用大白话讲解人工智能(10) 生成式AI:从“模仿“到“创造“的飞跃
2022年,一幅由AI生成的画作《太空歌剧院》在艺术比赛中击败人类选手夺冠,震惊了世界。这幅画细节丰富、意境悠远,很难想象它出自一个没有感情的机器之手。与此同时,ChatGPT能写出流畅的诗歌,Midjourney能生成"赛博朋克风格的猫",GitHub Copilot能帮程序员自动补全代码……这些AI不再只是"识别"或"分类"数据,而是能。这就是生成式AI(Generative AI)的革命——
生成式AI:从"模仿"到"创造"的飞跃
从"AI画画"看生成式AI的魔力
2022年,一幅由AI生成的画作《太空歌剧院》在艺术比赛中击败人类选手夺冠,震惊了世界。这幅画细节丰富、意境悠远,很难想象它出自一个没有感情的机器之手。
与此同时,ChatGPT能写出流畅的诗歌,Midjourney能生成"赛博朋克风格的猫",GitHub Copilot能帮程序员自动补全代码……这些AI不再只是"识别"或"分类"数据,而是能主动创造全新内容。
这就是生成式AI(Generative AI)的革命——它像一位会学习、会创作的艺术家,而不是只会按指令办事的工人。那么,这些AI是如何从"模仿"人类作品,走向"创造"全新内容的?
生成式AI vs 判别式AI:两种不同的"AI思维"
判别式AI:给事物"贴标签"的分类高手
我们之前讲的线性回归、CNN、RNN都属于判别式AI:
- 输入一张图片 → 判断"这是猫还是狗"(分类)
- 输入一段文字 → 判断"正面情绪还是负面情绪"(情感分析)
- 核心逻辑:从数据中找规律,给输入贴标签
就像语文考试中的"阅读理解":给你一篇文章,回答"作者表达了什么情感"——你不需要自己写文章,只要分析判断即可。
生成式AI:会"写文章"的创作高手
生成式AI则完全不同:
- 输入"一只穿着西装的猫,在月球上喝咖啡" → 生成一张全新图片
- 输入"写一首关于春天的七言绝句" → 生成一首原创诗歌
- 核心逻辑:学习数据的概率分布,创造符合规律的新内容
就像语文考试中的"作文题":给你一个主题,你需要写出一篇全新的文章——不仅要符合语法,还要有创意。
生成式AI的"学画之路":从临摹到原创
阶段1:像素级模仿(早期生成模型)
最早的生成式AI像刚学画的小孩,只会"描红":
- 比如生成人脸时,它会记住训练数据中"眼睛通常在鼻子上方"、"嘴巴通常在鼻子下方"这些规律
- 但生成的图片往往模糊不清,甚至出现"三眼两嘴"的怪胎
这是因为早期模型(如GAN)学习能力有限,只能捕捉简单的像素规律,无法理解高层语义。
阶段2:风格迁移(学会"画风")
后来的模型学会了"临摹大师作品":
- 给AI一张你的照片和梵高《星月夜》的画风,它能生成"梵高风格的你"
- 原理:把"内容"和"风格"分离,保留内容(你的脸),替换风格(梵高笔触)
这就像美术生临摹毕加索——能模仿画风,但还不能原创构图。
阶段3:自由创作(真正的生成式AI)
现在的GPT、Midjourney已经能像成熟艺术家一样创作:
- 你说"赛博朋克风格的猫,戴着墨镜,坐在飞行器上",AI能生成从未存在过的画面
- 关键突破:Transformer架构+海量数据+自回归生成
就像学画多年的画家,看过 millions 幅画后,能根据想象创造全新作品——既符合艺术规律,又充满创意。
生成式AI的"创作秘籍":自回归与概率预测
用"接龙游戏"理解自回归生成
生成式AI创作的过程,就像玩"成语接龙":
- 先随机选一个开头(如"今天")
- 根据训练数据,预测下一个词最可能是"天气"(因为"今天天气"最常见)
- 再根据"今天天气",预测下一个词是"很好"
- 继续下去,生成"今天天气很好,我想去公园散步"
自回归(Autoregressive) 就是这种"生成一个词,再用这个词预测下一个词"的过程,像链条一样环环相扣。
用"概率骰子"理解生成决策
AI生成内容时,每个选择都是"掷概率骰子":
- 输入"我想吃",AI会计算:
- "火锅"的概率30%,"米饭"的概率25%,"面条"的概率20%…
- 它不会每次都选概率最高的(那样会很单调),而是按概率随机选择
- 30%概率选"火锅",25%选"米饭",增加多样性
这就是为什么同一个提示词,GPT能生成不同版本的文章——它在概率允许的范围内"自由发挥"。
生成式AI的"三大门派"
1. 文本生成:GPT系列( decoder-only Transformer)
GPT像一位"语言大师",只靠Transformer的解码器就能生成流畅文本:
- 训练数据:互联网上的数万亿单词(书籍、网页、论文)
- 核心能力:理解上下文,生成符合语法和逻辑的长文本
- 局限:有时会"一本正经地胡说八道"(幻觉现象)
2. 图像生成:Diffusion Models(扩散模型)
Midjourney、Stable Diffusion属于扩散模型,生成图片的过程像"从模糊到清晰":
- 步骤1:给一张全是噪音的图
- 步骤2:慢慢去除噪音,同时根据提示词(如"猫戴墨镜")调整像素
- 步骤3:最终生成清晰图片
就像画家作画:先打草稿(模糊),再逐步细化(清晰)。
3. 多模态生成:DALL-E、GPT-4(图文互通)
这些模型能理解文字生成图片,或理解图片生成文字:
- 输入"一只穿着西装的企鹅在会议室做报告" → 生成对应图片
- 输入一张风景照 → 生成"夕阳西下,湖面波光粼粼,远处山峦叠嶂"
它们就像"跨语言翻译官",能在文字和图像之间自由转换。
为什么生成式AI突然爆发?三大关键技术
1. Transformer架构:给AI"全局视野"
Transformer的注意力机制让AI能同时理解整个句子/图像,避免RNN的"健忘症",为长文本/复杂图像生成奠定基础。
2. 海量数据:喂饱"饥饿的AI"
生成式AI需要"读万卷书,行万里路":
- GPT-3训练了45TB文本数据(相当于1000万本书)
- 图像模型训练了数十亿张图片
数据越多,AI的"创作素材"就越丰富。
3. 算力革命:GPU集群的"暴力美学"
训练GPT-3需要上万块GPU跑几个月,电费高达数百万美元。正是云计算的算力支持,才让这些庞然大物得以诞生。
生成式AI的"创作边界":它真的会"创造"吗?
本质:重组已有知识,而非真正创新
AI生成的内容,本质是对训练数据的高级重组:
- 它能写出"新诗歌",但用的是人类语言的语法和词汇
- 它能画出"新画作",但用的是人类艺术的构图和色彩
就像拼乐高:用已有积木块拼出新造型,但积木本身不是它发明的。
优势:规模和速度的碾压
- 人类画家画一幅油画可能需要一周,AI只需10秒
- 人类作家写一本小说需要半年,AI能在1小时内生成多版大纲
这种"量产创意"的能力,正在改变设计、写作、编程等行业。
局限:缺乏真实理解和情感
AI写"母爱"的诗歌,文字优美但没有真情实感;画"悲伤的人",表情到位但不懂悲伤的含义。它只是在模仿人类表达情感的"模式",而非真正拥有情感。
生活中的生成式AI:从"玩具"到"工具"
案例1:设计师的"灵感助手"
- 需求:为咖啡店设计logo,要求"温暖、自然、有咖啡元素"
- AI:1分钟生成20个方案,设计师从中挑选修改,效率提升10倍
案例2:程序员的"结对编程伙伴"
- 需求:写一个"用户登录页面的Python代码"
- AI:生成基础代码,程序员只需调整细节,减少重复劳动
案例3:学生的"学习辅导"
- 需求:用通俗语言解释"相对论"
- AI:生成多个版本的解释,从"类比法"到"数学公式",直到学生理解
小问题:生成式AI会让人类失去创造力吗?
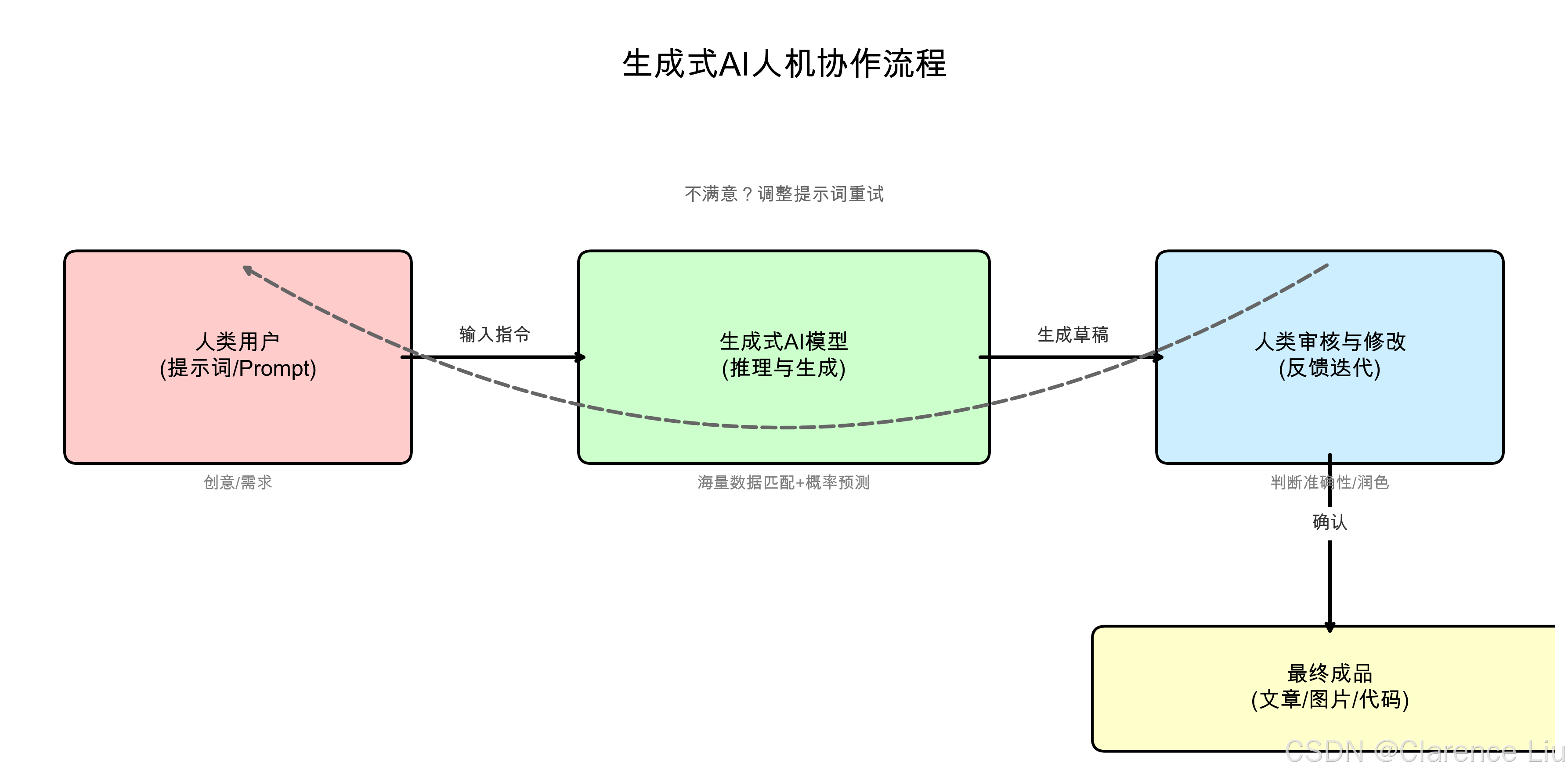
(提示:不会。AI更像"创意催化剂"——它能快速生成大量初稿,人类则负责筛选、修改和提升,把时间花在更高级的创意决策上。就像计算器没让人类失去计算能力,反而让我们能解决更复杂的数学问题。)
下一篇预告:《向量数据库:AI的"长期记忆"是如何实现的?》——用"图书馆索引"的例子,讲透大模型为什么需要向量数据库来存储知识。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)