GShard中的混合专家(MoE)
1991年,Geoffrey Hinton和Michael I. Jordan发表的论文被认为是MoE的奠基之作。通过引入专家网络和门控网络的组合,系统能够有效地给不同的专家,从而减少干扰。在论文的实验中希望对说话人的元音音素数据进行识别,那么每个专家可能就专注于区分某一对元音(例如[a]和[A])。2017年,Google发布《型神经网络:稀疏门控的MoE层》(后文简称为“2017年论文”)。通
为了搞清楚MoE这个概念,我在查找相关论文的时候,看到一篇讲到其发展史的博客:混合专家模型(MoE)的前世今生(感谢大佬🙇)
1991年,Geoffrey Hinton和Michael I. Jordan发表的论文Adaptive Mixture of Local Experts被认为是MoE的奠基之作。通过引入专家网络和门控网络的组合,系统能够有效地分配任务给不同的专家,从而减少干扰。在论文的实验中希望对说话人的元音音素数据进行识别,那么每个专家可能就专注于区分某一对元音(例如[a]和[A])。
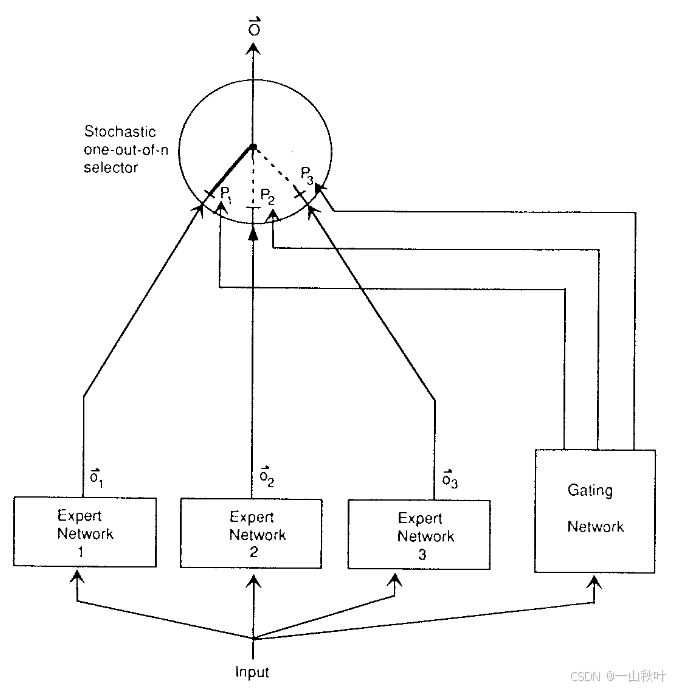
2017年,Google发布《超大型神经网络:稀疏门控的MoE层》(后文简称为“2017年论文”)Outrageously Large Neural Networks: The Sparsely-Gated Mixure-of-experts Layer。通过条件计算显著提升模型的容量,同时保持计算效率。实验中它将MoE应用到堆叠的LSTM层之间,每个MoE层的参数量可以高达137B。因为MoE是一种 条件计算 的实现,会根据输入有选择地只激活部分网络模块,所以能以较低的计算成本,在语言建模和机器翻译等现代深度学习任务中,取得了比当时的SOTA好很多的性能。
2020年,Google发布《通过条件计算和自动分片技术,训练超大规模模型》GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding。它训练了一个带稀疏门控MoE层的Transformer模型,带600B参数用于序列转换。我是从DeepSeek-V3的技术报告里的这篇参考文献过来的,那就细细品品这篇论文吧。(后面发现它除MoE外还有很多别的,标题的名字改了又改,最后还是沿用这个吧,这也是我找的这篇论文的初衷)
随着模型参数量增大,机器翻译的质量确实显著提升,计算花销还没有加很多,呈现的亚线性增长,怎么做到的?是条件计算(Conditional Computation)和自动分片技术(GShard Annotation)!
模型架构
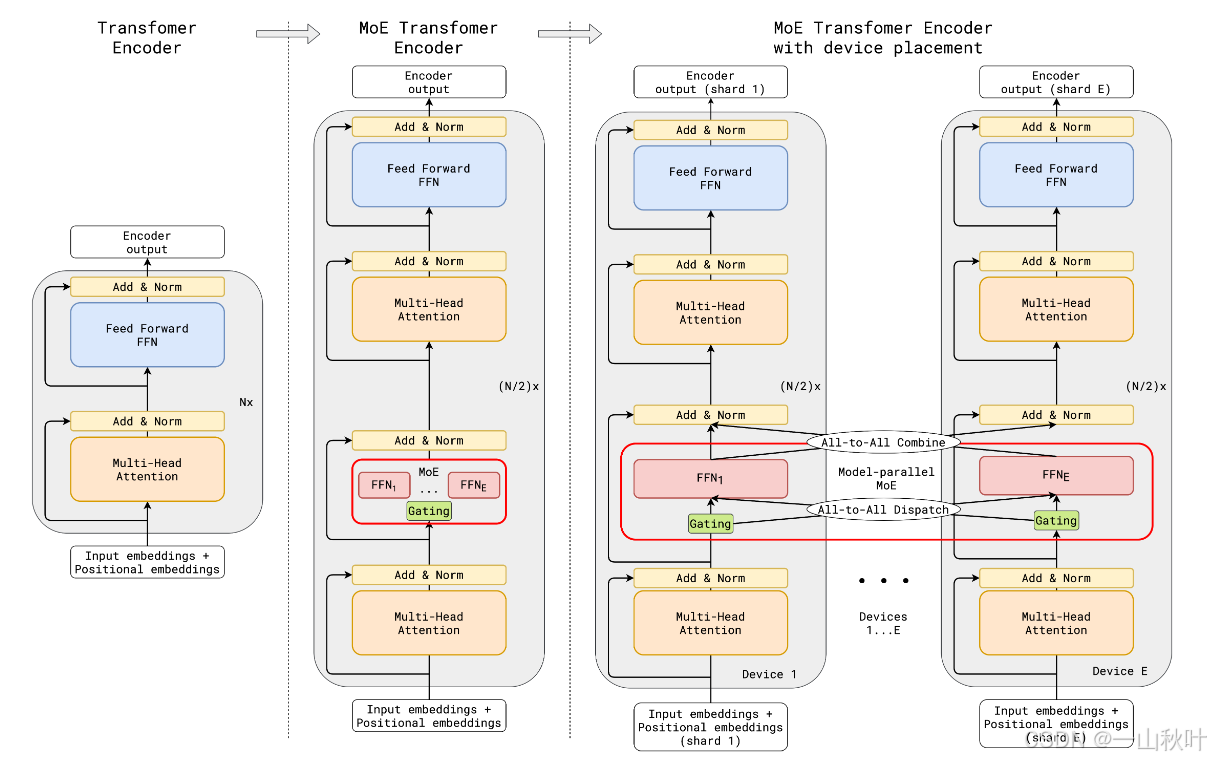
图中是添加了MoE的Transformer编码器的示意图,解码器的修改类似。如左图所示,标准Transformer的编码器由自注意力机制和前馈神经网络(Feed Forward Network, FFN)组成;中图将每隔一个FNN层就做一次替换,换后的MoE层包含多个专家(FFNs),带一个top-2门控,每层仅选择前两个专家参与计算,训练和推理时需要被激活的子网络的规模和MoE层的专家数也就独立了,便也造就了计算成本的非线性增长;右图进一步将每个MoE层分片到多个设备上,利用“局部组”的概念,每个设备只需要处理一部分专家的计算,得到的也仅是输入的一部分,这种分布式实现不仅提高了计算效率,也运行模型扩展到更大的规模。
每个MoE层由E个前馈神经网络组成,每个专家输出
,其中
是输入token,
和
分别是输入和输出的投影矩阵,结合形成了这个MoE层的输出
,其中向量
由门控函数
所得,每个token至多被发送给两个专家,相应的门控项
会被置为非零,表示专家对最终网络输出的贡献程度。
门控函数
门控函数是MoE层的核心组件,它会计算每个专家的得分,然后通过softmax激活函数来决定每个专家在处理输入时的权重。这篇论文设计了一个新颖有效的门控函数,先摆伪代码:

考量如下~
负载均衡
传统处理中,会根据softmax后得到的概率分布选出前k个专家,正如许多前人工作所呈现的,这在训练过程中会导致负载不均衡的问题,多数token发送给少数专家,有些专家得不到训练,而越训练的慢的专家后续被门控选择的概率越低,恶性循环。
2017年论文的做法
它选择添加“软约束”(一定的时间后发挥作用),引入重要性损失、负载损失,往门控输出添噪声
- 重要性损失
在当前批次训练中,它将每个专家针对所有tokens的门值总和定义成这个专家的重要性:
计算这个重要性值的变异系数(Coefficient of Variation,衡量数据集相对变异性的统计学指标,是标准差与均值的比率,有)的平方,乘以一个手动调节的缩放因子,作为额外的重要性损失:
但会怀疑,这只能保证每个专家的重要性尽量一样,有的专家可能拿到很少的大权重token,而另外的专家接收许多小权重token,依旧有不平衡的问题。
- 引入噪声
原先门控输出为,其中针对第
个专家的
。
现在通过在门控输出中添加噪声,模型能在选择专家时引入随机性,促进负载平衡,并增强模型的鲁棒性。每个专家的噪声由可训练的权重矩阵进行控制。变成:
其中表示从标准正态分布(均值为0,标准差为1)中抽取随机噪声,
是一个平滑的激活函数,输出正值,用于缩放噪声。
第个专家在给定输入
的情况下被激活的概率设置为
其中表示刨除第
个专家后,排第
大的
。标准正态分布的累积概率有
。
- 负载损失
样例数是一个离散值,不能直接用于反向传播,经过《引入噪声》这一节的处理后,便可以得到每个专家在整个批次中的负载的平滑估计:
为解决《重要性损失》这一节提到的怀疑,为确保每个专家拿到一样多的训练样例,可以借此引入负载损失,其中同样有一个手动调节的缩放因子
。
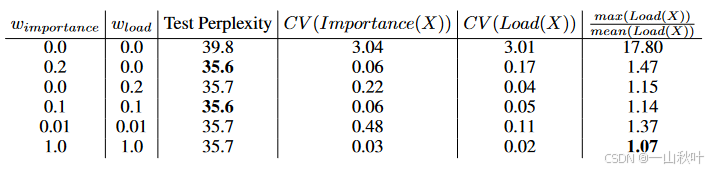
从实验结果来看,不论用哪个损失或两个都用,困惑度(Text Perplexity)是相近的,说明这两个损失函数对于最终模型质量的影响相似,但肯定比都不用要好。但论文也说了在负载损失的作用下,系统能够更加均衡地分配任务,避免某些专家过度忙碌。
这里的做法
这里直接强制每个专家处理的token数低于某个设定好的阈值,这个阈值名为专家容量(expert capacity)。假设在一个批次中共N个token,每个token最多分配给两个专家,专家容量就会设为O(N/E)。当然
会给每个专家一个token计数器
。如果某个token选出的两个专家的技术都超出了这个阈值,那这个token便是溢出(overflowed),对应的
会退化成零向量,不分配给任何专家,而是通过残差连接直接传到下一层。
比前文引入平衡函数,能避免动态负载平衡的复杂性,无需实时监控每个专家的激活情况,可以实现更高效的并行计算。(有种那么多复杂数学式白忙活一场的感觉)
本地调度
这篇论文将所有的token均匀划分到个局部组,每组有
个token进行本地调度,所有组独立并行执行,门控函数的速度提升
倍。赋予每个专家的容量是
,按理说
越大,溢出token越少,模型质量越好,但单个专家处理的越多,并行执行的门控数量
就越少,会损害训练的吞吐量,得权衡。
辅助损失函数
这里整体的损失函数为,其中
是一个常数。和前面的重要性损失、负载损失不同,这里引入了一种新的可微的辅助损失来加强负载平衡:
其中,表示传给专家
的token数占比。为了鼓励专家的负载均衡,辅助损失通常会考量这个负载比例的平方项,但论文将其替换成了可微的近似值
(我觉得这两个乘积项有近似于“重要性”和“负载”含义),可通过梯度下降进行优化,数值稳定性更好。
随机路由
直觉上模型的输出是两个专家(top-2)的输出的加权平均,但如果次优专家的权重很小,就直接忽略掉他吧,让
保持为0别去改它,在小规模模型中这样做(伪代码19、21行),结果溢出token更少。
高度并行
为了在设备集群中高效实现上述模型,作者们在TensorFlow 软件框架和 TPU 硬件平台上对矩阵乘法、加法等线性代数操作做了高度的优化,可以先将模型的计算表示成这些操作,以提高效率和性能,内部具体的实现放另一篇博客吧(写了(●'◡'●)),感觉挺智能的,这里就涉及用法得了。
方便之处在于,只要通过split、replicate等GShard API,把红色标注的分片信息传递给编译器,编译器就会自动应用变换并并行执行。而且用户只需标注重要算子,像Einsums里的张量,编译器会自己分析对其余张量的分片。
核心实现如下伪代码,其中的操作不受集群具体配置的影响,而是将集运看作一个统一的设备进行处理:

其中:局部组数;
:每组token数;
:每个token的特征维度数;
:专家数;
:专家容量;
:前馈隐藏层维度数。组数和专家数得是设备数
的倍数,
。
通过TensorFlow的爱因斯坦求和约定库tf.einsum,可以用简洁的符号表示复杂的张量操作,基本用法如下:
tf.einsum(subscripts, *operands)
subscripts:一个字符串,表示操作中各个张量维度如何映射,每个字母代表张量的一维
*operands:表示参与运算的一或多个张量
以伪代码中的为例,表示对输入张量
(形为
,按组划分)和门控权重
(
,所有设备都复制一份)做乘法,得到
的三维张量。可能是多种操作混在一起,还变形,非一眼能分解的。
从算法一求得的门控值中获取专家们的组合权重
(一个形为
的四维张量,当
作为组
中第
个发送给专家
的输入token时,对应位置元素值便非零)和调度掩码
(组合权重非零处标注为1)。
中指示了每个token是否被分配给某个专家的信息,与输入张量结合后,形成新的张量
(
,按专家划分),记录了每个被激活的专家收到的输入信息。
下面就是纯前馈层操作啦:每个专家各自对调度后的输入和输入权重做张量乘,所有专家一起得到
(
)。再各自应用激活函数引入非线性,和输出权重
做张量乘,做一番变形,所有专家一起得到
(
,按组划分)。最后各组分别和组合权重乘,得到最终输出
(
)。
带标注的算法版本就是
inputs = split(inputs, 0, D)
wg = replicate(wg)
gates = softmax(einsum("GSM, ME -> GSM", inputs, wg)
combine_weights, dispatch_mask = Top2Gating(gates)
dispatched_inputs = einsum("GSEC, GSM -> EGCM", dispatch_mask, inputs)
dispatched_inputs = split(dispatched_inputs, 0, D)
h = einsum("EGCM, EMH -> EGCH", dispatched_inputs, wi)这样一流程下来,每台设备上的浮点计算数为
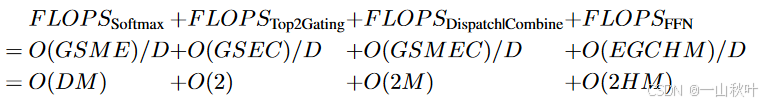
实验中最多16K个设备,必然,故每台设备上,softmax操作花费的FLOPS必然少于ffn,所以设备变多时,总花销也只是呈现亚线性增长。另外在
台TPU设备上调度AllToAll实现token分配和收集,阔设备通信成本不过
多语种机器翻译
用多语种机器翻译验证设计,辅以GShard实现高效训练。针对多任务学习问题Multilingual MT,旨在设计能同时翻译多种语言的单个神经网络。论文提出M4模型,采用MoE架构,通过条件计算动态激活相关子网络,使用含100种语言、约有130(13billion)亿个训练样例的庞大数据集进行训练,利用2048个TPU v3核执行分布式训练策略,这个有600B参数的模型可在4天内有效训练。
实验结果表明,M4相较于传统的双语模型翻译质量更好(比的是BLUE分数,这指标在多语言时怎么算自有它的规则),在高资源语言上通过参数共享和多任务学习的方式可以减轻过拟合,在低资源语言的翻译任务中有很好的迁移效果。这也验证了通过扩大模型规模提升模型质量依旧可行。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)