Word2vec 详解
自然语言处理(NLP)是一种涉及到处理语言文本的计算机技术。在NLP中,最小的处理单位是词语,词语是语言文本的基本组成部分。词语组成句子,句子再组成段落、篇章、文档,因此处理NLP问题的第一步是要对词语进行处理。在进行NLP问题处理时,一个常见的任务是判断一个词的词性,即动词还是名词等等。这可以通过机器学习来实现。具体地,我们可以构建一个映射函数 f(x)->y ,其中 x 是词语, y 是它们的
一、Word2vec是什么?
自然语言处理(NLP)是一种涉及到处理语言文本的计算机技术。在NLP中,最小的处理单位是词语,词语是语言文本的基本组成部分。词语组成句子,句子再组成段落、篇章、文档,因此处理NLP问题的第一步是要对词语进行处理。
在进行NLP问题处理时,一个常见的任务是判断一个词的词性,即动词还是名词等等。这可以通过机器学习来实现。具体地,我们可以构建一个映射函数 f(x)->y ,其中 x 是词语, y 是它们的词性。为了使用机器学习模型,需要将词语转换成数值形式。然而,在NLP中,词语是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),不是数值形式的,因此,需要将他们嵌入到一个数学空间中,这个过程就是词嵌入(word embedding)。
词嵌入是将词语映射到一个向量空间中的过程,使得相似的词在向量空间中距离较近,而不相似的词距离较远。Word2vec 则是其中一种词嵌入方法,是一种用于生成词向量的浅层神经网络模型,由Tomas Mikolov及其团队于2013年提出。Word2Vec通过学习大量文本数据,将每个单词表示为一个连续的向量,这些向量可以捕捉单词之间的语义和句法关系。Word2Vec有两种主要架构:连续词袋模型(Continuous Bag of Words,CBOW)和Skip-Gram模型。
二、CBOW模型
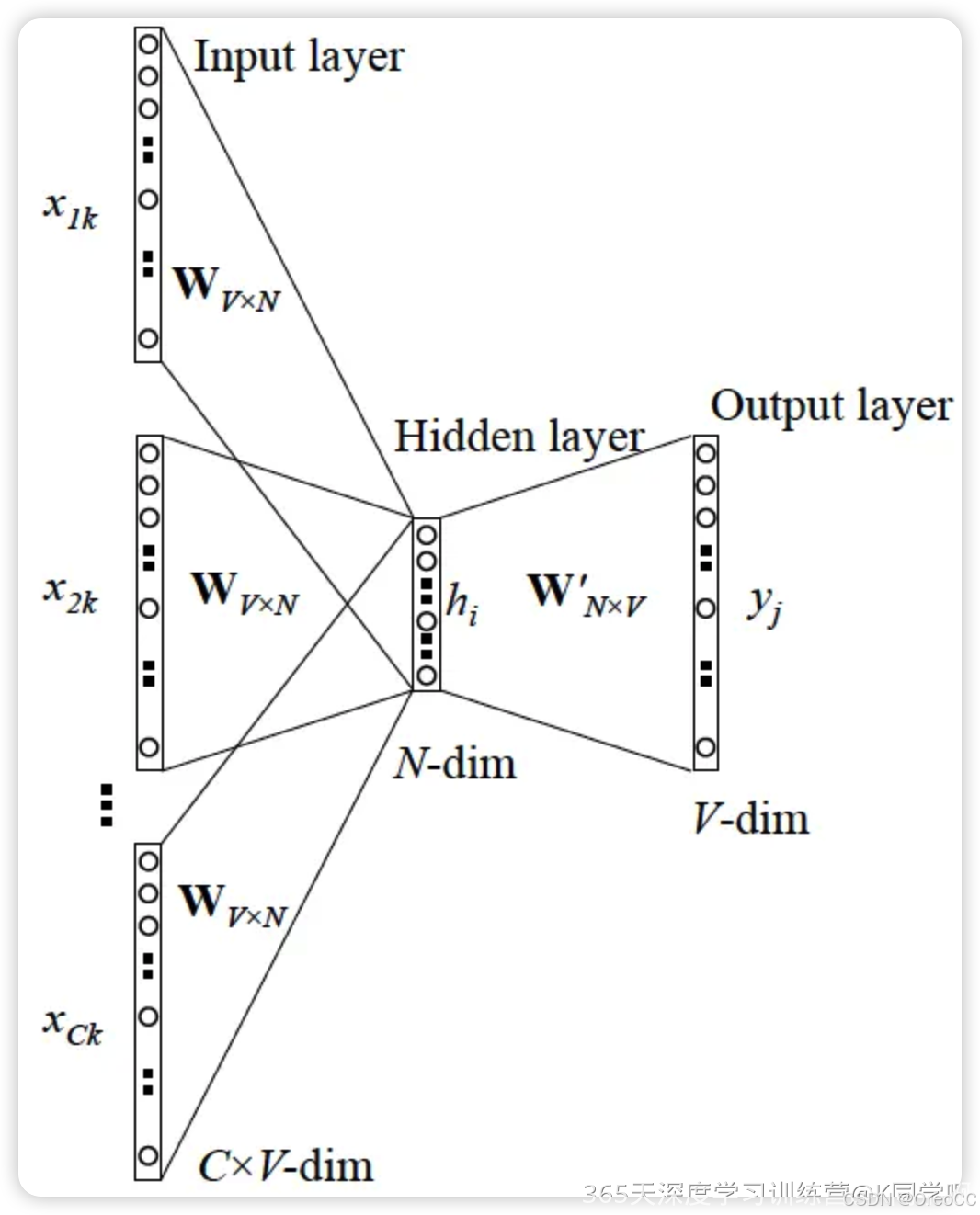
CBOW(Continuous Bag of Words)模型是通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。
具体来说,CBOW模型首先将输入的词语转换为词向量,然后将这些词向量相加得到一个向量表示,这个向量表示就是当前上下文的表示。最后,CBOW模型使用这个向量表示来预测目标的词语的概率分布。CBOW模型的核心思想是根据上下文预测当前词语,因此它通常适用于训练数据中目标词语出现频率较高的情况。
三、Skip-gram模型
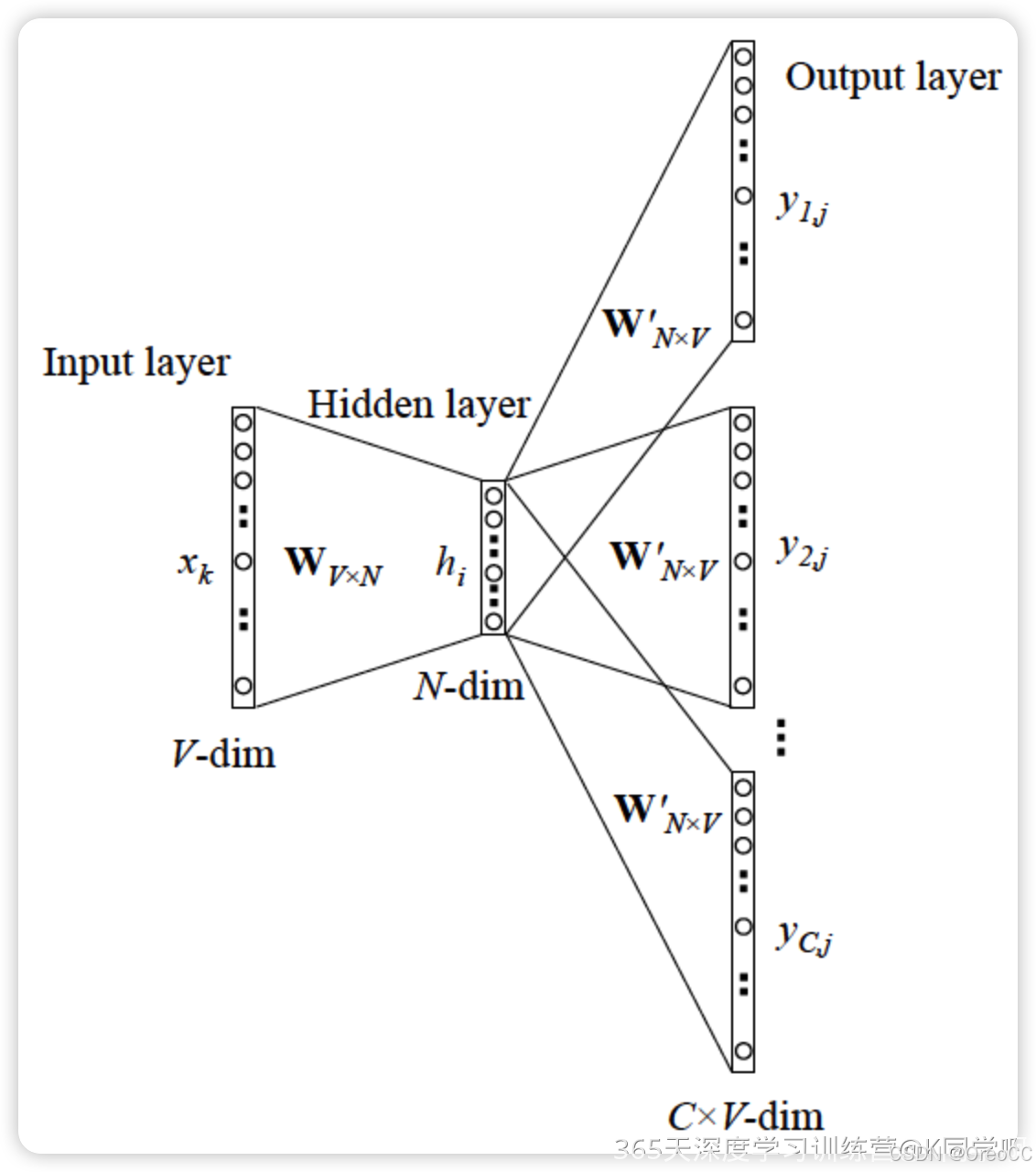
Skip-gram 模型用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
具体来说,Skip-gram 模型首先将目标词语转换为它的词向量,然后使用这个词向量来预测它周围的词语。Skip-gram 模型的核心思想是利用目标词语来预测上下文,因此,它通常适用于训练数据中目标词语出现频率较低的情况。
Skip-gram 模型和CBOW模型的训练过程都是基于反向传播算法和随机梯度下降算法实现的。在训练过程中,两个模型都会通过不断地更新词向量来最小化损失函数,使得目标词语和它周围的词语在向量空间中距离更近。最终,训练完成后,每个词语都被嵌入到了一个低维向量空间中,这些向量可以用于各种NLP任务,如语言模型、词性标注、文本分类等等。
四、实例解答
实例:假设我们有以下句子作为训练语料:
"The quick brown fox jumps over the lazy dog."对于Skip-gram模型,假设我们选择窗口大小为2(即在目标单词前后各取2个单词作为上下文)。以单词 "jumps" 为例,我们将有以下训练样本:
● 输入:jumps, 输出: (brown, fox, over, the)这些驯良样本用于调整词向量,使得给定单词 "jumps" 时,上下文单词的概率最大化。
而对于CBOW模型,训练样本是相反的:
● 输入: (brown, fox, over, the) , 输出:jumps在这种情况下,CBOW模型会根据上下文(brown, fox, over, the)来预测目标单词 "jumps" 。
训练完成后,每个单词都会被赋予一个词向量,这些词向量可以用于后续的NLP任务,如文本分类、聚类、相似度计算等。一个有趣的现象是,词向量之间的数学运算可以揭示单词之间的语义关系,例如:
● vce("king") - vec("man") + vec("woman") ≈ vec("queen")
● vce("Paris") - vec("France") + vec("Italy") ≈ vec("Rome")这些例子说明,Word2Vec可以成功捕捉单词之间的相似性和类比关系。
五、调用方法
gensim.models.word2vec() 函数原型:
class gensim.models.Word2Vec(
sentences=None,
corpus_file=None,
vector_size=100,
epochs=5,
alpha=0.025,
window=5,
min_count=5,
max_vocab_size=None,
sample=1e-3,
seed=1,
workers=1,
min_alpha=0.0001,
sg=0,
hs=0,
negative=5,
ns_exponent=0.75,
cbow_mean=1,
hashfxn=hash,
iter=None,
null_word=0,
trim_rule=None,
sorted_vocab=1,
batch_words=10000,
compute_loss=False,
callbacks=(),
max_final_vocab=None
)参数说明
以下是一些常用的参数及其含义:
1. sentences
-
类型:可迭代对象(如列表、生成器)
-
说明:训练数据,是一个由句子组成的可迭代对象。每个句子是一个单词列表。如果使用
corpus_file,则可以忽略此参数。
2. corpus_file
-
类型:字符串(文件路径)
-
说明:如果提供了文件路径,Word2Vec 会从文件中读取语料库,而不是直接从内存中的
sentences读取。文件中的每一行应该是一个句子,单词用空格分隔。
3. vector_size
-
类型:整数
-
默认值:100
-
说明:词向量的维度。较大的值需要更多的训练数据,但可以捕捉更复杂的语义关系。
4. epochs
-
类型:整数
-
默认值:5
-
说明:训练的迭代次数。较大的值可以提高模型的准确性,但会增加训练时间。
5. alpha
-
类型:浮点数
-
默认值:0.025
-
说明:初始学习率。
6. window
-
类型:整数
-
默认值:5
-
说明:上下文窗口大小,即目标单词前后考虑的单词数量。
7. min_count
-
类型:整数
-
默认值:5
-
说明:忽略总频率低于此值的所有单词。较高的值可以减少稀有单词对模型的影响。
8. workers
-
类型:整数
-
默认值:1
-
说明:训练模型时使用的线程数。如果机器有多核 CPU,可以设置为多线程加速训练。
9. sg
-
类型:整数
-
默认值:0
-
说明:训练算法的选择。
sg=1表示使用 Skip-gram 模型,sg=0表示使用 CBOW 模型。
10. hs
-
类型:整数
-
默认值:0
-
说明:是否使用层次 Softmax。
hs=1表示使用层次 Softmax,hs=0表示使用负采样(默认)。
11. negative
-
类型:整数
-
默认值:5
-
说明:负采样的数量。较大的值可以提高模型的准确性,但会增加训练时间。
12. cbow_mean
-
类型:整数
-
默认值:1
-
说明:在 CBOW 模型中,是否使用上下文单词的平均值(
cbow_mean=1)或求和值(cbow_mean=0)。
13. compute_loss
-
类型:布尔值
-
默认值:
False -
说明:是否计算训练过程中的损失值。
14. callbacks
-
类型:回调函数列表
-
默认值:
() -
说明:在训练过程中调用的回调函数,用于监控训练进度或调整参数。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)