. 全连接层 + BN + 激活
self.fc1 = nn.Linear(128 * 32 * 32, 256)
self.bn3 = nn.BatchNorm1d(256) # 1d用于全连接
# 3. 最后的输出层不用BN
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
# 标准模式:Conv -> BN -> ReLU
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.bn3(x)
x = F.relu(x)
return self.fc2(x)
# BatchNorm在不同层的维度要求
examples = {
'BatchNorm1d': '全连接层 [batch, features]',
'BatchNorm2d': '卷积层 [batch, channels, height, width]',
'BatchNorm3d': '3D卷积 [batch, channels, depth, height, width]'
}3.2 常见错误和陷阱
# ❌ 错误1:通道数不匹配
self.bn = nn.BatchNorm2d(64)
# 如果卷积输出是128通道,这里会报错
# ✅ 正确做法
self.conv = nn.Conv2d(3, 128, 3)
self.bn = nn.BatchNorm2d(128) # 通道数必须和conv输出一致
# ❌ 错误2:训练/推理模式混淆
model.eval() # 推理时忘记切换模式
# BN会用训练集的统计量,而不是当前batch
# ❌ 错误3:batch size太小
# 当batch size=1或2时,BN效果很差
# 解决方案:使用LayerNorm或GroupNorm四、BatchNorm对层的深远影响
4.1 对卷积层的影响
# 没有BN的卷积层
class ConvWithoutBN(nn.Module):
def forward(self, x):
x = self.conv(x)
x = torch.relu(x) # 直接激活
return x
# 有BN的卷积层
class ConvWithBN(nn.Module):
def forward(self, x):
x = self.conv(x)
x = self.bn(x) # BN介入
x = torch.relu(x) # 归一化后再激活
return x影响对比:
| 方面 | 无BN | 有BN |
|---|---|---|
| 梯度传播 | 容易消失/爆炸 | 梯度稳定 |
| 学习率 | 只能用小的(0.01) | 可以用大的(0.1~1.0) |
| 初始化 | 要求严格 | 不太敏感 |
| 收敛速度 | 慢 | 快3~10倍 |
| 泛化能力 | 一般 | 更好(有正则化效果) |
4.2 对激活函数的影响
import matplotlib.pyplot as plt
import numpy as np
def visualize_bn_effect():
"""可视化BN对激活值分布的影响"""
# 模拟没有BN的激活值
without_bn = np.random.randn(1000) * 2 + 1 # 均值为1,方差为4
# 模拟有BN的激活值
with_bn = (without_bn - without_bn.mean()) / without_bn.std()
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].hist(without_bn, bins=50, alpha=0.7)
axes[0].set_title('没有BN:激活值分布杂乱\n部分在饱和区')
axes[0].axvline(x=0, color='r', linestyle='--')
axes[1].hist(with_bn, bins=50, alpha=0.7)
axes[1].set_title('有BN:激活值规整\n大部分在敏感区')
axes[1].axvline(x=0, color='r', linestyle='--')
plt.show()
# 对ReLU的影响
# 没BN:很多负值被截断(梯度为0)
# 有BN:负值经过归一化可能变正,减少神经元死亡4.3 对梯度流动的影响
def analyze_gradient_flow(model_without_bn, model_with_bn):
"""分析梯度流动"""
def get_gradient_norm(model):
total_norm = 0
for p in model.parameters():
if p.grad is not None:
param_norm = p.grad.data.norm(2)
total_norm += param_norm.item() ** 2
return total_norm ** 0.5
# 没BN的网络:深层梯度小,浅层梯度大
grads_without_bn = []
# 有BN的网络:各层梯度相对均匀
grads_with_bn = []
# BN通过归一化,让梯度在各层之间更平衡
# 避免了"梯度消失"和"梯度爆炸"五、BatchNorm的超参数详解
class BatchNormHyperparams:
"""BatchNorm的所有可调参数"""
def __init__(self):
# 标准BN
self.bn = nn.BatchNorm2d(
num_features=64, # 特征通道数
eps=1e-5, # 防止除零的小常数
momentum=0.1, # 运行均值的更新动量
affine=True, # 是否学习γ和β
track_running_stats=True # 是否跟踪运行统计量
)
# 参数详解:
# momentum: 控制running_mean的更新速度
# running_mean = (1-momentum) × running_mean + momentum × batch_mean
# affine=True: 有可学习参数
# 参数量 = 2 × num_features(γ和β各一份)
# track_running_stats: 推理时使用全局统计量六、BatchNorm的变种
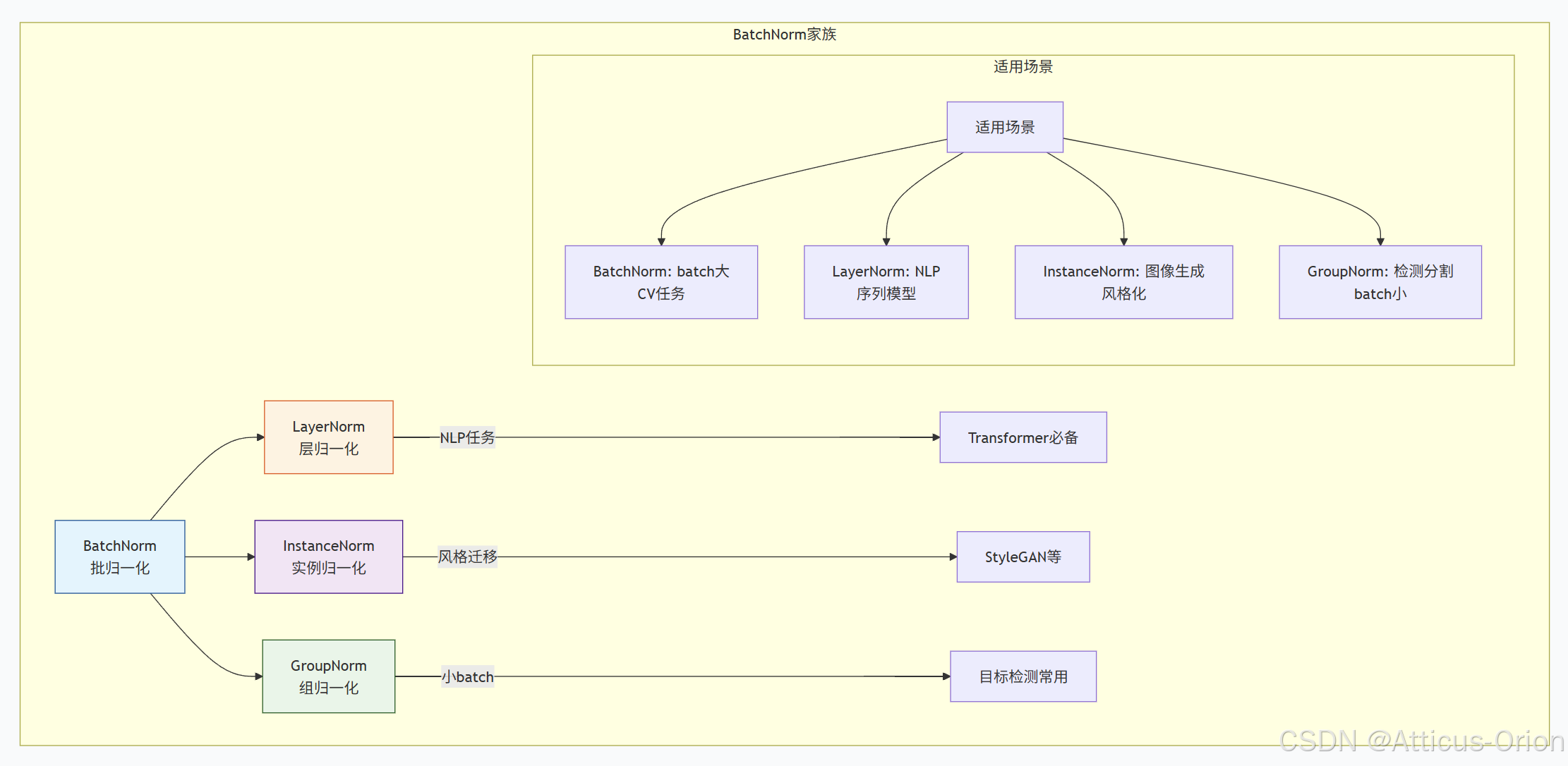
6.1 各种Normalization的对比
import torch
import torch.nn as nn
# 1. BatchNorm (最常用)
# 在batch维度归一化,保持通道独立
bn = nn.BatchNorm2d(64) # [N, C, H, W] -> 对每个通道的N×H×W求统计量
# 2. LayerNorm (Transformer用)
# 在特征维度归一化,保持batch独立
ln = nn.LayerNorm(512) # [N, L, D] -> 对每个样本的L×D求统计量
# 3. InstanceNorm (风格迁移用)
# 在每个样本的每个通道独立归一化
inn = nn.InstanceNorm2d(64) # [N, C, H, W] -> 对每个N×C的H×W求统计量
# 4. GroupNorm (小batch用)
# 将通道分组,组内归一化
gn = nn.GroupNorm(num_groups=32, num_channels=64) # 32组,每组2通道
# 不同方法的统计维度
stats_dims = {
'BN': 'batch和空间维度',
'LN': '特征和空间维度',
'IN': '空间维度',
'GN': '组内通道和空间维度'
}七、BatchNorm的实战技巧
7.1 训练策略
class BNTrainingTips:
"""BatchNorm训练技巧"""
@staticmethod
def warmup_strategy(optimizer, bn_model, epoch):
"""BN配合学习率预热"""
if epoch < 5:
# 预热阶段:用小的学习率
for param_group in optimizer.param_groups:
param_group['lr'] = 0.001 * (epoch + 1) / 5
else:
# 正常训练
pass
# 注意:BN的γ和β也会被优化器更新
@staticmethod
def large_batch_training():
"""大batch训练技巧"""
# 大batch时,BN的统计量更准确
# 可以适当增大学习率
# 线性缩放规则:
# lr_new = lr_base × (batch_size / base_batch_size)
# 但BN的momentum可能需要调小
# momentum_new = momentum_base × (base_batch_size / batch_size)
@staticmethod
def small_batch_alternative():
"""小batch时的替代方案"""
if batch_size < 8:
# 用GroupNorm代替BatchNorm
return nn.GroupNorm(num_groups=32, num_channels=64)
else:
return nn.BatchNorm2d(64)7.2 微调技巧
# 1. 冻结BN层进行微调
def freeze_bn(model):
"""微调时冻结BN层"""
for module in model.modules():
if isinstance(module, (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d)):
module.eval() # 固定统计量
module.requires_grad_(False) # 不更新γ和β
# 2. 不同学习率
def different_lr_strategy(model):
"""给BN层设置不同的学习率"""
bn_params = []
other_params = []
for name, param in model.named_parameters():
if 'bn' in name:
bn_params.append(param)
else:
other_params.append(param)
optimizer = optim.SGD([
{'params': other_params, 'lr': 0.1},
{'params': bn_params, 'lr': 0.01} # BN层用小学习率
], momentum=0.9)
# 3. 评估模式陷阱
def eval_mode_correct():
"""正确使用评估模式"""
model.eval() # 切换到评估模式
with torch.no_grad(): # 不计算梯度
for data in val_loader:
output = model(data) # BN用全局统计量八、BatchNorm的效果可视化
import matplotlib.pyplot as plt
def visualize_bn_impact():
"""可视化BN对训练的影响"""
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 1. 训练速度
axes[0, 0].plot(epochs, loss_without_bn, label='无BN', alpha=0.7)
axes[0, 0].plot(epochs, loss_with_bn, label='有BN', alpha=0.7)
axes[0, 0].set_title('训练速度对比')
axes[0, 0].legend()
# 2. 梯度分布
axes[0, 1].hist(grads_without_bn, bins=50, alpha=0.5, label='无BN')
axes[0, 1].hist(grads_with_bn, bins=50, alpha=0.5, label='有BN')
axes[0, 1].set_title('梯度分布')
axes[0, 1].legend()
# 3. 激活值分布
axes[0, 2].hist(acts_without_bn, bins=50, alpha=0.5)
axes[0, 2].set_title('无BN:激活值分布')
axes[1, 2].hist(acts_with_bn, bins=50, alpha=0.5)
axes[1, 2].set_title('有BN:激活值分布')
# 4. 学习率容忍度
axes[1, 0].plot(lrs, acc_without_bn, 'o-', label='无BN')
axes[1, 0].plot(lrs, acc_with_bn, 'o-', label='有BN')
axes[1, 0].set_xscale('log')
axes[1, 0].set_title('学习率敏感度')
axes[1, 0].legend()
# 5. 初始化鲁棒性
axes[1, 1].bar(['Xavier', 'He', 'Random'],
[acc1, acc2, acc3], alpha=0.5)
axes[1, 1].set_title('初始化鲁棒性')
plt.tight_layout()
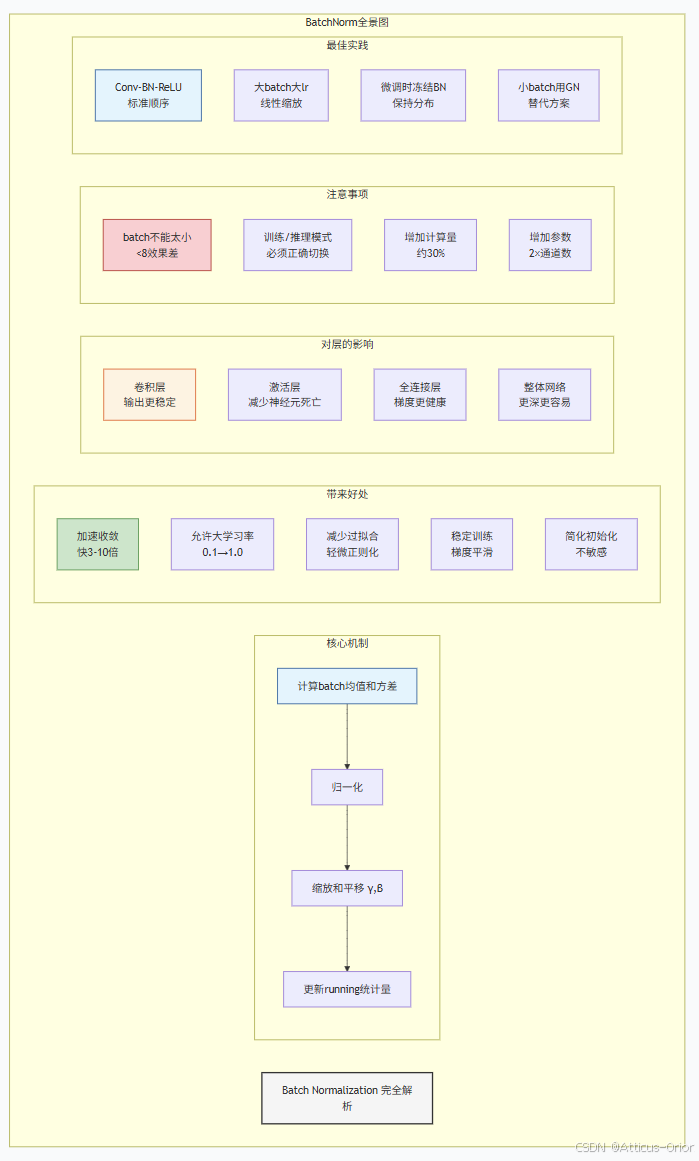
plt.show()九、BatchNorm总结全景图
十、终极总结
BatchNorm的三大革命性贡献:
-
让训练变快:以前要训100轮,现在30轮就够
-
让调参变简单:学习率大点小点都能训
-
让网络变深:没有BN,ResNet这样的百层网络根本无法训练
一句话记住BatchNorm:它就像是网络的"体温计",时刻监测并调节每一层的"体温",让整个网络保持在最佳工作状态!
实用口诀:
-
卷积后面加BN,激活之前放一放
-
训练统计当前批,推理要用全局量
-
大batch用效果好,小batch找替代方
-
微调记得要冻结,否则效果要遭殃

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 23
23 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)