[TNNLS 2024]An Efficient Graph Learning System for Emotion Recognition Inspired by the Cognitive Pri
计算机-人工智能-EEG情绪识别

论文代码:https://github.com/UESTC-BAC/BF-GCN
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.1. EEG-Based Emotion Recognition System
2.3.2. Emotion Recognition With Deep Learning
2.3.3. Transfer Learning of Emotion Recognition
2.4.1. Basic Theory of Spectral Graph Filtering
2.4.2. BF-GCN Graph Learning System for Emotional EEG
2.5.1. Subject-Dependent Experiments
2.5.2. Subject-Independent Experiments
2.5.3. Confusion Matrix on Two Datasets
2.6.1. Computational Efficiency Analysis
2.6.4. Cognitive Graph Pattern Analysis
3.2. logarithm energy spectrum
1. 心得
(1)从此ref改成bib记录了
(2)我好像知道为什么EEG用相位锁定值而fmri用皮尔逊?我是fmri的不懂EEG,有没有好心人能解答一下啊,ds回答了和没回答怎么没什么两样。纯因为高低频不一样吗?:

(3)怎么比fMRI多出了那么多数学
2. 论文逐段精读
2.1. Abstract
①High temporal resolution makes EEG as a excellent tool for emotion recognition
②For achieving effective EEG decoding and emotion recognition, they proposed Graph Convolutional Network framework with Brain network initial inspiration and Fused attention mechanism (BF-GCN)
③Datasets: SEED and SEED-IV
2.2. Introduction
①Non physiological signals such as posture, movement, and expression may conceal true emotions
2.3. Related Work
2.3.1. EEG-Based Emotion Recognition System
①2 widely used emotional models for affective computing: the discrete emotion model and the dimensional emotion model
②Introduced how other reseachers extract EEG features
2.3.2. Emotion Recognition With Deep Learning
①Lists some DL applied in emotion recognition
2.3.3. Transfer Learning of Emotion Recognition
②Domain generalization helps cross subject experiment
2.4. Methodology
①Overall framework:

2.4.1. Basic Theory of Spectral Graph Filtering
①A basic graph:
②Laplacian matrix: where
denotes degree matrix and
denotes adjacency matrix
③Spectral graph filtering transform given spatial signal to
, where
is graph filter obtained by
,
is orthonormal Fourier basis of graph
,
④Inverse graph Fourier transform:
⑤Graph convolution in 2 signals in graph spectral domain:
where denotes element wise Hadamard product
⑥A filtering function can be applied as:
and further:
which can extract differential entropy (DE) feature in emotion EEG signals
2.4.2. BF-GCN Graph Learning System for Emotional EEG
(1)Processing and DE Feature Extraction of Emotional EEG
①Segmenting original signal to segments with a length of 1 s, and employing bandpass filtering including delta (1–4 Hz), theta (4–8 Hz), alpha (8–14 Hz), beta (14–30 Hz), and gamma (30–48 Hz)
②For EEG signals which are assumed to obey the Gaussian distribution have such a DE:
where ,
(2)Cognition-Inspired Functional Graph Branch
①Phase synchronization:
where constructs adjacency matrix
②The graph convolution operator of cognition-inspired functional graph branch:
③Simplify feature extraction by -order Chebyshev polynomials:
where is Chebyshev coefficient and
is Chebyshec polynomial:
④Graph convolution operator:
where is scaled Laplacian,
is the largest element among
. They defined
⑤The output of the cognition-inspired functional graph branch:
(3)Data-Driven Graph Branch
①Loss: they combined cross entropy () and backpropagation (BP) algorithm:
where denotes ground truth and
is predicted label,
denotes model parameters and
is hyper parameter
②Updating adjacency matrix by:
③Graph convolution operator:
(4)Fused Common Graph Branch
①2 spectral graph filter:
②Loss for each branch:
where and
are normalized embedding matrix,
(5)Attention Mechanism
①Applying attention on 3 spectral graph pattern:
where denotes attention values
②Attention function:
where 3 branches share the same weight matrix
③Attention value for on node
:
similar to other 2
④Final combined embedding:
(6)Emotion Decoding Procedure
①Reducing the graph feature distribution difference between the source domain (training set) and the target domain (testing set) by graph domain adversarial:
where is a two layer fully connected neural network. 0 is source label and 1 denotes target domain
②Optimal domain classifier:
③Total loss by adding gradient reversal layer (GRL) and
:
where is conformance constraint parameter
2.5. Experiments and Results
①Datasets: SEED, SEED IV
②EEG electrodes: 64 channels
③Bandpass filter: delta 1–4 Hz, theta 4–8 Hz, alpha 8–14 Hz, beta 14–30 Hz, and gamma 30–48 Hz
④Layer of graph conv: 2
⑤Dropout rate: 0.5
⑥Optimizer: Adam with 0.005 learning rate in subject-dependent experiments and 0.008 in subject-independent experiments
⑦Max epoch: 400
⑧Batch size: 64
⑨L2 regularization is in [1e-3, 3e-2]
2.5.1. Subject-Dependent Experiments
①Data split: first 9 trials of EEG signals for training and remaining 6 for testing
②Performance on 5 bands on SEED:
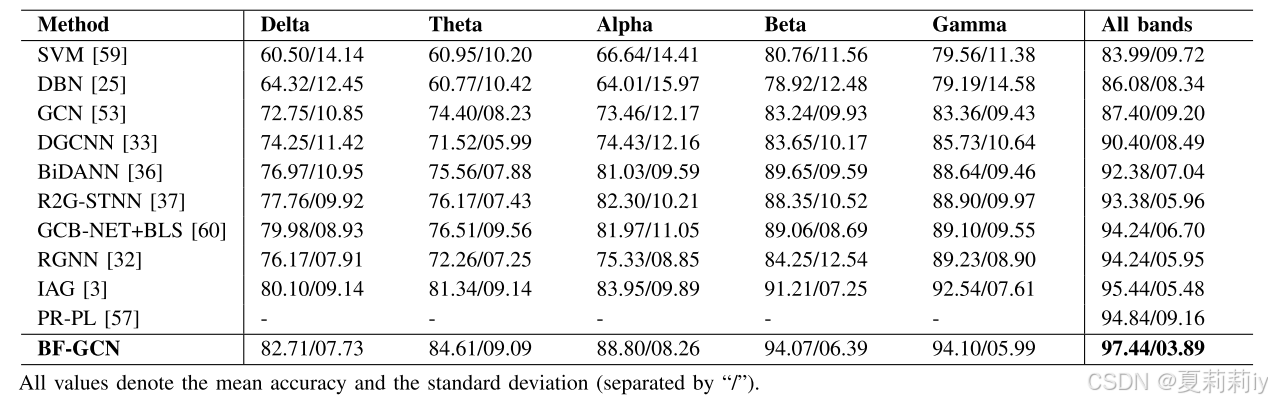
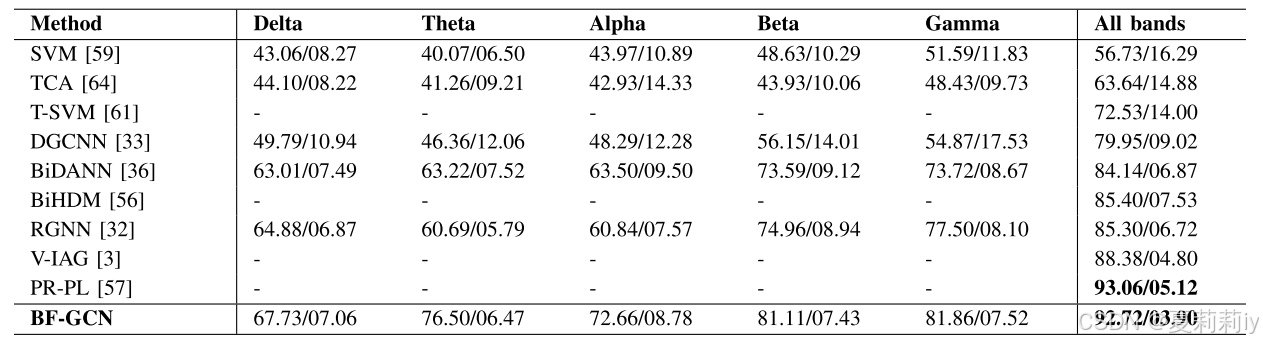
③4 categories classification on SEED IV:
2.5.2. Subject-Independent Experiments
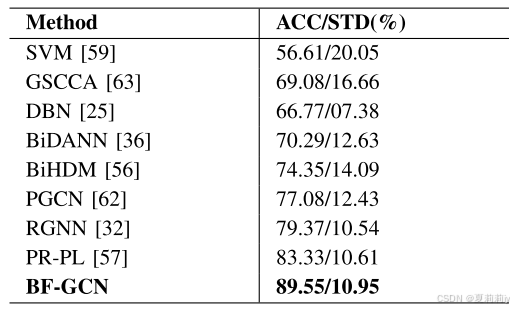
①They applied leaveone-subject-out cross-validation (LOSOCV) of 15 subjects on subject-independent experiments, on SEED:
and on SEED IV:
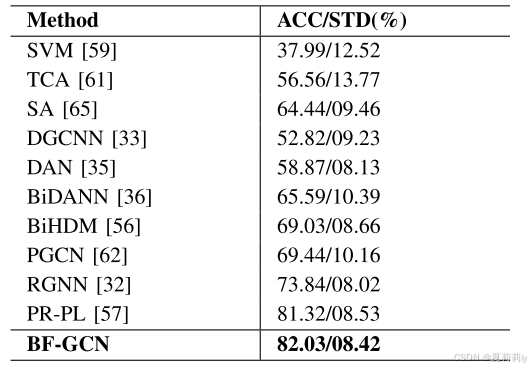
2.5.3. Confusion Matrix on Two Datasets
①Confusion matrices on SEED:
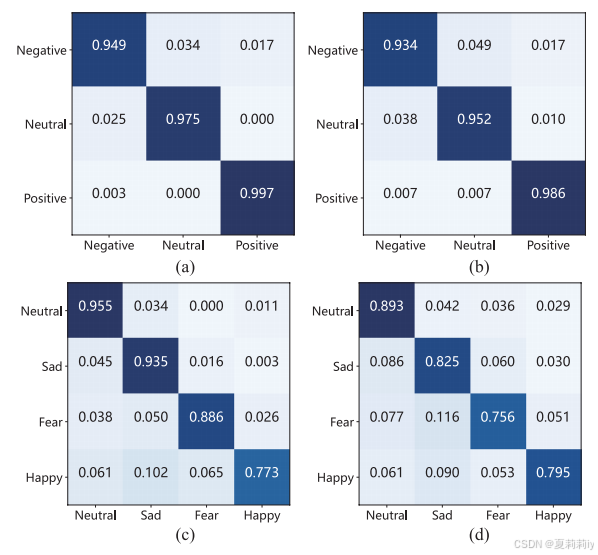
2.6. Analysis and Discussion
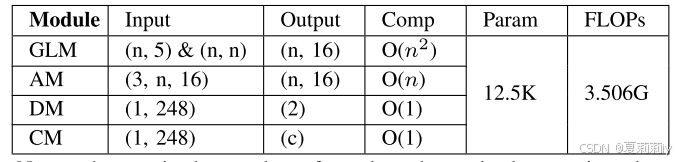
2.6.1. Computational Efficiency Analysis
①Parameters calculated by Torch-OpCounter (THOP) toolbox
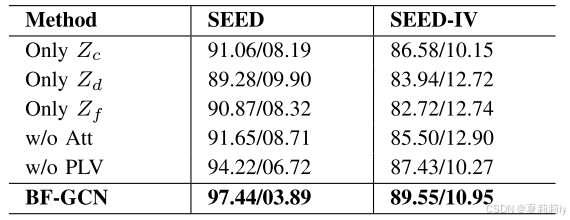
2.6.2. Ablation Study
①Feature and module ablation:
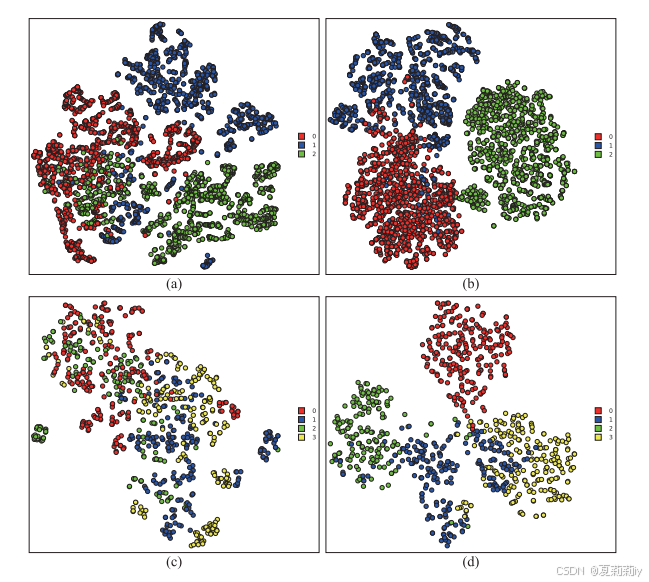
2.6.3. Visualization Analysis
①t-SNE visualization on SEED (the first row) and SEED IV (the second row):
2.6.4. Cognitive Graph Pattern Analysis
①Brain activation mapping:
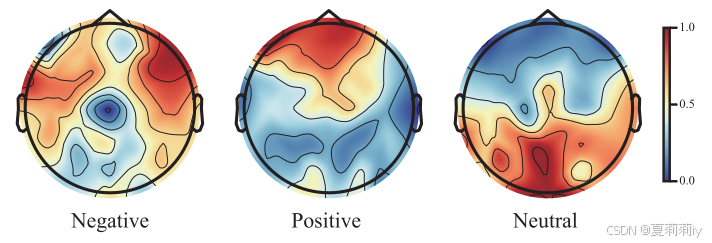
2.7. Conclusion
~
3. 知识补充
3.1. Phase Locking Value
(1)参考学习:PLV(Phase Locking Value,相位锁定值)的原理和计算-CSDN博客
3.2. logarithm energy spectrum
EEG(脑电图)的 对数能量谱(Logarithm Energy Spectrum) 是一种将 EEG 信号的频域能量分布进行对数变换后的表示方式,主要用于分析信号在不同频率上的能量强度,同时压缩动态范围以增强特征的可解释性
4. Reference
@article{li2024efficient,
title={An Efficient Graph Learning System for Emotion Recognition Inspired by the Cognitive Prior Graph of EEG Brain Network},
author={Li, Cunbo and Tang, Tian and Pan, Yue and Yang, Lei and Zhang, Shuhan and Chen, Zhaojin and Li, Peiyang and Gao, Dongrui and Chen, Huafu and Li, Fali and others},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2024},
publisher={IEEE}
}

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)