大模型2025年3月报告分析2:智能体AI Agent
SuperCLUE通用榜单智能体。
大模型2025年3月报告分析2:智能体AI Agent
技术人生黄勇 2025年03月24日 19:55 北京
【智能体Agent深度分析介绍】
主要介绍各个模型在SuperCLUE通用榜单智能体Agent任务上的表现,包括对国内外模型的表现对比、九大任务场景的模型表现、推理模型与基础模型的的表现对比、当前模型在Agent能力上的不足。
【智能体Agent任务介绍】
主要考察在中文场景下基于可执行的环境,LLM作为代理,在单轮或多轮对话中调用工具完成任务的能力。
-
两大任务类型:包含单轮多步任务和多轮多步任务,调用一次函数为1步。其中,单轮多步任务57道,多轮多步任务47道。
-
评价方式:结合任务完成与否、系统状态比对的评估(0-1得分)
【智能体Agent任务特点】
1. 单轮、多轮对话:当前对话轮数覆盖1-6轮,解题步数覆盖2-14步。
2. 任务覆盖场景:本次智能体agent任务涉及即时消息、旅游出行、智能座舱、智能家居等九大任务场景。
3. 测评环境:可执行的测评环境、人类标注的标准答案(ground truth)作为评判标准,允许模型与环境进行交互以及反思改进。

【智能体Agent深度分析】
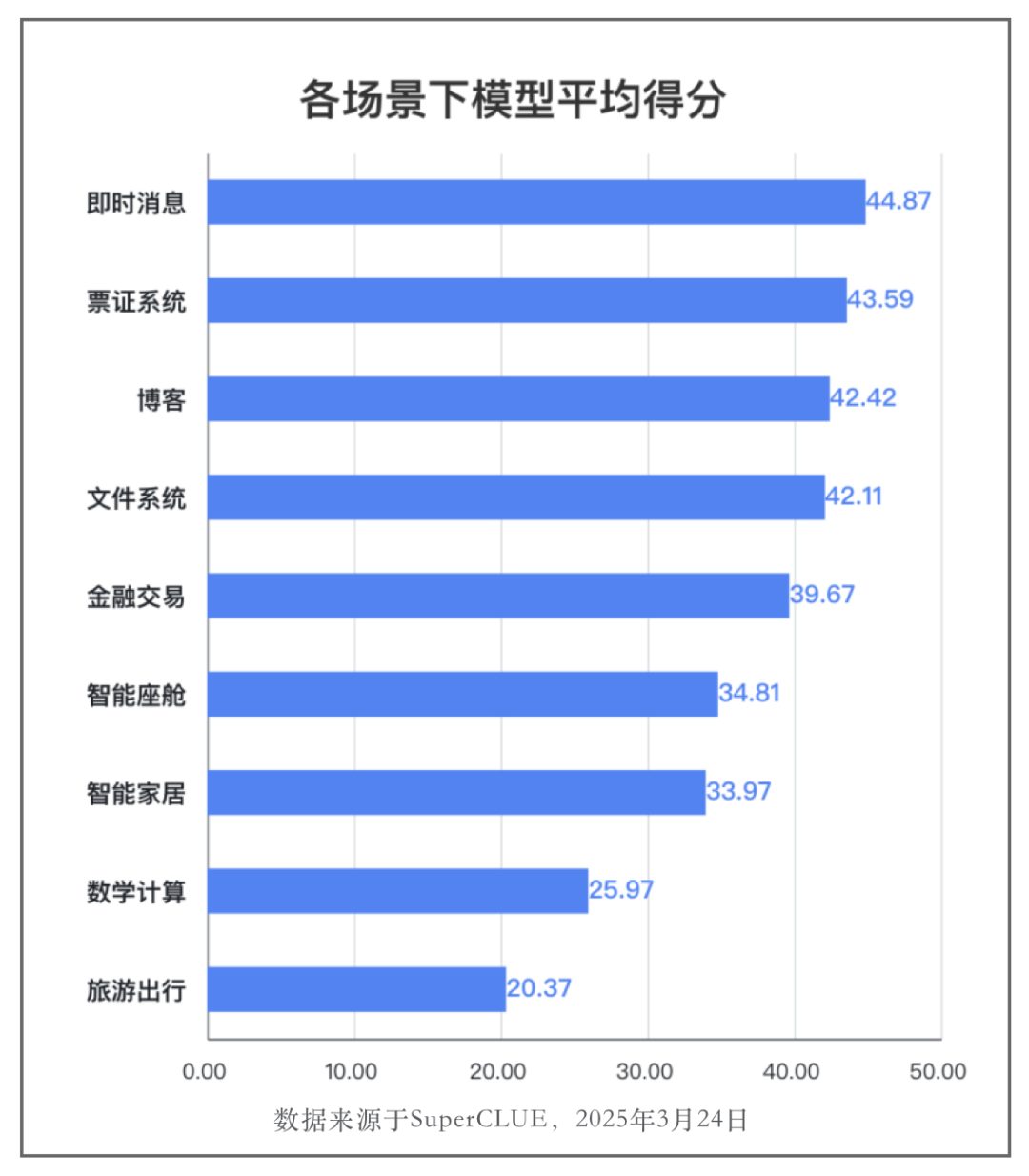
🔍九大场景应用的成熟度不同,旅游出行的应用成熟度最低
本次通用榜单智能体Agent任务涉及九大应用场景,其中即时消息、票证系统、博客、文件系统场景下的模型成熟度较高,模型平均得分分别为:44.87,43.59,42.42和42.11分,旅游出行场景模型平均分最低:20.37分(旅游出行场景下参数较多,难度较高)。当前模型在各个应用场景下仍然有较大的进步空间。
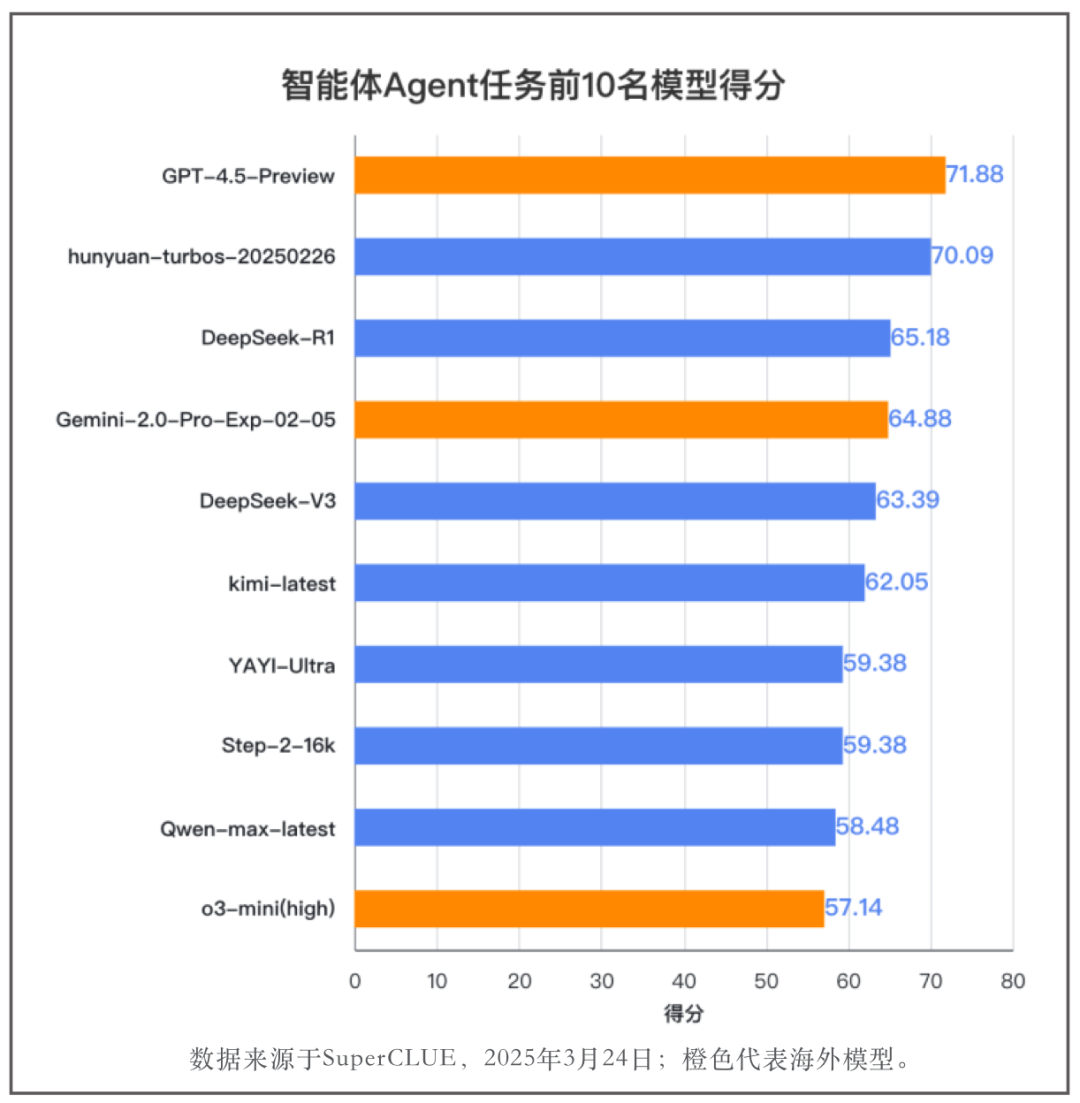
🔍国内大模型表现出彩,达到国际顶尖水平
分数排名前十的模型中,国内模型占7位。国内得分最高的模型hunyuan-turbos(70.09分)排名第二,与海外第一名GPT-4.5-Preview(71.88分)仅相差1.79分。
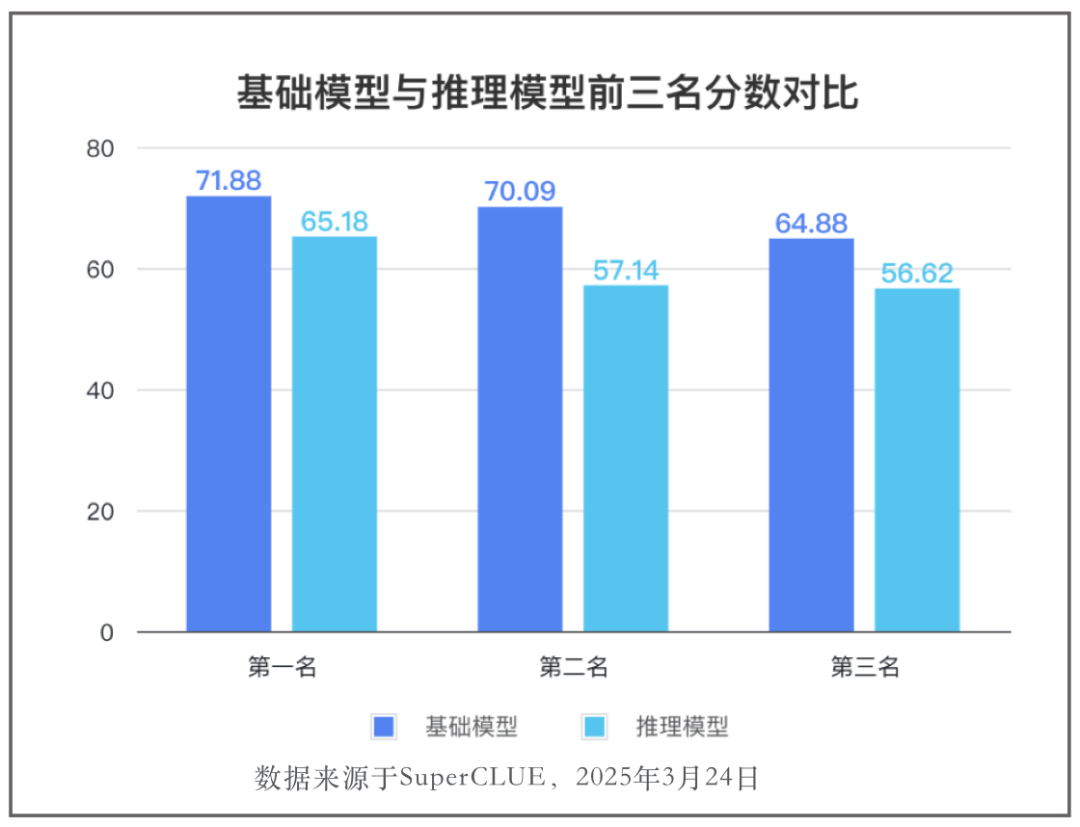
🔍基础模型整体强于推理模型
表现最好的推理模型Deepseek-R1(65.18分)比表现最好的基础模型GPT-4.5-Preview(71.88分)低6.7分。推理模型前三名相比于基础模型前三名平均低9.3分。
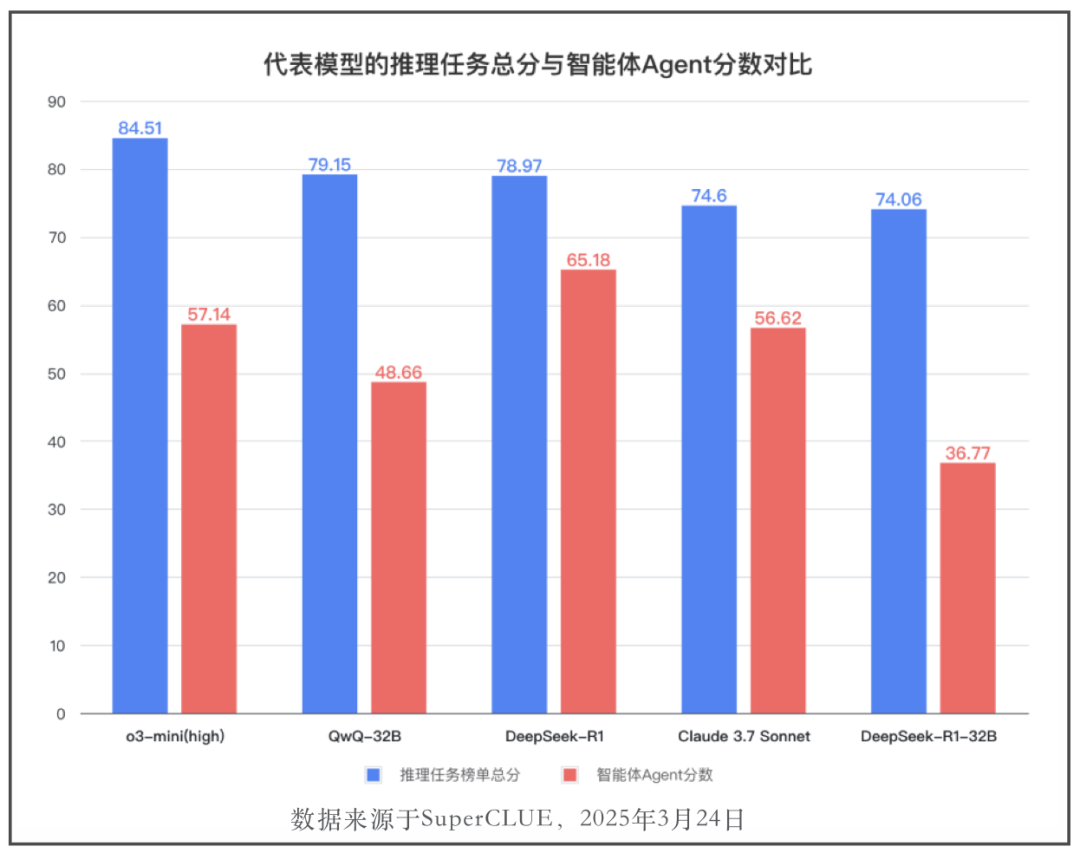
🔍兼顾强大推理能力和Agent能力是当前推理模型需要克服的难点
强大的推理能力并不代表更强的Agent能力。比如,o3-mini(high)和QwQ-32B在推理任务榜单上总分分别为:84.51和79.15,排名第一和第二,但在智能体Agent任务上的得分只有57.14和48.66,位于第10名和第17名。
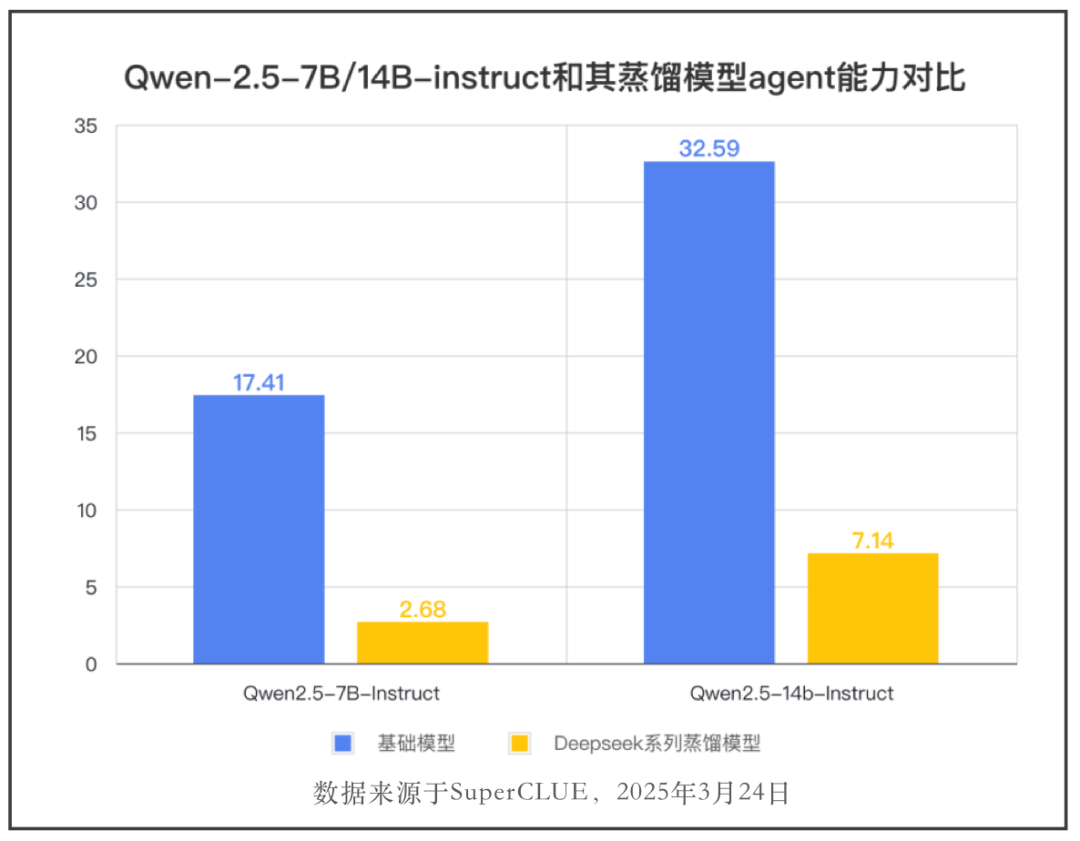
基础模型Qwen2.5-7B-Instruct和Qwen2.5-14b-Instruct得分别为:17.41分和32.59分。而基于这两个模型蒸馏得到的Deepseek系列推理模型得分只有2.68分和7.14分。蒸馏提升了模型的推理能力但降低了模型原本的Agent能力。
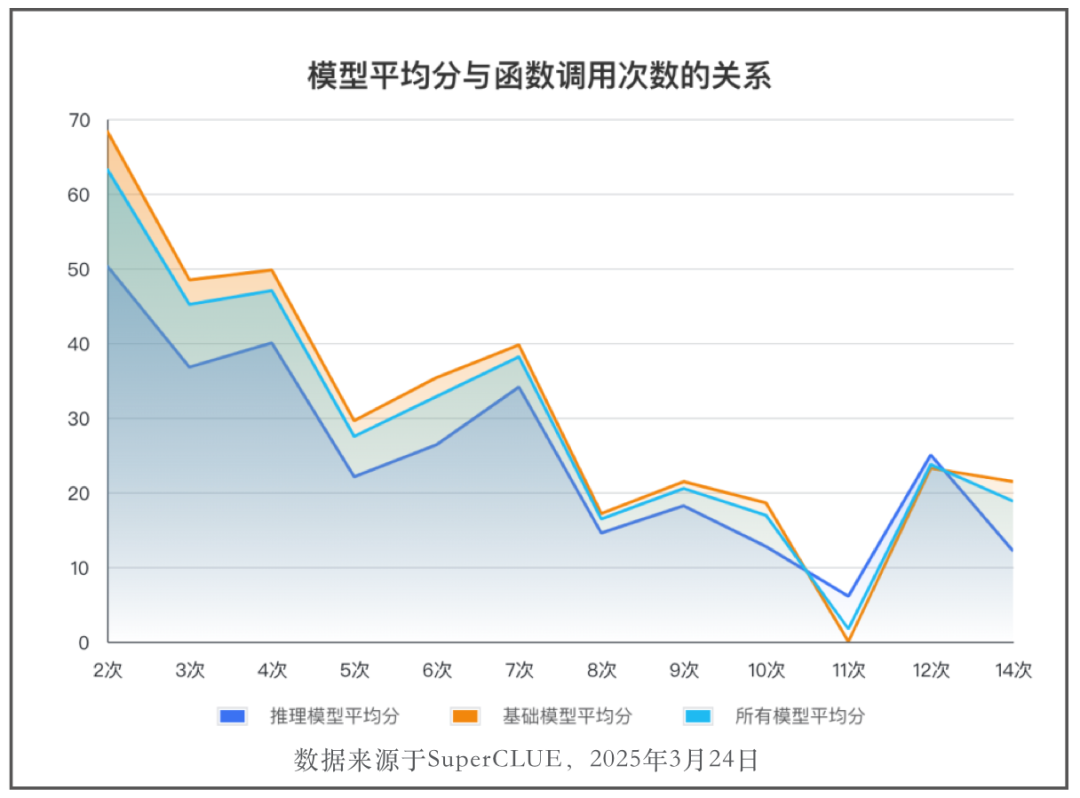
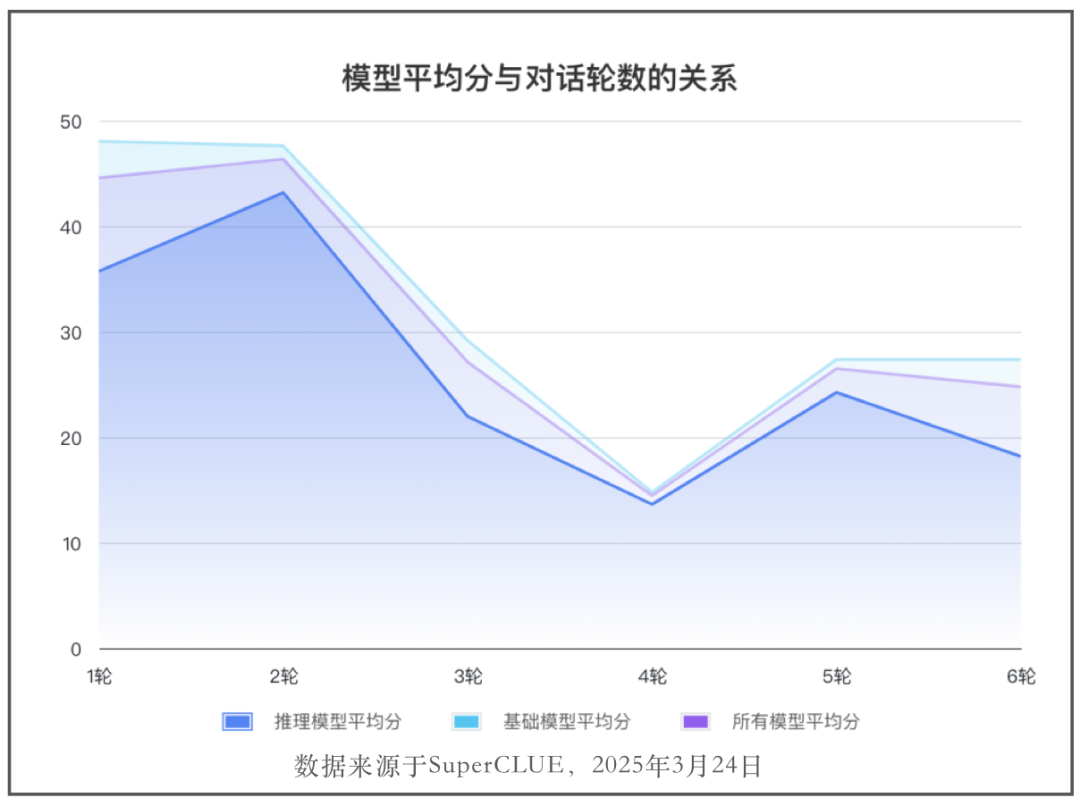
🔍多项问题限制模型Agent能力
伴随解题需要调用函数次数的增加和对话轮次的增加,模型的解题成功率呈现较为明显的下降趋势,表明模型在处理agent复杂和长程任务时能力不足。
此外,不遵循指令以及调用未提供的函数的情况,也是需要优化的问题。不遵循指令会导致提取标准函数调用失败,造成任务失败。而调用未提供的函数说明模型在agent任务中可能出现记忆出错、幻觉等问题,在构建智能体Agent应用时,需要设定严格权限以及完善的检查机制,防止调用错误的工具导致出现重大的问题。
【扩展阅读】
报告全文共46页,完整内容可查看高清完整PDF版。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_2503SuperCLUE
排行榜地址:
www.superclueai.com

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)