零基础:DeepSeek大模型入门级基础知识必读
DeepSeek的火爆让人产生了一种它无所不能的幻觉,实际上真正能落地运用的又不是很多,这可能源于技术突破的乐观预期和资本对未来的提前布局。有人说“未来AI会代替人类”,AI会不会完全代替人类时间会给出答案,但未来不会使用AI注定会被时代所淘汰。作为职场人、程序开发人员,我们不能仅局限于在聊天页面上熟练对话,还需要对通用人工智能产品的一些基础知识做进一步学习。毕竟,AI智能时代机会无处不在。基础概
DeepSeek的火爆让人产生了一种它无所不能的幻觉,实际上真正能落地运用的又不是很多,这可能源于技术突破的乐观预期和资本对未来的提前布局。有人说“未来AI会代替人类”,AI会不会完全代替人类时间会给出答案,但未来不会使用AI注定会被时代所淘汰。
作为职场人、程序开发人员,我们不能仅局限于在聊天页面上熟练对话,还需要对通用人工智能产品的一些基础知识做进一步学习。毕竟,AI智能时代机会无处不在。
基础概念
学习AI,我们要熟悉一些常听到的基础概念:
-
AI(人工智能):涵盖所有让机器模仿人类智能的技术总称,让机器像人一样聪明(比如手机里的语音助手);
-
机器学习:AI的子领域,让机器从数据中学习规律,教机器从经验中学习(比如让电脑看100张猫图,以后能认出猫);
-
深度学习:机器学习的分支,用复杂神经网络处理高维数据(如图像、语言),用“超级复杂数学公式”让机器学得更准(比如人脸识别背后的技术);
-
LLM:深度学习的延伸,专注语言任务的超大规模模型,具有读、写、推理能力;
-
生成式AI:能“创作内容”的AI技术总称(如生成文本、图片、视频),LLM是生成式AI的核心技术;
-
AIGC:生成式AI的实际应用(比如用AI生成短视频脚本);
-
AGI(通用人工智能):像人一样啥都会的“全能AI”(科幻电影里的机器人,还没实现);
-
多模态:让AI同时处理多种信息(比如看图说话、听歌写诗)。
用一张简图表示它们之间的关系。

关于LLM
LLM是Large Language Model英文缩写,直译过来就是大语言模型。它是一种通过海量文本数据训练的人工智能,这些数据来自于书籍、网页、系统数据等,实现模仿人类理解和生成语言。其实,早在2018年大语言模型就出现了,为大众所熟知是2022年11月30日OpenAI推出了一款人工智能聊天产品ChatGPT,它可以根据使用者输入的提示词生成类似人类的文本应答。同样,DeepSeek也是大语言模型中具有代表性的一个。
LLM本质是概率预测,即便是现在火爆的DeepSeek-R1也继承自概率预测的特性。有概率就有可能出错,例如它可能会生成看似合理但事实上错误的内容,比如给出的参考文献并不存在,这就是大家常说的“AI幻觉”。它的工作原理类似我们玩的填词游戏,根据已有的信息猜下一个词是什么,以及这些词出现的概率,但它又不是固定的按概率高低来选词,而是选择某种程度上“匹配”的词,不断重复这个过程。
当下,LLM可用于效率辅助,并不能过度依赖或者完全信任使用,可以把它当成给你打工的员工,员工的输出成果要做核验,要保持独立思考。
关于DeepSeek
DeepSeek是一款由国内人工智能公司深度求索开发的大型语言模型,在写作、编程、翻译和解决复杂问题方面可以辅助人类处理任务。
2025年1月20日正式发布DeepSeek-R1模型,并同步开源模型权重。在此之前国内也有很多优秀的大模型产品,为什么偏偏DeepSeek在2025年春节期间火爆全网,成为苹果应用商店美国区和中国区免费应用榜单的第一名。
首当其冲的就是省钱,其极低的训练成本,例如DeepSeek-V3成本600万美元,远低于GPT-4的6300万美元,用相当于同行1/10的费用就训练出对标国际顶级AI模型的能力,相当于用“经济舱价格”造出“头等舱性能”;其API接口调用成本仅为ChatGPT的1%-5%,这对于有应用层开发的个人和企业来说非常划算;不挑芯片,DeepSeek通过算法优化,支持国产芯片和其他品牌GPU,甚至能让普通显卡跑出高性能。
其次,直接开源模型代码和技术细节,相当于把“秘方”免费分享,全球开发者都能自由修改、优化,甚至用几十美元就能复现类似效果,吸引了大批技术爱好者参与,开源之后玩的就是生态,大家一起玩。拿智能手机操作系统来类比,Open AI走的苹果macOS路线,DeepSeek走的是谷歌安卓路线。
DeepSeek这一波免费开源算是把国内外大模型厂家逼到墙角了,国内百度文心一言在2月13日宣布4月1日0时起,开启全面免费,可以体验到最新、最全的模型能力和产品功能。同日,OpenAI也宣布免费版ChatGPT将在标准智能设置下无限制使用GPT-5进行对话。2月20日,马斯克旗下人工智能公司xAI宣布,最新发布的Grok 3模型现已开放免费使用。
此外,DeepSeek-R1深度思考首次实现OpenAI o1级别的深度推理能力,实现了复杂问题的分步推理能力,例如数学计算、逻辑推导等,被认为是国产AI从“生成”到“理解”的关键突破。它是世界上第一个开源的推理模型,要知道当时拥有深度推理能力的大模型产品还只有OpenAI ChatGPT一家,并且使用上有次数限制,要不就升级付费pro版本。
所以,一个省钱、性能强、开源免费、大家一起玩,一个昂贵(使用、训练)、能力确实强、闭源、限制访问的产品,你会选择哪个,火出圈是必然的。
关于DeepSeek的使用,简单问题不需要开启深度思考(R1),例如询问三角函数公式,这样会更快,此时会使用DeepSeek-V3模型;非时效性问题不需要联网搜索,例如唐朝建国多少年;深度思考(R1)的使用场景包括需要深度推理、复杂逻辑分析、专业领域的问题,例如数学题、代码调试、学术研究框架、伦理分析等;联网搜索适用于需要实时数据的情况,如股票行情、新闻事件、最新政策等。深度思考(R1)+联网搜索混合使用时,会先联网获取数据,再用R1分析,或者在需要验证信息时交叉使用。
DeepSeek-R1 671B中的"671B"表示该模型的参数规模为6710亿(671B,即671Billion),属于超大规模语言模型。模型参数是AI训练过程中调整的变量,参数越多,模型通常具备更强的学习能力和复杂任务处理能力。
关于Token
作为程序开发人员,容易误认为Token是用于身份识别的字符串。在大模型中Token是模型用来表示自然语言文本的的最小单位,可以是一个词、一个数字、一个标点符号、甚至单个字符等。通常1个中文词语、1个英文单词、1个数字或1个符号计为1个token。Token是文本与模型之间的“翻译器”,将人类自然语言转换为模型能处理的数字序列。
上下文窗口大小
上下文窗口大小是大模型可以处理Token数量,是大型语言模型处理文本时的“记忆容量”,决定了模型能同时考虑多少Token(文字片段)来生成连贯的回复。上下文越大,能处理的Token越多,大模型对信息的理解就越充分,生成的内容就越接近我们需要的结果。就像你读书时,需要翻回前几页才能理解当前内容,上下文窗口就是模型能“往回翻”的最大页数。
Prompt
Prompt(提示词)是用户与大模型交互时输入的指令或问题,相当于告诉AI“我需要你做什么”。使用大模型最直接的方式就是输入一段信息,让大模型根据输入内容生成目标内容,我们输入的内容就是提示词。它决定了AI的思考方向和输出质量,可以理解为给AI的“任务指南”,它的核心是让AI理解你的真实需求。
很多人会感觉大模型一点不好用,无法理解提问人的真实诉求、提供不了有效回复。实际上并不一定是大模型不好用,而是你提供的Prompt不够准确。就好像你到饭店吃饭,告诉服务员“给我上菜”,服务员会一脸懵“上菜?上什么菜?是要粤菜,还是川菜?是青菜豆腐,还是龙虾鲍鱼?”。所以,你需要提供足够多的信息。和大模型交互,你把它当成一位智者,告诉大模型他是谁(设置角色)、任务背景(任务关联的人和事等)、任务目标(要他完成什么)、输出要求(形式、字数、风格等),他也好综合考虑并推理给出你可能最想要的答案。
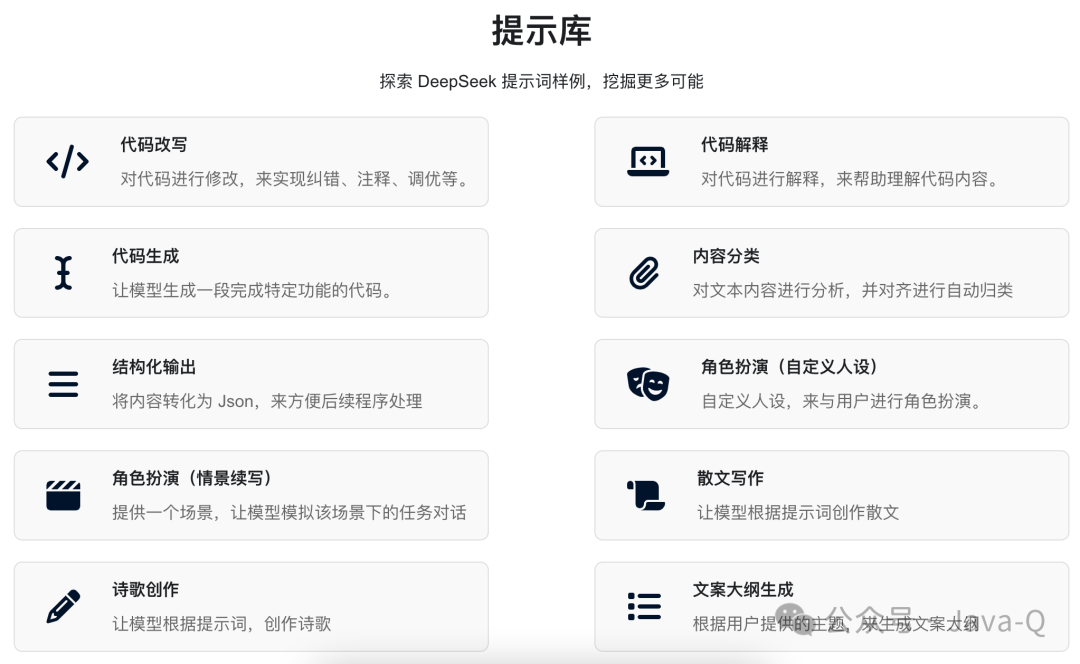
学会提问也是一门技术,DeepSeek考虑到这个问题,官网也提供了一份提示词样例(https://api-docs.deepseek.com/zh-cn/prompt-library/),感兴趣的可以看看。
Temperature
上面说到LLM在做概率预测时,并不会选择概率最高的词,你有没有想过如果每次都选择概率最高的词,生成的回复会不会很固定,就会出现大量同样的回答,这样就失去了“创造性”思维。这就好比,你向别人提问,每次都是固定的回答,你会不会觉得很无趣,那如果每次都换一种思维方式,会不会让你觉得“这个人蛮有意思”。这就是大模型的“创造力”,它的回答是随机的,也就是说同样的提问,回答可能不同。
Temperature参数,通过改变其取值,控制生成结果的随机性,产生不确定的“创造性”。对于DeepSeek来说,取值介于0和2之间,更高的值,如0.8会使输出更随机,随机意味着存在天马行空的风险;而更低的值,如0.2会使其更加集中和确定。这个参数可以在DeepSeek对话API请求参数中调整设置。
AI幻觉
AI幻觉是指大语言模型生成看似合理但实际错误或虚构内容的现象,通俗来说就是AI“一本正经地胡说八道”,它不会说“不知道”。AI幻觉的产生源自训练数据的问题、训练过程的缺陷、概率预测机制、上下文遗忘等,有时候普通人很难辨别,使用大模型要保持怀疑态度。
当然,行业内也有解决方案。比如,多模型交叉验证(用魔法打败魔法)、提供准确基础知识作为样本、通过不同可信度分为自动信任和人工确认等。
完全消除AI幻觉比较困难,但长期来看是趋势。
蒸馏技术
蒸馏技术在大模型中相当于“老师教学生”的过程,本质是让一个更小的模型(学生)学习一个更大、更强的模型(老师)的知识,从而在减少计算资源消耗的同时,尽量保持模型的性能,但体积更小、计算更快。
拿“浓缩果汁”来类比,原始大模型就像是一大桶新鲜果汁,里面有很多复杂的风味,但体积大、存储和运输成本高;蒸馏后的小模型就像是浓缩果汁,虽然体积变小了,但尽量保留了原有的风味和营养,便于存储和使用;蒸馏过程就是把果汁里的“水分”去掉,提炼核心的味道和营养,让小模型学到大模型的精华部分。
简单来说,蒸馏技术就是让“大师级”AI把知识“浓缩”后,教给“小AI”,让它在更低成本下也能做出类似的决策。例如DeepSeek-R1-Distill-Qwen-32B是基于DeepSeek-R1蒸馏而来的模型,在Qwen2.5-32B的基础上使用DeepSeek-R1生成的样本进行微调,保持了强大的推理能力。
RAG
RAG即检索增强生成,它是一种将“查找资料”与“生成答案”结合起来的技术。想象你在回答一个问题时,先去翻书、查互联网,然后把找到的信息整理后回答别人。RAG就是让AI在生成回答前,先检索相关的外部信息,再基于这些信息生成更准确、更新的回答。通过这种方式,RAG技术既发挥了大模型强大的生成能力,又借助检索模块补充最新和更具体的信息,让生成的答案更准确、实用。
Agent
在AI领域,Agent指的是一个具有自主“思考”和“行动”能力的智能体。也就是说,Agent不仅能“理解”信息,还能根据环境自主决策并执行任务。可以把Agent想象成一个非常聪明的私人助理,它不仅能给你建议,还可以主动帮你办事。例如,你问它“今天我需要带伞吗?”,它不仅会回答,还可能自动查好天气信息,再给出提醒。如果说大模型是“智慧的大脑”,那么Agent就是将这份智慧转化为实际行动的“执行者”,能操作工具、调用外部资源,甚至完成一系列复杂任务。
目前,字节跳动推出的扣子(Coze)就支持大模型智能体开发,感兴趣的可以试试。
Ollama
Ollama是一个开源的工具,专门用来在本地电脑上轻松运行和管理大型语言模型,它提供了简单的命令行接口和图形界面,只需几条命令就能下载、运行,甚至定制自己的AI模型,它把原本复杂的模型部署过程简化,让不太懂技术的人员也可以轻松部署大模型。
DeepSeek火爆全网之后,通过Ollama实现私有DeepSeek-R1-671B大模型部署不再是难事。如果你担心数据风险、隐私泄漏问题,可以尝试部署自己的私有大模型。
Hugging Face
Hugging Face是一个专注于人工智能和机器学习领域的开源社区和平台,里面收藏了各种预训练好的智能“工具”(也就是模型),比如翻译、聊天、问答、图像识别等。你可以使用这些工具,用于解决实际问题,而无需从头开始构建一个模型。
最后附上两幅图,据说众多大模型都在这道题上栽了跟头,无一幸免。
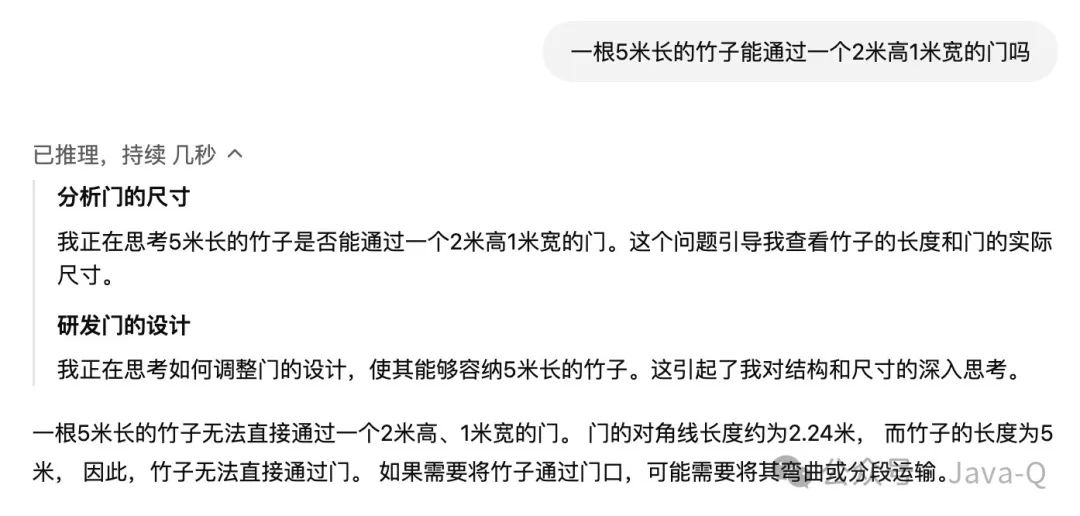
上图 ChatGPT o3-mini作答

上图 DeepSeek-R1作答

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)