node.js基于人工智能科研平台的电影推荐系统前程序+论文 可用于毕业设计
本选题将以人工智能科研平台为基础,结合深度学习、自然语言处理等技术,重点研究如何构建一个基于多模态数据的电影推荐系统,旨在解决传统推荐系统中存在的数据稀疏性、冷启动问题以及推荐结果单一化等问题,为用户提供更加精准和个性化的推荐服务。此外,现有的电影推荐系统在面对用户行为数据的动态变化时,往往表现出一定的滞后性和适应性不足的问题。[8] 罗斌,温丰蔚,曾晓钰,张亮,韦通明. 基于 Vue.js 的培
本系统(程序+源码+数据库+调试部署+开发环境)带文档lw万字以上,文末可获取源码
系统程序文件列表
开题报告内容
选题背景
随着互联网技术的快速发展和数字娱乐的普及,电影作为一种重要的文化娱乐形式,受到了越来越多人的喜爱。然而,在海量的电影资源中,用户如何快速找到自己喜欢的电影成为一个亟待解决的问题。传统的电影推荐系统主要依赖于协同过滤算法(Collaborative Filtering),但这类算法存在数据稀疏性、冷启动问题以及推荐结果单一化等问题,难以满足用户的个性化需求。
近年来,人工智能技术的快速发展为推荐系统带来了新的机遇。深度学习、自然语言处理(NLP)、计算机视觉等技术的结合,使得推荐系统能够更精准地捕捉用户的兴趣偏好,并提供多样化的推荐结果。特别是在电影推荐领域,基于深度学习的推荐算法(如神经网络协同过滤、深度矩阵分解等)逐渐成为研究热点。然而,目前的研究大多集中在单一算法的优化上,缺乏对整体推荐系统的系统性设计和多模态数据的融合应用。
此外,现有的电影推荐系统在面对用户行为数据的动态变化时,往往表现出一定的滞后性和适应性不足的问题。如何利用人工智能技术构建一个高效、灵活且个性化的电影推荐系统,仍然是一个具有挑战性的课题。
本选题将以人工智能科研平台为基础,结合深度学习、自然语言处理等技术,重点研究如何构建一个基于多模态数据的电影推荐系统,旨在解决传统推荐系统中存在的数据稀疏性、冷启动问题以及推荐结果单一化等问题,为用户提供更加精准和个性化的推荐服务。
研究意义
本选题针对电影推荐系统中存在的数据稀疏性、冷启动问题以及推荐结果单一化等问题的研究具有重要的理论意义和现实意义。
理论意义
- 丰富推荐系统理论:通过对基于人工智能的电影推荐系统的深入研究,可以进一步完善推荐系统的理论框架,尤其是在多模态数据融合、深度学习算法优化等方面提供新的理论支持。
- 推动人工智能技术发展:本研究将结合深度学习、自然语言处理等技术,探索其在推荐系统中的应用潜力,为人工智能技术在娱乐领域的应用提供新的思路。
现实意义
- 提升用户体验:通过构建一个高效、精准的电影推荐系统,能够显著提升用户的观影体验,帮助用户快速发现感兴趣的内容。
- 促进电影产业发展:精准的推荐系统可以帮助电影制片方和发行方更好地了解市场需求,优化内容生产和推广策略。
- 推动行业智能化升级:本研究将为娱乐行业的智能化升级提供技术支持,助力企业实现数字化转型。
研究方法
本研究将采用以下几种研究方法:
-
文献分析法
通过查阅国内外关于推荐系统、深度学习、自然语言处理等相关领域的文献资料,梳理现有研究成果和技术瓶颈,为本研究提供理论支持。 -
对比分析法
对比分析传统推荐算法(如协同过滤)与基于深度学习的推荐算法在性能上的差异,探讨深度学习在推荐系统中的优势和适用场景。 -
实验研究法
构建基于人工智能的电影推荐系统原型,并通过实验验证不同算法在推荐效果上的表现。实验将从准确率、召回率、覆盖率等多个维度进行评估。 -
数据驱动方法
利用公开的电影数据集(如MovieLens、IMDb等)进行训练和测试,结合用户行为数据和电影元数据(如剧情、演员、导演等),构建多模态数据融合的推荐模型。
研究方案
可能遇到的困难
-
数据获取与处理
电影推荐系统需要大量的用户行为数据和电影元数据支持,但在实际操作中可能存在数据获取困难或数据质量不高的问题。 -
算法复杂度高
基于深度学习的推荐算法通常具有较高的计算复杂度,可能导致训练时间和资源消耗过大。 -
用户反馈不足
在实验阶段,由于用户数量有限,可能无法获得足够的反馈数据来验证推荐系统的性能。
解决初步设想
-
数据获取与处理
通过公开数据集(如MovieLens)获取基础数据,并结合爬虫技术补充缺失的数据。同时,对数据进行清洗和预处理,确保数据质量。 -
算法复杂度高
采用分布式计算框架(如Spark)优化算法训练过程,并尝试引入轻量化模型(如神经网络剪枝技术)降低计算复杂度。 -
用户反馈不足
在实验阶段,通过A/B测试收集用户反馈数据,并结合模拟用户行为生成虚拟数据进行补充。
研究内容
本研究将围绕以下核心内容展开:
-
电影信息管理模块
包括电影元数据的采集、存储和管理,支持对电影的基本信息(如标题、类型、演员、导演等)进行分类和检索。 -
用户画像构建模块
通过分析用户的观影历史、评分记录和偏好设置,构建用户的兴趣画像,并动态更新用户的偏好信息。 -
推荐算法设计模块
结合深度学习技术(如神经网络协同过滤、深度矩阵分解等),设计高效的推荐算法,并探索多模态数据(如文本、图像、视频)的融合方法。 -
推荐效果评价模块
构建一套全面的评价指标体系(如准确率、召回率、覆盖率等),对推荐算法的性能进行评估和优化。 -
系统实现与测试模块
基于人工智能科研平台,实现电影推荐系统的原型,并通过实验验证系统的性能和稳定性。
拟解决的主要问题
- 如何利用深度学习技术提高电影推荐系统的推荐精度?
- 如何解决传统推荐系统中存在的数据稀疏性和冷启动问题?
- 如何实现多模态数据的融合,提升推荐结果的多样性?
预期成果
- 构建一个基于人工智能的电影推荐系统原型。
- 提出一种高效的多模态数据融合推荐算法。
- 发表相关学术论文1-2篇。
- 提交完整的毕业设计报告和演示视频。
进度安排:
|
完成日期 |
阶段性工作内容 |
|
2023.11.06 - 2023.11.19 |
设计前准备:检索收集相关资料,进行系统需求分析,明确研究方法和设计思路,完成开题报告。 |
|
2023.11.20 - 2023.12.03 |
学习系统的基本知识。收集数据。 |
|
2024.03.11 - 2024.04.14 |
系统整体设计,确定设计方案。完成界面设计和数据库设计,进行几大模块的设计实现。完成外文翻译。完成中期答辩。 |
|
2024.04.15 - 2024.05.05 |
完成基础设置、进行论文的撰写工作。 |
|
2024.05.06 - 2024.05.26 |
完善系统,完成设计的所有功能。进行系统测试及优化。完成论文的撰写,撰写用户手册等其他文档。 |
|
2024.05.27 - 2024.06.14 |
修改论文。准备幻灯片,准备并进行毕业答辩。整理材料,装订论文。 |
参考文献:
[1] 张贵强, 王美玲. 基于NodeJS的企业网站的设计与实现[J]. 信息技术与信息化, 2019, (12): 58-60.
[2] 胡扬帆. 使用Node.js技术,建设灵活高效的企业级Web系统[J]. 中国传媒科技, 2018, (04): 15-18.
[3] 伍万鹏. Node.JS平台下Web前端架构的研究[J]. 信息通信, 2016, (02): 103-104.
[4] 徐浪. 基于 Node.js 的 Web 应用框架研究与实现[D]. 安徽工业大学,2019.
[5] 黄扬子. 基于 NodeJS 平台搭建 REST 风格 Web 服务[J]. 无线互联科技,2015(16): 57-59.
[6] 兰天, 张荣庆, 梁乾. Excel协同汇总的Nodejs算法解决方案[J]. 数码世界, 2020, (02): 39.
[7] 张钊源,刘晓瑜,鞠玉霞. Node.js 后端技术初探[J]. 中小企业管理与科技(上旬刊),2020, (08): 193-194.
[8] 罗斌,温丰蔚,曾晓钰,张亮,韦通明. 基于 Vue.js 的培训可视化系统开发与设计[J]. 现代工业经济和信息化,2021, 11(12): 54-56.
[9] 赵学作,赵少农. Node.js 的安装与调试[J]. 网络安全和信息化,2019, (03): 87-88.
[10] 刘灿. 基于Bigpipe与Node.js的Web框架的设计与实现[D]. 北京邮电大学, 2018.
[11] 张钊源, 刘晓瑜, 鞠玉霞. Node.js后端技术初探[J]. 中小企业管理与科技(上旬刊), 2020, (08): 193-194.
[12] 黄可. 基于 Vue 的信息融合界面开发方案的设计与实现[J]. 信息技术与标准化,2022(03): 79-82.
[13] 赵陶钰. 基于 HTML5+Node.js 同步绘图板的设计与实现[J]. 邢台职业技术学院学报,2021, 38 (01): 92-95.
[14] 朱晓阳, 刘苑如, 范仲言. 基于Node.js的学习平台后端系统设计与实现[J]. 电脑知识与技术, 2019, 15 (13): 116-118.
[15] 方生. 基于 Vue.js 前端框架技术的研究[J]. 电脑知识与技术,2021,17(19): 59-60.
以上是开题是根据本选题撰写,是项目程序开发之前开题报告内容,后期程序可能存在大改动。最终成品以下面运行环境+技术+界面为准,可以酌情参考使用开题的内容。要本源码参考请在文末进行获取!!
系统环境搭建步骤:
1.访问Node.js官网下载并安装适用于Windows的Node.js版本,确保安装过程中包含NPM。安装完成后,通过命令提示符验证Node.js和NPM的安装情况。
2.搭建Vue.js前端开发环境,使用npm或Vue CLI安装Vue.js,并创建Vue项目进行前端开发与本地测试。接着,从MySQL官网下载并安装MySQL Server,设置root用户密码,并可选安装Navicat作为数据库管理工具。
3.配置Navicat连接到本地MySQL数据库。
4.开发Node.js后端,创建项目并安装如Express等所需的npm包,编写后端代码,前端利用Vue.js等前端技术栈实现用户界面和用户交互逻辑;同时,后端使用Node.js等技术实现业务逻辑、数据处理以及与前端的数据交互。并实现与MySQL数据库的连接。
技术栈:
前端:Vue.js、npm、Vue CLI
后端:Node.js、NPM、Express、MySQL
开发工具:Vscode、mysql5.7、Navicat 11
毕设程序界面:

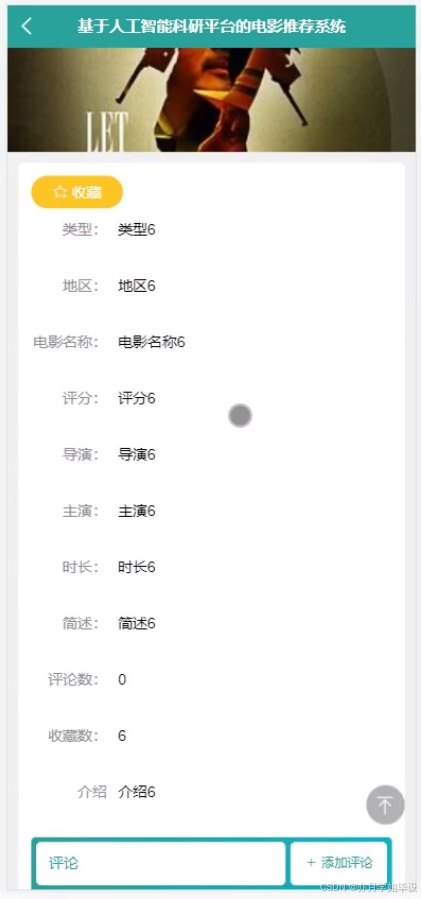
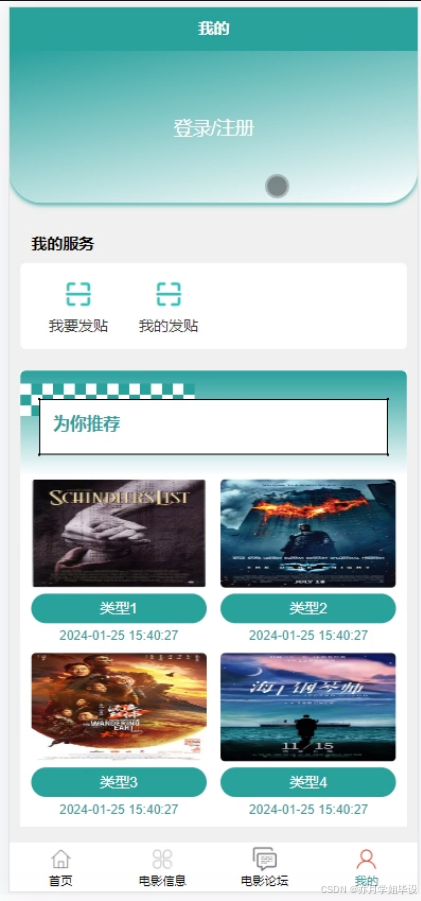
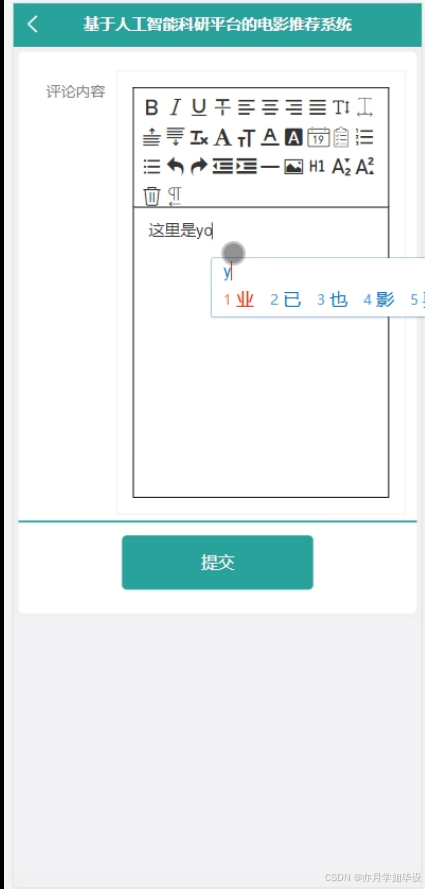
源码、数据库获取↓↓↓↓

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)