【有啥问啥】Contrastive Captioners(CoCa):对比式图像描述模型——图像-文本基础模型的新范式
随着深度学习技术的发展,多模态模型在处理视觉和语言任务方面的能力逐渐增强。特别是大规模预训练模型的兴起,使得这些模型可以快速迁移到许多下游任务中。本文深入探讨了CoCa(ContrastiveCaptioner),这是一种新的图像-文本对齐模型,旨在同时优化对比学习和图像描述的任务。通过结合对比损失和图像描述损失,CoCa能够在一个统一的框架内实现单模态、双模态以及生成任务的有效处理。
Contrastive Captioners(CoCa):对比式图像描述模型——图像-文本基础模型的新范式
引言
随着深度学习技术的发展,多模态模型在处理视觉和语言任务方面的能力逐渐增强。特别是大规模预训练模型的兴起,使得这些模型可以快速迁移到许多下游任务中。本文深入探讨了CoCa(Contrastive Captioner),这是一种新的图像-文本对齐模型,旨在同时优化对比学习和图像描述的任务。通过结合对比损失和图像描述损失,CoCa能够在一个统一的框架内实现单模态、双模态以及生成任务的有效处理。
背景
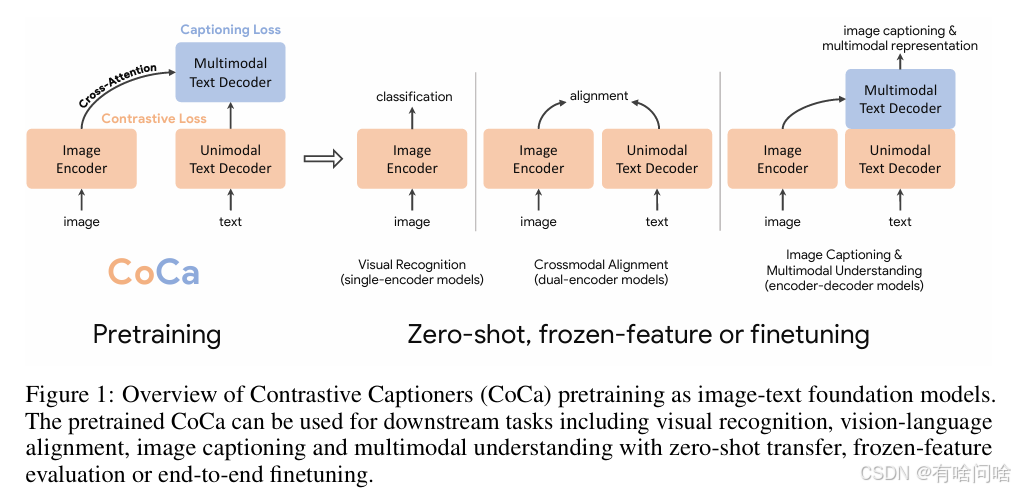
传统上,计算机视觉领域内的模型通常专注于单一任务,如图像分类或目标检测。然而,当涉及到理解和生成图像与文本之间的关系时,就需要更加复杂的模型来捕捉两者间的交互。CLIP(Contrastive Language–Image Pre-training)是早期的成功案例之一,它使用对比损失函数训练两个独立的编码器分别对图像和文本进行编码,并将它们映射到相同的潜在空间中,从而实现了跨模态检索的功能。另一方面,SimVLM则采用了编码器-解码器结构来进行图像描述生成,这种方法允许模型从输入图像中学习到丰富的语义信息,并据此产生自然语言描述。尽管这两种方法各有千秋,但它们也存在局限性,例如CLIP不擅长于生成任务,而SimVLM对于跨模态对齐的支持不够直接。
CoCa 的核心思想
为了克服上述限制,CoCa引入了一种全新的设计思路,即利用一个改进版的编码器-解码器架构,该架构能够在同一时间内完成对比学习和生成式学习两项任务。具体而言:
-
统一的编码器-解码器架构:CoCa基于Transformer构建,其中编码器负责提取图像特征,而解码器则用于生成相应的文本描述。这种设计不仅简化了模型结构,还提高了计算效率。
-
对比损失:CoCa通过对成对的图像和文本样本施加对比损失,确保正样本对(匹配的图像-文本对)在嵌入空间中的距离更近,而负样本对(非匹配的图像-文本对)则保持较远的距离。这有助于模型学会区分相关联的视觉和语言信息。
-
图像描述损失:除了对比损失外,CoCa还应用了图像描述损失,鼓励解码器根据给定的图像生成合理的句子。此过程采用自回归的方式逐词预测下一个token,直到生成完整的句子为止。
-
部分解码器层的改进:不同于传统的编码器-解码器Transformer,CoCa在解码器的前半部分省略了交叉注意力机制,仅保留自注意力以编码纯文本表示;而在后半部分,则加入了交叉注意力层,使得解码器可以直接访问来自图像编码器的信息,进而促进多模态融合。
-
端到端预训练:CoCa可以在网络规模的数据集上进行端到端的预训练,无需额外的监督信号。这意味着它可以利用大量的无标签数据来提升自身的泛化能力。
CoCa 的优势
相比之前的模型,CoCa展现出了几个重要的优点:
-
更高的效率:由于共享了相同的计算图并且减少了不必要的计算步骤,CoCa可以在更短的时间内完成训练,并且在推理阶段也能表现出更快的速度。
-
更强的通用性:得益于其独特的架构设计,CoCa不仅适用于图像分类、检索等标准视觉任务,还可以很好地应用于视觉问答、图像字幕生成等需要理解图像内容的任务。
-
更好的零样本迁移能力:借助对比学习的力量,CoCa即使是在没有见过特定类型的任务时,也能够有效地执行它们。例如,在ImageNet上的零样本top-1准确率达到了86.3%,而在经过微调后更是提高到了91.0% 。
实验结果
实验表明,CoCa在多个基准测试集上均取得了优异的成绩。特别是在视觉识别(ImageNet)、跨模态检索(MSCOCO, Flickr30K)、多模态理解(VQA, SNLI-VE, NLVR2)及图像描述(MSCOCO, NoCaps)等方面,CoCa均展示了超越现有技术水平的表现。此外,CoCa还在Kinetics-400/600/700视频分类任务上获得了88.0%/88.5%/81.1%的好成绩,进一步证明了其广泛的适用性和强大的性能。
结论
综上所述,CoCa代表了一种新的图像-文本基础模型范式,它通过巧妙地整合对比学习和生成式学习,实现了单模态、双模态乃至更多样化的任务处理。CoCa的成功为未来的研究提供了宝贵的启示,即通过构建更为复杂和灵活的多模态模型,我们可以更好地解决实际世界中存在的各种挑战。随着研究的不断深入和技术的进步,预计会有越来越多像CoCa这样的创新成果涌现出来,推动人工智能领域的持续发展。
参考文献:
- CoCa: Contrastive Captioners are Image-Text Foundation Models: https://arxiv.org/abs/2205.01917

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)