带你从入门到精通——自然语言处理(十三. 模型压缩)
建议先阅读我自然语言处理专栏的前置博客,掌握一定的自然语言处理前置知识后再阅读本文,链接如下:
目录
十三. 模型压缩
13.1 模型量化
13.1.1 模型量化概述
模型量化是指将深度学习模型中使用高精度浮点数(例如FP32、FP16)来表示的权重和激活值(模型中持续更新的输入通常被称为激活值)转换为低精度的整数(INT8、INT4)的过程,能够起到压缩模型、加速推理的作用。
目前主流的量化技术为训练后量化(Post-Training Quantization,PTQ),PTQ在模型完成训练后直接对权重和激活值进行低精度转换,无需重新训练或微调。
13.1.2 量化方式
在PTQ中有两种常用的量化方式:对称量化以及非对称量化,其中对称量化会将浮点数映射到有符号整数(例如量化为INT8,则范围为[-127,127])中,其中scale缩放因子的计算公式如下:
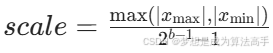
上式中b为量化后的比特位,例如量化为INT8,则b = 8,量化和反量化的公式如下:

![]()
上式中x为原始值,q为量化值,![]() 为反量化后的值。
为反量化后的值。
注意:量化是针对每层神经网络独立进行的,也就是说每层神经网络的scale都是独立计算的,有可能是不同的。
在非对称量化中会将浮点数映射到无符号整数(例如量化为UINT8,则范围为[0,255]),但在非对称量化中不仅需要计算缩放因子,还需要额外计算一个零点偏移量zero_point,具体计算公式如下:
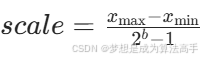
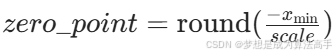
量化和反量化的计算公式如下:
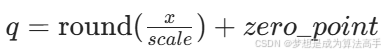
![]()
注意:在对称量化和非对称量化中,如果量化后的值超过了INT数值的表示范围,则需要对量化后的值x进行clip,即如果x大于最大值,则将其设为最大值,如果x小于最小值,则将其设为最小值。
对称量化的优点是计算简单,并且只需存储缩放因子,节省内存,但是对极端值比较敏感,会出现无法充分利用INT数值范围的情况,此外,通常需要数据服从以0为中心的对称分布,否则有较大的量化误差。
非对称分布的优点是量化的精度更高,误差更小,并且适用于非对称分布的数据,但是计算量较大,并且需要额外存储零点偏移量。
13.1.3 动态量化和静态量化
根据激活值量化时机的不同,PTQ又分为动态量化和静态量化:
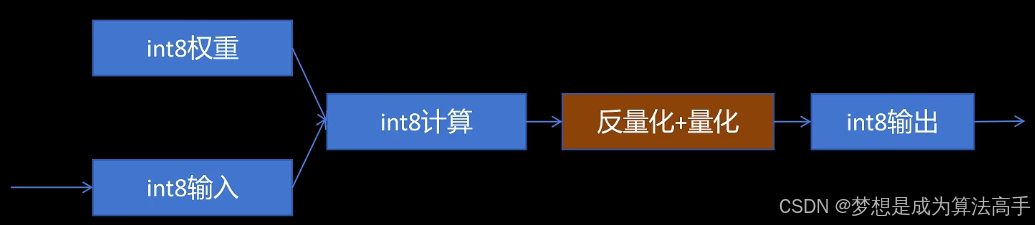
动态量化是指仅仅提前量化模型的权重,每层激活值的scale和zero_point在推理时动态计算,完成动态量化后模型的推理流程图如下:

在PyTorch中模型的动态量化的API为:torch.quantization.quantize_dynamic(),注意:在PyTorch中需要在CPU上进行量化。
静态量化是指提前量化模型的权重,并提前使用有代表性校准数据集输入模型进行推理,逐层统计激活值的数据范围,并根据校准数据计算对应层激活值的scale和zero_point,这个过程也被称为校准,完成静态量化后模型的推理流程图如下:
13.2 知识蒸馏
知识蒸馏(Knowledge Distillation)是2015年提出的一种将教师模型(通常是一个参数量较大的复杂模型)的知识转移给一个学生模型(通常是一个参数量较小的简单模型)的方法,能够提高学生模型的性能。
知识蒸馏也属于模型压缩技术的一种,通过迁移教师模型的知识到学生模型中,来起到压缩模型和加速推理(参数量较小的简单模型通常有着更快的推理速度)的作用。
其基本流程图如下:
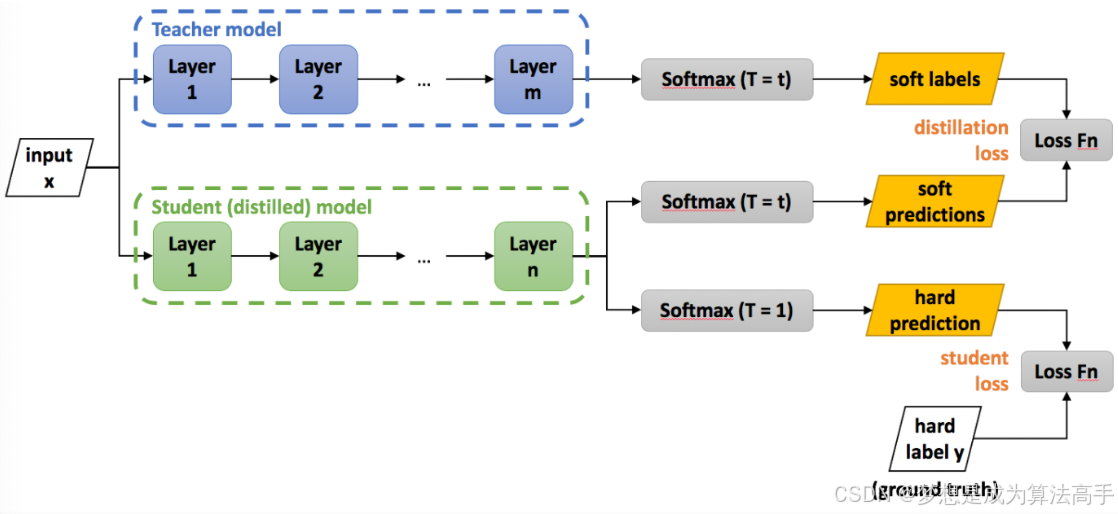
教师模型的输出经过softmax-T得到最终的概率分布,作为软标签,softmax-T的公式如下:
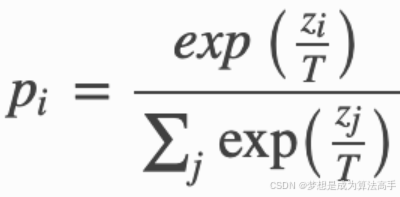
上式中的T被称为温度系数,当T = 1时softmax-T就退化为了softmax;当T趋近于0,softmax-T后的概率值中的最大值将趋近于1,而其他值将趋近于0,概率分布趋近于独热编码;当T趋近于无穷,概率分布趋近于均匀分布。
学生模型的输出经过softmax-T后得到对软标签的预测值,经过softmax后得到对硬标签的预测值(硬标签即为真实标签)。
在知识蒸馏中,对于软标签使用KL散度最为损失函数,对于硬标签使用交叉熵损失作为损失函数,因此最终学生模型的损失函数如下:
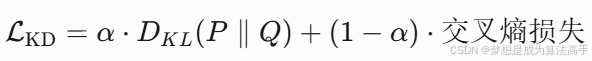
上式中![]() 表示KL散度(Kullback-Leibler Divergence),也称为相对熵(Relative Entropy),是一种用来衡量两个概率分布之间的差异的度量方式,KL散度的值越大,表明两个概率分布的差异性越大,此外,KL散度具有非负性,当且仅当P = Q时KL散度等于零,其计算公式如下:
表示KL散度(Kullback-Leibler Divergence),也称为相对熵(Relative Entropy),是一种用来衡量两个概率分布之间的差异的度量方式,KL散度的值越大,表明两个概率分布的差异性越大,此外,KL散度具有非负性,当且仅当P = Q时KL散度等于零,其计算公式如下:
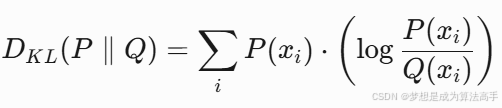
与交叉熵的关系如下:
![]()
13.3 模型剪枝
模型剪枝是指通过移除神经网络中冗余的参数或者结构,从而起到压缩模型和加速推理作用的一种技术。
剪枝可以分为结构化剪枝(Structured Pruning)和非结构化剪枝(Unstructured Pruning),结构化剪枝是指直接移除模型中的整个结构单元,例如移除冗余的神经元或者直接移除冗余的全连接层;非结构化剪枝是指移除模型权重矩阵中的单个权重参数,从而生成稀疏权重矩阵。
结构化剪枝通常使用L2剪枝来实现,该方式会移除神经网络中L2范数较小的结构单元,在PyTorch中的API为:torch.nn.utils.prune.ln_structured(n=2)。
非结构化剪枝通常使用L1剪枝来实现,该方式会移除神经网络中L1范数较小的权重参数,在PyTorch中的API为:torch.nn.utils.prune.l1_unstructured()。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)