Stable Diffusion教程|文生图基本参数深入浅出
Stable Diffusion是一款基于深度学习的文本生成图像模型,能够根据用户提供的文本描述创造出高质量、细节丰富的图像。本教程旨在帮助初学者深入理解并有效运用Stable Diffusion的基本参数,从而更好地控制生成图像的效果。我们将通过实例解析,让复杂参数变得通俗易懂,助力您开启精彩的文生图创作之旅。目录1 文生图工作流程2 基本参数详解3 实战演练**一、**文生图工作流程**输入提
前言
Stable Diffusion是一款基于深度学习的文本生成图像模型,能够根据用户提供的文本描述创造出高质量、细节丰富的图像。本教程旨在帮助初学者深入理解并有效运用Stable Diffusion的基本参数,从而更好地控制生成图像的效果。我们将通过实例解析,让复杂参数变得通俗易懂,助力您开启精彩的文生图创作之旅。
目录
1 文生图工作流程
2 基本参数详解
3 实战演练
**一、**文生图工作流程
**输入提示词:**您需要提供一段文字描述,明确表达想要生成图像的主题、风格、场景等要素。
**设置参数:**调整Stable Diffusion模型的各项参数,以控制生成图像的质量、风格、细节程度等。
**运行模型:**模型基于输入文本和设置的参数,进行迭代计算,生成对应图像。
**查看结果:**生成的图像将显示在指定位置,您可以根据需要进行保存或进一步编辑。
二、基本参数详解
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
采样迭代步数(Steps)
含义:模型生成图像时进行的迭代次数。步数越多,生成图像的细节越丰富,但也可能增加噪点。
用法:一般在18~30内,过低图像生成不完整无细节,过高轻微优化性价比不高。
采样方法(Sampler)
含义:指的是在模型生成图像的过程中,从模型所学习的概率分布中提取样本的具体算法。这些方法旨在将模型的内在概率知识转化为实际的图像输出,控制从初始噪声状态到最终清晰图像的转化过程。
用法:每次文生图,都需要选择一种采样方法
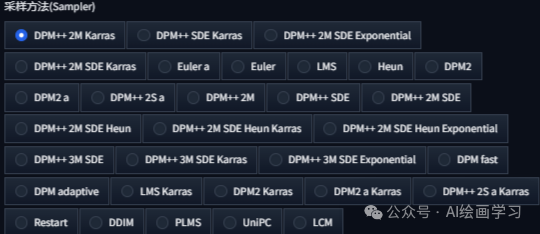
那么问题来了,30种采样方法,我们怎么选择?需要实验和总结。
实验:
可以用脚本“X/Y/Z plot”,在相同提示词“1girl”下,X轴为30种采样方法,每种都生成一张图,对比看看效果。
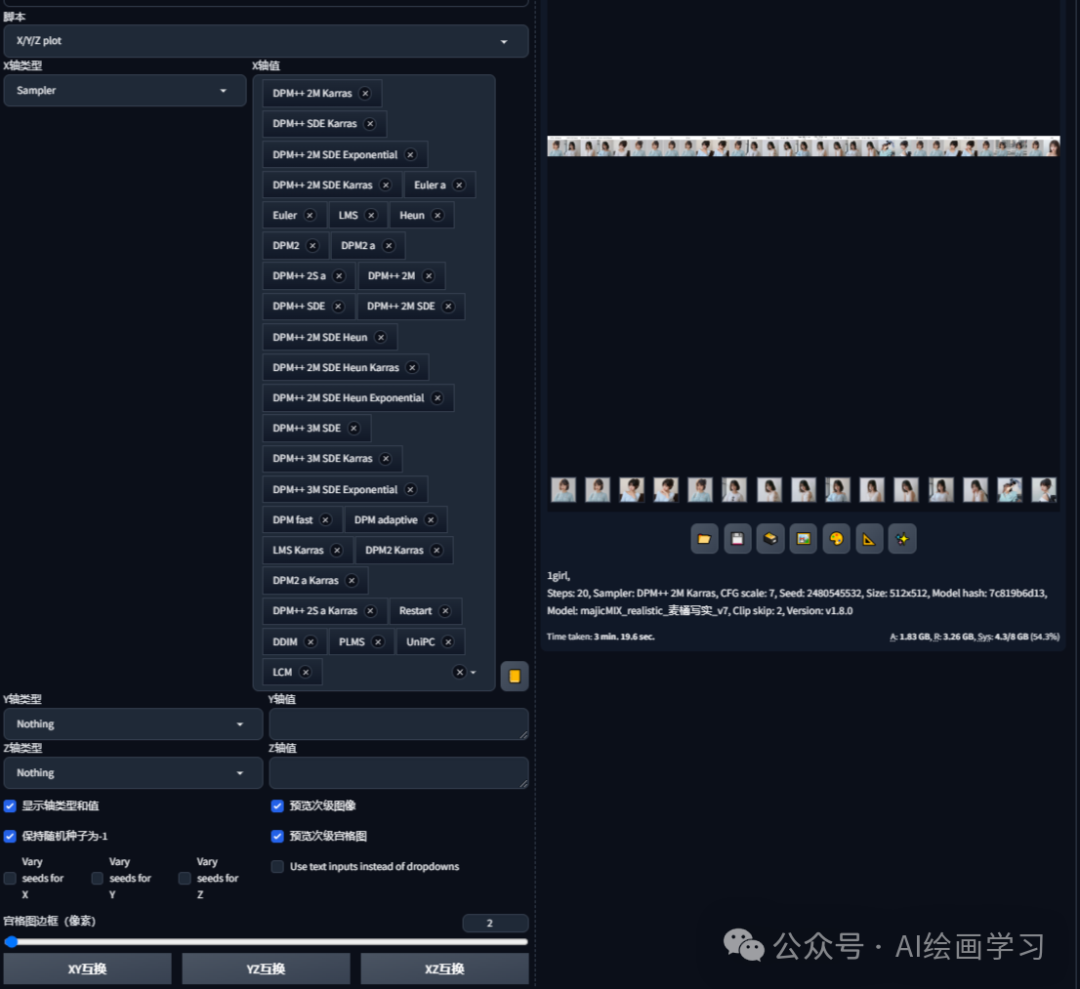

**速度快:**Euler系列、LMS系列、DPM++2M、DPM fast、DPM++2M Karras、DDIM系列。
**质量高:**Heum、PLMS、DPM++系列。
**tag利用率高:**DPM2系列、Euler系列。
**动画风:**LMS系列、UniPC。
**写实风:**DPM2系列、Euler系列、DPM++系列。
名词解释:
DPM-扩散概率模型;2M-表示200万步;Karras-是Karras等人提出的。
结论:
1、默认推荐使用DPM++2M Karras生成图片速度快、效果好。
**2、Eluer a采样生成速度最快,但人脸可能扭曲,适合生产icon图标\二次元\小图。
**
**3、DPM++2S a Karras 生成高质量图片,适合写实人物或复杂场景,同时设置setps越高效果越好。
**
4、DDIM效率更高,但二次元可能会变形。
但并不是绝对的,有的大模型和LORA作者,会特别推荐哪种采样方法,那最好照选哦!
宽度 高度

含义:设置生成图片的尺寸分辨率,单位是pix
用法:8G显存的显卡,一般用512*512,如果太大容易“爆显存”。(并非真的把显卡爆炸了 ,是指计算数据量超过显存容量,导致画面错误、帧数骤降、出现崩溃等异常)对于全身照,建议设置为512*768。(升级SDXL大模型,默认都是1024*1024的图)
,是指计算数据量超过显存容量,导致画面错误、帧数骤降、出现崩溃等异常)对于全身照,建议设置为512*768。(升级SDXL大模型,默认都是1024*1024的图)
那你肯定会问了,配置低又要高分辨率咋办?那就需要“高清修复”即可。
高清修复
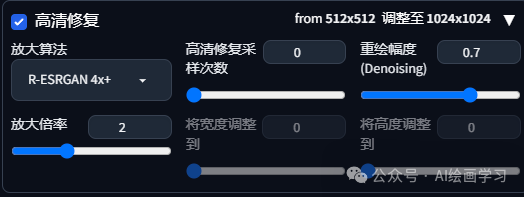
含义:采用某种放大算法,把低分辨率图片进行放大,通常为避免变形,都是等比例放大倍数,如:放大倍率2 就是 512*512放大1024*1024,比直接生成1024的图占用显存要低。
放大算法:真实图片建议用(R-ESRGAN 4x+),动漫二次元建议(R-ESRGAN 4x+ Anime6B),最佳质量(LDSR)。
高清修复采样次数:建议0,采用原图。
重绘幅度:建议0.4~0.7,值越大变化越大。
生成批次

含义:就是在绘制多副图像时,显卡按照一张接一张的顺序画。
用法:按需设置几张图 1~4张,提升抽卡的效率。
☆什么是抽卡?☆
SD出图效果比较随机,大家称之为“抽卡”,需要不断的生成新图,从中抽一张最好的图片。
每批数量
含义:就是显卡同时绘制多副图像,但效果通常比较差。
用法:8G显卡就选1即可。
提示词相关性(CFG Scale)

含义:又被称为提示词引导系数,控制模型对输入文本描述的遵循程度。值越大,生成图像越贴近文本描述;值越小,模型的创新性更强,但可能偏离文本描述。
用法:建议7~12,过低会导致图像的饱和度降低,过高则产生粗糙的线条或过度锐化图像甚至图像验证失真。
随机种子(seed)
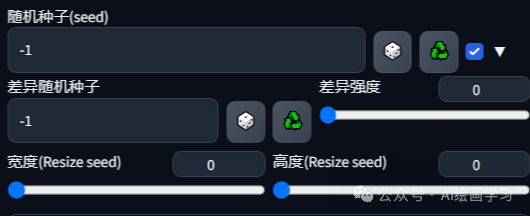
含义:每个图像的唯一编码,能帮我们复制和调整生成的图片。
用法:-1 代表随机生成一个新seed,其他数字都是具体的seed值。
差异随机种子:指在生成图像过程汇总,每次扩散的步骤使用不同的随机种子,从而融合不同的图像,产生叠加的变化。
差异强度:0~1,0 完全相同,1完全不同
三、实战演练
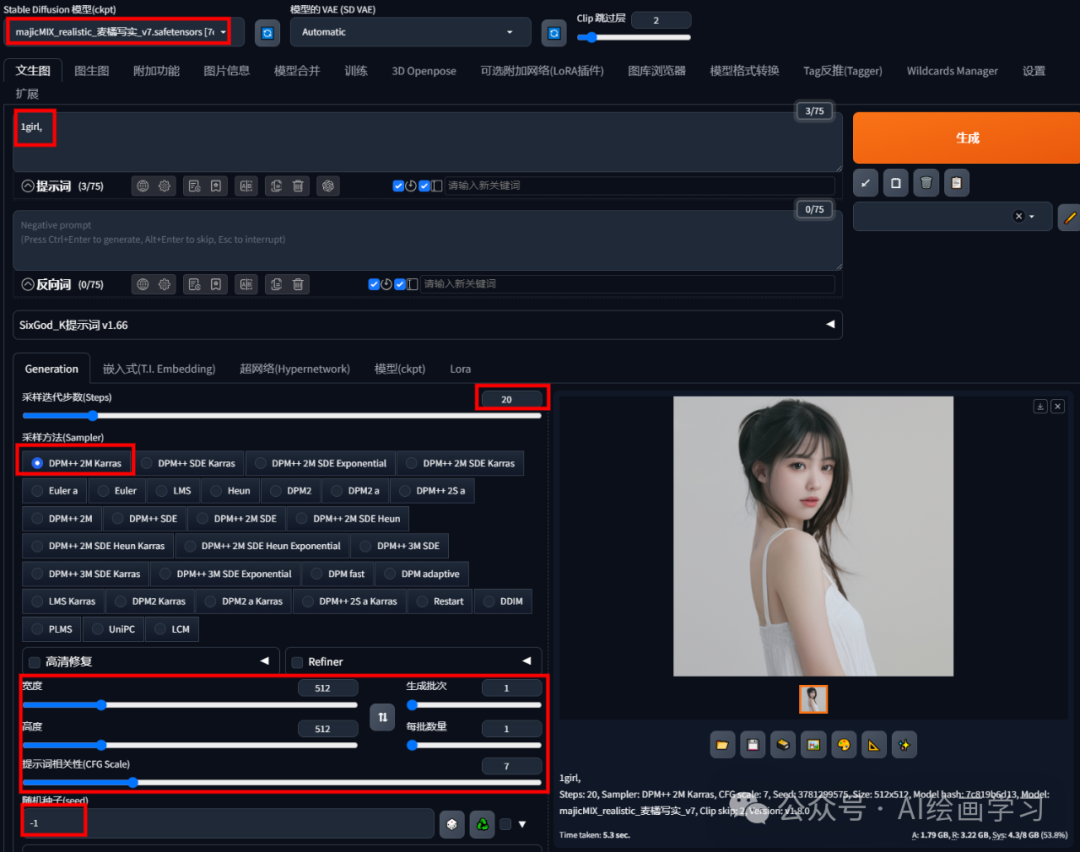
case1 生成1张512*512分辨率的女孩图片
红框是需要操作的地方。
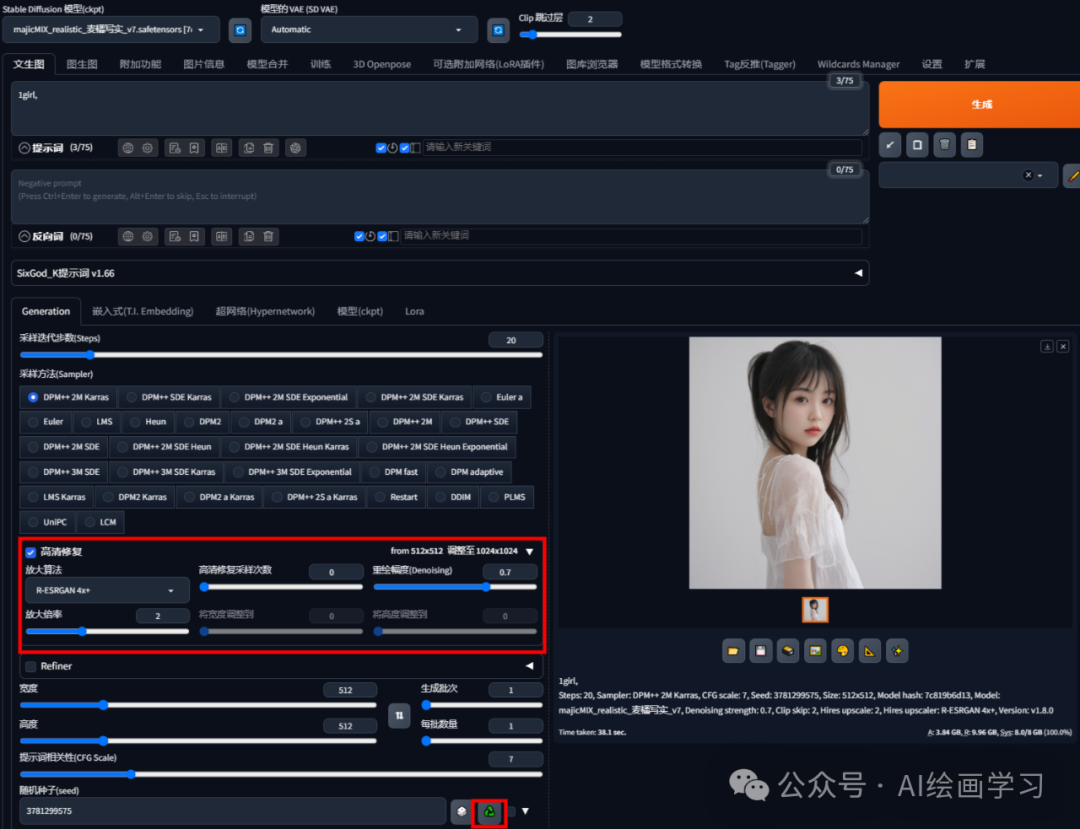
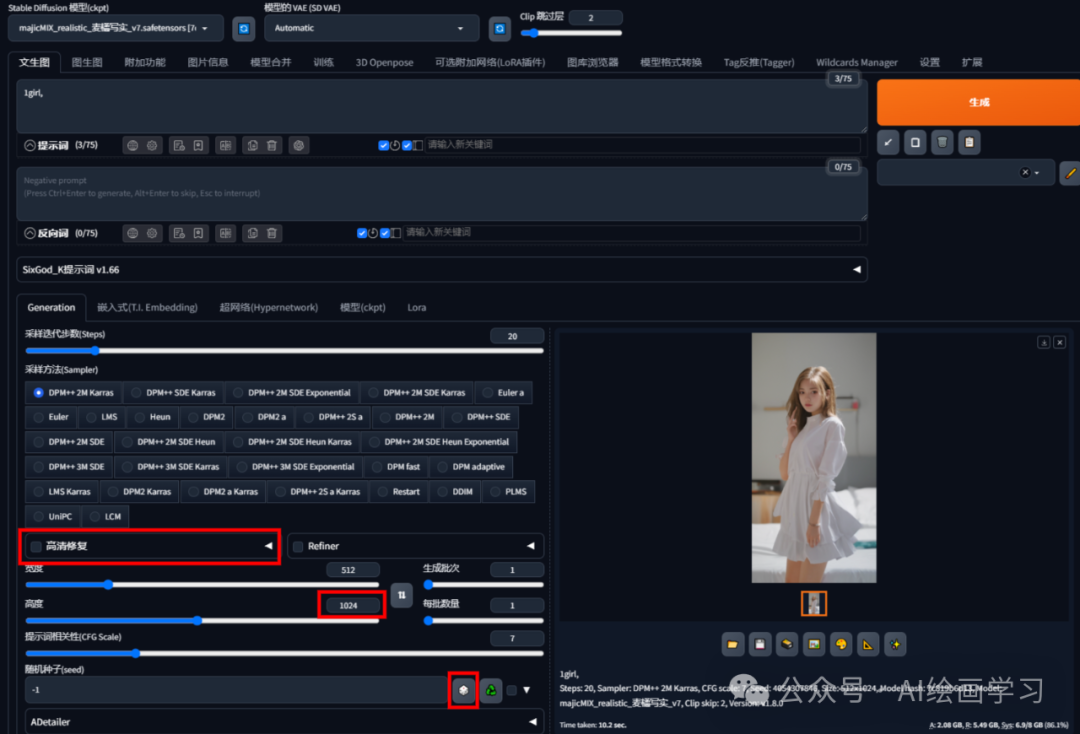
case2 把case1的图片放大2倍
先固定seed值生成“3781299575”,高清修复放大2倍,重绘0.7,女孩衣服变了样子和姿态没变。
case3 生成1张512*1024分辨率的女孩图片
1 点 把seed改为-1,去掉高清修复,调整分辨率高度1024,点击生成。
把seed改为-1,去掉高清修复,调整分辨率高度1024,点击生成。
2 等出图后,再次点击 ,产生新seed:4054307846
,产生新seed:4054307846
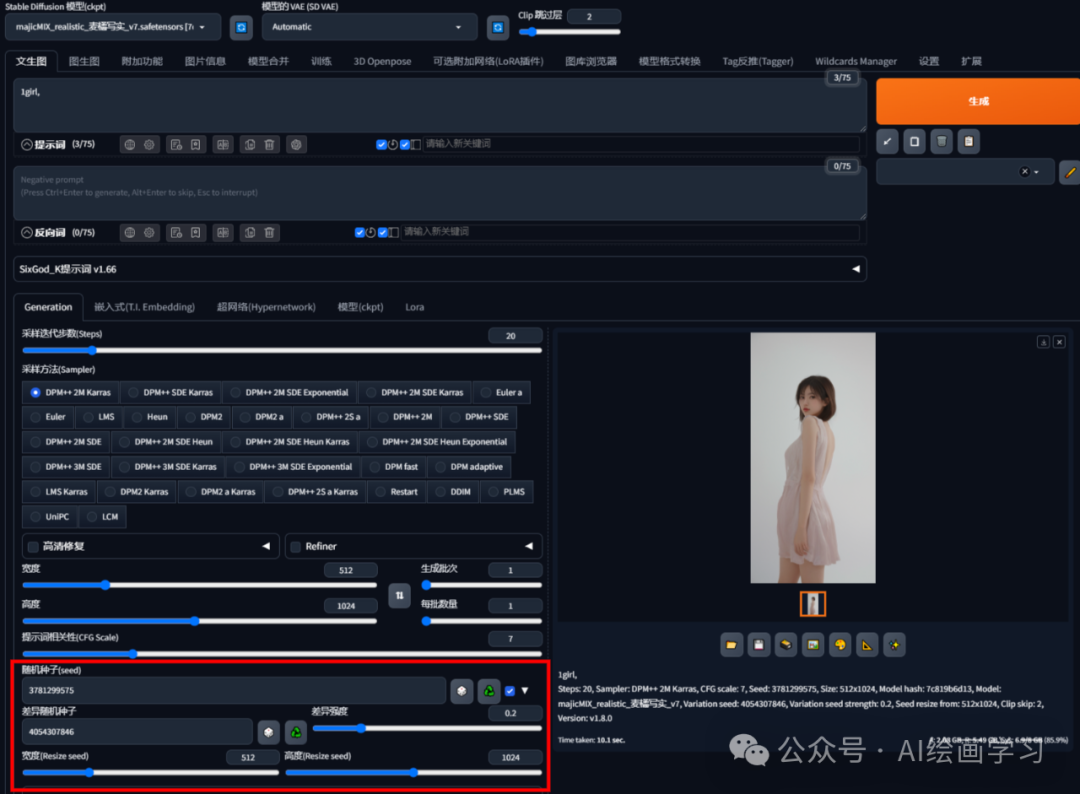
case4 把1和3的融合成512*1024的图****
把随机种子填写case1的seed值,差异种子填写case3的seed值,高度512 宽度1024,差异强调0.2,即可生成。
**

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)