Sigmoid函数:神经元的“激活”密码与百年浮沉,一条S型曲线背后的智能演化史
Sigmoid函数:从人口模型到深度学习的演变与局限 摘要:Sigmoid函数起源于1838年韦吕勒的人口增长模型,后在1943年成为MCP神经元的基础。其S型曲线特性(平滑、可微、有界)使其成为神经网络理想的激活函数,尤其适合二分类问题的概率输出。然而在深度学习中,Sigmoid的导数上限(0.25)导致梯度连乘时出现指数级衰减,造成训练停滞。现代神经网络多采用ReLU等替代方案,但Sigmoi
从19世纪的数学发现到20世纪神经网络的基石,再到21世纪深度学习中的争议角色——一条S型曲线背后的智能演化史
一、起源:从人口增长到概率映射的数学发现
历史溯源
Sigmoid函数的历史比现代人工智能早了一个多世纪。1838年,比利时数学家皮埃尔·弗朗索瓦·韦吕勒在研究人口增长模型时,首次提出了逻辑斯谛方程:
dPdt=rP(1−PK) \frac{dP}{dt} = rP\left(1 - \frac{P}{K}\right) dtdP=rP(1−KP)
这个微分方程描述了一个符合环境承载极限的增长过程,其解析解正是我们今天熟知的Sigmoid函数形式。有趣的是,韦吕勒当时完全没有意识到,这个描述人口如何从缓慢增长到快速扩张再到饱和的数学模型,会在150年后成为机器“思考”的关键组件。
二、生物灵感与神经科学背景
神经元的“全或无”原则
1943年,沃伦·麦卡洛克和沃尔特·皮茨提出了第一个形式化神经元模型(MCP神经元)。他们观察到生物神经元的一个重要特性:
- 神经元接收多个输入信号
- 信号在细胞体内进行空间与时间上的累加
- 当膜电位超过某个阈值时,神经元“发放”动作电位
- 动作电位的强度是固定的,遵循“全或无”原则
从阶跃函数到平滑过渡
早期的MCP神经元使用单位阶跃函数作为激活函数:
def step_function(x, threshold=0):
return 1 if x >= threshold else 0
但阶跃函数存在明显缺陷:
- 不可导:在阈值点导数不存在或为无穷大
- 信息损失:输出只有0或1,无法表示激活程度的强弱
神经科学家发现,虽然单个神经元的发放是二元的,但神经元群体的平均发放率却表现出平滑的S型响应特征。这一观察为Sigmoid函数的引入提供了生物学合理性。
三、数学定义与核心特性
标准Sigmoid函数
Sigmoid函数的标准形式为:
σ(x)=11+e−x=exex+1 \sigma(x) = \frac{1}{1 + e^{-x}} = \frac{e^x}{e^x + 1} σ(x)=1+e−x1=ex+1ex
可视化展示
关键数学特性
-
值域有界性:( \sigma(x) \in (0, 1) )
- 当 ( x \to -\infty ) 时,( \sigma(x) \to 0 )
- 当 ( x \to +\infty ) 时,( \sigma(x) \to 1 )
- 当 ( x = 0 ) 时,( \sigma(x) = 0.5 )
-
处处可导性:
ddxσ(x)=σ(x)[1−σ(x)] \frac{d}{dx}\sigma(x) = \sigma(x)[1 - \sigma(x)] dxdσ(x)=σ(x)[1−σ(x)]
这个优雅的导数形式是反向传播算法的关键 -
概率解释:输出值可直接解释为概率
P(y=1∣x)=σ(wTx+b) P(y=1|x) = \sigma(w^Tx + b) P(y=1∣x)=σ(wTx+b) -
饱和性:当|x|较大时,函数进入饱和区,梯度接近零
四、为什么选择Sigmoid?——深度学习中的角色
逻辑斯谛回归:二分类问题的完美搭档
考虑一个医疗诊断场景:根据肿瘤特征预测是否为恶性
import numpy as np
def sigmoid(x):
"""Sigmoid函数实现"""
return 1 / (1 + np.exp(-x))
# 假设特征:肿瘤大小、形状不规则度、细胞异型性
X_patient = np.array([2.5, 0.8, 1.2]) # 患者特征
weights = np.array([0.8, 1.5, 1.0]) # 学习到的权重
bias = -2.3 # 偏置项
# 计算逻辑斯谛值
z = np.dot(X_patient, weights) + bias
probability_malignant = sigmoid(z)
print(f"恶性概率: {probability_malignant:.2%}")
# 输出: 恶性概率: 62.18%
在神经网络中的实际应用
class NeuronWithSigmoid:
"""使用Sigmoid激活的神经元"""
def __init__(self, input_size):
self.weights = np.random.randn(input_size) * 0.1
self.bias = np.random.randn() * 0.1
def forward(self, inputs):
"""前向传播"""
z = np.dot(inputs, self.weights) + self.bias
# Sigmoid激活
activation = 1 / (1 + np.exp(-z))
return activation
def backward(self, inputs, grad_output):
"""反向传播计算梯度"""
# 前向传播的中间结果需要保存
z = np.dot(inputs, self.weights) + self.bias
a = 1 / (1 + np.exp(-z))
# Sigmoid的导数:σ'(z) = σ(z)(1-σ(z))
local_gradient = a * (1 - a)
# 链式法则
grad_weights = grad_output * local_gradient * inputs
grad_bias = grad_output * local_gradient
return grad_weights, grad_bias
五、Sigmoid的变体与改进
1. 双曲正切函数(Tanh)
tanh(x)=ex−e−xex+e−x=2σ(2x)−1 \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} = 2\sigma(2x) - 1 tanh(x)=ex+e−xex−e−x=2σ(2x)−1
- 值域:(-1, 1),零中心化输出
- 仍存在梯度消失问题
2. 硬Sigmoid(计算优化版)
def hard_sigmoid(x):
"""分段线性近似,用于低功耗设备"""
return np.clip((x + 1) / 2, 0, 1)
3. Logit函数:Sigmoid的逆函数
logit(p)=ln(p1−p) \mathrm{logit}(p) = \ln\left(\frac{p}{1-p}\right) logit(p)=ln(1−pp)
用于将概率转换回线性空间
六、现代深度学习中的局限性
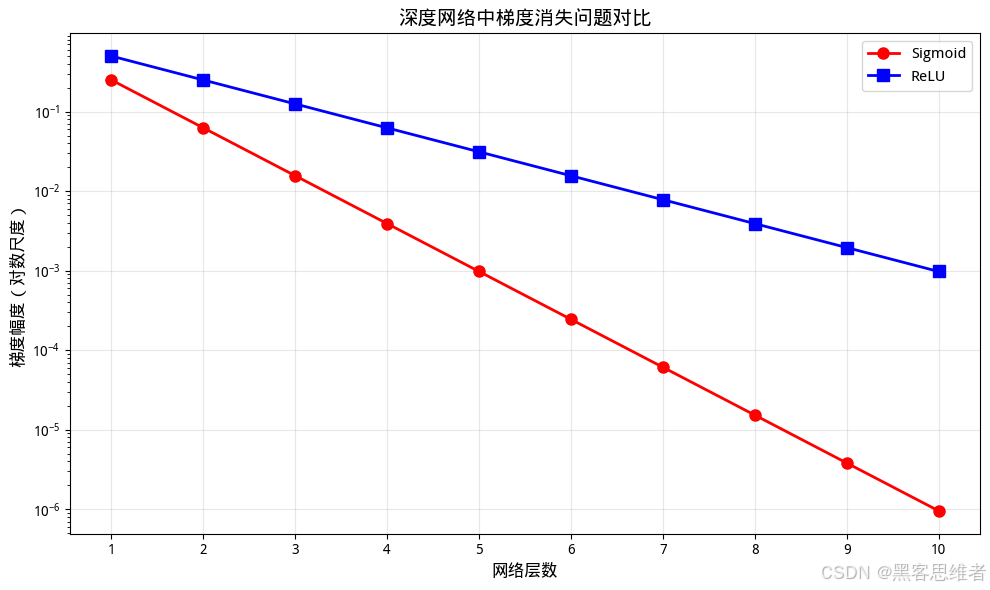
梯度消失问题:Sigmoid的阿喀琉斯之踵
实际对比:Sigmoid vs ReLU
import matplotlib.pyplot as plt
# 模拟深度网络训练
def simulate_gradient_flow(n_layers=10, activation='sigmoid'):
"""模拟梯度在深层网络中的流动"""
grad = 1.0
gradients = []
for i in range(n_layers):
if activation == 'sigmoid':
# 假设平均激活值在0.5,导数为0.25
grad *= 0.25
elif activation == 'relu':
# 假设50%的神经元激活,平均梯度0.5
grad *= 0.5
gradients.append(grad)
return gradients
# 可视化对比
layers = list(range(1, 11))
sigmoid_grads = simulate_gradient_flow(activation='sigmoid')
relu_grads = simulate_gradient_flow(activation='relu')
plt.figure(figsize=(10, 6))
plt.plot(layers, sigmoid_grads, 'ro-', label='Sigmoid', linewidth=2)
plt.plot(layers, relu_grads, 'bs-', label='ReLU', linewidth=2)
plt.yscale('log')
plt.xlabel('网络层数', fontsize=12)
plt.ylabel('梯度幅度(对数尺度)', fontsize=12)
plt.title('深度网络中梯度消失问题对比', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
七、Sigmoid的现代应用场景
尽管在深度神经网络隐藏层中失宠,Sigmoid仍在特定场景中不可替代:
1. 二分类输出层
class BinaryClassifier:
def __init__(self, n_features):
self.linear = nn.Linear(n_features, 1)
def forward(self, x):
# 最后一层使用Sigmoid输出概率
logits = self.linear(x)
probabilities = torch.sigmoid(logits)
return probabilities
def predict(self, x, threshold=0.5):
probs = self.forward(x)
return (probs >= threshold).float()
2. 门控机制(如LSTM、GRU)
在长短时记忆网络中,Sigmoid用于控制信息流动:
- 输入门:控制新信息的进入程度
- 遗忘门:控制旧信息的保留程度
- 输出门:控制内部状态的输出程度
3. 注意力机制中的评分函数
def attention_score_sigmoid(query, key):
"""使用Sigmoid的注意力评分"""
# 计算相关性分数
scores = torch.matmul(query, key.transpose(-2, -1))
# 使用Sigmoid而非Softmax,允许选择多个相关项
attention_weights = torch.sigmoid(scores)
return attention_weights
4. 概率校准
在需要精确概率估计的场景,如:
- 医疗风险评估
- 金融违约概率预测
- 推荐系统的点击率预估
八、实践建议:何时使用Sigmoid
| 场景 | 推荐使用 | 理由 |
|---|---|---|
| 二分类输出层 | ✅ 推荐 | 输出有界,天然概率解释 |
| 深度网络隐藏层 | ⚠️ 慎用 | 梯度消失问题严重 |
| 门控机制(LSTM) | ✅ 推荐 | 需要(0,1)区间的控制信号 |
| 多分类最后一层 | ❌ 不推荐 | 使用Softmax更合适 |
| 低精度/边缘计算 | ⚠️ 考虑硬Sigmoid | 计算复杂度较低 |
代码示例:安全使用Sigmoid的建议
class SafeSigmoidNetwork(nn.Module):
"""安全使用Sigmoid的网络设计"""
def __init__(self, input_dim, hidden_dims, output_dim):
super().__init__()
layers = []
prev_dim = input_dim
# 隐藏层:使用ReLU系列激活函数
for i, hidden_dim in enumerate(hidden_dims):
layers.append(nn.Linear(prev_dim, hidden_dim))
# 最后一层隐藏层之前使用ReLU
if i < len(hidden_dims) - 1:
layers.append(nn.ReLU())
else:
# 倒数第二层可使用LeakyReLU避免死亡神经元
layers.append(nn.LeakyReLU(0.01))
layers.append(nn.BatchNorm1d(hidden_dim)) # 批归一化帮助训练
layers.append(nn.Dropout(0.3)) # 防止过拟合
prev_dim = hidden_dim
# 输出层:二分类使用Sigmoid
layers.append(nn.Linear(prev_dim, output_dim))
if output_dim == 1: # 二分类
layers.append(nn.Sigmoid())
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
九、Sigmoid的哲学意义与未来展望
作为“软阈值”的认知启示
Sigmoid函数提供了一个关于确定性与不确定性的数学隐喻:
- 模糊边界:现实世界中的分类往往没有绝对界限
- 证据累积:决策基于多个证据的加权和
- 渐进确信:随着证据增加,置信度平滑变化而非突变
在可解释AI中的新角色
近年来,研究者重新审视Sigmoid在可解释性方面的优势:
def interpretable_decision(x, feature_names, weights, bias):
"""可解释的基于Sigmoid的决策"""
contributions = x * weights
logit = contributions.sum() + bias
print("决策分解:")
for i, (name, val, w, contrib) in enumerate(zip(feature_names, x, weights, contributions)):
print(f"{name}: {val:.2f} × {w:.3f} = {contrib:.3f}")
print(f"\n偏置项: {bias:.3f}")
print(f"逻辑斯谛值: {logit:.3f}")
print(f"最终概率: {sigmoid(logit):.1%}")
# 可视化贡献
plt.figure(figsize=(10, 4))
colors = ['green' if c > 0 else 'red' for c in contributions]
plt.barh(feature_names, contributions, color=colors)
plt.axvline(x=0, color='black', linestyle='--', alpha=0.5)
plt.xlabel("对决策的贡献度")
plt.title("可解释决策分析")
plt.show()
神经科学的新启示
最近神经科学研究发现,单个神经元的响应函数确实近似Sigmoid形状,这与早期认为的“全或无”原则形成了有趣的对话。大脑可能通过神经元群体的集体动力学来实现类似Sigmoid的平滑响应。
结语:Sigmoid的辉煌与黄昏
Sigmoid函数的历史是一部微缩的AI发展史:
- 起源期(19世纪):作为人口模型被发现
- 潜伏期(20世纪中叶):等待计算能力和神经科学的成熟
- 黄金期(1980-2010):成为神经网络的标准激活函数
- 转型期(2010至今):在隐藏层被ReLU取代,但在特定场景保持价值
正如生物进化保留了古老的基因片段用于新功能,深度学习也保留了Sigmoid这一“古早”函数,将其用于最适合的生态位。理解Sigmoid,不仅是理解一个数学函数,更是理解人工智能如何从简单的数学抽象走向复杂系统的认知历程。
在GPT-4、Transformer架构统治的今天,Sigmoid仍然在LSTM的门控机制、二分类输出层、概率校准等场景中默默工作——这或许是对其百年数学优雅的最好致敬。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 30
30 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)