基于 Transformer 的模型(BERT、GPT)深度解析
Transformer架构最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。与传统的循环神经网络(RNN)和长短期记忆(LSTM)网络不同,Transformer完全摒弃了序列化的计算方式,采用了全局自注意力机制(Self-Attention)来处理序列数据。自注意力机制(Self-Attention):计算每个词与其它所有词之间的关系。前馈神
目录
基于 Transformer 的模型(BERT、GPT)深度解析
2. BERT:Bidirectional Encoder Representations from Transformers
3. GPT:Generative Pre-trained Transformer
基于Transformer架构的模型已经在自然语言处理(NLP)领域掀起了革命性的变化。模型如BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)不仅在各种NLP任务中表现卓越,还为更复杂的语言理解和生成提供了新的解决方案。今天,我们将深入探讨基于Transformer架构的模型,特别是BERT和GPT,并通过TensorFlow实现它们的简化版本。
1. Transformer架构简介
1.1 Transformer的起源
Transformer架构最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。与传统的循环神经网络(RNN)和长短期记忆(LSTM)网络不同,Transformer完全摒弃了序列化的计算方式,采用了全局自注意力机制(Self-Attention)来处理序列数据。
Transformer的核心组件包括:
- 自注意力机制(Self-Attention):计算每个词与其它所有词之间的关系。
- 前馈神经网络(Feed-Forward Network):对每个位置的表示进行非线性变换。
- 多头注意力机制(Multi-Head Attention):并行计算多个注意力子空间,增强模型的学习能力。
- 位置编码(Positional Encoding):由于Transformer不具备处理序列顺序的能力,位置编码用于为每个输入位置添加位置信息。
Transformer的优势在于其并行计算能力,这使得它能够更高效地处理长文本。
1.2 Transformer架构的结构图
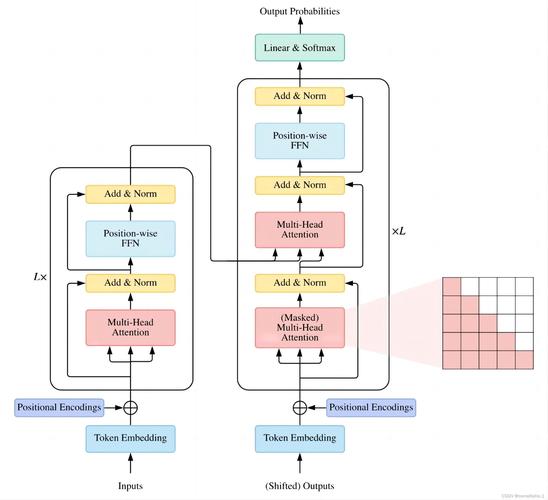
1.3 TensorFlow中的Transformer实现
TensorFlow提供了高效的实现来构建Transformer模型。下面是一个简化版的Transformer编码器的实现:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, LayerNormalization, Dropout
from tensorflow.keras.models import Model
# 自注意力机制
def attention(query, key, value):
matmul_qk = tf.matmul(query, key, transpose_b=True)
dk = tf.cast(tf.shape(key)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, value)
return output
# Transformer编码器层
def transformer_encoder(inputs, head_size, num_heads, ff_size, dropout=0.1):
# 多头自注意力层
attention_output = attention(inputs, inputs, inputs)
attention_output = Dropout(dropout)(attention_output)
attention_output = LayerNormalization(epsilon=1e-6)(attention_output + inputs)
# 前馈神经网络层
ff_output = Dense(ff_size, activation='relu')(attention_output)
ff_output = Dropout(dropout)(ff_output)
ff_output = Dense(head_size)(ff_output)
ff_output = LayerNormalization(epsilon=1e-6)(ff_output + attention_output)
return ff_output
# 输入和模型
inputs = Input(shape=(None, 128)) # 输入维度(batch_size, sequence_length, embedding_dim)
x = transformer_encoder(inputs, 128, 8, 512)
model = Model(inputs, x)
model.summary()
2. BERT:Bidirectional Encoder Representations from Transformers
2.1 BERT的核心思想
BERT是由Google AI提出的预训练语言表示模型。与传统的语言模型不同,BERT通过双向(Bidirectional)自注意力机制来处理文本,即它不仅仅看当前词的上下文,还能同时关注左侧和右侧的上下文,从而更好地理解句子含义。
BERT的关键创新之一是Masked Language Model (MLM)。BERT在训练过程中会随机“掩盖”部分词,并通过上下文来预测这些掩盖的词。这种方法允许BERT捕捉到更丰富的上下文信息,进而提升其理解能力。
2.2 BERT的训练和应用
BERT的预训练包含两个阶段:
- Masked Language Model (MLM):将部分输入词随机掩盖,通过上下文预测这些掩盖的词。
- Next Sentence Prediction (NSP):给定两个句子,判断第二个句子是否为第一个句子的下文。
在这些预训练完成后,BERT可以通过fine-tuning技术,针对特定任务进行微调。
2.3 TensorFlow实现BERT
在TensorFlow中,我们可以利用transformers库来简化BERT模型的实现。以下是加载和使用BERT模型的示例代码:
from transformers import TFBertForSequenceClassification, BertTokenizer
import tensorflow as tf
# 加载预训练BERT模型和Tokenizer
model_name = 'bert-base-uncased'
model = TFBertForSequenceClassification.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
# 编码输入文本
inputs = tokenizer("Hello, how are you?", return_tensors="tf", padding=True, truncation=True)
# 进行推理
outputs = model(inputs)
logits = outputs.logits
print(logits)
2.4 BERT的优势与局限性
| 特性 | BERT |
|---|---|
| 预训练任务 | Masked Language Model (MLM), Next Sentence Prediction (NSP) |
| 训练方式 | 无监督预训练 + 任务微调 |
| 双向上下文 | 是(通过Transformer的Encoder实现) |
| 适用场景 | 文本分类、命名实体识别、问答系统等 |
| 优点 | 捕捉到更丰富的上下文信息,提高理解能力 |
| 缺点 | 训练资源要求高,推理速度较慢 |
3. GPT:Generative Pre-trained Transformer
3.1 GPT的核心思想
GPT是由OpenAI提出的生成式预训练Transformer模型。与BERT的双向预训练不同,GPT采用的是单向(左到右)的自回归语言建模方式,即它通过左侧的上下文来预测下一个词。
GPT的预训练任务为Causal Language Modeling (CLM),即给定前面的词,预测下一个词。GPT模型本质上是一种自回归模型,适用于文本生成任务,如机器翻译、文本生成等。
3.2 GPT的训练和应用
GPT的训练过程采用自回归的方式。预训练阶段的目标是最大化每个词的条件概率,利用所有前面的词来预测当前词。然后,通过微调(fine-tuning)来适应特定任务,如文本生成或情感分析等。
3.3 TensorFlow实现GPT
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
# 加载预训练GPT-2模型和Tokenizer
model_name = 'gpt2'
model = TFGPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# 编码输入文本
inputs = tokenizer.encode("Once upon a time", return_tensors="tf")
# 进行文本生成
outputs = model.generate(inputs, max_length=50, num_return_sequences=1)
# 解码并输出生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
3.4 GPT的优势与局限性
| 特性 | GPT |
|---|---|
| 预训练任务 | Causal Language Modeling (CLM) |
| 训练方式 | 无监督预训练 + 任务微调 |
| 单向上下文 | 是(从左到右) |
| 适用场景 | 文本生成、机器翻译、对话系统等 |
| 优点 | 高效的文本生成能力,适用于对话生成 |
| 缺点 | 对于长文本生成能力较弱,缺乏全局上下文 |
4. BERT vs GPT
| 特性 | BERT | GPT |
|---|---|---|
| 预训练目标 | Masked Language Modeling (MLM) + Next Sentence Prediction (NSP) | Causal Language Modeling (CLM) |
| 上下文方向 | 双向(通过Encoder) | 单向(左到右,通过Decoder) |
| 适用任务 | 文本分类、问答、命名实体识别等 | 文本生成、对话系统、摘要等 |
| 优点 | 捕捉上下文的完整信息,理解能力强 | 高效的生成能力,适用于生成任务 |
| 缺点 | 生成任务较弱 | 只支持左到右的单向生成,推理较慢 |
5. 总结
基于Transformer架构的模型,如BERT和GPT,已经成为现代NLP领域的标杆。BERT通过双向上下文建模,提供了强大的文本理解能力,而GPT通过自回归模型,成为了生成任务中的佼佼者。TensorFlow和Hugging Face等库提供了简化的接口,使得我们可以快速加载和使用这些预训练模型,进一步推动了NLP技术的发展。
无论是用于文本分类、问答系统,还是文本生成,Transformer架构的模型都展现出了强大的能力。在实际应用中,选择合适的模型要根据任务的性质、数据的特点以及计算资源来决定。希望这篇文章能帮助你更好地理解Transformer架构,掌握如何利用BERT和GPT在NLP任务中取得优异的成果。
推荐阅读:
使用 TensorFlow 实现 CNN(卷积神经网络)-CSDN博客

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 30
30 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)