【深度学习】基于 K-means 聚类算法的图像区域分割(Matlab代码实现)
K-means聚类算法的基本思想是以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。初始化:随机选择K个数据点作为初始的聚类中心。分配数据点到最近的聚类中心:对于数据集中的每个数据点,计算其到每个聚类中心的距离,并将其分配到最近的聚类中心。更新聚类中心:根据每个聚类中的数据点,重新计算聚类中心。新的聚类中心是聚类中所有数据点的均值
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
数据聚类是最基础和最重要的数据分析手段,实现对海量数据快速智能的聚类分析对于帮助整理、摘要和储存数据具有重要意义。在大数据和人工智能快速发展的背景下,传统聚类算法逐渐不能满足人们的实际需求,基于深度神经网络的聚类方法成为当前领域的热门研究方向。现有的深度聚类算法普遍存在目标函数易退化、泛化能力弱、训练不稳定和无监督神经网络表达性不足等问题。如何设计具有强表达性、泛化性、稳定性的深度聚类算法是人工智能中至关重要的研究问题。致力于克服现有深度聚类存在的研究难点,从目标函数设计、数据增强技术、自步学习算法、同变性特征和自监督表示学习等方面,研究如何提升深度聚类学习特征的质量,最终提高聚类性能。为了进一步解决深度聚类在背景复杂接近自然的图像数据上表现不佳的问题,提出基于图像平移的自监督表示学习算法。自监督学习方法通过预测施加在数据上的变换来为神经网络提供监督信息,实践证明用这种监督信息可以训练更加复杂的神经网络,以及在复杂数据集上学习具有判别性的特征。但现有的基于几何变换的自监督方法受变换产生的边缘效应的影响,性能还有待提升。为了解决该问题,我们设计了预测图像平移的像素个数的自监督任务,并通过对同一平移方向的图像施加相同的掩码来消除边缘效应对该任务的影响。实验证明提出的自监督方法能在复杂图像数据集上学习具有很强判别性的特征,为深度聚类提供了新的特征学习模型。 图像分割是图像分析和模式识别的首要问题,它在很大程度上决定着图像的最终质量分析和判别分析的结果,半监督聚类是目前机器学习和数据挖掘领域的一个研究热点,吸引了众多学者对该领域进行研究,并取得了一定的研究成果。本文对图像分割方法和半监督聚类方法进行了研究,提出了两种基于半监督聚类的图像分割算法,并通过实验对其分割效果进行了验证,一定程度上丰富了图像分割算法的研究内容,给图像分割问题的求解提供了新的思路,具有一定的科研价值和应用潜力。
一、引言
图像分割是图像处理、模式识别和人工智能等多个领域中一个十分重要且又十分困难的问题,是计算机视觉技术中首要的、重要的关键步骤。K-means聚类算法作为一种无监督学习的聚类方法,在图像分割中得到了广泛应用。本文旨在探讨基于K-means聚类算法的图像区域分割技术。
二、K-means聚类算法概述
K-means聚类算法的基本思想是以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。算法的关键步骤包括:
- 初始化:随机选择K个数据点作为初始的聚类中心。
- 分配数据点到最近的聚类中心:对于数据集中的每个数据点,计算其到每个聚类中心的距离,并将其分配到最近的聚类中心。
- 更新聚类中心:根据每个聚类中的数据点,重新计算聚类中心。新的聚类中心是聚类中所有数据点的均值。
- 迭代优化:重复分配数据点和更新聚类中心的步骤,直到满足停止条件(如聚类中心的变化小于某个阈值,或达到预设的最大迭代次数)。
三、K-means聚类算法在图像分割中的应用
在图像处理中,K-means聚类算法常用于图像分割。算法可以将图像中的像素点按照颜色、纹理等特征划分为不同的区域,从而实现图像的自动分割。
1. 灰度图像分割
对于灰度图像,K-means聚类算法可以将像素点聚类成K个簇,然后使用每个簇内的质心点来替换簇内所有的像素点,从而实现图像颜色的量化压缩和层级分割。
2. 彩色图像分割
对于彩色图像,K-means聚类算法可以按照颜色特征将图像分割成不同的区域。算法将图像中的每个像素点视为一个数据点,并根据其颜色值(如RGB值)进行聚类。通过调整K值,可以得到不同数量的聚类结果,从而实现不同粒度的图像分割。
四、K-means聚类算法的优缺点及改进方法
优点
- 简单易懂:K-means聚类算法的原理简单,易于理解和实现。
- 计算速度快:该算法的计算效率较高,适用于大数据集的聚类分析。
- 可扩展性好:随着数据规模的扩大,K-means聚类算法仍然能够保持较好的性能。
局限性
- 需要预先设定聚类数目K:K值的选择对聚类结果有很大影响,但往往很难预先确定。
- 对初始聚类中心敏感:初始聚类中心的选择会影响最终的聚类结果,导致结果的不稳定性。
- 容易陷入局部最优解:K-means聚类算法在迭代过程中可能陷入局部最优解,导致聚类效果不佳。
改进方法
- K-means++算法:通过改进初始聚类中心的选择方法,提高聚类结果的稳定性和准确性。
- 基于密度的聚类方法:引入密度信息来优化聚类过程,提高算法对噪声数据和异常值的处理能力。
- 结合其他智能优化算法:如遗传算法、粒子群优化算法等,以优化K-means算法的聚类过程,提高全局搜索能力和寻优能力。
五、实验与结果分析
为了验证K-means聚类算法在图像分割中的有效性,可以进行一系列实验。选择不同的图像数据集,分别应用K-means聚类算法进行图像分割,并对比分割结果。通过实验可以发现,K-means聚类算法在图像分割中具有较好的性能,能够准确地将图像划分为不同的区域。同时,通过调整K值和优化算法参数,可以进一步提高分割效果。
六、结论与展望
本文探讨了基于K-means聚类算法的图像区域分割技术,并分析了该算法的优缺点及改进方法。实验结果表明,K-means聚类算法在图像分割中具有广泛的应用前景。未来可以进一步研究如何自动确定K值、提高算法的稳定性和准确性以及将K-means聚类算法与其他图像处理技术相结合以实现更高效的图像分割方法。
📚2 运行结果
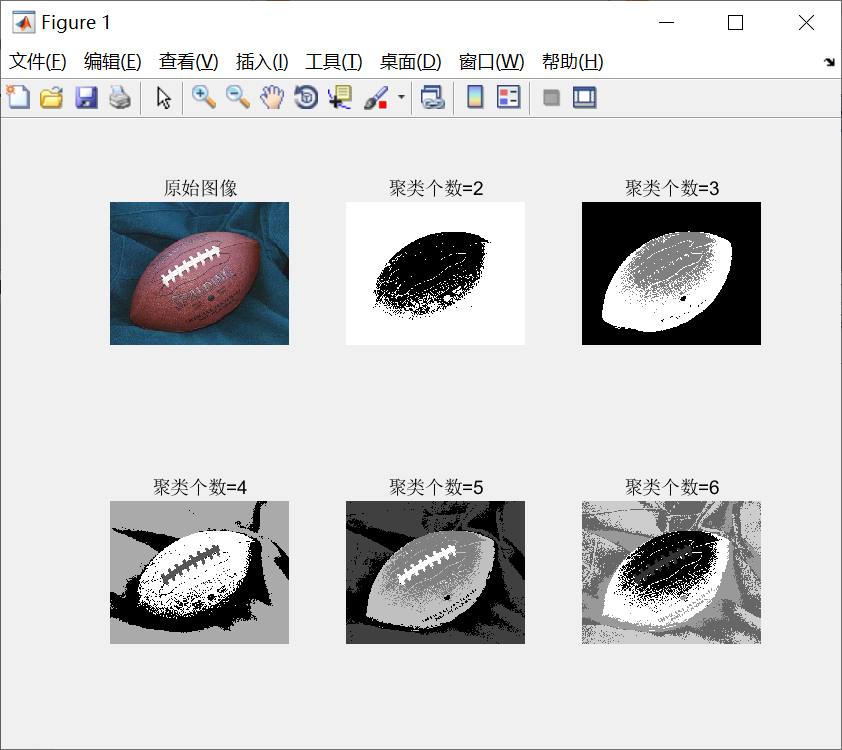
部分代码:
主函数
clc
close all
I=imread('football.jpg');
I=double(I)/255;
subplot(2,3,1)
imshow(I)
title('原始图像')
for i=2:6
F=imkmeans(I,i);
subplot(2,3,i);
imshow(F,[]);
title(['聚类个数=',num2str(i)])
end
其中部分子函数:
function [center]=searchcenter(X,kratio)
[n,~]=size(X);
isleft=true(n,1);
count=zeros(n,1);
center=[];
kind=0;
dist=0;
for i=1:n
for j=i+1:n
dist=dist+weightdist(X(i,:),X(j,:));
end
end
dist=dist/((n-1)*(n-1)/2);
radius1=dist*kratio(1);
radius2=dist*kratio(2);
while any(isleft)
for i=1:n
count(i)=0;
if isleft(i)
for j=1:n
if isleft(j)
dist=weightdist(X(i,:),X(j,:));
count(i)=count(i) + dist<=radius1;
end
end
end
end
[~,locs]=max(count);
iscenter=true;
for i=1:kind
dist=weightdist(X(locs,:),center(i,:));
iscenter=iscenter && dist>=radius2;
if ~iscenter
break;
end
end
if iscenter
kind=kind+1;
center(end+1,:)=X(locs,:);
for i=1:n
if isleft(i)
dist=weightdist(X(i,:),X(locs,:));
if dist <= radius1
isleft(i)=false;
end
end
end
else
isleft(locs)=false;
end
end
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]郭西风. 基于深度神经网络的图像聚类算法研究[D].国防科技大学,2020.DOI:10.27052/d.cnki.gzjgu.2020.000056.
[2]谭静. 基于半监督聚类的图像分割算法研究[D].中国海洋大学,2012.
🌈4 Matlab代码实现

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 17
17 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)