【无监督学习入门:KMeans 聚类算法(附啤酒数据实战)】
K-means 是无监督机器学习中最经典的聚类算法,核心是将数据集划分为 K 个簇(类别),使得同一簇内的数据相似度最高,不同簇间相似度最低。
K-means 是无监督机器学习中最经典的聚类算法,核心是将数据集划分为 K 个簇(类别),使得同一簇内的数据相似度最高,不同簇间相似度最低。
一、基本概念:
1.聚成多少个簇:需要指定K的值
2.距离的度量:一般采用欧式距离
3.质心:各向量的均值
4.优化目标:
其中为第i个簇的质心,x为
簇内的样本。
常见距离:
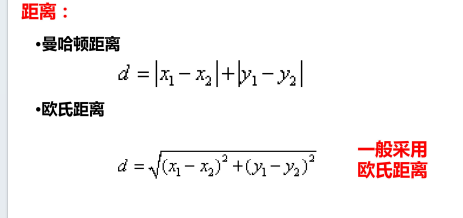
K-means 算法优先采用欧氏距离
二、K-means 算法核心步骤:
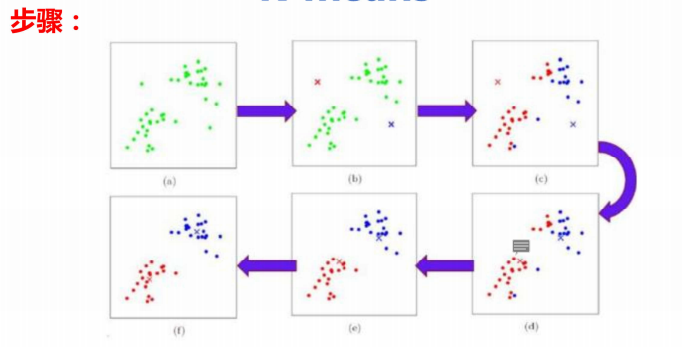
1.初始化质心:随机从数据集中选择K个样本,作为K个簇的初始质心;
2. 样本分配:计算每个样本到K个质心的距离(欧氏距离),将样本分配到距离最近的簇中;
3. 更新质心:根据每个簇的现有样本,重新计算簇的质心(簇内所有样本的均值);
4. 迭代收敛:重复执行「样本分配 - 更新质心」,直到质心不再发生变化(或变化小于设定阈值),迭代终止,得到最终聚类结果。
三、聚类效果评价方式 —— 轮廓系数
1.核心定义(单个样本xi的轮廓系数S(i))
(1)两个关键指标

a(i)越小,簇内样本越紧密

b(i)越大,簇间差异越明显
(2)计算公式和轮廓系数:

计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数
核心评价逻辑
整体轮廓系数越接近1,说明当前设定的K值越合适,聚类结果的簇内紧密、簇间独立;若整体轮廓系数偏低(如接近 0 或负数),则需调整K值重新聚类。
四、sklearn.cluster.KMeans 接口参数 ,属性简表
1、参数说明
| 参数名 | 默认值 | 说明 |
|---|---|---|
| n_clusters | 8 | 类中心个数,即就是要聚成几类 |
| init | 'k-means++' | 参初始化的方法,
(1)'k-means++': 用一种特殊的方法选定初始质心从而能加速迭代过程的收敛. (2) ‘random’: 随机从训练数据中选取初始质心。 (3) 如果传递的是一个ndarray,则应该形如 (n_clusters, n_features) 并给出初始质心。 |
| n_init | 10 |
用不同的质心初始化值运行算法的次数,最终解是在inertia意义下选出的最优结果。 |
| max_iter | 300 | 单次 k-means 算法的最大迭代数 |
| tol | 0.0001 | 收敛阈值,与 inertia 结合判断收敛 |
| precompute_distances | 'auto' | 预计算距离,可选 auto/True/False,
(1)‘auto’:如果 样本数乘以聚类数大于 12million 的话则不预计算距离。 (2)True:总是预先计算距离。 (3)False:永远不预先计算距离。 |
| verbose | 0 | 日志输出级别,整形 |
| random_state | None | 随机状态 |
| copy_x | True | 当我们precomputing distances时,将数据中心化会得到更准确的结果。如果把此参数值设为True,则原始数据不会被改变。如果是False,则会直接在原始数据 上做修改并在函数返回值时将其还原。但是在计算过程中由于有对数据均值的加减运算,所以数据返回后,原始数据和计算前可能会有细小差别。 |
| algorithm | 'auto' |
聚类算法 full:采用经典的EM算法 |
2、属性说明
| 属性名 | 类型 / 形状 | 说明 |
|---|---|---|
| cluster_centers_ | n_clusters*n_features 矩阵 | 聚类中心的坐标 |
| labels_ | 数组 | 每个样本的分类标签 |
| inertia_ | float | 所有样本到其簇质心的距离之和 |
| n_iter_ | int |
算法实际执行的迭代次数 |
目录
四、sklearn.cluster.KMeans 接口参数 ,属性简表
1. 库导入:聚类 + 评估 + 可视化基础配置
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metricspandas:用于读取结构化文本数据(txt),处理特征矩阵;sklearn.cluster.KMeans:sklearn 封装的 KMeans 聚类算法,无需手动实现迭代逻辑;sklearn.metrics:提供聚类效果评估指标,核心用silhouette_score计算轮廓系数。
2. 数据加载:适配空格分隔的 txt 文件
beer = pd.read_table("data.txt",sep=' ',encoding='utf8',engine='python')pd.read_table:专门读取非逗号分隔的文本文件(区别于pd.read_csv);- 关键参数:
sep=' ':指定数据分隔符为空格(适配啤酒数据的格式);encoding='utf8':避免中文乱码(若数据是 GBK 编码需改为encoding='gbk')engine='python':解决 C 引擎解析空格分隔数据时的兼容性问题;
- 数据要求:data.txt必须包含calories、sodium、alcohol、cost四列,否则后续索引会报错。
3. 特征提取:筛选聚类用的数值特征
X = beer[["calories","sodium","alcohol","cost"]]- 核心逻辑:KMeans 基于欧氏距离计算,仅支持数值型特征,需排除文本、分类等非数值列;
X的格式:DataFrame,形状为(样本数, 4),是 KMeans 模型的标准输入;- 潜在问题:未做数据标准化(如
calories单位是大卡,cost单位是元,量纲差异大),会导致距离计算偏向数值大的特征,影响聚类结果
4. 遍历 K 值计算轮廓系数:核心逻辑
scores = []
for k in range(2,10):
labels=KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X,labels)
scores.append(score)
print(scores)scores = []:初始化空列表,存储每个 K 值对应的轮廓系数;
for k in range(2,10):遍历 K=2 到 K=9(聚类至少需要 2 个簇,无意义);
KMeans(n_clusters=k).fit(X).labels_:
1. KMeans(n_clusters=k):初始化模型,指定聚类数为 k;
2. .fit(X):用特征矩阵 X 训练模型,完成质心迭代;
3. .labels_:获取训练后每个样本的聚类标签(值为 0~k-1);
• metrics.silhouette_score(X,labels):
◦ 计算当前 K 值的平均轮廓系数(取值 [-1,1],越接近 1 聚类效果越好);
◦ 输入要求:X为特征矩阵,labels为对应聚类标签;
• scores.append(score):将当前 K 值的系数存入列表;
• print(scores):打印数值结果,可精准定位最大值对应的 K 值(避免可视化的视觉误差)
5. 可视化:直观展示 K 值与轮廓系数的关系
import matplotlib.pyplot as plt
plt.plot(list(range(2,10)),scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Silhouette Score")
plt.show()plt.plot(...):绘制折线图,横轴为 K 值(2~9),纵轴为轮廓系数;- 坐标轴标签:
xlabel:标注横轴为 “初始化的聚类数”;ylabel:纵轴代表对应 K 值下,所有样本的平均轮廓系数(取值范围 [-1,1]),系数越大说明聚类效果越好。
plt.show():显示折线图,峰值点对应的 K 值即为最优聚类数(如 K=3 时系数最高,则聚 3 类效果最好)。
运行结果: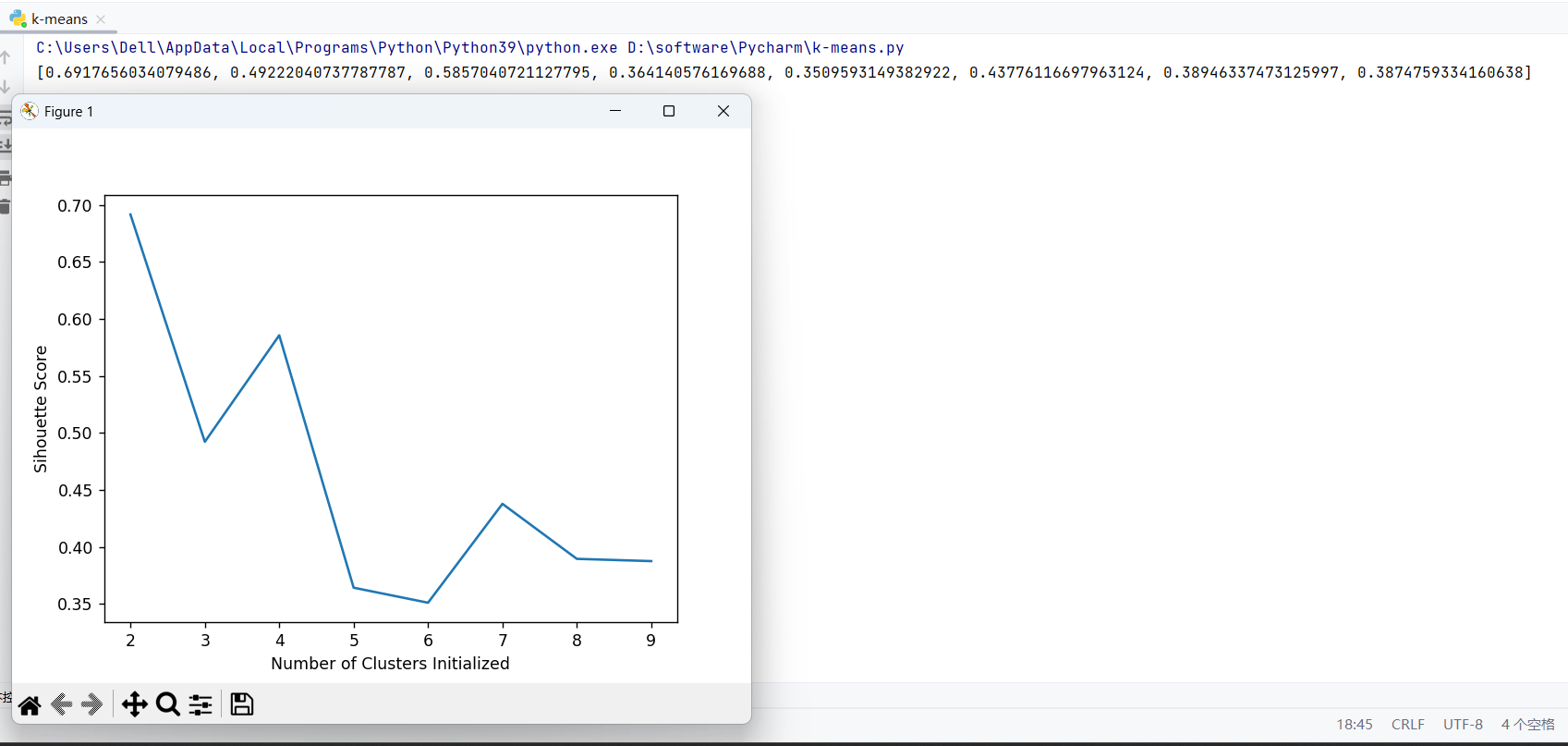
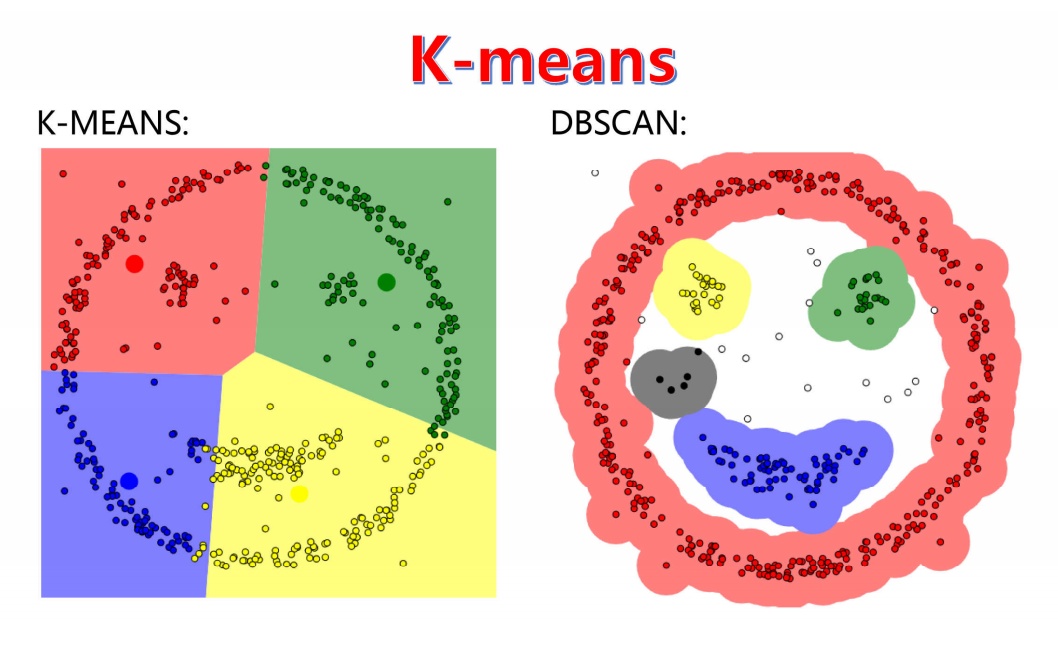
K-means 算法:优点是原理简单、运算快速,适配常规数据集;缺点是难以确定最优 K 值,且很难识别数据集中任意形状的簇。
六、DBSCAN 算法:
全称是基于密度的带噪声的空间聚类应用算法,核心是将密度相连的点的最大集合定义为簇,能划分高密度区域为簇,同时可在含噪声的数据集中发现任意形状的聚类。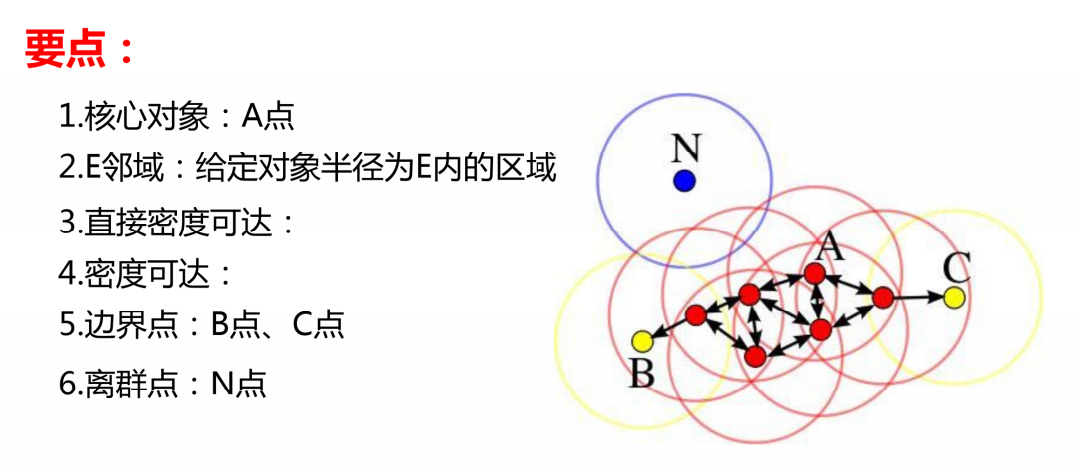
实现过程:
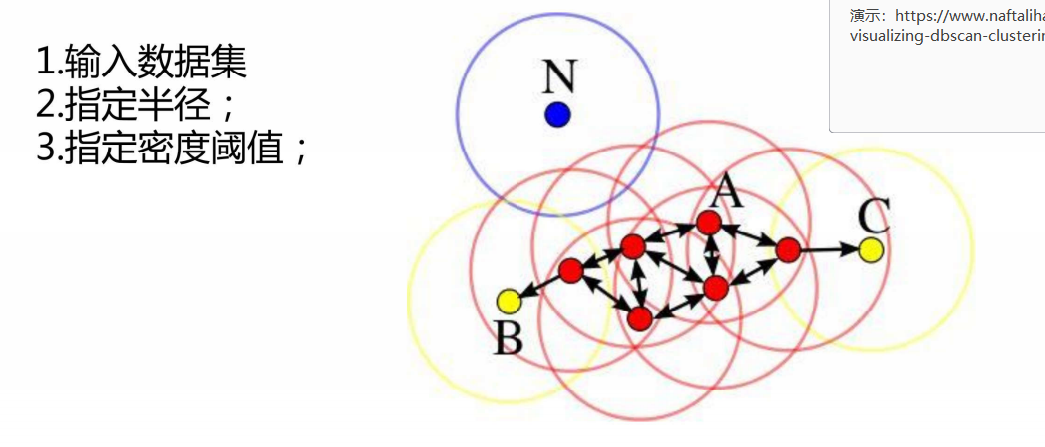
演示网站:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
sklearn.cluster.DBSCAN 核心 API 参数速查表
参数:
| 参数名 | 默认值 | 功能简述 & 调参要点 |
|---|---|---|
| eps | 0.5 | ε- 邻域距离阈值,判定样本是否在同一邻域;过大簇易合并,过小簇易拆分 |
| min_samples | 5 | 样本成为核心对象的 ε- 邻域样本数阈值(含自身);与 eps 配合调参,过大核心对象少、噪声多,过小则簇数偏少 |
| metric | 'euclidean' | 样本间距离度量方式,常用欧式 / 曼哈顿 / 切比雪夫距离,常规场景用默认值 |
| p | None | 仅用于闵可夫斯基距离,p=1 为曼哈顿距离、p=2 为欧式距离,默认欧式距离无需设置 |
| algorithm | 'auto' | 最近邻搜索算法;auto 自动选最优,brute 蛮力实现(稀疏特征强制使用),kd_tree 适配大数据,ball_tree 适配分布不均数据 |
| leaf_size | 30 | 配合 kd_tree/ball_tree 使用,影响树的构建与查询效率,默认值适配多数场景 |
| metric_params | None | 距离度量额外参数,无特殊需求无需设置 |
| n_jobs | None | 并行运行作业数,无并行需求无需设置 |
属性
| 属性名 | 说明 |
|---|---|
| labels_ | 每个样本的聚类标签,噪声点标记为 - 1,不同簇用 0、1、2 等整数标识 |

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 41
41 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)