day13_挖掘类标签
人工智能:是关于赋予机器“智能”,使其能够模拟和执行人类的智能行为。人工智能的主要领域:自然语言处理:使计算机能够理解、解释和生成人类语言。例如,语音识别、机器翻译和聊天机器人。计算机视觉:使计算机能够从图像或视频中提取信息。例如,图像识别、面部识别和自动驾驶汽车的环境感知。机器人技术:开发能够自主执行任务的物理机器人。例如,工业机器人、医疗手术机器人和家庭服务机器人。专家系统:模仿人类专家的决策
文章目录
day13_挖掘类标签
一、人工智能概述(了解)
人工智能:是关于赋予机器“智能”,使其能够模拟和执行人类的智能行为。
人工智能的主要领域:
-
自然语言处理:使计算机能够理解、解释和生成人类语言。例如,语音识别、机器翻译和聊天机器人。
-
计算机视觉:使计算机能够从图像或视频中提取信息。例如,图像识别、面部识别和自动驾驶汽车的环境感知。
-
机器人技术:开发能够自主执行任务的物理机器人。例如,工业机器人、医疗手术机器人和家庭服务机器人。
-
专家系统:模仿人类专家的决策过程。例如,医学诊断系统和金融分析系统。
-
推荐系统:根据用户的历史数据和偏好,向用户推荐产品或服务。例如,电子商务网站的商品推荐和流媒体平台的内容推荐。
-
机器学习:一种通过数据学习和改进性能的技术,是实现人工智能的重要方法。包括监督学习、无监督学习和强化学习。
人工智能的主要应用:
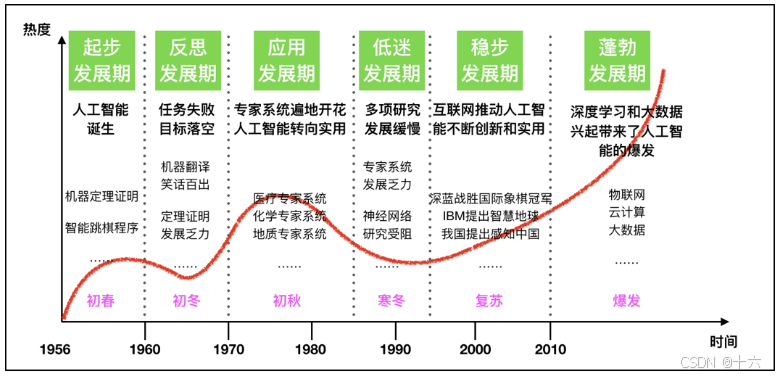
发展历史:
二、机器学习概述(了解)
机器学习:是一种人工智能技术,它让计算机系统通过学习数据中的模式和规律来自动改进其性能,而不是通过显式编程来完成任务。例子:电子邮件垃圾邮件过滤器。
1、人工智能、机器学习、深度学习关系
机器学习是人工智能的一个分支,深度学习是实现机器学习的一种技术。如下图: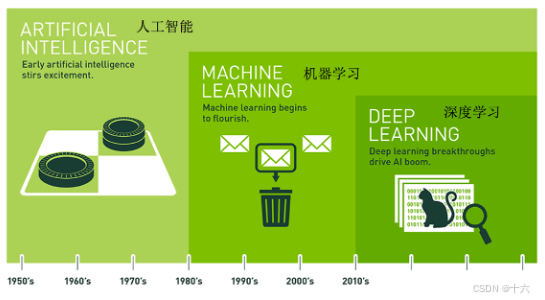
2、数据分析、数据挖掘区别
-
数据分析:
- 对数据的一种操作手段,目标是经过先验(已有经验)的约束,对数据进行整理、筛选和加工,最后得到信息。【从数据到信息的转化过程】
- 针对历史数据,分析得出各项指标,经过数据分析我们得到的是信息。
-
数据挖掘:
- 是对数据分析之后的信息,进行价值化的分析。【信息的价值化】
- 经过大量数据挖掘我们得到的是有价值的信息,即对信息进行规律或价值提前。
机器学习是一种方法;数据挖掘是一件事情
3、机器学习分类(熟悉)
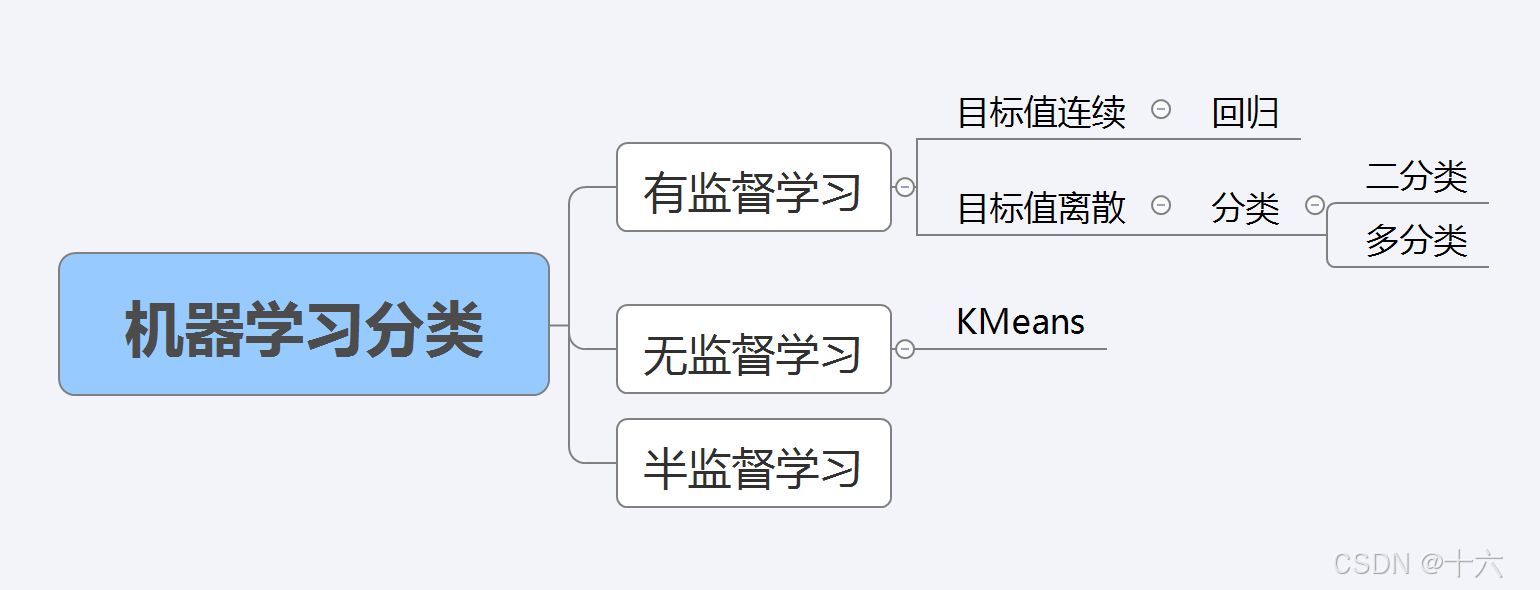
区别点:训练集的数据里面是否有目标值。
3.1 有监督学习
监督学习也称为监督机器学习,其定义是使用标记数据集训练算法以准确对数据进行分类或预测结果。
通俗易懂地讲:监督学习指的是人们给机器一大堆标记好的数据,比如一大堆照片,标记住那些是猫的照片,那些是狗的照片,然后让机器自己学习归纳出算法或模型,然后所使用该算法或模型判断出其他照片是否是猫或狗。
代表的算法或模型有Linear regression、Logistic regression、SVM、Neural network等。
如下图流程所示: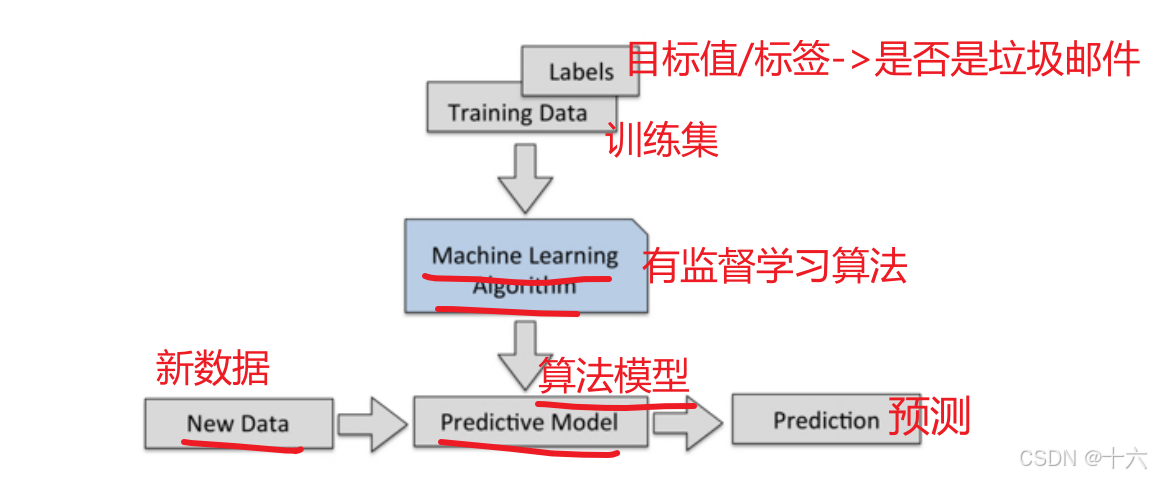
- 利用分类对类标进行预测
监督学习从数据中学习一个分类模型或分类决策函数,称为分类器(classifer),分类器对新的输入进行输出的预测,称为分类(classification)。也就是说分类问题包括学习和分类的两个过程。
- 利用回归预测连续输出值
针对连续型输出变量进行预测,也就是所谓的回归分析(regression analysis)。回归分析中,数据中会给出大量的自变量和相应的连续因变量(对应输出结果),通过尝试寻找自变量和因变量的关系,就能够预测输出变量。
3.2 无监督学习
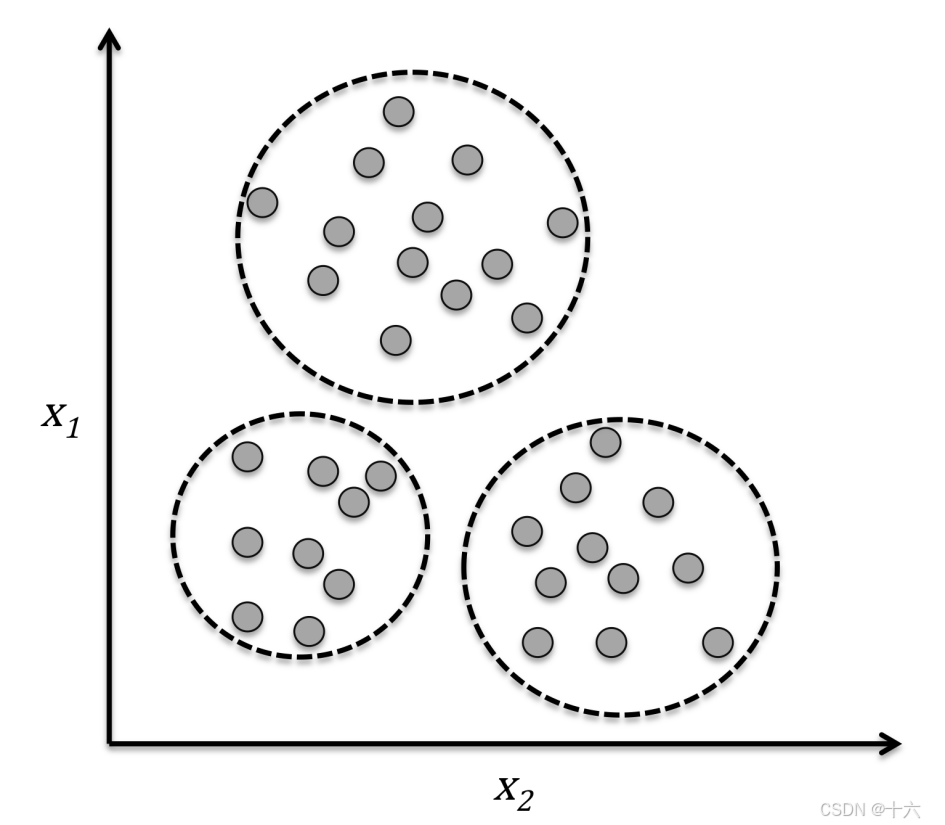
无监督学习也称为无监督机器学习,它使用机器学习算法分析和聚类未标记数据集。
聚类是一种探索性数据分析技术,在没有任何相关先验信息的情况下(相当于不清楚数据的信息),它可以帮助我们将数据划分为有意义的小的组别(也叫簇cluster)。其中每个簇内部成员之间有一定的相似度,簇之间有较大的不同。这也正是聚类作为无监督学习的原因。
3.3 半监督学习
半监督学习在监督学习和无监督学习之间提供了一种折衷方案。在训练过程中,它使用较小标记数据集指导从较大未标记数据集中进行分类和提取特征。半监督学习可以解决监督学习算法没有足够多标记数据的问题。
三、SparkML概述(了解)
MLlib是Spark的机器学习库。提供了利用Spark构建大规模和易用性的机器学习平台,组件:
(1)ML 算法:包括了分类、回归、聚类、降维、协同过滤
(2)Featurization特征化:特征抽取、特征转换、特征降维、特征选择
(3)Pipelines管道:tools for constructing, evaluating, and tuning ML Pipelines
(4)Persistence持久化:模型的保存、读取、管道操作
(5)Utilities:提供了线性代数、统计学以及数据处理工具
官方文档:https://spark.apache.org/docs/latest/ml-guide.html
归一化代码:
from pyspark.ml.feature import MinMaxScaler
from pyspark.ml.linalg import Vectors
from pyspark.sql import SparkSession
import os
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.appName("SparkML——归一化处理")\
.master("local[*]")\
.getOrCreate()
# 2- 数据输入
init_df = spark.createDataFrame(
data=[
(0,Vectors.dense([1.0,0.1,2.0])),
(1,Vectors.dense([2.0,1.1,1.0])),
(2,Vectors.dense([3.0,10.1,3.0]))
],
schema=["id","features"]
)
init_df.show()
init_df.printSchema()
# 3- 数据处理
# 归一化处理
# 创建归一化实例对象
transformer = MinMaxScaler(min=0.0,max=1.0,inputCol="features",outputCol="new_features")
# 使用归一化实例对象对数据进行处理
# 实例对象对数据进行学习。这里就是分析出最大值、最小值是多少
model = transformer.fit(init_df)
# 对数据进行真正的处理
result_df = model.transform(init_df)
# 4- 数据输出
print(model.getMin())
print(model.getMax())
result_df.show()
# 5- 释放资源
spark.stop()
四、SparkML构建聚类算法(熟悉)
1、SparkML聚类介绍
聚类是一种无监督学习技术,可以在事先不知道正确结果(即无类标信息或预期输出值)的情况下,发现数据本身所蕴含的结构等信息。
聚类的目标是发现数据中自然形成的分组,使得每个簇内样本的相似性大于其他簇内样本的相似性。
聚类本质上是一种分组方法,分组的标准是组内对象相似度尽可能高,而组间对象的相似度尽可能低。
可将聚类理解为:将对象的集合进行分组的过程。
2、SparkML聚类原理详解
Euclidean Distance 定义:欧几里得距离(Euclidean Distance)是数学上用来衡量两点间距离的一种方法。它是两点在欧几里得空间中的直线距离,通常也被称为直线距离或L2距离。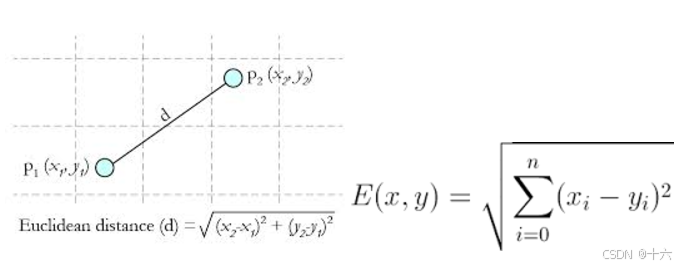
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)。
3、K-Means算法原理
聚类(clustering) 属于无监督学习 (unsupervised learning),无类别标记(class label)。如下图,相同类别的通过属性之间的相似性聚集在一起。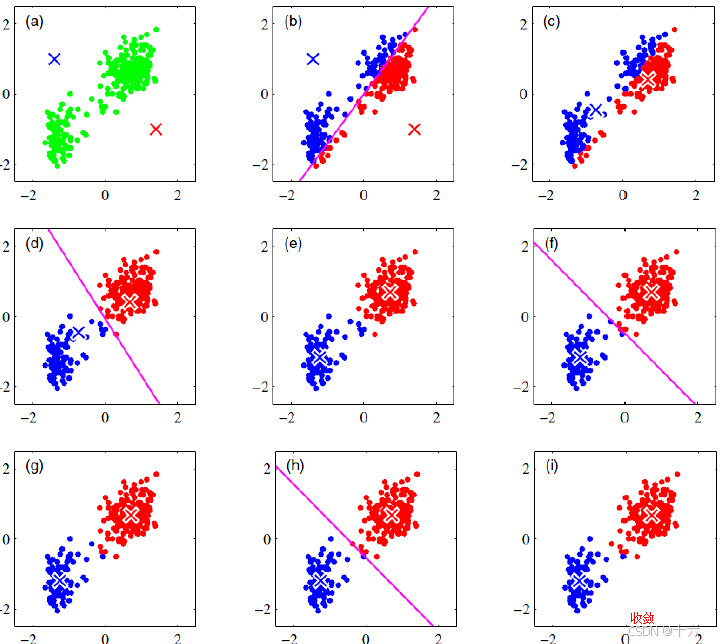
K-Means算法特点:
-
优点:速度快,简单。对处理大数据集,该算法保持可伸缩性和高效率。当簇近似为高斯分布时,它的效果较好。
-
缺点:最终结果跟初始点选择相关,容易陷入局部最优,需知道k值
- k均值算法中k是直接给定的,这个k值的选定是非常难估计的。
- k均值的聚类算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,当数据量大的时候,算法开销很大。
- k均值是求得局部最优解的算法,所以对于初始化时选取的k个聚类的中心比较敏感,不同点的中心选取策略可能带来不同的聚类结果。
- 对噪声点和孤立点数据敏感。
K均值是一种基于属性/特征将对象分类或分组为K的算法组数。 K是正整数。 通过最小化平方和来完成分组数据与对应的集群中心之间的距离。
计算步骤:
(1)选择 K 个点作为初始聚类中心
(2)计算其他的点到中心点的距离, 进行聚类, 使用欧式距离
(3)重新计算每个聚类的中心点, 再次聚类
(4)直到中心点不再变化, 或者达到迭代次数
如下流程图: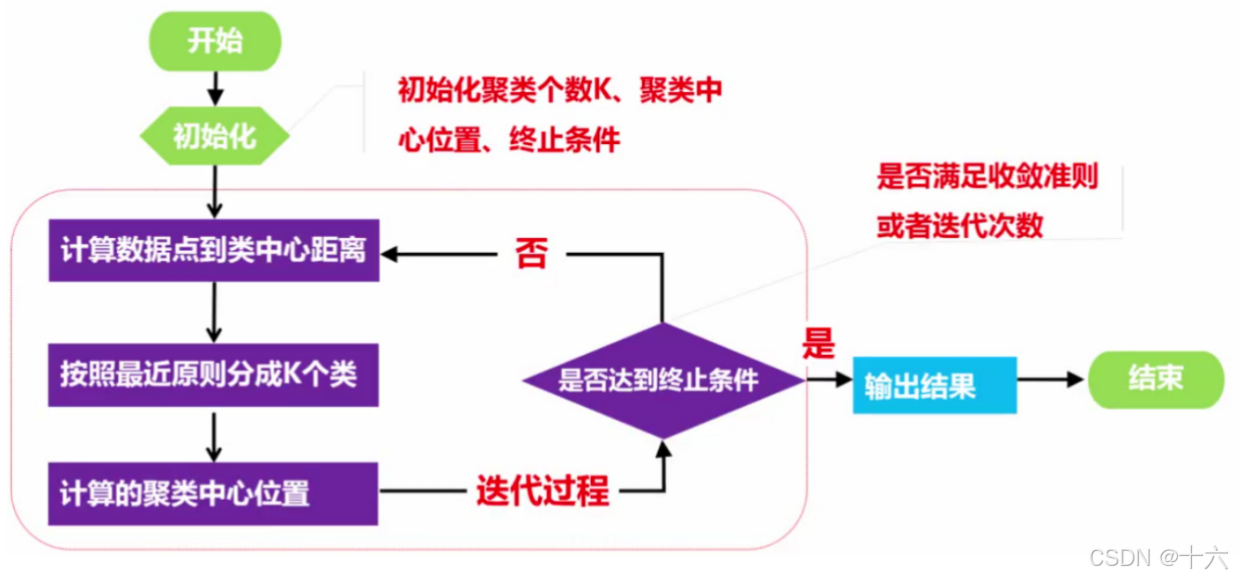
4、K-Means性能评价指标
4.1 SSE误差平方和
一种度量k-means算法的聚类效果的指标是误差平方和SSE(Sum of Squared-Error)。
计算公式:
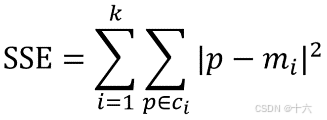
-
P表示点位置(x,y)。
-
Mi为质点的位置。
使用方法:SSE表示数据样本与它所属的簇中心之间的距离(差异度)平方之和。直观的来说,SSE越小,表示数据点越接近它们的中心,聚类效果越好。因为对误差取了平方,更加重视那些远离中心的点。
4.2 轮廓系数 Silhouette Cofficient
评估标准描述:结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类算法的效果。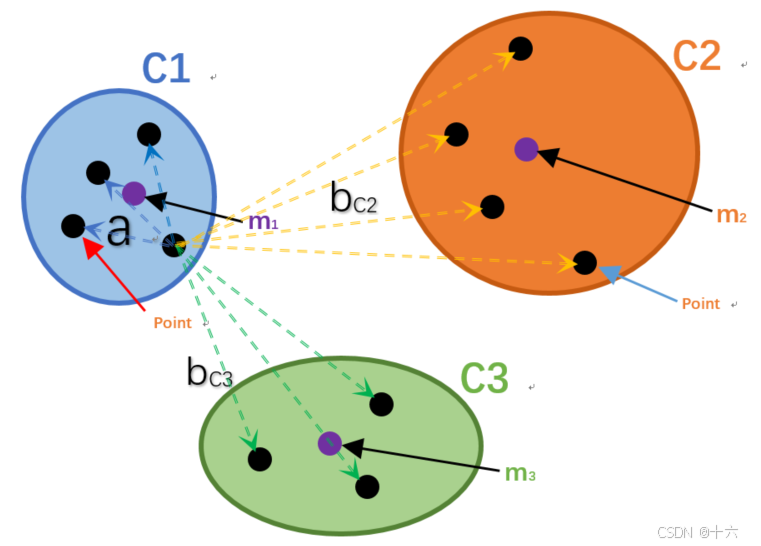
参数描述:
-
a表示C1簇中的某一个样本点Xi到自身簇中其他样本点的距离总和的平均值。
-
bC2表示样本点Xi 到C2簇中所有样本点的距离总和的平均值。
-
bC3表示样本点Xi 到C3簇中所有样本点的距离总和的平均值。
-
我们定义b = min(bC2 ,bC3)
计算公式: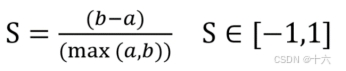
-
a:样本Xi到同一簇内其他点不相似程度的平均值
-
b:样本Xi到其他簇的平均不相似程度的最小值
使用方法:
-
每次聚类之后,每一个样本点都会得到一个轮廓系数,当S的取值越靠近1,当前点与周围簇距离较远,结果非常好。
-
当S的取值为0,说明当前点可能处在两个簇的边界上。
-
当S的取值为负数时,可能这个点被误分了。
-
求出所有样本点的轮廓系数之后再求平均值就得到了平均轮廓系数,平均轮廓系数越大,簇内样本距离越近,簇间样本距离越远,聚类效果越好。
最好的聚类结果 a<<b (b-a)/max(a,b) = b/b = 1
最差的聚类结果 a>>b (b-a)/max(a,b) = -a/a= -1
5、K-Means药物聚类代码实战
将以下药物数据聚类成2个簇。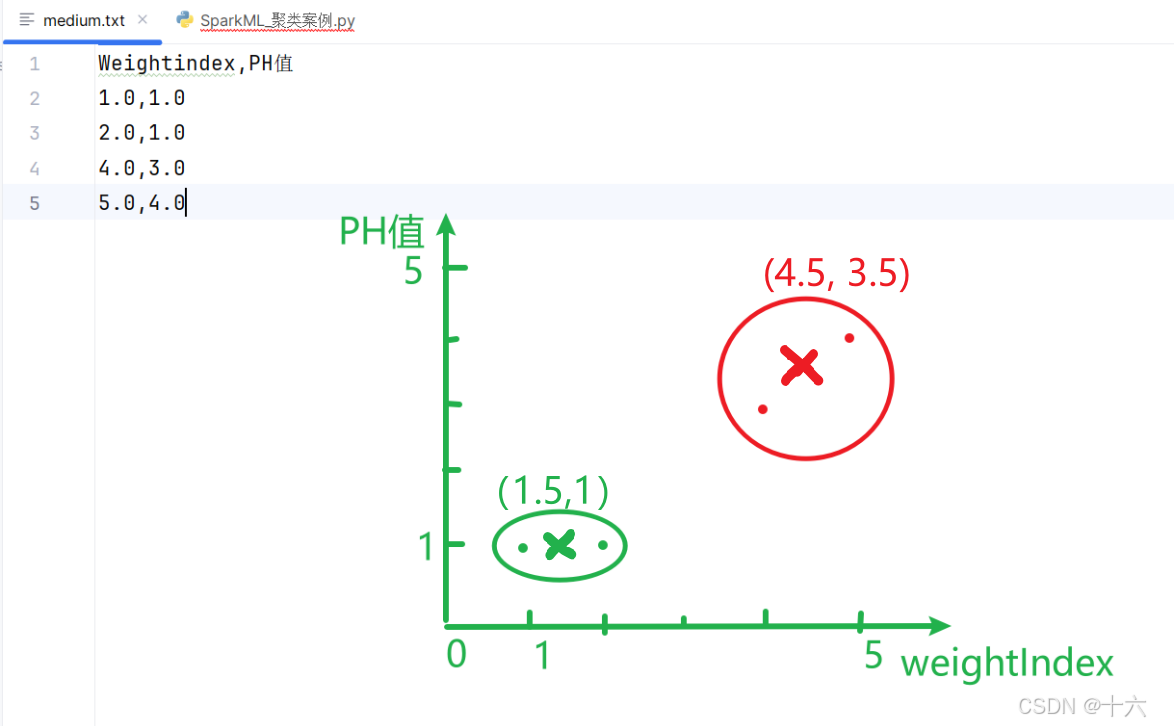
- 数据如下
Weightindex,PH值
1.0,1.0
2.0,1.0
4.0,3.0
5.0,4.0
- KMeans模型参数
featuresCol: str = ..., 特征列 features
predictionCol: str = ..., 模型输出的结果 prediction
k: int = ..., 聚成几类 默认k = 2
initMode: str = 默认kmeans||,即kmeans++ 随机选择初始的聚类中心的时候, 第一个点随机选, 从第二个点开始选离前面的距离最远的点
maxIter: int = ..., 最大迭代次数 作为聚类结束的条件
seed: int | None = ..., 随机数种子 固定有效果 具体取值是多少没有含义
distanceMeasure: str = ... -> None 距离计算方式 默认欧式距离
- SparkML代码
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.linalg import Vectors
from pyspark.sql import SparkSession
import os
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 创建SparkSession对象
spark = SparkSession.builder\
.appName("聚类案例")\
.master("local[*]")\
.getOrCreate()
# 数据输入
init_df = spark.read.csv(
path="file:///export/data/workspace/user_profile/test/SparkML_聚类案例/medium.txt",
schema="Weightindex float,PH float",
sep=",",
encoding="UTF-8",
header=True
)
# init_df.show()
# init_df.printSchema()
# 数据处理
# 特征预处理,将数据拼接为向量
assembler = VectorAssembler(
inputCols=["Weightindex","PH"],
outputCol="features"
)
# 对数据进行预处理
tranform_df = assembler.transform(init_df)
# tranform_df.show()
# tranform_df.printSchema()
# 模型训练
# 创建模型
kmeans = KMeans().setK(2).setSeed(1)
# 对特征预处理后的数据进行模型训练
model = kmeans.fit(tranform_df)
# 对新数据进行预测
predict_result = model.predict(Vectors.dense([5.0,3.0]))
print("新数据预测结果类型:",predict_result)
# 输出质心位置
centers_infos = model.clusterCenters()
for info in centers_infos:
print(info)
# 释放资源
spark.stop()

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)