在亚马逊云科技上构建安全、负责任的多模态AI应用
在上个月的2024年亚马逊云科技“全球春晚”-re:Invent大会上,亚马逊云科技人工智能产品副总裁Swami介绍了AI模型管理平台AmazonBedrock上用于构建安全的AI应用的功能-Guardrails新增了支持图像的多模态有害内容检测功能。这个功能让Guardrails,不仅可以检测和过滤文本中的不良内容,还能识别和拦截图像中的不良内容,帮助开发者在亚马逊云科技上构建安全、负责任的多模
在上个月的2024年亚马逊云科技“全球春晚” - re:Invent大会上,亚马逊云科技人工智能产品副总裁Swami介绍了AI模型管理平台Amazon Bedrock上用于构建安全的AI应用的功能 - Guardrails新增了支持图像的多模态有害内容检测功能。这个功能让Guardrails,不仅可以检测和过滤文本中的不良内容,还能识别和拦截图像中的不良内容,帮助开发者在亚马逊云科技上构建安全、负责任的多模态AI应用,下面请跟随小李哥一起体验下这次的新功能在应用开发过程中的使用效果吧。

Amazon Bedrock Guardrails是什么?
Amazon Bedrock Guardrails的主要功能是为我们在云端构建生成式AI应用提供多重保障,包括过滤不良内容、删除个人身份信息(PII),以及提升内容的安全性和隐私性。开发者们可以根据具体使用场景和负责任的 AI 策略,配置多样的安全策略,包括禁止回复话题、内容过滤、词语过滤器、PII(个人敏感信息)删除、上下文验证的准确性检查以及根据预定回复策略文档的自动推理检查。
除了以上的文字内容过滤外,Amazon Bedrock Guardrails还可以检测并拦截以下类别的有害图像内容:如仇恨(Hate)、侮辱(Insults)、色情(Sexual)和暴力(Violence)。我们可以根据应用需求设置检测阈值,数值从低(对应宽松检测)到高(严格检测)进行灵活调整。
目前图像内容审查功能适用于Amazon Bedrock上生成图片的所有基础模型(FMs),或者开发者们自己经过微调的自定义模型。Guardrails就相当于在模型输出和应用返回之间加了一个多模态保护层,帮助我们在构建负责任的AI应用时更加便捷高效。
如何配置和使用Amazon Bedrock Guardrails?
创建和使用Amazon Bedrock Guardrails的方式可以有两种,可以既可以在亚马逊云科技控制台中创建防护规则,并针对文本或图像数据配置内容过滤器,还可以使用亚马逊云科技提供的SDK将集成到的应用程序中进行过滤。
1)创建防护规则
1. 我们登录亚马逊云科技控制台,导航到Amazon Bedrock并选择Guardrails功能。
2. 在界面中选择创建一个新的防护规则。或者使用现有的内容过滤器,配置规则以检测并拦截图像数据以及文本数据中的不良内容。创建防护规则的步骤如下。
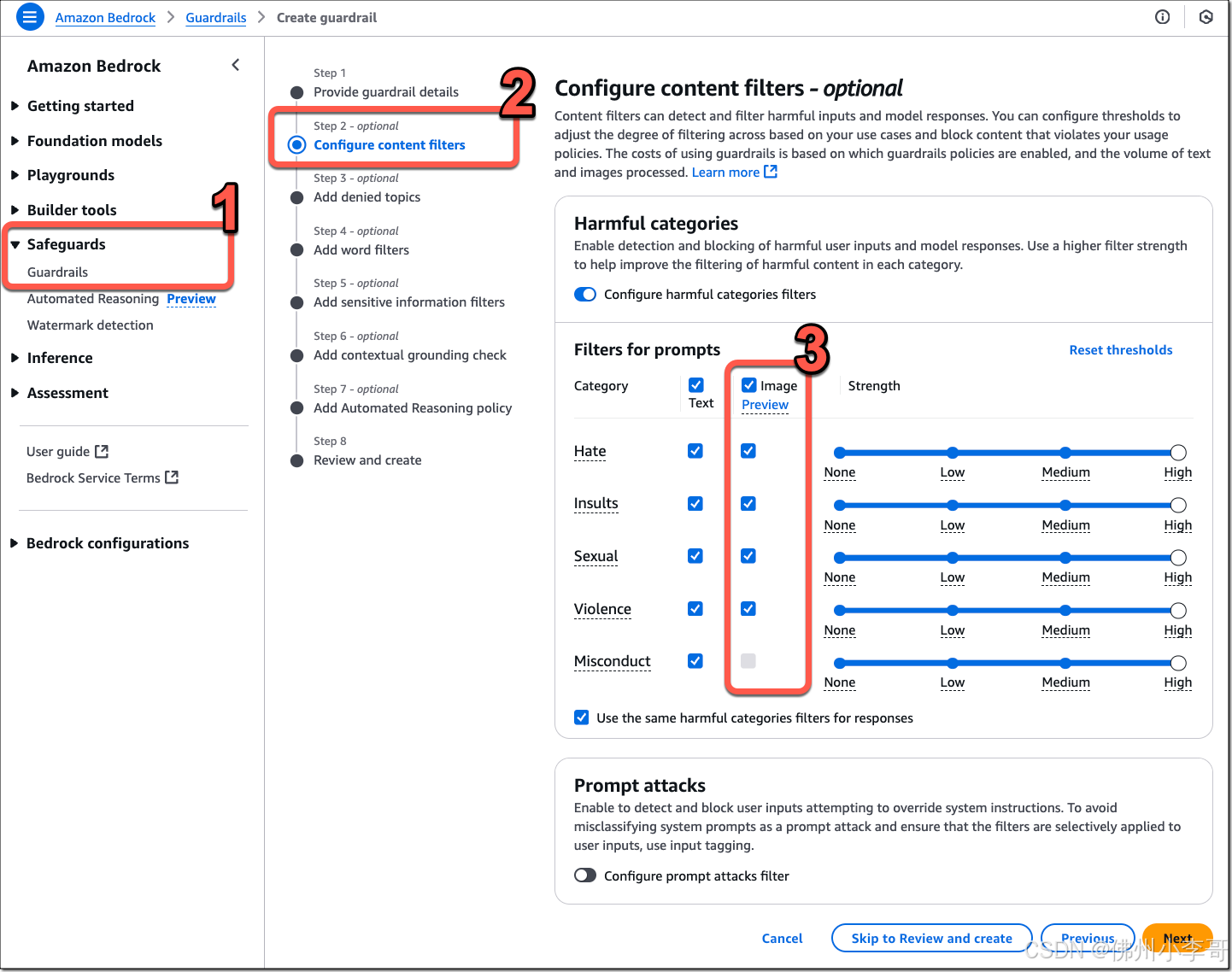
我们可以看到图片中图片过滤类别包括四类:仇恨(Hate)、侮辱(Insults)、色情(Sexual)、暴力(Violence)。这些类别可以用于对文本、图像内容或两者同时进行配置。同时可以看到文本过滤相对于图片过滤,有·不当行为(Misconduct)和提示攻击(Prompt attacks)额外两个类别。我们可以通过灵活的配置选项,根据具体的应用需求调整过滤策略,更好地保护生成式AI应用程序免受不良内容的影响。
2) 通过API测试Guardrails功能
在我们创建好Guardrails过滤器后,我们可以在控制台中测试新的防护规则,选择该规则并点击“测试”(Test)即可开始测试。我们可以用过两种方式进行测试
1. 直接选择并并将Guardrail加载,通过向模型提问来测试防护规则。
2. 使用Amazon Bedrock Guardrails独立的ApplyGuardrail API测试防护规则,而无需调用模型。
通过ApplyGuardrail API,我们可以在应用开发流程中的任意环节验证内容,在向终端用户展示结果之前进行处理。该API还可以用于评估任何我们自己预训练的模型或第三方基础模型的输入和输出。比如我们可以使用该API评估托管在 Amazon SageMaker上的开源Meta Llama 3.2模型,或者运行在我们本地Jupyter Notebook上的Mistral NeMo模型。ApplyGuardrail API的调用脚本如下:
response = client.apply_guardrail(
guardrailIdentifier='string',
guardrailVersion='string',
source='INPUT'|'OUTPUT',
content=[
{
'text': {
'text': 'string',
'qualifiers': [
'grounding_source'|'query'|'guard_content',
]
},
'image': {
'format': 'png'|'jpeg',
'source': {
'bytes': b'bytes'
}
}
},
]
)在AI应用中验证Guardrails的多模态过滤效果
下面我们就详细给大家介绍下如何通过这两种方式验证我们配置好的Guardrails功能。
通过向模型提问测试回复中的多模态防护效果
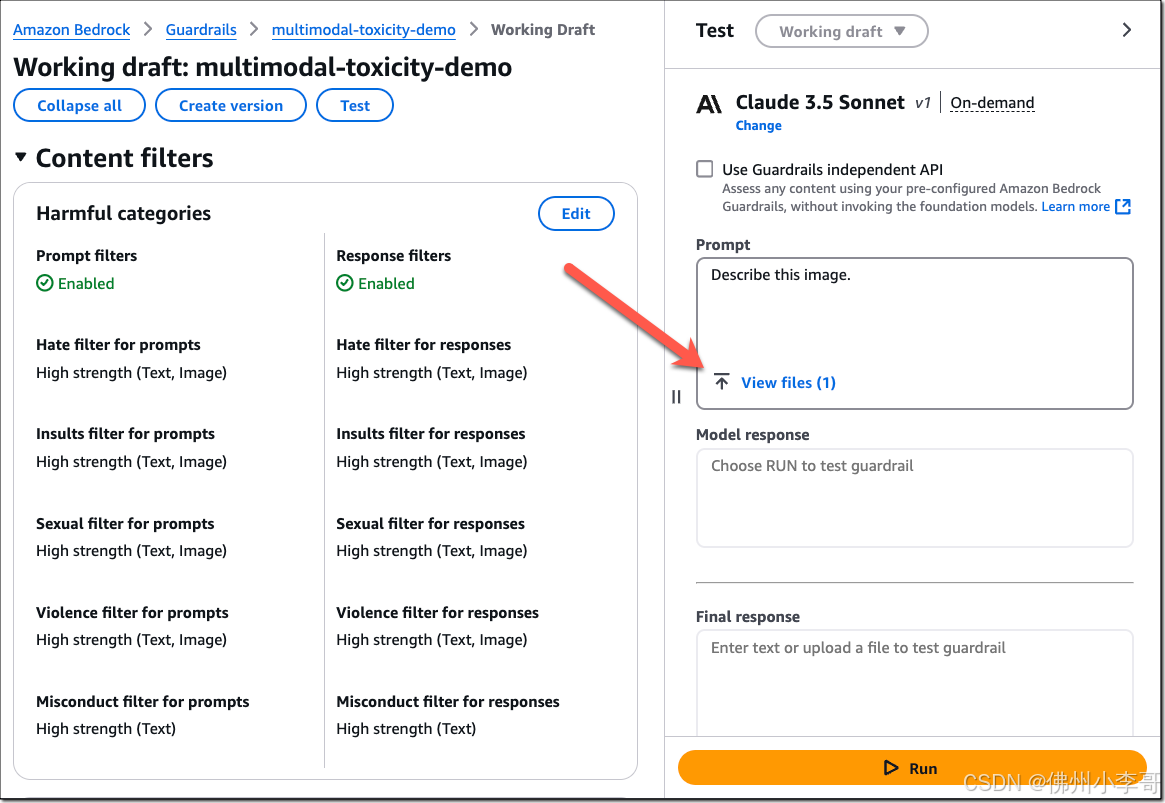
首先我们选择一个支持图像输入或输出的模型,例如Anthropic的Claude 3.5 Sonnet。验证是已开启提示和响应过滤器。接下来,我们输入一个提示语“形容一下这个图片”,上传一个图像文件,并选择“运行”(Run)。
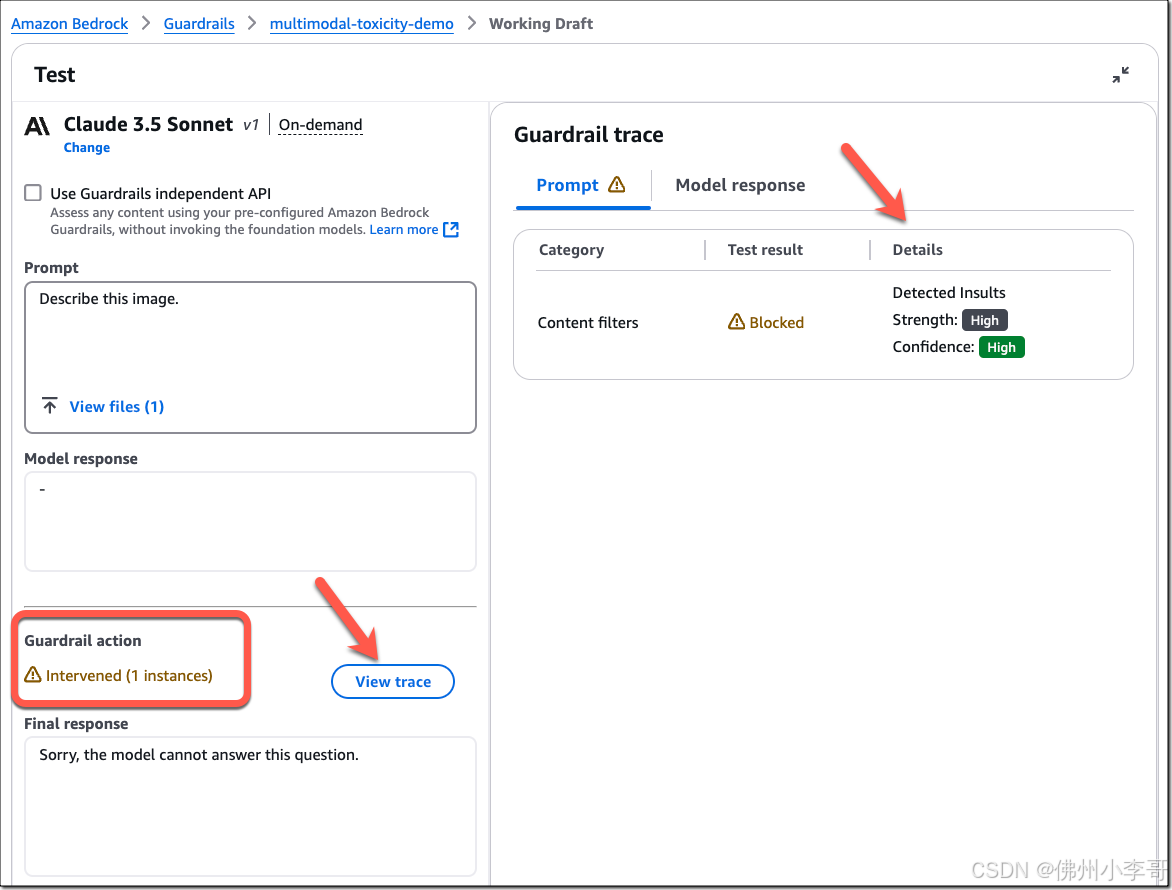
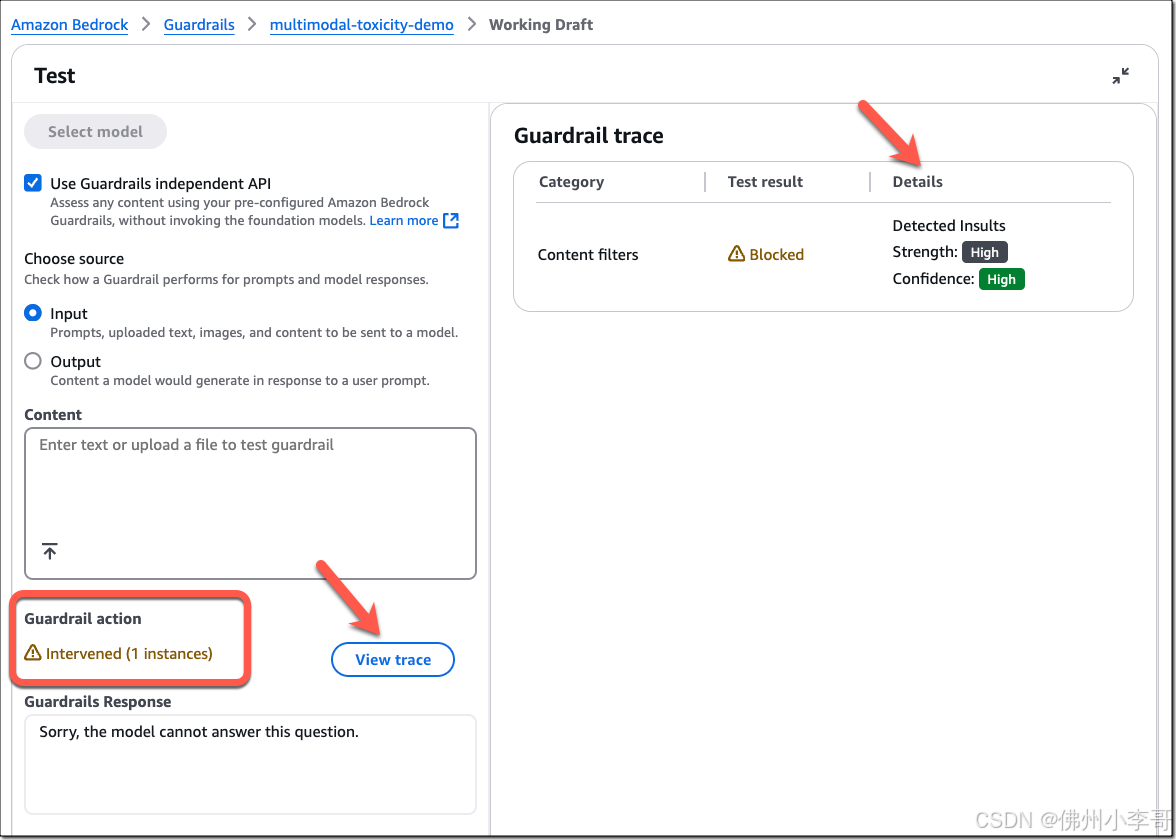
在下图中,我们可以看到Amazon Bedrock Guardrails检测到了有害内容,并进行了干预(intervened)。我们嫩选择“查看跟踪”(View trace)查看详细的干预信息。点击后我们可以看到,防护规则跟踪提供了关于交互期间如何应用图片防护安全措施的记录。它分别显示了Amazon Bedrock Guardrails是否进行了干预(test result显示阻止),以及对输入(提示语)和输出(模型响应)进行了哪些评估(侮辱性检测)。在该示例中,内容过滤器阻止了输入提示,因为它在图像中以高置信度检测到了侮辱性内容。
通过API测试模型测试防护规则
接下来我们通过前面提到的ApplyGuardrail API,不调用模型生成回复测试防护规则。
在亚马逊云科技Bedrock控制台中,我们勾选Use Guardrails independent API,通过独立的API测试防护规则而无需调用模型。选择对输入提示或模型生成输出的过滤规则。然后重复之前的步骤,确认过滤器已对图像内容启用,提供需要验证的图片内容,输入提示词,并选择“运行”(Run)。
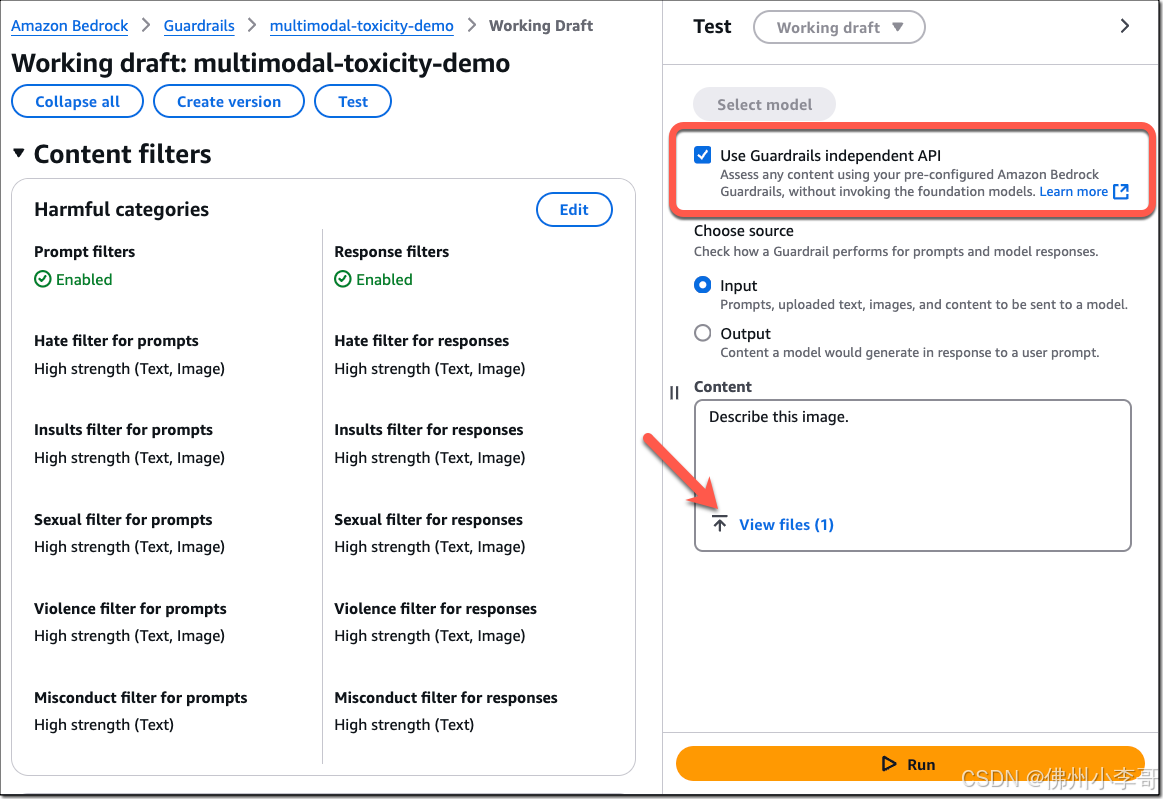
在检测结果中我们可以看到,我们上传了相同的图像,输入了相同提示词,Amazon Bedrock Guardrails再次进行了干预。选择“查看跟踪”(View trace)查看详细信息,可以看到这次得到相同的阻止记录。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)