百度EasyDL:零代码AI开发全指南—— 从入门到行业实战深度解析
EasyDL平台旨在为企业和开发者提供一个无需深厚算法背景的AI开发解决方案。零算法基础:用户无需掌握复杂的CNN、RNN等深度学习原理,通过图形化界面即可完成从数据准备到模型部署的全流程操作。高效开发:从数据标注、模型训练到上线部署,用户可以在5-10分钟内快速实现AI应用。这样一来,即便是初学者也能通过简单操作完成较为复杂的任务。灵活部署:平台支持多种部署方式——公有云API、设备端SDK、私
在人工智能迅速普及的今天,企业和开发者迫切需要一个降低门槛、加速落地的AI开发平台。百度推出的EasyDL正是为了满足这一需求而生。作为基于飞桨深度学习框架的零代码模型定制平台,EasyDL不仅帮助用户在几分钟内上手,还覆盖了工业、零售、医疗、安防等50多个行业,累计服务超过80万开发者,模型调用量突破千亿次。接下来,我们将从多个维度解析EasyDL的原理、功能及行业应用,帮助读者全面认识这一“平民化工具”。
一、EasyDL简介
EasyDL平台旨在为企业和开发者提供一个无需深厚算法背景的AI开发解决方案。平台核心优势主要体现在以下几个方面:
- 零算法基础:用户无需掌握复杂的CNN、RNN等深度学习原理,通过图形化界面即可完成从数据准备到模型部署的全流程操作。
- 高效开发:从数据标注、模型训练到上线部署,用户可以在5-10分钟内快速实现AI应用。这样一来,即便是初学者也能通过简单操作完成较为复杂的任务。
- 灵活部署:平台支持多种部署方式——公有云API、设备端SDK、私有化服务器以及软硬件一体化方案,满足不同场景下对延迟、成本和硬件环境的多重要求。
界面展示:
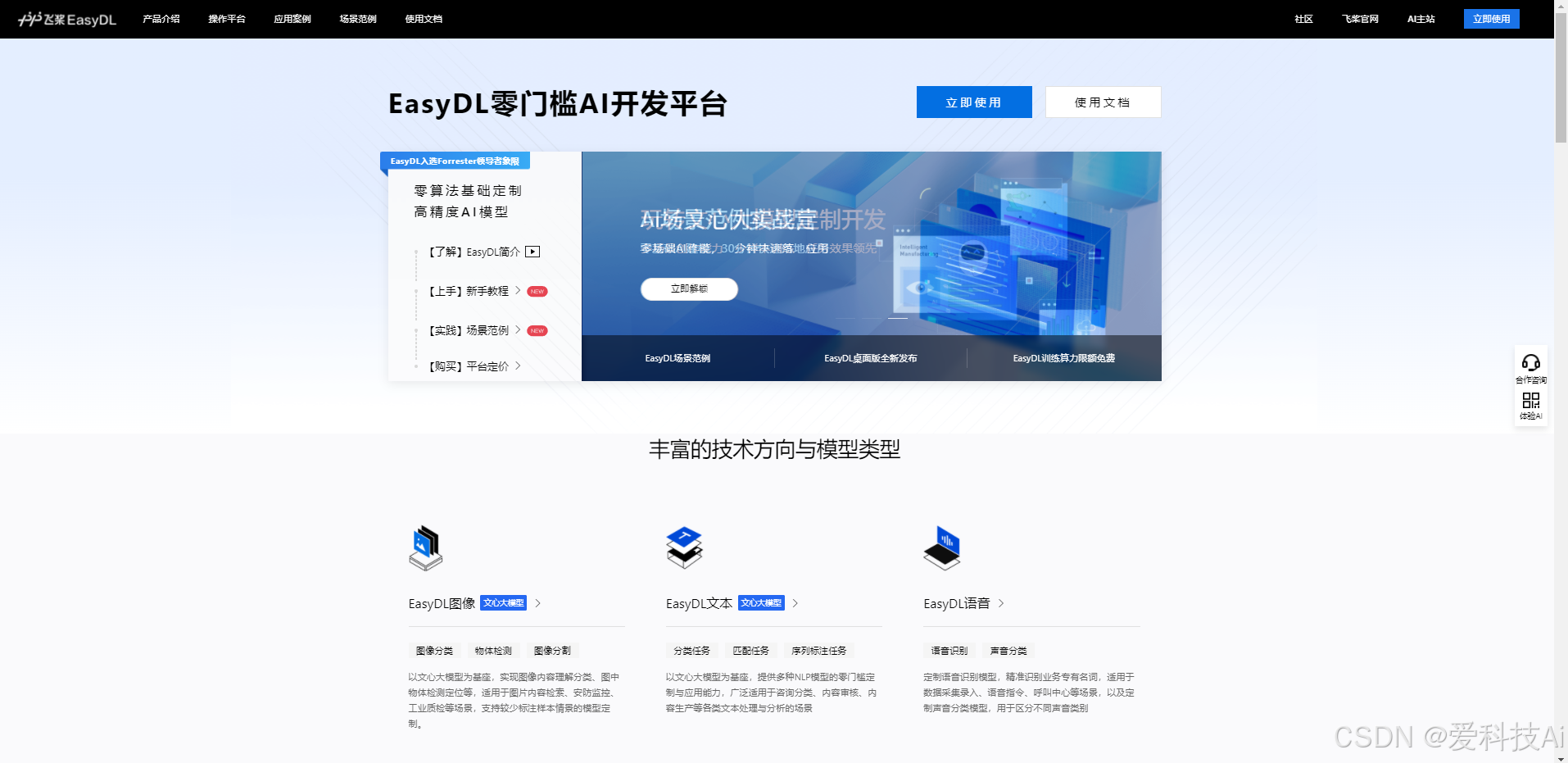
百度EasyDL平台通过直观的界面设计,将复杂的AI开发流程简化为“选择–配置–验证”的线性操作。用户可在模型创建与场景选择界面中,根据业务需求快速选定图像分类、物体检测等多种模型类型,并通过预设的流程图了解数据准备、模型训练及部署的全流程。
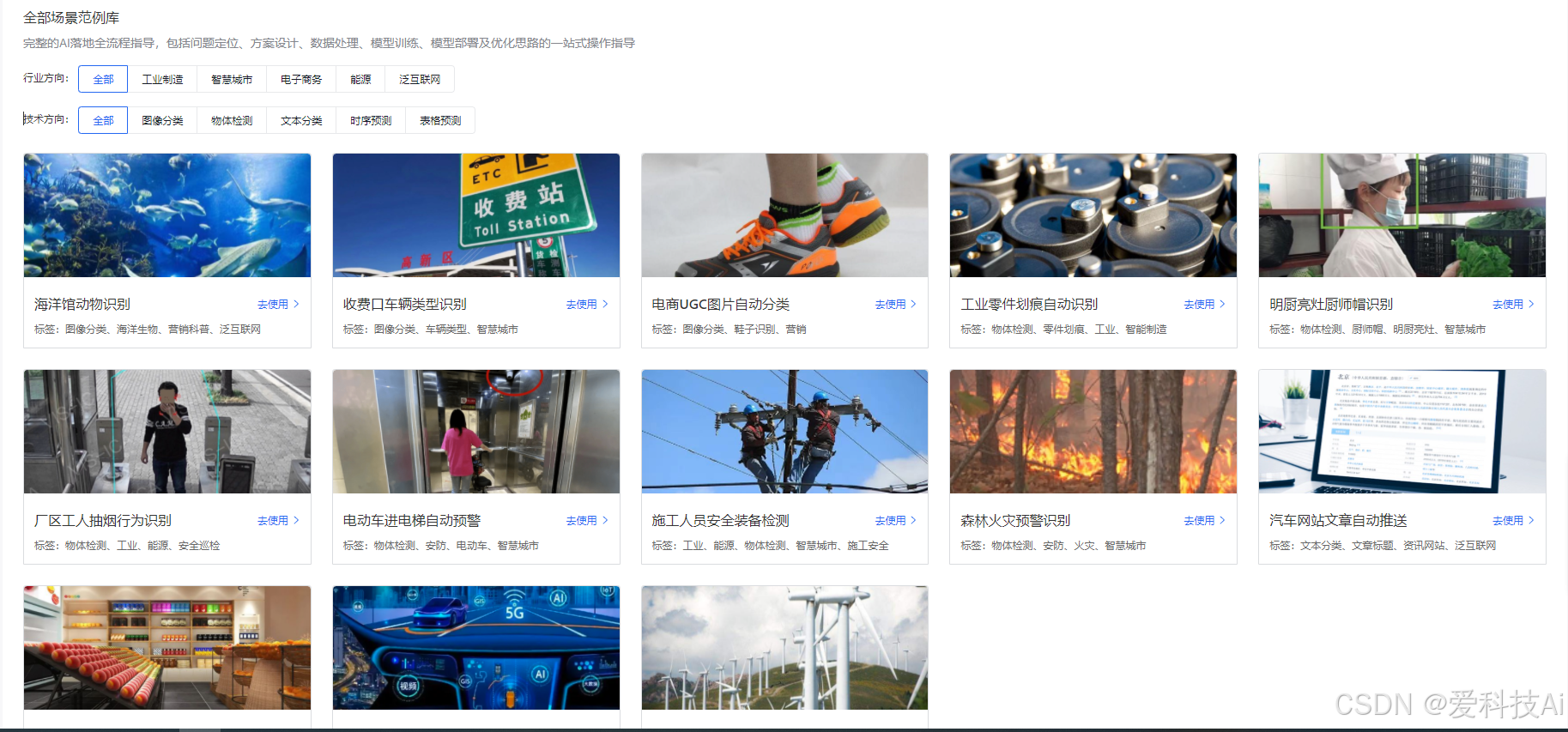
数据管理界面支持多格式数据上传、智能预处理和多人协作标注,同时提供数据增强配置,极大提高了标注效率和数据质量。训练配置界面则分为基础与高级两部分,用户既可选择自动化优化模式,也能根据需要手动调整训练参数,并通过实时监控了解训练进程。
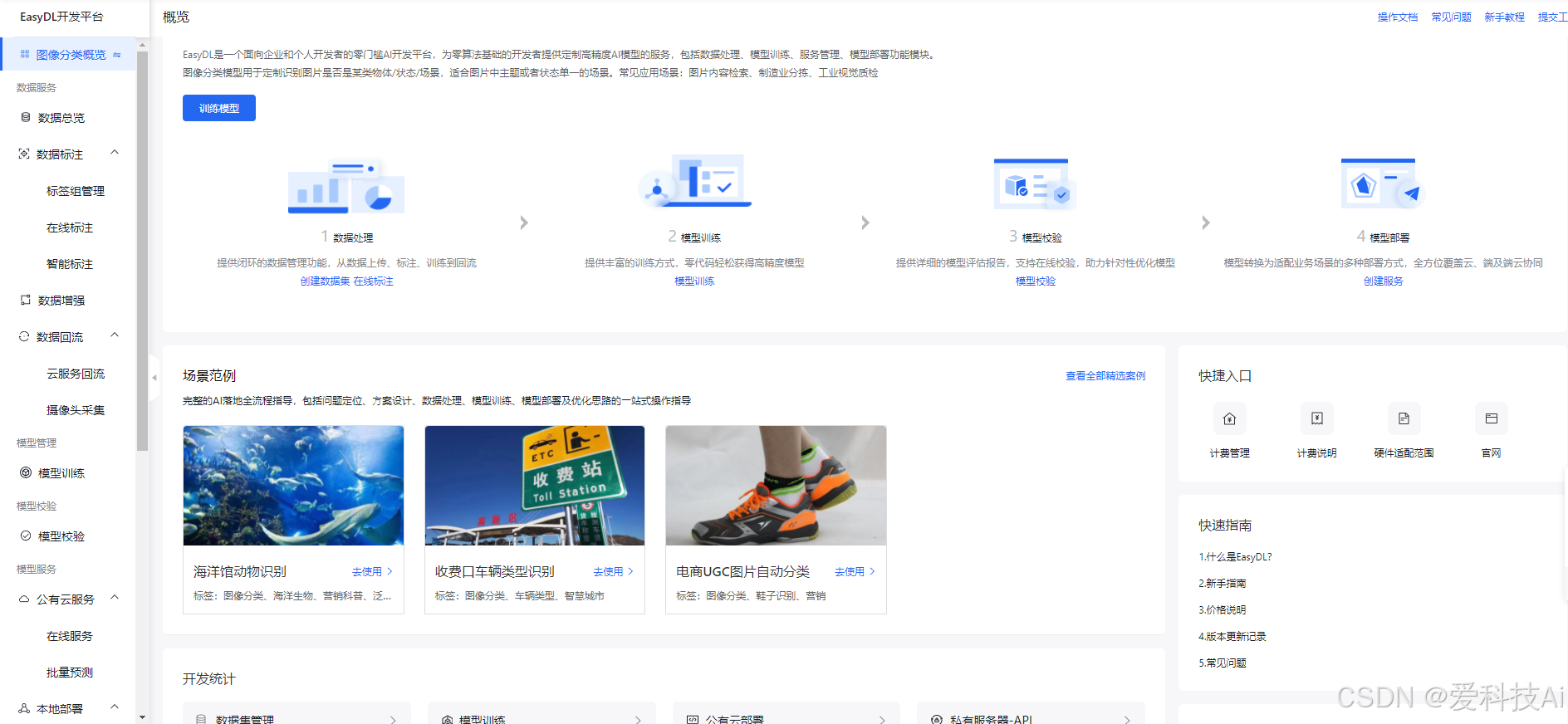
模型校验与评估界面以交互式测试工具和详尽的评估报告帮助用户直观理解模型表现;而部署方案选择界面则根据不同业务场景提供公有云、边缘设备和私有化部署等多种选项,确保模型应用高效、安全。整体上,平台的设计理念贯彻“最小认知负荷”,使AI开发变得更加民主化和高效。
二、技术原理
2.1 底层架构:飞桨、AutoML与迁移学习
EasyDL建立在百度自研的飞桨(PaddlePaddle)深度学习框架之上。飞桨作为国内领先的AI框架,具备分布式训练、自动优化等先进特性,能够高效支持大规模数据训练任务。平台同时引入AutoML自动化技术,通过智能搜索算法(如PBT)自动优化数据增强策略和超参数,进一步提升模型的泛化能力。此外,利用迁移学习技术,平台借助预训练的ERNIE大模型,在仅有小样本数据的情况下也能快速调整出高精度模型。
2.2 性能优化“黑科技”
- 数据增强策略:平台支持手动配置旋转、裁剪等常见增强手段,同时内置PBA算法进行自动搜索,在ImageNet数据集上取得了高达18.13%的精度提升效果。
- 模型压缩:通过量化技术,平台可以将FP32模型压缩至INT8格式,使模型体积缩减75%,且精度损失控制在1%以内。这对资源受限的边缘设备尤为关键。
- 硬件适配引擎:为满足不同设备的需求,EasyDL具备自动转换模型格式的能力,支持NVIDIA Jetson、华为昇腾等20余种边缘设备,确保模型部署时的高效运行。
三、功能详解:四步打造企业级AI模型
EasyDL将整个模型开发过程划分为数据准备、模型训练、验证优化以及部署四大阶段,每个阶段均提供了一站式解决方案:
3.1 数据准备与标注
- 数据要求:对于单分类任务,建议至少准备20张图片(推荐100张以上),支持PNG、JPG等常见格式,文件大小保持在4MB以内。
- 智能标注工具:平台提供了智能标注功能,可在预标注的基础上快速人工校正,据统计在工业零件图像的标注上,能提升70%的效率。
- 团队协作:支持多人在线协作,团队成员可分工标注,同时平台自动生成质检报告,确保标注数据的一致性和准确性。
3.2 模型训练配置
在后台,用户无需编写代码,EasyDL自动调用飞桨框架的标准模型。例如,下面的Python代码展示了使用ResNet50进行迁移学习的示例(实际操作无需用户编写代码):
# 后台实际执行的飞桨代码示例
model = paddle.vision.models.ResNet50(pretrained=True)
model = paddle.Model(model)
model.prepare(optimizer=paddle.optimizer.Adam(),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
model.fit(train_data=DataLoader(dataset), epochs=50, batch_size=32)
3.3 模型验证与优化
- 在线校验:用户可上传测试图片实时查看模型识别效果,如猫狗分类置信度高达99.99%。
- 错误样本迭代:对于识别错误的数据,平台支持自动收集并加入到训练集,经过再训练后,整体精度可提升5%-15%。
3.4 部署方案选型
针对不同应用场景,平台提供了多种部署方案:
| 部署方式 | 延迟 | 成本(月) | 适用场景 |
|---|---|---|---|
| 公有云API | 200-500ms | ¥0.1/次 | 电商商品识别(QPS<100) |
| 边缘设备SDK | 10-50ms | 硬件¥2999起 | 工厂实时质检 |
| 私有化服务器 | 50-100ms | ¥2万+ | 医院PACS系统集成 |
这样多样化的部署方案确保了从低延迟实时应用到大规模离线任务的全面覆盖。
四、实战案例:工业缺陷检测全流程解析
以某PCB电路板厂商为例,企业原本依赖人工质检,漏检率高达15%。通过引入EasyDL,项目实施步骤如下:
4.1 项目背景
- 检测需求:针对电路板10类常见缺陷(如短路、虚焊等)进行识别。
- 痛点:人工检测存在较高的漏检率及检测效率低下问题。
4.2 实施步骤
- 数据采集:利用工业相机拍摄2000张高清图片,5人团队在3天内完成初步标注。
- 模型训练:启用AutoML自动增强(如旋转±15°、亮度调整),4×V100显卡训练2小时,最终模型在mAP上达到92.7%。
- 边缘部署:采用华为Atlas 500设备对接产线摄像头,实现单张推理时间仅28ms,实时响应满足工业级需求。
4.3 经济效益
- 成本节约:年节省人力成本约80万元。
- 效率提升:检测速度提升40倍,漏检率从15%降至1.2%。
这一案例不仅展示了EasyDL在工业领域的强大应用,也为其他行业提供了宝贵的经验借鉴。
五、未来展望:EasyDL的持续进化
百度EasyDL并未止步于现有成果,其未来发展方向充满前景:
5.1 技术趋势
- 多模态融合:未来将整合图像、文本和语音数据,实现智能客服等更复杂场景的联合模型。
- 自监督学习:计划在2024年推出无标注训练功能,进一步降低对大规模标注数据的依赖。
- 低代码开发:支持Drag & Drop的自定义网络结构搭建,让用户在无需编码的前提下构建出专属于自己的模型(如自定义ResNet模块)。
5.2 行业深化
- 医疗领域:病理切片分析模块正在协和医院试点,为精准医疗提供有力支持。
- 农业应用:在新疆棉田中试点的病虫害识别模型,准确率已达到89%,大大提升农业生产效率。
六、开发者建议:如何高效利用EasyDL避开常见“坑”
6.1 数据准备阶段
- 分布一致性:确保训练集和验证集数据环境一致,避免因白天与夜间拍摄等环境差异引发模型偏差。
- 标注规范:尤其在物体检测任务中,建议标注框预留2-5像素的空隙,以便后续模型能够更好地拟合真实目标边界。
6.2 模型调优技巧
- 动态学习率:当验证集准确率出现波动时,建议启用自适应学习率调整,帮助模型稳定收敛。
- 模型蒸馏:通过将大模型(如ResNet101)的知识迁移至轻量级模型(如MobileNetV3),可在保持高精度的同时大幅降低模型体积,便于边缘设备部署。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)