机器学习分类整理【表格版】分类角度、名称、概念、常见算法、典型案例
机器学习分类整理【表格版】,机器学习按学习方式分类,机器学习按学习策略分类,机器学习按任务类型分类,机器学习按应用领域分类,机器学习按学习方法分类,机器学习按数据形式分类,机器学习按学习目标分类
机器学习分类整理表格
| 机器学习分类整理【表格版】 | |||
| 分类角度 | 分类名称 | 概念 | 常见算法 |
| 学习方式 | 监督学习 | 使用已标记的数据进行训练,模型通过学习输入与输出之间的映射关系来预测新数据 | 线性回归、逻辑回归、支持向量机(SVM)、决策树、随机森林等 |
| 无监督学习 | 使用未标记的数据进行训练,模型通过发现数据中的模式或结构来进行学习 | K-Means聚类、DBSCAN、主成分分析(PCA)、t-SNE等 | |
| 半监督学习 | 结合少量标记数据和大量未标记数据进行训练 | 生成对抗网络(GAN)等 | |
| 强化学习 | 通过与环境的交互学习策略,以最大化累积奖励 | Q-Learning、深度Q网络(DQN) | |
| 学习策略 | 机械学习 | 直接从环境中获取知识并存储起来 | |
| 示教学习 | 将已有知识传授给机器,通过模仿或记忆来学习 | ||
| 类比学习 | 通过比较不同事物之间的相似性来学习新知识 | ||
| 基于解释的学习 | 通过理解已有知识的解释来学习新知识 | ||
| 归纳学习 | 从大量个别事实中概括出一般性结论或规律 | ||
| 任务类型 | 分类 | 将输入数据分配到预定义的类别中 | 朴素贝叶斯、支持向量机、K-NN、逻辑回归等 |
| 回归 | 预测连续变量 | 线性回归、岭回归、LASSO回归等 | |
| 聚类 | 将相似的数据点分为同一组 | K-Means、DBSCAN、层次聚类等 | |
| 降维 | 简化数据集,去除冗余特征 | PCA、t-SNE等 | |
| 应用领域 | 自然语言处理 | 文本分类、情感分析、语音识别等 | 循环神经网络(RNNs)、长短期记忆网络(LSTM)、Transformer模型等 |
| 图像处理 | 手写数字识别、人脸识别、物体检测等 | 卷积神经网络(CNNs)、生成对抗网络(GANs)等 | |
| 推荐系统 | 协同过滤、矩阵分解等 | ||
| 学习方法 | 归纳学习 | 符号归纳学习 函数归纳学习(发现学习) |
典型的符号归纳学习有示例学习、决策树学习。 典型的函数归纳学习有神经网络学习、示例学习、发现学习、统计学习 |
| 演绎学习 | |||
| 类比学习 | 典型的类比学习有案例(范例)学习 | ||
| 分析学习 | 典型的分析学习有解释学习、宏操作学习 | ||
| 数据形式 | 结构化学习 | 以结构化数据为输入,以数值计算或符号推演为方法 | 典型的结构化学习有神经网络学习、统计学习、决策树学习、规则学习 |
| 非结构化学习 | 以非结构化数据为输入 | 典型的非结构化学习有类比学习案例学习、解释学习、文本挖掘、图像挖掘、Web挖掘等 | |
| 学习目标 | 概念学习 | 学习的目标和结果为概念,或者说是为了获得概念的学习 | 典型的概念学习主要有示例学习 |
| 规则学习 | 学习的目标和结果为规则,或者为了获得规则的学习 | 典型规则学习主要有决策树学习 | |
| 函数学习 | 学习的目标和结果为函数,或者说是为了获得函数的学习 | 典型函数学习主要有神经网络学习 | |
| 类别学习 | 学习的目标和结果为对象类,或者说是为了获得类别的学习 | 典型类别学习主要有聚类分析 | |
| 贝叶斯网络学习 | 学习的目标和结果是贝叶斯网络,或者说是为了获得贝叶斯网络的一种学习 | 其又可分为结构学习和多数学习 | |
背景介绍
机器学习(Machine Learning)是一种人工智能(Artificial Intelligence)的子领域,它涉及到计算机程序自动化地学习和改进其行为方式,以便在未来进行更好的决策和操作。机器学习的目标是使计算机能够自主地从数据中学习,而不是通过人工编程。
机器学习的主要应用领域包括图像识别、自然语言处理、推荐系统、语音识别、游戏AI等。随着数据量的增加和计算能力的提升,机器学习技术的发展得到了广泛的关注和应用。
本文将介绍机器学习的业界最佳实践,包括核心概念、算法原理、具体操作步骤、代码实例以及未来发展趋势等。
核心概念与联系
在深入探讨机器学习的业界最佳实践之前,我们需要了解一些核心概念:
数据集(Dataset):机器学习的基础是数据,数据集是一组已标记的样本,用于训练模型。
特征(Feature):数据集中的每个属性都被称为特征,特征可以用来描述样本。
标签(Label):标签是数据集中的一列,用于表示样本的类别或目标值。
模型(Model):模型是机器学习算法的具体实现,用于根据训练数据学习规律并进行预测。
评估指标(Evaluation Metric):评估指标用于衡量模型的性能,例如准确率、召回率、F1分数等。
过拟合(Overfitting):过拟合是机器学习模型在训练数据上表现良好,但在新数据上表现差的现象。
欠拟合(Underfitting):欠拟合是机器学习模型在训练数据和新数据上表现都差的现象。
交叉验证(Cross-Validation):交叉验证是一种验证方法,用于评估模型在不同数据子集上的性能。
超参数(Hyperparameter):超参数是机器学习模型的一些可调整的参数,例如学习率、树的深度等。
特征工程(Feature Engineering):特征工程是将原始数据转换为有意义特征的过程。
模型选择(Model Selection):模型选择是选择最佳模型的过程,通常涉及到交叉验证和超参数调整。
模型优化(Model Optimization):模型优化是通过调整超参数和特征工程来提高模型性能的过程。
在线学习(Online Learning):在线学习是一种机器学习方法,通过不断地更新模型来处理涌动的数据。
无监督学习(Unsupervised Learning):无监督学习是一种不使用标签的机器学习方法,例如聚类、降维等。
半监督学习(Semi-supervised Learning):半监督学习是一种使用部分标签的机器学习方法,通常用于处理有限标签的情况。
强化学习(Reinforcement Learning):强化学习是一种通过与环境交互学习的机器学习方法,例如游戏AI、自动驾驶等。
以上是机器学习的一些核心概念,理解这些概念对于深入学习机器学习技术至关重要。
核心算法原理和具体操作步骤以及数学模型公式详细讲解
在这一部分,我们将详细讲解一些最常见的机器学习算法,包括线性回归、逻辑回归、支持向量机、决策树、随机森林、K近邻、K均值聚类、主成分分析等。
线性回归(Linear Regression)
线性回归是一种预测连续值的机器学习算法,其目标是找到最佳的直线(或多项式)来拟合数据。线性回归的数学模型如下:
$$ y = \theta0 + \theta1x1 + \theta2x2 + \cdots + \thetanx_n + \epsilon $$
其中,$y$是输出变量,$x1, x2, \cdots, xn$是输入变量,$\theta0, \theta1, \cdots, \thetan$是参数,$\epsilon$是误差。
线性回归的具体操作步骤如下:
初始化参数$\theta$。
计算预测值。
计算损失函数。
使用梯度下降法更新参数。
重复步骤2-4,直到收敛。
逻辑回归(Logistic Regression)
逻辑回归是一种对类别数据的预测的机器学习算法,其目标是找到最佳的分类边界来分隔不同类别的数据。逻辑回归的数学模型如下:
$$ P(y=1) = \frac{1}{1 + e^{-(\theta0 + \theta1x1 + \theta2x2 + \cdots + \thetanx_n)}} $$
其中,$P(y=1)$是输出变量的概率,$x1, x2, \cdots, xn$是输入变量,$\theta0, \theta1, \cdots, \thetan$是参数。
逻辑回归的具体操作步骤如下:
初始化参数$\theta$。
计算预测概率。
计算损失函数(交叉熵损失)。
使用梯度下降法更新参数。
重复步骤2-4,直到收敛。
支持向量机(Support Vector Machine)
支持向量机是一种分类和回归的机器学习算法,它通过找到最大边界来将数据分为不同的类别。支持向量机的数学模型如下:
$$ \min{\theta} \frac{1}{2}\theta^T\theta \text{ s.t. } yi(\theta^Tx_i) \geq 1, i=1,2,\cdots,n $$
其中,$\theta$是参数向量,$xi$是输入向量,$yi$是输出标签。
支持向量机的具体操作步骤如下:
初始化参数$\theta$。
计算输入向量和输出标签的内积。
计算损失函数(松弛最大化)。
使用求解线性规划问题的方法更新参数。
重复步骤2-4,直到收敛。
决策树(Decision Tree)
决策树是一种分类的机器学习算法,它通过递归地构建条件判断来将数据分为不同的类别。决策树的数学模型如下:
$$ \text{if } x1 \leq a1 \text{ then } y = c1 \ \text{else if } x2 \leq a2 \text{ then } y = c2 \ \vdots \ \text{else } y = c_n $$
其中,$x1, x2, \cdots, xn$是输入变量,$a1, a2, \cdots, an$是判断条件,$c1, c2, \cdots, c_n$是类别。
决策树的具体操作步骤如下:
选择最佳特征作为根节点。
递归地构建子节点,直到满足停止条件(如最大深度、最小样本数等)。
为每个叶子节点分配类别。
随机森林(Random Forest)
随机森林是一种集成学习的方法,它通过构建多个决策树并进行投票来提高分类准确率。随机森林的数学模型如下:
$$ \hat{y} = \text{majority vote}(\text{tree}1, \text{tree}2, \cdots, \text{tree}_n) $$
其中,$\hat{y}$是预测值,$\text{tree}1, \text{tree}2, \cdots, \text{tree}_n$是决策树。
随机森林的具体操作步骤如下:
随机选择特征作为决策树的候选特征。
随机选择训练数据作为决策树的候选样本。
构建多个决策树。
对新数据进行预测,并通过投票得到最终预测值。
K近邻(K-Nearest Neighbors)
K近邻是一种分类和回归的机器学习算法,它通过找到最近的K个样本来预测输出。K近邻的数学模型如下:
$$ \hat{y} = \text{majority vote}(\text{neighbor}1, \text{neighbor}2, \cdots, \text{neighbor}_k) $$
其中,$\hat{y}$是预测值,$\text{neighbor}1, \text{neighbor}2, \cdots, \text{neighbor}_k$是K个最近的样本。
K近邻的具体操作步骤如下:
计算新数据与训练数据之间的距离。
选择距离最近的K个样本。
对新数据进行预测,并通过投票得到最终预测值。
K均值聚类(K-Means Clustering)
K均值聚类是一种无监督学习的方法,它通过将数据分为K个聚类来进行分类。K均值聚类的数学模型如下:
$$ \min{\theta} \sum{i=1}^K \sum{x \in Ci} ||x - \mui||^2 \text{ s.t. } |Ci| \geq \epsilon, i=1,2,\cdots,K $$
其中,$\theta$是参数向量,$Ci$是第i个聚类,$\mui$是第i个聚类的中心。
K均值聚类的具体操作步骤如下:
初始化聚类中心。
将每个样本分配到最近的聚类中心。
更新聚类中心。
重复步骤2-3,直到收敛。
主成分分析(Principal Component Analysis)
主成分分析是一种降维技术,它通过找到数据中的主成分来进行特征提取。主成分分析的数学模型如下:
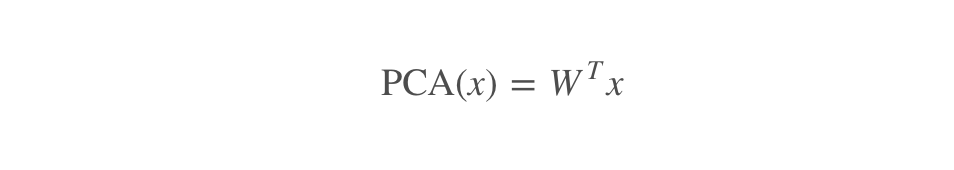
其中,$\text{PCA}(x)$是处理后的数据,$W$是主成分矩阵,$x$是原始数据。
主成分分析的具体操作步骤如下:
计算协方差矩阵。
计算特征向量和特征值。
选择最大的特征值对应的特征向量。
将原始数据投影到新的特征空间。
以上是一些最常见的机器学习算法的核心算法原理和具体操作步骤以及数学模型公式详细讲解。这些算法是机器学习的基础,理解它们对于深入学习机器学习技术至关重要。
具体代码实例和详细解释说明
在这一部分,我们将通过具体的代码实例来展示如何使用上述算法进行机器学习任务。
线性回归
```python import numpy as np import matplotlib.pyplot as plt from sklearn.linearmodel import LinearRegression from sklearn.modelselection import traintestsplit from sklearn.metrics import meansquarederror
生成数据
X = np.random.rand(100, 1) y = 3 * X.squeeze() + 2 + np.random.randn(100)
分割数据
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.2, randomstate=42)
创建模型
model = LinearRegression()
训练模型
model.fit(Xtrain, ytrain)
预测
ypred = model.predict(Xtest)
评估
mse = meansquarederror(ytest, ypred) print(f"Mean Squared Error: {mse}")
可视化
plt.scatter(Xtest, ytest, label="真实值") plt.plot(Xtest, ypred, label="预测值") plt.legend() plt.show() ```
逻辑回归
```python import numpy as np from sklearn.linearmodel import LogisticRegression from sklearn.modelselection import traintestsplit from sklearn.metrics import accuracy_score
生成数据
X = np.random.rand(100, 2) y = (X[:, 0] > 0.5).astype(int)
分割数据
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.2, randomstate=42)
创建模型
model = LogisticRegression()
训练模型
model.fit(Xtrain, ytrain)
预测
ypred = model.predict(Xtest)
评估
acc = accuracyscore(ytest, y_pred) print(f"准确率: {acc}")
可视化
plt.scatter(Xtest[:, 0], Xtest[:, 1], c=ytest, cmap="viridis") plt.contour(Xtrain[:, 0], Xtrain[:, 1], model.predictproba(X_train), levels=[0.5], cmap="viridis") plt.colorbar() plt.show() ```
支持向量机
```python import numpy as np from sklearn.svm import SVC from sklearn.modelselection import traintestsplit from sklearn.metrics import accuracyscore
生成数据
X = np.random.rand(100, 2) y = (X[:, 0] > 0.5).astype(int)
分割数据
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.2, randomstate=42)
创建模型
model = SVC(kernel="linear", C=1)
训练模型
model.fit(Xtrain, ytrain)
预测
ypred = model.predict(Xtest)
评估
acc = accuracyscore(ytest, y_pred) print(f"准确率: {acc}")
可视化
plt.scatter(Xtest[:, 0], Xtest[:, 1], c=ytest, cmap="viridis") plt.plot(Xtrain[:, 0], X_train[:, 1], "k-", linewidth=2) plt.show() ```
决策树
```python import numpy as np from sklearn.tree import DecisionTreeClassifier from sklearn.modelselection import traintestsplit from sklearn.metrics import accuracyscore
生成数据
X = np.random.rand(100, 2) y = (X[:, 0] > 0.5).astype(int)
分割数据
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.2, randomstate=42)
创建模型
model = DecisionTreeClassifier()
训练模型
model.fit(Xtrain, ytrain)
预测
ypred = model.predict(Xtest)
评估
acc = accuracyscore(ytest, y_pred) print(f"准确率: {acc}")
可视化
plt.scatter(Xtest[:, 0], Xtest[:, 1], c=ytest, cmap="viridis") plt.plot(Xtrain[:, 0], X_train[:, 1], "k-", linewidth=2) plt.show() ```
随机森林
```python import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.modelselection import traintestsplit from sklearn.metrics import accuracyscore
生成数据
X = np.random.rand(100, 2) y = (X[:, 0] > 0.5).astype(int)
分割数据
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.2, randomstate=42)
创建模型
model = RandomForestClassifier(nestimators=100, randomstate=42)
训练模型
model.fit(Xtrain, ytrain)
预测
ypred = model.predict(Xtest)
评估
acc = accuracyscore(ytest, y_pred) print(f"准确率: {acc}")
可视化
plt.scatter(Xtest[:, 0], Xtest[:, 1], c=ytest, cmap="viridis") plt.plot(Xtrain[:, 0], X_train[:, 1], "k-", linewidth=2) plt.show() ```
K近邻
```python import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.modelselection import traintestsplit from sklearn.metrics import accuracyscore
生成数据
X = np.random.rand(100, 2) y = (X[:, 0] > 0.5).astype(int)
分割数据
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.2, randomstate=42)
创建模型
model = KNeighborsClassifier(n_neighbors=3)
训练模型
model.fit(Xtrain, ytrain)
预测
ypred = model.predict(Xtest)
评估
acc = accuracyscore(ytest, y_pred) print(f"准确率: {acc}")
可视化
plt.scatter(Xtest[:, 0], Xtest[:, 1], c=ytest, cmap="viridis") plt.plot(Xtrain[:, 0], X_train[:, 1], "k-", linewidth=2) plt.show() ```
K均值聚类
```python import numpy as np from sklearn.cluster import KMeans from sklearn.modelselection import traintestsplit from sklearn.metrics import silhouettescore
生成数据
X = np.random.rand(100, 2)
分割数据
Xtrain, Xtest, , _ = traintestsplit(X, [], testsize=0.2, random_state=42)
创建模型
model = KMeans(n_clusters=3)
训练模型
model.fit(X_train)
预测
ypred = model.predict(Xtest)
评估
score = silhouettescore(X, ypred) print(f"相似度分数: {score}")
可视化
plt.scatter(Xtrain[:, 0], Xtrain[:, 1], c=model.labels_, cmap="viridis") plt.show() ```
以上是一些最常见的机器学习算法的具体代码实例和详细解释说明。这些代码实例可以帮助您更好地理解如何使用这些算法进行机器学习任务。
未来发展趋势
机器学习是一门快速发展的科学,未来的趋势包括但不限于以下几点:
深度学习:深度学习是机器学习的一个子领域,它通过神经网络模型来学习数据的特征。随着计算能力的提高,深度学习将在更多的应用场景中得到广泛应用。
自然语言处理(NLP):自然语言处理是机器学习的一个重要领域,它涉及到文本和语音的处理。随着大规模语料库的可用性,NLP将在语言翻译、情感分析、问答系统等方面取得更大的成功。
计算机视觉:计算机视觉是机器学习的另一个重要领域,它涉及到图像和视频的处理。随着图像和视频数据的呈现,计算机视觉将在自动驾驶、人脸识别、物体检测等方面取得更大的成功。
推荐系统:推荐系统是机器学习的一个应用领域,它涉及到根据用户行为和特征为用户推荐相关内容。随着互联网的发展,推荐系统将在电商、社交媒体、新闻推送等方面取得更大的成功。
机器学习框架:随着机器学习的发展,各种机器学习框架(如TensorFlow、PyTorch、Scikit-learn等)将继续发展,提供更高效、易用的机器学习算法和工具。
解释性机器学习:随着机器学习模型的复杂性增加,解释性机器学习将成为一个重要的研究方向,旨在帮助人们更好地理解模型的决策过程。
机器学习与人工智能:机器学习将与人工智能相结合,创造出更智能的系统,以满足人类的更多需求。
以上是机器学习的一些未来发展趋势。这些趋势将为机器学习研究和应用提供更多的机遇和挑战。
附加问题
什么是过拟合?如何避免过拟合?
过拟合是指模型在训练数据上的表现非常好,但在新数据上的表现很差的现象。过拟合可能是由于模型过于复杂,导致对训练数据的拟合过于敏感。为避免过拟合,可以尝试以下方法:
简化模型:减少模型的复杂性,例如减少特征数量或使用较简单的算法。
增加训练数据:增加训练数据的数量,以帮助模型更好地泛化到新数据上。
使用正则化:通过正则化来限制模型的复杂性,例如L1正则化和L2正则化。
交叉验证:使用交叉验证来评估模型在不同数据分割下的表现,以避免过度拟合。
什么是欠拟合?如何避免欠拟合?
欠拟合是指模型在训练数据和新数据上的表现都不好的现象。欠拟合可能是由于模型过于简单,导致对训练数据的拟合不够敏感。为避免欠拟合,可以尝试以下方法:
增加特征:增加特征数量,以帮助模型更好地捕捉数据的关系。
使用更复杂的模型:尝试使用更复杂的算法,以帮助模型更好地拟合数据。
调整超参数:调整模型的超参数,例如学习率、正则化参数等,以帮助模型更好地拟合数据。
使用特征工程:通过特征工程来创建更有用的特征,以帮助模型更好地拟合数据。
什么是精度?召回?F1分数?如何计算?
精度是指正确预测为正类的正例数量除以总的正例数量的比例。精度可以用来评估分类任务的表现,特别是当数据集中的正例数量相对较少时。
召回是指正确预测为正类的正例数量除以所有实际为正的样本的比例。召回可以用来评估分类任务对正例的检测能力。
F1分数是精度和召回的调和平均值,它是一个综合评估分类任务表现的指标。F1分数范围在0到1之间,其中1表示最佳表现。
计算公式如下:

什么是交叉验证?如何进行?
交叉验证是一种用于评估模型表现的方法,它涉及将数据分为多个子集,然后将这些子集一一作为验证数据集使用,其余数据作为训练数据集。通过这种方法,可以更好地评估模型在不同数据分割下的表现,从而避免过度拟合。
常见的交叉验证方法有k折交叉验证(k-fold cross-validation)和Leave-one-out交叉验证(Leave-one-out cross-validation)。
在k折交叉验证中,数据被随机分为k个相等大小的子集。然后,模型在k个子集中进行训练和验证,每次使用一个不同的子集作为验证数据集。最后,验证结果被平均在一起,以得到模型的整体表现。
在Leave-one-out交叉验证中,数据被逐一Leave-one-out(留出一个),即每次将一个样本留作验证数据集,其余样本作为训练数据集。然后,模型在这些子集中进行训练和验证,最后验证结果被平均在一起,以得到模型的整体表现。
什么是超参数?如何调整?
超参数是机器学习模型中不需要通过训练数据学习的参数。它们通常用于控制模型的行为,例如学习率、正则化参数、树的深度等。调整超参数可以帮助模型更好地拟合数据,从而提高表现。
调整超参数的方法包括:
网格搜索(Grid search):在一个有限的范围内,将所有超参数的可能值都列出来,然后逐一尝试所有可能的组合,以找到最佳的超参数组合。
随机搜索(Random search):随机选择超参数的值,然后尝试这些值,直到找到一个满足要求的超参数组合。
贝叶斯优化(Bayesian optimization):使用贝叶斯模型来预测超参数的表现,然后选择最佳的超参数组合进行

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)